一种基于深度强化学习的CSMA优化方法
一种基于深度强化学习的csma优化方法
技术领域
1.本发明涉及无线通信技术领域,主要涉及一种基于深度强化学习的csma优化方法。
背景技术:
2.强化学习是智能体(agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏,强化学习不同于连接主义学习中的监督学习,主要表现在强化信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统rls(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,rls必须靠自身的经历进行学习。通过这种方式,rls在行动-评价的环境中获得知识,改进行动方案以适应环境。
3.深度学习具有较强的感知能力,但是缺乏一定的决策能力;而强化学习具有决策能力,对感知问题束手无策。因此,将两者结合起来,优势互补,为复杂系统的感知决策问题提供了解决思路。深度强化学习将深度学习的感知能力和强化学习的决策能力相结合,可以直接根据输入的图像进行控制,是一种更接近人类思维方式的人工智能方法。
4.载波侦听多址接入协议,全称carrier sense multiple access(csma),是一种允许多个设备在同一信道发送信号的协议,其中的设备监听其它设备是否忙碌,只有在线路空闲时才发送。csma/ca(带有冲突避免的载波侦听多路访问)是csma在无线网络情况下的一种改进,在无线通信领域得到了广泛应用。
5.在csma/cd系统中,站点是发生了碰撞之后开始执行退避算法的,而对csma/ca系统,当一个站点要发送一个分组时,它首先侦听信道的状态,如果信道空闲,而且经过difs后仍然空闲,站点就开始发送信息,如果信道忙,则一直侦听信道的空闲时间超过difs。当信道最终空闲下来时,站点使用二进制退避算法(binary back-off algorithm),进入退避状态,以免发生碰撞。因为没有碰撞检测机制,所以站点在信道从忙到空闲时就要执行退避算法。
6.在网络规模较大、网络负载较重时,同一时间参与信道竞争的节点数量变多,这将导致大量的数据碰撞,从而导致大量的数据重传,从而传输性能大大降低。此外,csma还存在较大的公平性不足的问题,如在csma/ca中使用二进制退避算法来避免碰撞,由于上次发送成功的节点将获得更小的退避窗口,因此上次发送成功的节点竞争获得信道的概率更大,这种信道分配方式严重的不公平性。
技术实现要素:
7.发明目的:针对上述背景技术中存在的问题,本发明提供了一种基于深度强化学习的csma优化方法,以类似时隙aloha的方式将数据划分时隙,单个设备分别作为智能体,获取环境信息并以深度强化学习的方式决定是否参与单个发送时隙的信道竞争,使得网络能够根据实际网络情况智能的进行信道分配,在网络中发送负载较大时智能降低自身参与
信道竞争的频率,从而避免了传统csma中会发生的大量数据碰撞,提高系统性能和健壮性,同时这也能提高设备间的公平性。
8.技术方案:为实现上述目的,本发明采用的技术方案为:
9.一种基于深度强化学习的csma优化方法,包括以下步骤:
10.步骤s1、单个节点作为深度强化学习的智能体,完成初始化学习模型参数;获取时隙长度dataslottime和周期t;
11.步骤s2、当某个节点存在待发送帧信息时,节点通过深度强化学习,选择后n个时隙dataslottime所采取的动作,将所述动作表示为长度为n的数组action,其中action[i]表示后续的第i个时隙中节点要参与信道的竞争;当节点没有待发送帧信息时,该时隙内节点保持接收信息状态,并记录环境信息,直至有待发送帧出现;
[0012]
步骤s3、节点发送帧信息具体步骤包括:
[0013]
步骤s3.1、初始化计数器slotcount=0;
[0014]
步骤s3.2、当action[slotcount]为真时,代表节点参与此时隙的竞争,则该节点尝试向目的节点发送一个帧;当action[slotcount]不为真时,继续等待dataslottime时间;当完成发送或等待操作后,计数器加一;
[0015]
步骤s3.3、重复步骤s3.2,直至slotcount=n。
[0016]
进一步地,所述步骤s2中,将每个节点分别作为深度强化学习的智能体,分别执行深度强化学习算法,以t=n
×
dataslottime为基本运行时间单位;则步骤s2中强化学习算法模型表示如下:
[0017]
state
t
=(nn
t
,ni
t
,p
t
,send
t-1
),t=1,2,3,...
