一种基于深度强化学习的水下无线传感器网络拓扑控制方法
1.本发明主要涉及水下无线传感网络技术领域,尤其涉及一种基于深度强化学习的水下无线传感器网络拓扑控制方法
背景技术:
2.水下无线传感器网络是一种实时、便捷、易扩展的水下信息感知和收集的网络,能够提高对海洋环境的监控和预测能力,以及增强处理海洋突发事件的能力。它有着广泛的应用场景,如海洋信息采集、环境监测、深海探测、灾害预测、辅助导航、分布式战术监控等。在水下无线传感器网络中,水下传感器节点通常由电池供电,电池容量严重受限,充电不方便。为了保证海洋应用的服务时间,支持海洋应用的水下无线传感器网络的网络生命周期至关重要。然而,在复杂、动态的水下环境中,优化水下无线传感器网络的网络生存期是一个非常具有挑战性的问题。首先,水下通信的能耗远高于地面无线传感器网络通信的能耗。此外,低质量的水下无线信道容易造成数据重传问题,进一步增加水下无线传感器网络的能量消耗。例如,水声通信质量容易受到多普勒效应、多径效应和海洋环境噪声等多种因素的影响;水下环境的浑浊度影响水下无线光通信的信道质量。此外,水流引起的水下传感器节点移动容易破坏网络拓扑结构,降低水下无线传感器网络的数据传输的可靠性。
3.拓扑控制是优化水下无线传感器网络的网络生命周期的重要方法之一。拓扑控制的目的是在保证网络连通性和网络覆盖的前提下,为水下无线传感器网络的数据传输阶段提供一种传输功率降低、网络负载均衡的网络拓扑。然而,现有的水下无线传感器网络拓扑控制策略缺乏及时有效地感知网络整体状态(信道状态和传输状态)的能力。具体来说,为了降低算法复杂度,提高计算效率,水下无线传感器网络的拓扑控制策略大多采用分布式启发式设计,无法从全局角度获取水下信道状态的特征。此外,数据传输阶段相关内置协议(路由协议和mac协议)的传输状态特征也影响拓扑控制策略的设计;这是因为拓扑控制本质上是为数据传输服务的。综上可知,如果水下无线传感器网络的拓扑控制策略不能充分考虑上述状态特征,将会严重削弱其优化网络生命周期的性能。因此,需要在水下无线传感器网络中设计一种能够充分感知整个网络各种状态的拓扑控制方法。
4.如期刊论文“a complex network approach to topology control problem in underwater acoustic sensor networks”提出了一种基于复杂网络的水下无线传感器网络拓扑控制策略,该策略以最小化传输能耗和提高数据传输可靠性为目标,根据水下传感器节点的局部信息去构建一种双分簇的网络拓扑结构,在保证网络拓扑具有复杂网络特征的前提下最小化网络能耗,从而延长网络生命周期。但是它没有考虑复杂动态的水下信道对网络拓扑的整体影响以及没有考虑后期运行的相关传输协议是否适用于该网络拓扑,从而导致数据传输成功率低以及网络生命周期短的问题。针对现有水下无线传感器网络的拓扑控制策略无法充分利用整体网络的信道和数据传输信息的问题,本发明提出了一种基于深度强化学习的水下无线传感器网络拓扑控制方法;它能有效保证网络连通性,降低和均衡网络能量消耗,从而延长网络生命周期。
技术实现要素:
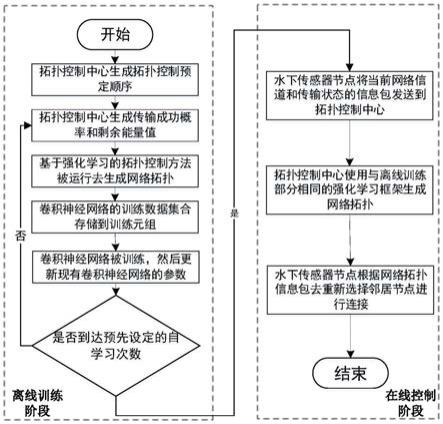
5.为解决上述技术问题,本发明提供一种基于深度强化学习的水下无线传感器网络拓扑控制方法。本发明是一种集中式的拓扑控制方法,它分为离线训练和在线控制两个阶段。首先在离线训练阶段,本发明设计了一个拓扑控制预定顺序的方法,按照该顺序去控制网络拓扑能够有效均衡网络负载,并同时保证网络的连通性。然后,本发明设计了一种基于强化学习的拓扑控制方法去根据网络的信道和传输信息生成网络拓扑;在此过程中本发明提出了一个基于深度学习的蒙特卡洛树搜索方法去评估每个动作选择的收益。最后,本发明设计了一种自学习方法去生成训练一个卷积神经网络,该卷积神经网络被训练后将用于在线部分的拓扑控制过程的动作选择的奖励评估。在网络运行的在线控制阶段,拓扑控制中心定期接收来自水下传感器节点的信息包,获取有关网络信道和传输状态的有用参数值。根据这些参数值,拓扑控制中心使用与离线训练部分相同的强化学习框架生成网络拓扑,以适应当前动态的水下环境。水下传感器节点在升级后的网络拓扑上使用现有路由策略进行数据传输。当拓扑控制的周期时间到达时,水下传感器节点将当前网络信道和传输状态的信息包发送到拓扑控制中心,拓扑控制中心重新生成网络拓扑。
