数据接收方法与流程
1.本发明涉及数据接收领域,特别涉及一种数据接收方法。
背景技术:
2.随着不同项目对udp数据接收的需求,对于网络数据接收的差异性趋势愈发明显,对于如何实现网络数据的差异化接收成为迫切需求。既要满足数据接收的差异性,同时要兼顾数据收发性能,并且还需要剥离业务场景,以便适配不同项目中udp数据和业务紧密相关的部分。
3.目前,对于不同场景下的数据接收方案均需分别设计,并且,大多数据接收方案在接收数据时,只能适应一种类型的数据,对于多个数据发送端发送的数据,目前尚未有兼容性较好的方案。
技术实现要素:
4.本发明的目的是提供一种数据接收方法,能够根据不同场景下的不同类型的数据动态自动配置对应的解析模块,并且能够对各种类型的数据进行乱序重排,避免数据混乱。
5.本发明解决其技术问题,采用的技术方案是:
6.数据接收方法,包括如下步骤:
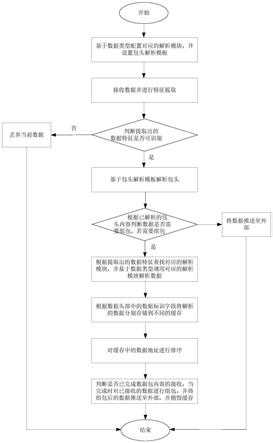
7.步骤1.基于数据类型配置对应的解析模块,并设置包头解析模板;
8.步骤2.接收数据并进行特征提取,并判断提取出的数据特征是否可识别,若可识别,则进入步骤3,否则丢弃当前数据,并结束;
9.步骤3.基于包头解析模板解析包头,并根据已解析的包头内容判断数据是否需要组包,若需要组包,则进入步骤4,否则直接将数据推送至外部;
10.步骤4.根据提取出的数据特征查找对应的解析模块,并基于数据类型调用对应的解析模块解析数据;
11.步骤5.根据数据头部中的数据标识字段将解析的数据分别存储到不同的缓存;
12.步骤6.对缓存中的数据地址进行排序;
13.步骤7.判断是否已完成数据包内容的接收,当完成时对已接收的数据进行组包,并将组包后的数据推送至外部,并销毁缓存。
14.进一步的是,步骤2中,通过配置的特征字段所在数据的偏移位置和所占字节数进行特征提取。
15.进一步的是,步骤2中,若提取出的数据特征不可识别,在丢弃当前数据的同时,进行日志报错。
16.进一步的是,步骤3中,所述基于包头解析模板解析包头具体为:
17.按包头解析模板的参数设置内容的字段字节数和字段所处的偏移位置对数据包包头携带的信息进行解析,获取数据标识、打包数量、包头长度及当前包号的包头内容。
18.进一步的是,步骤3中,所述根据已解析的包头内容判断数据是否需要组包时,当
打包数量和当前包号均等于1时,标识此原始数据包在发送侧未进行拆包处理,并直接将该数据推送至外部。
19.进一步的是,步骤4中,所述根据提取出的数据特征查找对应的解析模块时,根据判断出的数据特征,查找对应的解析模块,如果没有,则丢弃数据,进行日志报错,并从代码层面增加当前场景下的解析模块。
20.进一步的是,步骤5中,所述根据数据头部中的数据标识字段将解析的数据分别存储到不同的缓存,具体为:
21.根据数据标识在数据接收缓存队列搜索,确定此包是否是接收的第一包数据,当是第一包时,需重新分配缓存队列,并将接收数据拷贝至已分配的缓存队列;当不是第一包时,寻找对应的缓存队列,并将接收数据拷贝至对应的缓存队列中。
22.进一步的是,步骤6中,所述对缓存中的数据地址进行排序,具体为:
23.对于接收到的数据,获取头部字段中的数据标识,找到对应数据标识的有序队列;
24.再获取头部字段中的当前序号字段,在有序队列中查找数据,找到比当前序号小的位置,插入数据地址到有序队列;
25.如果没有找到,则说明所有数据都比当前数据要小,则将数据地址插入到有序队列尾部。
26.进一步的是,步骤7中,所述判断是否已完成数据包内容的接收时,当对应某一数据标识的有序队列中,当缓存的包数小于打包数量时,表示数据未接收完成,继续等待数据接收;当缓存的包数等于打包数量时,表示数据已接收完成。
27.进一步的是,步骤7中,所述对已接收的数据进行组包,具体为:基于数据包包头的当前包号字段,将有序队列中的数据依次取出,拼接到缓存中;
28.所述拼接过程为:每次拷贝数据前,记录之前已经拷贝数据的长度,按照长度偏移后拷贝数据,同时更新已经拷贝数据长度。