[0018]
其中state
t
代表状态集合,t代表周期数;nn
t
代表节点的两跳邻居数量;ni
t
表示节点两跳邻居态势信息,在结构上为二维矩阵;p
t
代表发送负载,即等待发送的帧的个数;send
t-1
代表上一周期本节点成功发送数据包的个数;
[0019]
每个节点各自维护两跳邻居态势信息,通过一跳邻居节点广播的信标帧更新自身态势表,并向一跳邻居广播自身信息和维护的态势表;其中态势信息包括节点发送负载pn、邻居节点数量nnn这2个值,则ni
t
表示为一个2
×
nn
t
的矩阵。
[0020]
进一步地,所述步骤s2中所述强化学习算法模型中回报函数表示如下:
[0021][0022]
其中
[0023][0024]ri
表示上一动作周期t中第i个时隙奖励值,所述收到正确收到数据帧代表收到任意目的节点的通过crc校验的帧。
[0025]
进一步地,所述步骤s3.2中发送一个帧是指采用csma/ca方式发送一个帧;具体步骤包括:
[0026]
步骤s3.2.1、节点以二进制指数退避算法进行回退,定义最小退避窗口cw
min
=22=4,最大退避窗口cw
min
=25=32,最大重复次数为4次,即重复超过4次表示回退失败;当回退失败或dataslottime时隙剩余时间不足以完成该帧的发送时,则等待时隙结束后执行步骤3.3;
[0027]
步骤s3.2.2、当节点竞争信道成功时,发送一个帧信息;所述帧信息包括数据帧和信标帧;数据帧由网络层下发获得,用于完成节点间的数据交互;信标帧由mac层周期性生成,用于完成节点的信息交互及时间同步;发送的帧信息是数据帧时,使用csma/ca方式发送;当发送的帧信息是信标帧时,则使用直接广播的方式发送,发送完成后等待接收端回复的确认帧ack并记录发送结果;当发送失败时,取消执行重复发送,在后续时隙中进行重传操作。
[0028]
有益效果:
[0029]
本发明提供的基于深度强化学习的csma优化方法,通过感知环境并以深度强化学习的方式决定是否参与单个发送时隙的信道竞争,智能调节设备参与信道竞争频率,根据实际网络情况智能的进行信道分配。使得系统在发送负载较小时能够充分利用信道,同时在网络中发送负载较大时又能避免传统csma中会发生的大量数据碰撞,避免了系统性能的急剧下降,增强系统健壮性。同时学习算法可以根据网络中每个节点实际负载情况,调节节点参与竞争的概率,使负载较大的节点获得更多的发送机会,同时又避免的部分节点一直获得信道,提高网络的公平性和实时性。
附图说明
[0030]
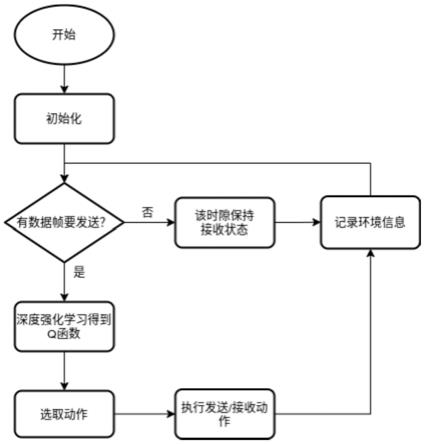
图1是本发明提供的基于深度强化学习的csma优化方法流程图;
[0031]
图2是本发明提供的智能体深度强化学习过程示意图;
[0032]
图3是本发明实施例中优化后的多个节点发送竞争情况示意图。
具体实施方式
[0033]
下面结合附图对本发明作更进一步的说明。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0034]
如图1所示为本发明应用于无线ad hoc网络时的典型优化方法流程图。网络中节点入网后首先等待接收其他节点的信标帧,如果收到信标帧,则进行时间同步和时隙长度矫正,否则按默认值初始化时间戳和时隙长度dataslottime和周期t,由此节点完成入网。入网后节点调度方法包括以下步骤:
[0035]
步骤s1、单个节点作为深度强化学习的智能体,完成初始化学习模型参数;获取时隙长度dataslottime和周期t。
[0036]
步骤s2、当某个节点存在待发送帧信息时,节点通过深度强化学习,选择后n个时隙dataslottime所采取的动作,将所述动作表示为长度为n的数组action,其中action[i]表示后续的第i个时隙中节点要参与信道的竞争;当节点没有待发送帧信息时,该时隙内节点保持接收信息状态,并记录环境信息,直至有待发送帧出现。
[0037]
上述节点发送的帧信息包括数据帧和信标帧。其中数据帧由网络层下发,用于完
成节点间的数据交互;信标帧由mac层周期性生成,用于完成节点的信息交互及时间同步。下表1中展示了信标帧中部分控制字段及其含义。
[0038]
表1信标帧中部分控制字段及其含义
[0039][0040][0041]
上述实施例中,将每个节点分别作为深度强化学习的智能体,执行深度强化学习算法,以t=n
×
dataslottime为基本运行时间单位;则强化学习算法模型表示如下:
[0042]
state
t
=(nn
t
,ni
t
,p
t
,send
t-1
),t=1,2,3,...