6.本发明的目的通过以下技术方案来实现:一种基于深度强化学习的水下无线传感器网络拓扑控制方法,包括以下步骤:
7.一种基于深度强化学习的水下无线传感器网络拓扑控制方法,包括如下步骤:
8.s1.离线训练阶段
9.步骤101:拓扑控制中心获取已经完成部署的水面汇聚节点和水下传感器节点的坐标信息,并根据这些坐标信息生成拓扑控制预定顺序;
10.步骤102:拓扑控制中心为初始网络拓扑中的每条链路随机生成传输成功概率,同时为每个水下传感器节点随机生成剩余能量值;
11.步骤103:拓扑控制中心根据强化学习框架按照拓扑控制预定顺序依次为水下传感器节点选择它的数据传输的下一跳节点,并将该选择作为当前状态的卷积神经网络的训练数据;
12.步骤104:卷积神经网络的训练数据集合存储到训练元组;
13.步骤105:在下一次的拓扑控制过程中,拓扑控制中心利用更新完卷积神经网络的基于深度学习的蒙特卡洛树搜索方法去计算动作收益;
14.步骤106:判断拓扑控制中心是否达到预先设定的自学习次数,满足条件进入在线控制阶段;否则返回步骤102;
15.s2、在线控制阶段
16.步骤201:水下传感器节点将当前网络信道和传输状态的信息包发送到拓扑控制中心;
17.步骤202:当拓扑控制中心接收到所有水下传感器节点的信息包后,拓扑控制中心使用与离线训练部分相同的强化学习框架生成网络拓扑;
18.步骤203:当拓扑控制中心生成网络拓扑后,它以能够覆盖所有水下传感器节点的发射功率发送网络拓扑信息包;水下传感器节点收到网络拓扑信息包后,根据网络拓扑信息包,重新选择邻居节点进行连接,达到根据水下通信环境去进行网络拓扑控制的目的。
19.进一步,所述步骤103中拓扑控制中心为水下传感器节点传输的下一跳节点过程;
20.步骤301:按照拓扑控制预定顺序,某水下传感器节点ni为当前状态s
t
对应的水下传感器节点,拓扑控制中心利用基于深度学习的蒙特卡洛树搜索方法去计算当前状态s
t
的每个动作a
t
的收益
21.步骤302:拓扑控制中心选择当前状态s
t
的所有动作中具有最大收益的动作去作为当前状态下采取的最佳动作(即最优策略);
22.步骤303:当前状态s
t
转移到下一个状态s
t+1
,直到所有状态被遍历。
23.进一步,所述步骤301中基于深度学习的蒙特卡洛树搜索方法包含四个步骤:选择、扩展、模拟和方向传播:
24.1)选择过程:以水下传感器节点ni对应当前状态s
t
作为搜索树的根节点,当前状态s
t
的最优动作由公式1计算所得;当前状态s
t
执行最优动作后,转移到由最优动作决定的下一个状态s
t+1
,这个状态s
t+1
将执行动作选择;重复上述步骤直到到达一个之前没有出现过的状态,它被称为叶子状态。
25.其中公式1表示如下:
[0026][0027]
式中a
t
是当前状态s
t
的一个动作;a
t
是当前状态s
t
的动作集;c是一个预先设定的调节系数,且c>0;m(s
t
)是相同最优动作下状态s
t
对应的水下传感器节点被到达的次数;m(s
t
,a
t
)是当前状态s
t
选择动作a
t
的次数;q
π
(s
t
,a
t
)是当前状态s
t
选择动作a
t
期望收益,它由公式2计算获得;p(s
t
,a
t
)是当前状态s
t
选择动作a
t
的估计概率,它通过向卷积神经网络输入当前状态s
t
和动作a
t
