一种基于深度学习的换脸视频溯源方法及系统与流程
1.本发明涉及计算机视觉技术领域,具体涉及一种基于深度学习的换脸视频溯源方法及系统。
背景技术:
2.随着计算机视觉软硬件技术的发展和突破,越来越多的应用在c端普及,这带来了很多前所未有的ai伦理问题和潜在风险,特别是近几年gan的兴起带动了deepfake的开发和应用浪潮,其中的风险更是引起了社会各界人士和政府的重视。以zao为代表的手机app让换脸成为所有人都可以使用的技术,这项技术生成的几乎无法分辨真假的换脸视频由于其高逼真度和易用性,在带来全民娱乐的同时也暗藏着许多风险,其中包括肖像侵权、隐私泄露、不良视频传播等,这些风险让人们对换脸这把双刃剑保持着更多怀疑的态度。
3.目前市场上的换脸软件还没有使用溯源技术,而现有的视频溯源技术大概分为两类:基于水印的方法和基于指纹的方法。
4.1)基于水印方法,也就是在视频图像中加入水印来标记视频的来源,在溯源时再从图片中提取水印。水印可以是肉眼可见的,也可以是肉眼不可见的数字水印,该方法的本质就是修改原视频帧中的数值信息,把水印信息标记在像素中。其中又包括两种方法:
5.1.1修改空域:一般来说,不对信号做任何频率变换而得到的信号域就是空间域,通常是采用修改像素的某个分量值来实现水印的嵌入,典型的空间域水印算法有lsb算法、patchwork算法和纹理块映射编码算法。在空间域加入水印一般只能嵌入较小的数据量,并且通过该方法添加水印的图片很容易经过低通滤波、重新量化、有损压缩等操作去除水印;
6.1.2利用频域:典型算法有基于dft(离散傅里叶变换)、dct(离散余弦变换)、dwt(离散小波变换)的算法,这类算法是把图像变换到频域,在频域上加入水印,再通过逆变换,将图像转为空域上可见的格式。因为该方法是将水印信号分布到空间的所有像素上,并且与现有的图像压缩方法兼容,所以该方法能较好解决不可见性和鲁棒性之间的矛盾。
7.2)基于指纹的方法,也就是在视频生成后提取视频的指纹信息,然后保存在数据库中,当需要溯源的时候,再次计算视频指纹,通过数据库中唯一的指纹得到该视频的来源信息。这种方法的核心是视频指纹的提取,有传统的md5方法、对部分内容修改保持鲁棒的rabin指纹方法,也有现代的基于区块链的记录方法。
8.基于水印的视频溯源方法对于一些篡改攻击是不鲁棒的,比如视频压缩、视频帧加噪点、视频多水印混合等,这样的操作后很难再从视频中提取出原水印,而当前网络传播的特点就是视频可能被多次编辑,这种情况使得视频在传播中无法保持携带的水印信息,导致成功提取水印的概率大幅降低。
9.而对于基于指纹的方法,需要在生成视频的时候就对其指纹进行计算和记录,也就是需要c端的换脸应用先获取用户的信息,然后在生成视频后根据用户信息将水印加入视频中,并记录该视频指纹对应的用户和生成信息,这需要额外的计算能力和数据存储空间来实现。并且对于b端用户,生成视频的能力掌握在用户手上,无法收集和记录生成的视
频指纹,所以该技术对应用场景的限制性很大。也就是说,这种方法不适合当前网络环境和应用的根本原因是指纹是根据视频具体内容生成的,在视频生成之前无法确定指纹,而视频生成过程是在用户端进行的,所以无法在视频生成后对该视频进行记录。
技术实现要素:
10.为此,本发明提供一种基于深度学习的换脸视频溯源方法及系统,以解决现有视频溯源方法存在的对视频的水印破坏攻击鲁棒性低,指纹信息根据视频具体内容生成的,方法应用场景有限等问题。
11.为了实现上述目的,本发明提供如下技术方案:
12.根据本发明实施例的第一方面,提出了一种基于深度学习的换脸视频溯源方法,所述方法包括水印的合成和水印的提取;
13.所述水印的合成,具体包括:
14.将原始人脸视频和替换人脸图片输入至视频换脸模型得的换脸后的换脸视频;
15.根据用户id使用水印合成器生成用户唯一水印码,将所述水印码和换脸视频输入至视频水印编码模型,编码得到加有水印的换脸视频;
16.所述水印的提取,具体包括:
17.将待鉴别视频输入至视频鉴伪模型判断所述待鉴别视频是否为换脸视频;
18.若是,则将视频输入至视频水印解码模型,解码得到融合在视频帧中的水印码,并根据所述水印码得到生成换脸视频的用户信息。