[0043]
其中state
t
代表状态集合,t代表周期数;nn
t
代表节点的两跳邻居数量;ni
t
表示节点两跳邻居态势信息,在结构上为二维矩阵;p
t
代表发送负载,及等待发送的帧的个数;send
t-1
代表上一周期本节点成功发送数据包的个数;
[0044]
每个节点各自维护两跳邻居态势信息,通过一跳邻居节点广播的信标帧更新自身态势表,并向一跳邻居广播自身信息和维护的态势表;其中态势信息包括节点发送负载pn、邻居节点数量nnn这2个值,则ni
t
表示为一个2
×
nn
t
的矩阵。
[0045]
强化学习算法模型中回报函数表示如下:
[0046][0047]
其中
[0048][0049]ri
表示上一动作周期t中第i个时隙奖励值,所述收到正确收到数据帧代表收到任意目的节点的通过crc校验的数据帧或态势帧。
[0050]
如图1所示,设备初始化完成后,设备进入等待状态;设备时域上被划分为长度为dataslottime的时隙,如果没有帧需要发送,则在当前时隙等待接收数据帧,直到时隙结束,时隙结束时更新节点状态信息,其中等待发送的帧包括来自上层的数据帧和mac层定时生成的信标帧;如果有数据帧要发送,则设备运行基于深度强化学习的csma优化学习算法,dqn网络输出q函数,设备基于q函数以∈-greedy策略选取出后续n个时隙的最佳动作action,之后设备利用表3的节点发送数据步骤执行后续n个时隙的动作;动作执行结束后设备再次检查是否有待发送的帧,重复执行此步骤。
[0051]
dqn网络学习算法具体如下表2所示:
[0052]
表2基于深度强化学习的csma优化学习算法
[0053][0054]
步骤s3、节点发送帧信息具体步骤包括:
[0055]
步骤s3.1、初始化计数器slotcount=0;
[0056]
步骤s3.2、当action[slotcount]为真时,代表节点参与此时隙的竞争,则该节点尝试向目的节点发送一个帧;当action[slotcount]不为真时,继续等待dataslottime时间;当完成发送或等待操作后,计数器加一;
[0057]
上述“发送一个帧”指的是节点以csma/ca方式发送一个帧,具体方式如下表3所示:
[0058]
表3节点发送数据步骤
[0059]
[0060]
步骤s3.2.1、节点以二进制指数退避算法进行回退,定义最小退避窗口cw
min
=22=4,最大退避窗口cw
min
=25=32,最大重复次数为4次,即重复超过4次表示回退失败;当回退失败或dataslottime时隙剩余时间不足以完成该帧的发送时,则等待时隙结束后执行步骤s3.3;
[0061]
步骤s3.2.2、当节点竞争信道成功时,发送一个帧信息。发送的帧信息是数据帧时,使用csma/ca方式发送;发送的帧信息是信标帧时,则使用直接广播的方式发送;发送完成后等待接收端回复的确认帧ack并记录发送结果;当发送失败时,取消执行重复发送,在后续时隙中进行重传操作。
[0062]
步骤s3.3、重复步骤s3.2,直至slotcount=n。
[0063]
图3展示了3个节点情况下的信道竞争情况,可见网络能根据信道情况及时调整自身发送频率使系统能够以最佳性能运行。
[0064]
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1