一种基于AVS3编码框架下的多路视频多视角场景编解码方法与流程
一种基于avs3编码框架下的多路视频多视角场景编解码方法
技术领域
1.本发明属于视频压缩编码领域,特别是一种基于avs3编码框架下的多路视频多视角场景编解码方法。
背景技术:
2.进入2021年,我国超高清8k编码标准第三代音视频标准avs3(audio video standard3)已经在国内的各地方进行商用,尤其是中央电视总台cctv 8k超高清试验频道开播,标志正式进入了8k超高清时代,接下来将在超高清基础研究下,推进3d超高清编解码技术,使得我国超高清编码标准继续领跑国际标准。
3.目前,在运动场下,传统多路摄像机拍摄出来的图像,将进行拼接处理,形成一个360度全景图像,之后再次编码传输,在后端则进行解码后的多视角输出观看。根据现有的技术,图像拼接质量对算法要求高,并且对性能也有极高需求,有拼接边界也会有模糊图像出现,这个直接影响到图像质量和用户体验,而且拼接算法与cpu\gpu计算相关,图像分辨率越大,越需要强大的硬件算力,这对图像处理是一个巨大挑战,并且也会影响图像实时性,并且要解决这种超高清图像的拼接所带来的拼接边界模糊缺陷,一方面需要强大的实时图像处理能力,同时,一旦多路拍摄视角有所变化,则需要重新拼接,并且需要重新植入算法,难度较大,并且成本较高,通用性不强。
4.为此,市场需要提出一种不需要进行拼接的算法,在图像编码层进行了一种多路直接编码传输方法,利用avs3标准现有的单路编码数据结构,扩展出多路编码结构,并且预置一些场景应用,经过理论验证分析,可以达到与传统拼接手段一样的可实现360度全景观看的目的,该方法具有了性能高,成本低,技术易实现等特点,同时不会出现拼接拼缝模糊现象,进而直接提升用户体验,具备初步可应用条件,因此本发明可为avs3提供一种新的多路编码手段,可充实avs3标准框架,具有一定的可实用意义。
技术实现要素:
5.本发明的目的在于公开一种基于avs3编码框架下的多路视频多视角场景编解码方法。该基于多路多视角编解码方法,在编码侧编码多路视频并且进行数据同步和传输,在后端解码侧可以随时选择和配置不同的视频作为最终输出。
6.实现本发明技术目的的技术方案如下:
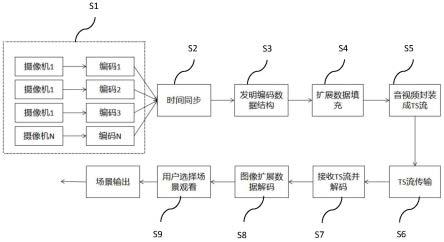
7.一种基于avs3编码框架下的多路视频多视角场景编解码方法,包含如下步骤:
8.第一步、多视角avs3编码:在某场景下,多路超高清摄像机分别进行多视角avs3编码
9.第二步、时间同步:编码后获取每路视频编码后的图像,进行多路视频编码时间校验,保证编码后的时间数据一致。
10.第三步、发明编码数据结构:在avs3编码框架内,利用编码图像的扩展数据,并把多路视频编码相关信息嵌入到该扩展数据中,其中该扩展数据包括多场景定义、各路图像
信息以及同步时间信息和多场景下解码的解码取帧排序等。
11.第四步、扩展数据填充:把扩展数据填充到第二步编码图像后扩展数据区中。
12.第五步、音视频封装成ts流:把携带扩展数据编码图像与音频结合后,封装成ts流格式,其中ts流(transport stream)即:传送流,是一种媒体文件封装格式。
13.第六步、ts流传输:ts流进行网络传输。
14.第七步、接收ts流并解码:用户在收到ts流后进行解码。
15.第八步、图像扩展数据解码:解码侧解码图像的扩展数据,检测到带有多路多视角时,可让用户选择不同推荐视角(不同场景)的视角画面输出。
16.第九步、用户选择场景观看:用户体验选择,并体验不同视角。
17.优选地,第二步、时间同步的进行多路视频编码时间校验,具体是把每帧含时间戳图像数据按链表数据结构存入内存中,通过向链表读取每路每帧数据,并读取时间戳,该时间戳为一串长整型时间数据,进行数字大小比对,确认编码后的时间数据一致。优选地,第三步、发明编码数据结构是:编码图像扩展数据是一种携带编码信息的特定数据,本发明人基于此数据结构,创立了一种叫做全景编码图像的扩展数据结构全景编码图像的扩展数据结构,并把多路视频编码相关信息嵌入到该扩展数据中,该扩展数据结构包括多场景定义、各路图像信息以及同步时间信息和多场景下解码的解码取帧排序等。
18.优选地,第八步、图像扩展数据解码是:解码侧解码图像的解析出全景编码图像的扩展数据结构表扩展数据,检测到带有多路多视角时,可让用户选择不同推荐视角(不同场景)的视角画面输出。
19.根据本发明的技术方案,产生的有益效果是:
20.1、本发明的一种基于avs3编码框架内的多路视频同时编码方法实现了在在avs编码框架下的全景多角编码,给超高清内容的制作,特别是需要全景内容制作领域提供一种方法指引,进一步完善了avs3编码标准。
21.2、本方法技术实现简便,不需要全景拼接,省去了图像拼接所带来的许多边界模糊问题,解决了视频因为图像拼接所带来的许多边界模糊问题,为市场提供更加清晰的视频信号和用户体验,同时场景编解码效率更高效。
22.3、本发明的基于avs3编码框架下的多路视频多视角场景编解码方法,不使用基于gpu(graphics processing unit,图像处理器)的拼接算法,且不需要对图像进行拼接,也不需要强大的算力支撑,但可为后端内容制作与输出提供不同视角,提供有力360度全景方案,因而能节约成本。
23.本发明中使用技术术语的英文缩写的含义及中文对照:
24.avs3(audio video standard 3)第三代音视频标准;
25.ts流(transport stream,传送流,一种媒体文件封装格式)。
附图说明
26.图1本发明编解码方法的流程方框图;
27.图2是本发明模拟实施的系统流程图。
具体实施方式
28.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,通过具体实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
29.一种基于avs3编码框架下的多路视频多视角场景编解码方法,包括如下步骤:
30.第一步s1、多视角avs3编码s1:多路超高清摄像机分别进行多视角avs3编码。
31.第二步s2、时间同步s2:编码后获取每路视频编码后的图像,编码的图像含有时间戳,(时间戳是基于同步时钟90k hz来换算,如果帧率是25fps的话,一帧数据采样时间40ms(=1000ms/25),那么每帧数据时间戳值增加就是90k x 40ms=3600),把每帧含时间戳图像数据按链表数据结构存入内存中,通过向链表读取每路每帧数据,并读取时间戳值,得到的时间戳为一串长整型数据,通过对时间戳数字大小的比对,当各路编码的时间戳之差绝经值不超过某个特定值(如100,具体可调整设置),就能确认两路的编码时间基本上保持一致,从而确认编码后的时间数据一致性。
32.第三步s3、编码数据结构s3:在avs3标准框架内,本身avs3在编码时,会携带各种类型扩展数据,表1:avs3标准下的扩展数据结构定义。
33.表1:avs3标准下的扩展数据结构定义
[0034][0035]
表2为全景编码图像的扩展数据结构表,如表2所示,编码图像扩展数据是一种携带编码信息的特定数据,本发明人基于此数据结构,创立了一种叫做全景编码图像的扩展数据结构,c语言伪代码如下:
[0036][0037]
并把多路视频编码属性信息(详看表2),通过代码写入到该扩展数据中,该扩展数据结构包括多场景定义、各路图像信息以及同步时间信息和多场景下解码的解码取帧排序等。
[0038]
表2:为全景编码图像的扩展数据结构表
[0039][0040][0041]
第四步s4、扩展数据填充s4:把扩展数据追加到第二步编码图像后扩展数据区中,形成最新的avs扩展数据区,c语言伪代码如下:
[0042][0043]
第五步s5、音视频封装成ts流s5:把携带扩展数据编码图像与音频结合后,封装成ts流格式。
[0044]
第六步s6、ts流传输s6:封装后的ts流,利用udp发送服务器,在组播网内部,把ts包通过udp协议发到组网内,进行数据流的推送,实现网络传输。
[0045]
udp是user datagram protocol的简称,即:用户数据包协议。
[0046]
第七步s7、接收ts流并解码s7:用户在收到ts流后进行解码。
[0047]
第八步s8、图像扩展数据解码s8:解码侧解码图像的解析出全景编码图像的扩展数据结构表扩展数据,通过检测avs扩展数据区的(next_bits(4)==
‘
1101’条件,参考表2)就得得到全景编码图像的扩展数据结构,解析出多路视频编码属性信息。
[0048]
第九步s9、用户选择场景观看s9:一旦检测到该流带有多路多视角多场景时,可让用户选择不同推荐视角(不同场景)的视角,用户在选择其中一路视解码,解码器根据该视频下的多路视频编码属性信息得知,场景号、解码帧顺序、pcr、宽、高等数据,选择其中一路进行解码即可。最终输出该视角场景下的视频。
[0049]
图2是本发明模拟实施的系统流程图,如下图2所示,
[0050]
该流程基本上验证了上述发明的所有步骤,具备一定的实施可行性,达到了多视角场景编解码的目标。本发明在服务器上的模拟过程如下:
[0051]
1、准备四路yuv原始数据各一帧图像,模拟当作摄像机拍摄的四个角度视频流,角度分别为0度,90度、180度、270度,准备一台编码服务器(含udp发送服务),准备一台接收服务器(含avs3解码)。
[0052]
2、利用avs3编码引擎同时分开编码四图yuv数据,生成avs3编码的基本视频数据。
[0053]
3、创建扩展数据,把每路的全景编码图像的扩展数据结构创建好。
[0054]
4.按事先模拟好的四个场景,写入全景编码图像的扩展数据结构到扩展数据区中
[0055]
5、数据封装成ts流。
[0056]
6.利用udp协议发送ts流
[0057]
7、接收服务器收到ts数据
[0058]
8、解码,解析扩展数据,解析全景编码图像的扩展数据结构
[0059]
9、列出四路场景。
[0060]
10、手动选择场景。
[0061]
11、按选择的场景输出
[0062]
通过上述一系列的模拟论证,我们发现,首先,编码到解码的流程基本符合本发明的整个过程,第二,在解析扩展数据时,能够实时获取并且达到按顺序解码的目的,第三,我们通过手动选择某个场景输出,验证解码时,也能够对应该场景的解码输出,基本上符合本发明的要点,我们有理由相信,当应用在多于4路或更多视角视频时,也能够符合本发明的要求,能达到本发明全景多视角观看目的,因此技术效果明显。
[0063]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1