19.进一步地,所述视频水印编码模型的输入视频帧为512*512*3的张量,输入的水印码为128*128*1的张量,输入的128*128*1水印码经过卷积操作后得到的512*512*3张量输入至ism模块,然后输出的512*512*3的水印码与输入的512*512*3视频帧经concat操作后输出512*512*3的张量,再经卷积操作后输出为512*512*6。
20.进一步地,所述ism模块具体用于,将随机数进行reshape操作后经卷积得到512*512*3的张量,并与输入的512*512*3张量经concat操作后得到512*512*6的张量,然后输入至1
×
1卷积得到第一512*512*32张量,继续输入至3
×
3卷积得到第二512*512*32张量,继续输入至3
×
3卷积得到第三512*512*32张量,将得到的三个512*512*32张量经concat操作得到512*512*96张量,经卷积后得到512*512*3张量,然后将得到的512*512*3张量与输入的512*512*3张量经element-wise plus操作后输出512*512*3的张量。
21.进一步地,所述视频水印解码模型的输入视频帧为512*512*3的张量,输入至1
×
1卷积得到第一512*512*3张量,继续输入至3
×
3卷积得到第二512*512*3张量,继续输入至3
×
3卷积得到第三512*512*3张量,然后将得的的三个512*512*3张量经concat操作后512*512*9张量,然后输入至全连接层fc层得到512*512*3的张量,最后再经一些卷积操作和尺度变换得到128*128*1的输出,输出即为加在视频上的水印码。
22.进一步地,所述方法还包括:
23.使用l1损失函数对视频水印编码模型和视频水印解码模型进行训练。
24.根据本发明实施例的第二方面,提出了一种基于深度学习的换脸视频溯源系统,所述系统包括水印合成模块和水印提取模块;
25.所述水印合成模块,用于:
26.将原始人脸视频和替换人脸图片输入至视频换脸模型得的换脸后的换脸视频;
27.根据用户id使用水印合成器生成用户唯一水印码,将所述水印码和换脸视频输入至视频水印编码模型,编码得到加有水印的换脸视频;
28.所述水印提取模块,用于:
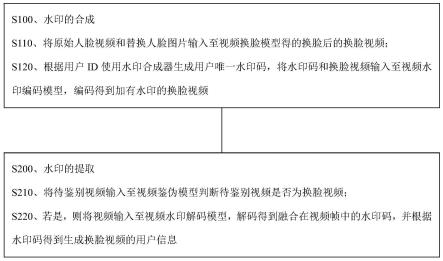
29.将待鉴别视频输入至视频鉴伪模型判断所述待鉴别视频是否为换脸视频;
30.若是,则将视频输入至视频水印解码模型,解码得到融合在视频帧中的水印码,并根据所述水印码得到生成换脸视频的用户信息。
31.根据本发明实施例的第三方面,提出了一种计算机存储介质,所述计算机存储介质中包含一个或多个程序指令,所述一个或多个程序指令用于被一种基于深度学习的换脸视频溯源系统执行如上任一项所述的方法。
32.本发明具有如下优点:
33.本发明提出的一种基于深度学习的换脸视频溯源方法及系统,可让违反了法律的不良换脸视频可以被检测出来并找到生成该视频的用户或责任方,让溯源成为可能,从而约束人们对换脸技术的不良应用。本方法不需要记录生成视频的指纹信息,只需要在向用户分发模型时记录该模型对应的唯一水印,就可以通过生成的视频确定生成视频的用户,也就是说,水印信息不同于指纹信息,水印具体内容在视频生成前就已经确定,所以本发明能在用户获取应用的时候就确定了该用户生成的所有视频的唯一标识,从而达到了从源头进行溯源的目的;同时,发明对视频的水印破坏攻击有较高的鲁棒性。
附图说明
34.为了更清楚地说明本发明的实施方式或现有技术中的技术方案,下面将对实施方式或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是示例性的,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图引伸获得其它的实施附图。
35.图1为本发明实施例1提供的一种基于深度学习的换脸视频溯源方法的流程示意图;
36.图2为本发明实施例1提供的一种基于深度学习的换脸视频溯源方法中水印合成流程示意图;
37.图3为本发明实施例1提供的一种基于深度学习的换脸视频溯源方法中视频水印编码模块结构示意图;
38.图4为本发明实施例1提供的一种基于深度学习的换脸视频溯源方法中ism模块的结构示意图;
39.图5为本发明实施例1提供的一种基于深度学习的换脸视频溯源方法中水印提取流程示意图;
40.图6为本发明实施例1提供的一种基于深度学习的换脸视频溯源方法中视频水印解码模块结构示意图。
具体实施方式
