一种空地协同的自组织网络数据传输方法
1.本发明属于无线通信技术领域,尤其涉及一种应用深度强化学习实现空地协同的自组织网络数据传输方法。
背景技术:
2.自组织网络是一个无线节点的集合,网络中节点间的通信可以不依赖任何预先存在的基础路由设施,而是可以直接通信或者依靠其他节点作为中继节点进行通信,其分布式的无线和自配置特性让它得到广泛的应用。然而,当多个节点同时向一个中继节点传输数据包时,会导致中继节点过载。这是由于节点传输速率有限、数据包数量多,使得系统的传输时延增加。
3.无人机辅助通信具有高移动性、快速灵活部署、低成本及视距链路通信的特性,它可以用作空中物联网用户收集信息、不受地理限制成为空中基站,以及在没有可靠的直接通信链路的用户之间充当移动中继设备。相比于陆地基站通信和高空平台通信,按需分配的无人机通信系统能更快部署、更加灵活,并且由于短程视距链路的出现,还可能带来更好的通信信道。
4.专利申请公开号cn113193906a,基于无人机模式转换的空地融合通信方法,通过依据无线通信环境动态地选择无人机工作模式,可以在避免无人机频繁巡航所产生大量机械能耗的同时,在一定程度上改善信号传输质量,在信息传输吞吐量和能量消耗之间取得最优折中,有效提升无人机通信链路的经济效率;专利申请公开号cn111800185a提出了一种无人机辅助通信中的分布式空地联合部署方法,该算法收敛于最优的联盟结构。
5.为了解决地面节点拥堵的问题,可以采用无人机作为空中中继节点对自组织网络中的数据包进行中继传输。然而无人机的高机动性与地面自组织网络中数据包传输导致的动态环境使得需要无人机辅助传输的节点动态变化,动态变化的环境又会使得选择数据包的传输路径变得困难,且无人机的航迹规划问题与地面节点接入规划问题紧密耦合,使得最优的无人机辅助地面自组织网络的决策方案难以求解。
技术实现要素:
6.为了解决上述已有技术存在的不足,本发明提出一种基于深度强化学习的空地协同的自组织网络数据传输方法,可以根据数据传输的情况,快速在线优化无人机与地面节点间的通信,从而缓解自组织网络中的数据包拥堵问题,提升自组织网络的传输性能,并降低数据包的端到端时延,扩大自组织网络的应用范围。本发明的具体技术方案如下:一种空地协同的自组织网络数据传输方法,包括以下步骤:s1:建立无人机辅助地面自组织网络传输数据包的系统模型;具体过程为:s1-1:构建无人机辅助地面自组织网络传输数据包的基本场景模型,并进行模型简化;s1-2:补充信道模型,包括地-地信道模型和空-地信道模型,设自组织网络间的通
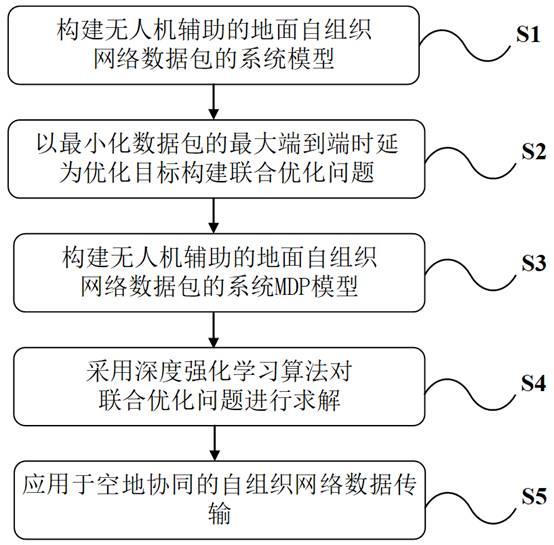
信和与无人机的通信均采用正交信道,因此不存在信道间干扰;s2:以最小化数据包的最大端到端时延为优化目标,构建有关无人机航迹和地面节点接入的联合优化问题;s3:构建无人机辅助地面自组织网络传输数据包的系统mdp模型;s4:基于步骤s3的模型,采用深度强化学习算法对联合优化问题进行求解;s5:将步骤s4的结果应用于空地协同的自组织网络数据传输。
7.进一步地,所述步骤s1-1包括以下步骤:s1-1-1:在长度为l,宽度为w的l
×
w矩形地面区域内,存在由j个节点组成的地面自组织网络以及一个地面接入点,每个节点有k个大小为n bits的数据包,各节点需要将所有数据包传输到地面接入点,采用prim算法预先给定地面路由方式;s1-1-2:各节点依次传输在本节点处的数据包,节点能够选择将数据包经由其他节点传输到地面接入点,或选择通过将数据包传给无人机,再由无人机传输到地面接入点;s1-1-3:设时间离散化,时间间隔为δt,每个数据包的每一次传输需要花费整数个时间间隔δt;设无人机以时间间隔δt
action
调整其飞行策略,δt
action
是δt的整数倍;s1-1-4:设无人机以固定高度h和恒定速度v飞行,从一个随机的初始位置li起飞,且无人机通过改变飞行方向调整飞行轨迹,在一个时间间隔δt
action
内的位置保持不变,无人机持续向地面接入点传输数据包,但只能在悬停时接受节点的数据包,将第j个节点坐标记为(x
j,