获得;
[0028]
其中公式2表示如下:
[0029][0030]
式中m(s
t
,a
t
)是当前状态s
t
选择动作a
t
的次数;q
π
'(s
t
,a
t
)是第m(s
t
,a
t
)-1次时的当前状态s
t
选择动作a
t
的期望收益;v
t+1
(a
t
)表示执行动作a
t
到达状态s
t+1
后状态s
t+1
获得的期望收益,它通过向卷积神经网络输入当前状态s
t
和动作a
t
获得;
[0031]
2)扩展过程:当达到一个叶子状态时,扩展该叶子状态,直到mcts搜索次数达到设定的阈值;
[0032]
3)模拟过程:使用公式1来计算在扩展阶段被扩展的叶子状态的最优动作;当到达最终状态s
hn
所对应的水下传感器节点时,状态s
hn
的期望收益为v
hn
由公式3获得;当s
hn
执行完动作后,网络拓扑完成生成;
[0033]
其中:最终状态s
hn
是因为水下传感器节点个数为n以及网络连通性需求的连通度是h,即拓扑控制中心需要按照拓扑控制预定顺序遍历h次网络中n个水下传感器节点:
[0034]
其中公式3表示如下:
[0035]
[0036]
式中式中a
hn
是当前状态s
hn
的一个动作;a
hn
是当前状态s
hn
的动作集;t
π
表示通过将已生成的网络拓扑以及对应的网络信道和传输信息输入到已有的网络模拟器中去计算获得的该网络拓扑对应的网络生命周期;
[0037]
4)反向传播过程:将公式3的模拟奖励回传给根节点,并更新所经过的所有状态上的信息。
[0038]
有益效果
[0039]
1.本发明利用深度强化学习模型设计一种适用于动态水下环境的水下无线传感器网络拓扑控制方法,可以根据水下通信环境为水下无线传感器网络重新生成网络拓扑,在满足网络连通性要求的同时有效延长网络生命周期。
[0040]
2.本发明在网络未开始运行时利用一种自学习方法去无监督的训练应用于拓扑控制的卷积神经网络,从而提升在线控制阶段经过本发明的拓扑控制方法所得到的网络拓扑的水下环境适应能力。
附图说明
[0041]
图1为本方法执行的流程图;
具体实施方式
[0042]
为更加清楚描述实施方式,假设网络中有1个水面汇聚节点,1个水面拓扑控制中心,n个水下传感器节点,每个水下传感器节点的初始能量为e,初始网络拓扑的连通度为k,网络连通性需求的连通度h,其中1≤h≤k。以下结合附图1,对依据本发明设计的水下无线传感器网络的拓扑控制方法的具体方式、结构、特征及作用详细说明如下。
[0043]
s1.离线训练阶段
[0044]
步骤101:拓扑控制中心(通常位于水面)获取已经完成部署的水面汇聚节点和水下传感器节点的坐标信息,并根据这些坐标信息生成拓扑控制预定顺序。拓扑控制预定顺序生成如下:首先拓扑控制中心根据各个水下传感器节点到水面汇聚节点的传输时延,将初始网络拓扑简化成最小生成树形式的网络结构(根节点为水面汇聚节点)。将最小生成树的广度优先搜索顺序作为拓扑控制预定顺序。它是遍历一次网络中所有水下传感器节点的顺序。
[0045]
其中初始网络拓扑是所有水下传感器节点连接自身最大通信半径内的所有其它节点(包括水下传感器节点和水面汇聚节点)所构成的网络拓扑结构。
[0046]
其中最小生成树形式的网络结构具体为每个水下传感器节点存在一条到达水面汇聚节点通信时延最短的路径,并且这个网络拓扑满足以水面汇聚节点为根的树状结构。
[0047]
其中广度优先搜索顺序是在树结构中依次按层搜索,并且每一层的水下传感器节点被搜索的顺序是按照水下传感器节点到达水面汇聚节点传输时延由短到长的顺序进行。
[0048]
其中遍历一次网络中所有水下传感器节点的顺序是指拓扑控制中心根据该顺序依次为每个水下传感器节点选择一个下一跳邻居节点。具体来说,假如网络连通性需求的连通度h,那么扑控制中心需要按照拓扑控制预定顺序遍历h次网络中所有水下传感器节点。
[0049]