29.本发明的有益效果是,通过上述数据接收方法,首先,基于数据类型配置对应的解析模块,并设置包头解析模板;其次,接收数据并进行特征提取,并判断提取出的数据特征是否可识别,若不可识别则丢弃当前数据并结束,若可识别,则基于包头解析模板解析包头,并根据已解析的包头内容判断数据是否需要组包,若不需要则直接将数据推送至外部,否则根据提取出的数据特征查找对应的解析模块,并基于数据类型调用对应的解析模块解析数据;然后,根据数据头部中的数据标识字段将解析的数据分别存储到不同的缓存;然后,对缓存中的数据地址进行排序;最后,判断是否已完成数据包内容的接收,当完成时对已接收的数据进行组包,并将组包后的数据推送至外部,并销毁缓存。因此,本发明可以接收不同场景下的不同类型的数据,并且,能够根据不同的数据类型自动适配对应的解析模块,当数据流量较大时,也能够及时释放缓存资源,大大提升了数据传输效率。
附图说明
30.图1为本发明实施例1中数据接收方法的整体流程图;
31.图2为本发明实施例中数据包具体格式示意图;
32.图3为本发明实施例中多种数据标识数据接收并存储的示意图;
33.图4为本发明实施例中组包具体步骤示意图。
具体实施方式
34.下面结合附图及实施例,详细描述本发明的技术方案。
35.实施例
36.本实施例以udp协议数据为例进行详细说明,udp是user datagram protocol的简称,中文名是用户数据报协议,是osi(open system interconnection,开放式系统互联)参考模型中一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务,ietf rfc 768是udp的正式规范。一般来说,在网络质量令人十分不满意的环境下,udp协议数据包丢失会比较严重,但是由于udp的特性,它不属于连接型协议,因而具有资源消耗小,处理速度快的优点,所以通常音频、视频和普通数据在传送时使用udp较多,因为它们即使偶尔丢失一两个数据包,也不会对接收结果产生太大影响。
37.因此,本实施例提供的一种数据接收方法,其整体流程图见图1,其中,该方法包括如下步骤:
38.s1.基于数据类型配置对应的解析模块,并设置包头解析模板。
39.本实施例在涉及不同场景的业务需求部分,采用了灵活配置和动态创建的方式灵活适配不同的业务场景。比如:对于数据解析,不同的场景,使用到的数据类型,可能并不相同,这里采用动态创建的形式进行适配不同的场景。因此,在启动前,先配置好需要用到哪个解析模块,则数据采用对应的解析模块解析数据,解析完成的数据再执行后续流程。
40.这里,包头解析模板主要包括数据标识、打包数量、当前包号、数据包包头长度等参数设置内容,当接收到udp数据包后,可根据如上字段完成:是否需要进行组包、是否已完成原始数据包接收等内容的判断。其中,数据包具体格式示意图见图2。
41.各参数设置内容包括的具体字段、字段格式及其内容含义如下表所示:
[0042][0043]
s2.接收数据并进行特征提取,并判断提取出的数据特征是否可识别,若可识别,则进入s3,否则丢弃当前数据,并结束。
[0044]
这里,为了适应udp协议数据的数据传输要求,并且保证提取效率,可以通过配置的特征字段所在数据的偏移位置和所占字节数进行特征提取。实际应用时,若提取出的数据特征不可识别,在丢弃当前数据的同时,进行日志报错,这种情况下,表示接收的数据可能是骚扰数据,数据特征的识别,可以很好地滤除一些垃圾信息,降低处理负担,提升数据接收的质量和效率。
[0045]
s3.基于包头解析模板解析包头,并根据已解析的包头内容判断数据是否需要组包,若需要组包,则进入s4,否则直接将数据推送至外部。
[0046]
本实施例中,针对udp协议下的数据接收,基于包头解析模板解析包头具体可以为:
[0047]