yj, 0);其中,在t时刻至t+1时刻的时间间隔δt
action
中,环境与无人机状态的信息维持不变,即用t时刻的状态表征t+δt
action
时间段内的信息,t时刻无人机的位置为l(t) = (x(t), y(t), h)。
8.进一步地,所述步骤s1-2包括以下步骤:s1-2-1:地面通信链路采用sub-6ghz频带,信道模型为瑞利衰落下的自由空间传输路径损耗模型,考虑环境中存在高斯白噪声,给出t时刻节点j在给定功率pj下,向节点传输数据包的信道模型和传输速率,即:(1)(2)其中,为参照距离d0=1m时的路径损耗,为节点j到节点直线距离,为非视距传输的路径损耗参数,为t时刻单位方差下的循环对称复高斯分布小尺度衰落成分,b1是sub-6g频带下的子信道带宽,n0为高斯白噪声单边功率谱密度;s1-2-2:对空地通信链路,在视距链路通信模型下,无人机与节点及地面接入点间的信道增益服从自由空间路径损耗模型,考虑环境中存在高斯白噪声,给出t时刻节点j向无人机传输数据包的信道模型h
j,u
(t)和传输速率r
j,u
(t),以及无人机在给定功率pu下,向地面接入点传输数据包的信道模型h
u,ap
(t)和传输速率r
u,ap
(t),即:
(3)(4)(5)(6)其中,d
j,u
(t)和d
u,ap
(t)分别为t时刻节点j到无人机的直线距离和无人机到地面接入点的直线距离,为视距传输的路径损耗参数,b2表示无人机传输数据时所用的信道带宽,ga为定向波束赋形天线增益。
9.进一步地,所述步骤s2的具体过程为:确定优化目标为最小化数据包的最大端到端时延,其中,一个数据包端到端时延是指该数据包从源节点传输到地面接入点所用的总时间,包括数据包在各节点间传输所用的时间,和在各节点处等待传输的时间;系统模型中,所有数据包都是从t=0时刻开始传输,因此,数据包的最大端到端时延即最后一个到达地面接入点的数据包的端到端时延,即所有数据包都到达地面接入点的所用时间t
end
,则建立的联合优化问题为:其中,v
flight
表示无人机飞行方向,v
access
表示节点接入策略。
10.进一步地,所述步骤s3构建无人机辅助地面自组织网络传输数据包的系统的mdp模型,包括状态s、行为a、状态转移概率矩阵p、奖励函数r和折扣因子γ,包括以下步骤:s3-1:状态s:每个时间间隔δt
action
内,系统的状态由以下两部分组成:无人机的位置坐标l(t),包括x和y坐标;各节点处及无人机处的数据包数量q(t)={qi(t),i=1,2,
…
,j,u},其中,i取1,2,
…
,j时表示第i个节点,i取u时表示无人机,qi(t)为t时刻第i个节点或无人机处的数据包数量;s3-2:行为a:考虑无人机轨迹规划和地面节点接入规划的联合优化,从而在mdp的行为中也包括这两个方面的行为:在无人机轨迹规划方面,在每个时间间隔δt
action
内,无人机通过改变其飞行方向来调整其飞行轨迹,对应行为;在地面节点接入规划方面,无人机悬停并接收距离其最近的节点的数据包,对应行为,即总共有五个能够选择的行为v
flight
+v
access
;s3-3:奖励函数r:奖励函数设置为:
(7)其中,r表示在终止状态前的最后一个大时间间隔δt
action
里,仍有r个时间间隔δt内系统未到达终止状态。
11.进一步地,所述步骤s4采用dqn算法对联合优化问题进行求解,包括以下步骤:s4-1:给定初始环境s0,初始化评估神经网络参数θ和目标神经网络参数θ-,并减少随机探索的概率ε;s4-2:以概率ε随机选择一个行为或以概率1
ꢀ–ꢀ
ε将当前状态s
t
输入评估神经网络,选择评估神经网络估计出的q值中最大q值对应的行为a
t
;s4-3:将选择的行为a
t
作用于环境,得到环境反馈的奖励r
t+1
,并将环境更新到状态s
t+1
;s4-4:判断经验回放池是否存满,如果未存满,将(s
t
,a
t
,r
t+1
,s
t+1
)对存入经验回放池并重复步骤s4-2 至步骤s4-4;如果已存满,用(s
t
,a
t
,r
t+1
,s
t+1
)对替换掉最开始存入经验回放池的(sm,am,r
m+1
,s