其中邻居节点是指任意一个水下传感器节点通信半径范围内的其它水下传感器
节点和通信半径范围内的水面汇聚节点,这些节点都是该水下传感器节点的邻居节点。
[0050]
步骤102:拓扑控制中心为初始网络拓扑中的每条链路随机生成传输成功概率,同时为每个水下传感器节点随机生成剩余能量值er。
[0051]
其中每条链路的传输成功概率为一个从0到1的实数值。
[0052]
其中水下传感器节点的剩余能量值er为一个从0到e的实数值。
[0053]
步骤103:根据强化学习框架,拓扑控制中心按照拓扑控制预定顺序依次为水下传感器节点选择它的数据传输的下一跳节点。该强化学习框架组成部分主要包含五个成分:状态集s、动作集a、策略集π、收益r、状态转移概率矩阵p。状态集s由已经按照拓扑控制预定顺序排序的水下传感器节点的状态组成。每个状态的动作集由每个传感器节点的邻居节点组成,每个状态的动作是指拓扑控制中心为该状态对应的水下传感器节点选择一个下一跳邻居节点。策略集是由状态和动作的组合映射构成。收益表示节点采取某一个策略时对应的奖励。状态转移概率矩阵表示节点当前状态转移到其它某个状态的概率矩阵。
[0054]
其中状态s
t
是由一个五元组{t
t-1
,t
t
,a
t
,p
t
,e
t
,}组成。t
t-1
表示从状态s1到状态s
t-1
已完成的动作选择;t
t
表示从状态s1到当前状态s
t
已完成的动作选择;a
t
表示当前状态s
t
的可选动作集合;p
t
表示网络链路传输成功率矩阵;e
t
表示所有水下传感器节点的能量参数,任意水下传感器节点的能量参数为其剩余能量er与它初始能量e的比值。
[0055]
步骤301:按照拓扑控制预定顺序,某水下传感器节点ni为当前状态s
t
对应的水下传感器节点(即当前ni需要选择数据传输的下一跳节点),拓扑控制中心利用基于深度学习的蒙特卡洛树搜索方法去计算当前状态s
t
的每个动作a
t
的收益
[0056]
其中基于深度学习的蒙特卡洛树搜索方法包含四个步骤:选择、扩展、模拟和方向传播。
[0057]
1)选择过程:以水下传感器节点ni对应当前状态s
t
作为搜索树的根节点,当前状态s
t
的最优动作由公式1计算所得;当前状态s
t
执行最优动作后,转移到由最优动作决定的下一个状态s
t+1
,这个状态s
t+1
将执行动作选择。重复上述步骤直到到达一个之前没有出现过的状态,它被称为叶子状态。
[0058]
其中公式1表示如下:
[0059][0060]
式中a
t
是当前状态s
t
的一个动作;a
t
是当前状态s
t
的动作集;c是一个预先设定的调节系数,且c>0;m(s
t
)是相同最优动作下状态s
t
对应的水下传感器节点被到达的次数;m(s
t
,a
t
)是当前状态s
t
选择动作a
t
的次数。q
π
(s
t
,a
t
)是当前状态s
t
选择动作a
t
期望收益,它由公式2计算获得。p(s
t
,a
t
)是当前状态s
t
选择动作a
t
的估计概率,它通过向卷积神经网络输入当前状态s
t
和动作a
t
获得。
[0061]
其中公式2表示如下:
[0062]
[0063]
式中m(s
t
,a
t
)是当前状态s
t
选择动作a
t
的次数;q
π'
(s
t
,a
t
)是第m(s
t
,a
t
)-1次时的当前状态s
t
选择动作a
t
的期望收益;v
t+1
(a
t
)表示执行动作a
t
到达状态s
t+1
后状态s
t+1
获得的期望收益,它通过向卷积神经网络输入当前状态s
t
和动作a
t
获得。
[0064]
其中卷积神经网络有三部分组成:特征网络、值网络和策略网络。特征网络包含一个卷积模块和三个resnet模块,卷积模块由一个64卷积滤波器、3
×
3卷积核、批处理归一化模块和relu激活模块组成。每个resnet由两个卷积滤波器建立,它的每个卷积滤波器都有一个3
×