41.以下由特定的具体实施例说明本发明的实施方式,熟悉此技术的人士可由本说明
书所揭露的内容轻易地了解本发明的其他优点及功效,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
42.实施例1
43.如图1所示,本实施例提出了一种基于深度学习的换脸视频溯源方法,整个技术方案包含3个相对独立的深度模型,即视频换脸模型(face swaper)、人脸鉴伪模型(deepfake detector)和视频水印编解码模型(encoder和decoder),这三个模型共同组成了本技术的整体架构。该方法包括水印的合成和水印的提取。
44.s100、水印的合成,具体包括:
45.s110、将原始人脸视频和替换人脸图片输入至视频换脸模型得的换脸后的换脸视频。
46.s120、根据用户id使用水印合成器生成用户唯一水印码,将水印码和换脸视频输入至视频水印编码模型,编码得到加有水印的换脸视频。
47.水印合成流程如图2所示,输入被替换的人脸视频和替换人脸图片,经过视频换脸模型生成换脸后的视频,此时的视频是未加水印信息的视频,然后根据用户id用水印合成器生成一个代表用户的唯一水印码,将这个水印码和视频输入视频水印编码网络,可以获得加上水印的换脸视频。
48.本实施例提出的视频水印编码模型将水印信息通过深度网络散布在图片的所有空间,并用不同的尺度重叠放置,所以对视频篡改攻击具有较强的鲁棒性,例如视频的色彩、光照调整、部分画面缺失、压缩等操作都不会影响之后的水印提取。由于深度网络使用的是图片像素微小的数值改变,所以肉眼无法分辨出加水印前后视频的区别。
49.本实施例中,视频水印编码模型具体结构如图3所示,输入视频帧为512*512*3的张量,输入的水印码为128*128*1的张量,为了提高水印码中的信息的鲁棒性,该模型中使用了ism(information spread module)模块,这个模块的作用是将水印信息以不同的感受野重叠遍布在512*512的区域中,然后再与原图片融合。
50.输入的128*128*1水印码经过卷积操作后得到的512*512*3张量输入至ism模块,然后输出的512*512*3的水印码与输入的512*512*3视频帧经concat操作后输出512*512*3的张量,再经卷积操作后输出为512*512*6。
51.ism的具体结构如图4所示,该模块的输入(input)是水印码经过一些卷积操作后得到的512*512*3张量,这里为了对水印码进行一层加密,使视频扩散时无法通过多次相同技术加水印的方法覆盖原有的水印信息,增加了一个随机数(random vector)生成的信息,这个干扰信息存在于生成的水印中,但可以通过与该水印编码模型相应的水印解码模型去除。也就是说,如果本技术中使用的模型如果被以同样的训练方式进行了复现,但是由于随机数的不同,被复现的模型也不能干扰某一套特定随机数的编解码模型的解码,从而达到“一把钥匙开一把锁”的目的。
52.ism模块具体用于,将随机数进行reshape操作后经卷积得到512*512*3的张量,并与输入的512*512*3张量经concat操作后得到512*512*6的张量,然后输入至1
×
1卷积得到第一512*512*32张量,继续输入至3
×
3卷积得到第二512*512*32张量,继续输入至3
×
3卷积得到第三512*512*32张量,将得到的三个512*512*32张量经concat操作得到512*512*96
张量,经卷积后得到512*512*3张量,然后将得到的512*512*3张量与输入的512*512*3张量经element-wise plus操作后输出512*512*3的张量。
53.如图4所示,水印码在3个不同的感受野上进行了信息提取,然后将不同的张量结果在通道维度上叠加,这样就可以达到信息重叠遍布的目的,加上最初尺寸的信息,该模块的输出一共包含了4个尺度的水印码。生成的水印码与原图片结合,再经过一系列卷积操作就可以得到加了水印信息的换脸视频帧。为了使融合了水印信息的帧与原始帧肉眼无法区分,在训练时,这里的损失函数使用它们各个像素的l1 loss来衡量。
54.s200、水印的提取,具体包括:
55.s210、将待鉴别视频输入至视频鉴伪模型判断待鉴别视频是否为换脸视频;
56.s220、若是,则将视频输入至视频水印解码模型,解码得到融合在视频帧中的水印码,并根据水印码得到生成换脸视频的用户信息。