m+1
)对;s4-5:判断评估神经网络更新次数是否为目标神经网络更新间隔c的整数倍,如果是则将评估神经网络参数赋值给目标神经网络,即θ-=θ;s4-6:从经验回放池中抽取m个(sm,am,r
m+1
,s
m+1
)对;s4-7:对每个rm和s
m+1
,如果s
m+1
是终止状态,则令y
m=rm
,否则将状态s
m+1
输入目标神经网络,得到目标神经网络估计出的在状态s
m+1
时做出各行为a
m+1
的q值的最大值,并令;s4-8:对每个sm和am,将状态sm输入评估神经网络,获得评估神经网络估计出的在状态sm时做出各行为的q值中,所选行为a对应的q值;s4-9:计算损失函数;s4-10:通过损失函数l(θ)用梯度下降法更新评估神经网络,并使评估神经网络更新计数器+1;s4-11:判断环境是否到达终止状态,如果未到达终止状态则重复步骤s4-2 至步骤s4-11;s4-12:判断是否经训练了设定的次数,即是否到达了设定次数的终止状态,如果是则结束训练,否则重复步骤s4-1至步骤s4-12。
12.进一步地,所述步骤s5包括以下步骤:s5-1:给定初始环境s0;s5-2:将当前状态s
t
输入评估神经网络,选择评估神经网络估计出的q值中最大q值对应的行为a
t
;s5-3:将选择的行为a
t
作用于环境,得到环境反馈的奖励r
t+1
,并将环境更新到状态s
t+1
;
s5-4:判断环境是否到达终止状态,如果未到达终止状态则重复步骤s5-1至步骤s5-4,如果到达终止状态则结束应用过程。
13.本发明的有益效果在于:1.本发明的一种基于深度强化学习的无人机辅助地面自组织网络的空地通信联合优化方法,通过对无人机辅助地面自组织网络传输数据包的场景进行建模,同时根据优化目标和约束条件构建系统mdp模型,再利用深度强化学习不断更新神经网络,据此调整无人机的飞行策略和地面节点接入方案,最终实现自组织网络中数据包端到端时延的最小化。
14.2.本发明考虑到高度耦合的联合优化问题,使用强化学习进行求解可以简化系统模型,实现快速在线决策。
15.3.本发明应用无人机辅助地面自组织网络能够利用无人机的高机动性和与地面节点建立视距链路的能力,以较低的成本实现数据包的灵活传输,并为数据传输提供更好的信道。
16.4.本发明提出无人机辅助地面自组织网络传输数据包的技术方案能够提升自组织网络的传输性能,降低网络传输时延,为时间敏感型数据提供端到端时延保证,使得自组织网络能够应用到军用通信、灾后重建、救援行动等对端到端时延有严格要求的通信场景。
附图说明
17.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,通过参考附图会更加清楚的理解本发明的特征和优点,附图是示意性的而不应理解为对本发明进行任何限制,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,可以根据这些附图获得其他的附图。其中:图1为系统模型示意图;图2为节点传输数据包的两种方式;图3为dqn算法求解流程图;图4为dqn算法应用流程图;图5为传输方法整体流程图。
具体实施方式
18.为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合。
19.在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
20.如图1所示,本发明提出了一种基于深度强化学习的空地协同的自组织网络数据传输方法,首先建立无人机辅助地面自组织网络传输数据包的系统模型,其中无人机作为空中中继设备可以接收地面节点的数据包,并与远处的地面接入点(ap,access point)建立视距通信链路,可以向地面接入点高速传输数据包,从而缓解地面节点处的数据包拥堵
问题。然后利用神经网络区分并评价环境的不同状态,然后不断训练神经网络并更新其权重,最终学会使得系统传输时延最低的无人机飞行航迹与地面节点接入方案。