3卷积核,一个批处理归一化模块和一个relu激活模块。三个resnet块的卷积滤波器分别为128、256和512。在特征网络之后,卷积神经网络划分为值网络和策略网络两个分支。值网络和策略网络都包含一个卷积模块,该卷积块具有512卷积滤波器、1
×
1卷积核、批处理归一化模块和relu激活模块,然后是全连接层。最后,值网络和策略网络分别使用softmax函数和tanh函数作为两个网络的输出层。估计概率p(s
t
,a
t
)和期望收益v
t+1
(a
t
)分别从策略网络和价值网络的输出层获得。
[0065]
2)扩展过程:当达到一个叶子状态时,扩展该叶子状态,直到mcts搜索次数达到设定的阈值。
[0066]
3)模拟过程:使用公式1来计算在扩展阶段被扩展的叶子状态的最优动作。当到达最终状态s
hn
所对应的水下传感器节点时,状态s
hn
的期望收益为v
hn
由公式3获得。当s
hn
执行完动作后,网络拓扑完成生成。
[0067]
其中最终状态s
hn
是因为水下传感器节点个数为n以及网络连通性需求的连通度是h,即拓扑控制中心需要按照拓扑控制预定顺序遍历h次网络中n个水下传感器节点。
[0068]
其中公式3表示如下:
[0069][0070]
式中式中a
hn
是当前状态s
hn
的一个动作;a
hn
是当前状态s
hn
的动作集;t
π
表示通过将已生成的网络拓扑以及对应的网络信道和传输信息输入到已有的网络模拟器中去计算获得的该网络拓扑对应的网络生命周期。
[0071]
4)反向传播过程:将公式3的模拟奖励回传给根节点,并更新所经过的所有状态上的信息。
[0072]
步骤302:然后,拓扑控制中心选择当前状态s
t
的所有动作中具有最大收益的动作去作为当前状态下采取的最佳动作(即最优策略)。
[0073]
步骤303:最后,当前状态s
t
转移到下一个状态s
t+1
,直到所有状态被遍历。
[0074]
步骤104:当拓扑控制中心根据强化学习框架完成网络拓扑控制之后,它将该网络拓扑以及对应的网络信道和传输信息输入到现有的网络模拟器中去计算该网络拓扑对应的网络生命周期。将生成该网络拓扑的每个状态、每个状态的动作概率、以及网络寿命作为一个训练数据集合存储到训练元组中。
[0075]
步骤105:从训练元组中以随机抽样的方式选择一组训练数据集合去作为训练卷积神经网络的输入,经过这次训练完的卷积神经网络将被更新。在下一次的拓扑控制过程中,拓扑控制中心利用更新完卷积神经网络的基于深度学习的蒙特卡洛树搜索方法去计算动作收益。
[0076]
步骤106:步骤2-5是采用自学习方法无监督训练神经网络的步骤,重复步骤2-5;
直至达到预先设定的自学习次数。
[0077]
以上步骤仅在本发明拓扑控制方法执行的离线训练阶段根据水下通信环境运行有限次。
[0078]
s2.在线控制阶段
[0079]
步骤201:当拓扑控制的周期时间到达时,水下传感器节点将当前网络信道和传输状态的信息包发送到拓扑控制中心。
[0080]
步骤202:当拓扑控制中心接收到所有水下传感器节点的信息包后,拓扑控制中心使用与离线训练部分相同的强化学习框架生成网络拓扑。
[0081]
步骤203:当拓扑控制中心生成网络拓扑后,它以能够覆盖所有水下传感器节点的发射功率发送网络拓扑信息包。水下传感器节点收到网络拓扑信息包后,根据网络拓扑信息包,重新选择邻居节点进行连接,达到根据水下通信环境去进行网络拓扑控制的目的。
[0082]
本发明并不限于上文描述的实施方式。以上对具体实施方式的描述旨在描述和说明本发明的技术方案,上述的具体实施方式仅仅是示意性的,并不是限制性的。在不脱离本发明宗旨和权利要求所保护的范围情况下,本领域的普通技术人员在本发明的启示下还可做出很多形式的具体变换,这些均属于本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1