按包头解析模板的参数设置内容的字段字节数和字段所处的偏移位置对数据包包头携带的信息进行解析,获取数据标识、打包数量、包头长度及当前包号等的包头内容,可以用于下一步骤的处理。
[0048]
参见图4,根据已解析的包头内容判断数据是否需要组包时,当打包数量和当前包号均等于1时,标识此原始数据包在发送侧未进行拆包处理,因此,在接收侧也不需要进行拼包处理,可以直接将该数据推送至外部。
[0049]
s4.根据提取出的数据特征查找对应的解析模块,并基于数据类型调用对应的解析模块解析数据。
[0050]
这里,根据提取出的数据特征查找对应的解析模块时,根据判断出的数据特征,查找对应的解析模块,如果没有,则丢弃数据,进行日志报错,这种情况说明自适应的解析模块已经无法满足当前业务场景,需要从代码层面增加当前场景下的数据解析模块。
[0051]
s5.根据数据头部中的数据标识字段将解析的数据分别存储到不同的缓存。
[0052]
如图3所示,根据数据标识在数据接收缓存队列搜索,确定此包是否是接收的第一包数据。当是第一包时,需重新分配缓存队列,并将接收数据拷贝至已分配的缓存队列;当不是第一包时,寻找对应的缓存队列,并将接收数据拷贝至对应的缓存队列中。其中判断是否是第一包数据的主要目的是数据标识为1的数据还没有接受完毕,数据标识为2的数据就已经来到,这时需要将不是该数据标识的数据存储起来。其优点是可以同时处理从多个发送端发送的数据。
[0053]
s6.对缓存中的数据地址进行排序。
[0054]
本实施例中,对缓存中的数据地址进行排序,具体为:首先,对于接收到的数据,获取头部字段中的数据标识,找到对应数据标识的有序队列。然后,再获取头部字段中的当前序号字段,在有序队列中查找数据,找到比当前序号小的位置,插入数据地址到有序队列。这里不产生数据拷贝,只保存地址,对数据地址进行排序,保证了高效性。最后,如果没有找到,则说明所有数据都比当前数据要小,则将数据地址插入到有序队列尾部。流程结束,继续后续数据处理。
[0055]
s7.判断是否已完成数据包内容的接收,当完成时对已接收的数据进行组包,并将组包后的数据推送至外部,并销毁缓存。
[0056]
需要说明的是,判断是否已完成数据包内容的接收时,当对应某一数据标识的有序队列中,当缓存的包数小于打包数量时,表示数据未接收完成,继续等待数据接收;当缓存的包数等于打包数量时,表示数据已接收完成。
[0057]
这里,在对已接收的数据进行组包时,可以基于数据包包头的当前包号字段,将有序队列中的数据依次取出,拼接到缓存中;所述拼接过程为:每次拷贝数据前,记录之前已经拷贝数据的长度,按照长度偏移后拷贝数据,同时更新已经拷贝数据长度。
[0058]
实际应用时,对于每次收到的数据,可以先判断有序队列中数据量是否达到打包数量,如果没有,则通过当前包号,采用插入排序,每一次的数据地址存入到有序队列中,排序的标识为当前包号,按照由小到大的顺序排,因为队列中存储的是数据地址,所以排序过程不会产生数据拷贝。这里,会一直判断有序队列中的数据个数是否等于打包数量,如果相等,则说明已经对数据标识1拆包后的数据收取完整,此时,由于有序队列中已经完整收取了数据,并且是按照包号进行的排序,所以组包过程只需要将有序队列中的数据依次取出,拼接到缓存中即可。拼接过程为:每次拷贝数据前,记录之前已经拷贝数据的长度,按照长度偏移后拷贝数据,同时更新已经拷贝数据长度。当数据拷贝完后,缓存中的数据就是组包完成后的数据,将该数据推送到外部继续进行后续数据组包。
[0059]
这里,销毁缓存的目的是为了节省缓存空间,以适用数据流量大的情况,进一步提高数据传输效率。
[0060]
因此,本实施例可以快速、高效、灵活的接收底层网络数据,同时,对于底层收发网络数据的缓存区,进行灵活配置,用以适配数据流量较大的情况。同时在接收到网络数据后,将数据存入缓存,在数据接收和数据处理间形成异步,用以提升数据接收性能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1