21.如图5所示,一种空地协同的自组织网络数据传输方法,包括以下步骤:s1:建立无人机辅助地面自组织网络传输数据包的系统模型;具体过程为:s1-1:构建无人机辅助地面自组织网络传输数据包的基本场景模型,并进行模型简化;s1-2:补充信道模型,包括地-地信道模型和空-地信道模型,设自组织网络间的通信和与无人机的通信均采用正交信道,因此不存在信道间干扰。
22.s2:以最小化数据包的最大端到端时延为优化目标,构建有关无人机航迹和地面节点接入的联合优化问题;具体过程为:确定优化目标为最小化数据包的最大端到端时延,其中,一个数据包端到端时延是指该数据包从源节点传输到地面接入点所用的总时间,包括数据包在各节点间传输所用的时间,和在各节点处等待传输的时间;系统模型中,所有数据包都是从t=0时刻开始传输,因此,数据包的最大端到端时延即最后一个到达地面接入点的数据包的端到端时延,即所有数据包都到达地面接入点的所用时间t
end
,则建立的联合优化问题为:其中,v
flight
表示无人机飞行方向,v
access
表示节点接入策略。
23.本发明的优化目标为最小化系统的最大端到端时延,在模型中,一个数据包的端到端时延是指从t = 0时刻至该数据包到达地面接收点的时刻所用的总时间,也包括了该数据包在各个节点等待该节点传输数据包队列中所有排在其前面的数据包时的等待时间,而数据包的最大端到端时延是所有数据包端到端时延的最大值。
24.在本发明使用的模型中,虽然存在多个数据包同时到达某一节点的情况,而没有决定这些数据包在该节点处被传输向下一个目标的先后顺序,所以无法通过单独描述每个数据包的端到端时延,再对其求最大值的方法得到最大端到端时延的表达式。但在模型中假设了所有数据包都是从t = 0时刻开始传输,不难发现最大端到端时延就是最后一个到达地面接入点的数据包的端到端时延,即所有数据包都到达地面接入点的所用时间,因此本发明没有必要对同时传输到某个节点的数据包进行排序,决定其传输的先后顺序。
25.s3:构建无人机辅助地面自组织网络传输数据包的系统mdp模型;本发明要解决的联合优化问题可以表述为一个序列决策问题,从而可以用深度强化学习算法进行求解。强化学习算法通过让智能体与环境不断交互来训练智能体,最终使得智能体学会能够获得最大长期回报的策略,智能体的行为完全由策略决定。
26.s4:基于步骤s3的模型,采用深度强化学习算法对联合优化问题进行求解;s5:将步骤s4的结果应用于空地协同的自组织网络数据传输。
27.在一些实施方式中,步骤s1-1包括以下步骤:s1-1-1:如图1所示,在长度为l,宽度为w的l
×
w矩形地面区域内,存在由j个节点组成的地面自组织网络以及一个地面接入点,每个节点有k个大小为n bits的数据包,各节点需要将所有数据包传输到地面接入点,采用prim算法预先给定地面路由方式;s1-1-2:如图2所示,各节点依次传输在本节点处的数据包,节点能够选择将数据
包经由其他节点传输到地面接入点,或选择通过将数据包传给无人机,再由无人机传输到地面接入点;s1-1-3:设时间离散化,时间间隔为δt,每个数据包的每一次传输需要花费整数个时间间隔δt;由于无人机在极短的时间δt内连续大幅度改变其飞行方向在现实中难以实现且没有必要,故设无人机以时间间隔δt
action
调整其飞行策略,δt
action
是δt的整数倍;s1-1-4:设无人机以固定高度h和恒定速度v飞行,从一个随机的初始位置li起飞,且无人机通过改变飞行方向调整飞行轨迹,在一个时间间隔δt
action
内的位置保持不变,无人机持续向地面接入点传输数据包,但只能在悬停时接受节点的数据包,将第j个节点坐标记为(x
j,
yj, 0);其中,在t时刻至t+1时刻的时间间隔δt
action
中,环境与无人机状态的信息维持不变,即用t时刻的状态表征t+δt
action
时间段内的信息,t时刻无人机的位置为l(t) = (x(t), y(t), h)。