57.水印提取流程如图5所示,待鉴定的视频首先通过视频鉴伪模型判断该视频是否为脸部被替换视频,如果判断为真视频,即视频中人脸内容是真实人脸而非换脸模型生成,那么流程结束;如果判断为假视频,即视频为换脸后生成,那么视频输入视频水印解码模型,输出融合在视频帧中的水印码,由于水印码是用户唯一标识,所以可以用该水印获取生成该换脸视频的用户信息。
58.视频水印解码模型与视频水印编码模型是一一对应的,在模型训练时它们都成对训练,因为上文提到的random vector对于一组编解码模型是固定不变的,所以在编码时融合的random信息要用对应解码器去排除干扰。
59.视频水印解码模型具体结构如图6所示,输入的视频帧为512*512*3的张量,由于其中的水印信息以不同感受野重叠分布在图片中,所以使用了与编码时对应的一系列卷积来提取不同尺寸上的信息,然后将它们在通道维度叠加。得到的512*512*9的张量是原本512*512*3的水印码的重复信息叠加,所以使用一个fc层来解除它们之间的线性关联,因为重复信息可以认为是耦合的,使用fc将高位降到低维度可以认为是一种解耦操作,得到的512*512*3的张量。
60.具体的,视频水印解码模型的输入视频帧为512*512*3的张量,输入至1
×
1卷积得到第一512*512*3张量,继续输入至3
×
3卷积得到第二512*512*3张量,继续输入至3
×
3卷积得到第三512*512*3张量,然后将得的的三个512*512*3张量经concat操作后512*512*9张量,然后输入至全连接层fc层得到512*512*3的张量,最后再经一些卷积操作和尺度变换得到128*128*1的输出,输出即为加在视频上的水印码。为了让提取的水印码与原先加入的水印码一致,在训练时损失函数就是两个码的对应像素l1 loss。
61.本实施例提出的一种基于深度学习的换脸视频溯源方法,具有以下优点:
62.(1)将视频换脸模型(face swaper)、人脸鉴伪模型(deepfake detector)和水印编解码模型(encoder和decoder)三种相对独立的技术组合在一起,形成一整套换脸视频生成、鉴定和溯源的方案;
63.(2)视频水印编码模型中的ism结构,使用了随机干扰信息(random vector)和多尺度信息叠加的方法来防止视频篡改攻击,具有较高的鲁棒性;视频水印解码模型利用了相应策略获取消除重复信息和干扰信息,从而获取正确的水印;
64.(3)训练视频水印编解码模型时为了让视频中的水印肉眼不可见使用了l1损失函
数,为了让提取的水印正确也使用了l1损失函数,两个损失函数的加权组成了整体模型的损失函数,这也体现了该技术的使用目的;
65.(4)用深度网络将水印在低频空间以多尺度重叠的方式嵌入原图片,结合了深度网络可以进行无监督空间映射和多空间混合的优势,在传统频谱方法的基础上提高了复杂度并大幅提升算法的鲁棒性;
66.(5)将用户水印信息融合在视频生成模型中,用户生成的所有视频都携带水印的唯一标识,只需要在向用户分发模型时记录该用户标识,不需要对生成视频进行记录。
67.实施例2
68.与上述实施例1相对应的,本实施例提出了一种基于深度学习的换脸视频溯源系统,系统包括水印合成模块和水印提取模块;
69.水印合成模块,用于:
70.将原始人脸视频和替换人脸图片输入至视频换脸模型得的换脸后的换脸视频;
71.根据用户id使用水印合成器生成用户唯一水印码,将水印码和换脸视频输入至视频水印编码模型,编码得到加有水印的换脸视频;
72.水印提取模块,用于:
73.将待鉴别视频输入至视频鉴伪模型判断待鉴别视频是否为换脸视频;
74.若是,则将视频输入至视频水印解码模型,解码得到融合在视频帧中的水印码,并根据水印码得到生成换脸视频的用户信息。
75.本发明实施例提供的一种基于深度学习的换脸视频溯源系统中各部件所执行的功能均已在上述实施例1中做了详细介绍,因此这里不做过多赘述。
76.实施例3
77.与上述实施例相对应的,本实施例提出了一种计算机存储介质,计算机存储介质中包含一个或多个程序指令,一个或多个程序指令用于被一种基于深度学习的换脸视频溯源系统执行如实施例1的方法。
78.虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1