28.在一些实施方式中,步骤s1-2包括以下步骤:s1-2-1:地面通信链路采用sub-6ghz频带,信道模型为瑞利衰落下的自由空间传输路径损耗模型,考虑环境中存在高斯白噪声,给出t时刻节点j在给定功率pj下,向节点传输数据包的信道模型和传输速率,即:(1)(2)其中,为参照距离d0=1m时的路径损耗,为节点j到节点直线距离,为非视距传输的路径损耗参数,为t时刻单位方差下的循环对称复高斯分布小尺度衰落成分,b1是sub-6g频带下的子信道带宽,n0为高斯白噪声单边功率谱密度;s1-2-2:对空地通信链路,在视距链路通信模型下,无人机与节点及地面接入点间的信道增益服从自由空间路径损耗模型,考虑环境中存在高斯白噪声,给出t时刻节点j向无人机传输数据包的信道模型h
j,u
(t)和传输速率r
j,u
(t),以及无人机在给定功率pu下,向地面接入点传输数据包的信道模型h
u,ap
(t)和传输速率r
u,ap
(t),即:(3)(4)(5)
reply)和固定目标值网络(fixed q-target)技术:经验回放是将采集到的样本先放入记忆池中,训练神经网络时则从记忆池中随机抽取部分样本来进行训练,从而消除了样本之间的关联性并提升了样本的利用率。dqn中还定义了固定目标值网络,通过一个更新缓慢的目标神经网络(target network)计算目标q值,从而提高了训练的稳定性和收敛性。
33.步骤s4的具体过程为:通过对环境进行建模,利用构建出的环境对智能体进行训练,即智能体不断与环境交互并获得奖励,智能体利用获得的奖励更新其神经网络参数,最终使得神经网络能够根据输入的状态拟合出较为精确的各行为的q值,从而得到一个收敛的策略,流程图如图3所示,较佳地,步骤s4包括以下步骤:s4-1:给定初始环境s0,初始化评估神经网络参数θ和目标神经网络参数,并减少随机探索的概率ε;s4-2:以概率ε随机选择一个行为或以概率1
ꢀ–ꢀ
ε将当前状态s
t
输入评估神经网络,选择评估神经网络估计出的q值中最大q值对应的行为a
t
;s4-3:将选择的行为a
t
作用于环境,得到环境反馈的奖励r
t+1
,并将环境更新到状态s
t+1
;s4-4:判断经验回放池是否存满,如果未存满,将(s
t
,a
t
,r
t+1
,s
t+1
)对存入经验回放池并重复步骤s4-2 至步骤s4-4;如果已存满,用(s
t
,a
t
,r
t+1
,s
t+1
)对替换掉最开始存入经验回放池的(sm,am,r
m+1
,s
m+1
)对;s4-5:判断评估神经网络更新次数是否为目标神经网络更新间隔c的整数倍,如果是则将评估神经网络参数赋值给目标神经网络,即;s4-6:从经验回放池中抽取m个(sm,am,r
m+1
,s
m+1
)对;s4-7:对每个rm和s
m+1
,如果s
m+1
是终止状态,则令y
m=rm
,否则将状态s
m+1
输入目标神经网络,得到目标神经网络估计出的在状态s
m+1
时做出各行为a
m+1
的q值的最大值,并令;s4-8:对每个sm和am,将状态sm输入评估神经网络,获得评估神经网络估计出的在状态sm时做出各行为的q值中,所选行为a对应的q值;s4-9:计算损失函数;s4-10:通过损失函数l(θ)用梯度下降法更新评估神经网络,并使评估神经网络更新计数器+1;s4-11:判断环境是否到达终止状态,如果未到达终止状态则重复步骤s4-2 至步骤s4-11;s4-12:判断是否经训练了设定的次数,即是否到达了设定次数的终止状态,如果是则结束训练,否则重复步骤s4-1至步骤s4-12。
34.具体的应用过程不需要更新神经网络,而是直接向训练好的神经网络中输入各状态值,根据神经网络输出的q值选择行为直到终止状态,从而得到用训练结束后得到的策略进行无人机轨迹规划和节点接入规划时数据包的最大端到端时延。步骤s5的流程图如图4
所示,较佳地,步骤s5包括以下步骤:s5-1:给定初始环境s0;s5-2:将当前状态s
t
输入评估神经网络,选择评估神经网络估计出的q值中最大q值对应的行为a
t
;s5-3:将选择的行为a
t
作用于环境,得到环境反馈的奖励r
t+1
,并将环境更新到状态s
t+1
;s5-4:判断环境是否到达终止状态,如果未到达终止状态则重复步骤s5-1至步骤s5-4,如果到达终止状态则结束应用过程。
35.以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1