一种全景视频生成方法及装置与流程
1.本技术涉及一种图像处理技术,尤其涉及一种全景视频生成方法。本技术还涉及一种全景视频生成装置。
背景技术:
2.目前视频监控技术已经相当成熟,其主要是在待监控位置进行摄像头部署,并将摄像头拍摄的视频呈现在显示屏幕上,以便于随时观察。
3.当前,视频监控技术可以通过多个摄像头对待监控区域进行拍摄,并利用图像拼接技术将每个摄像头拍摄的视频进行拼接形成全景图像,实现对待监控区域的全视角监控。但是当前的画面拼接技术,由于视频拍摄、摄像头像素或者光线明暗的问题,容易导致视频中画面细节在视频拼接过程中丢失,使得画面失真,导致全景图像与实际场景不匹配。
技术实现要素:
4.为解决现有技术中全景图像细节丢失的问题,本技术提供一种全景视频生成方法。本技术还涉及一种全景视频生成装置。
5.本技术提供一种全景视频生成方法,包括:为预设的全景区域建立3d模型;设置多个具有预设视角的视频获取端获取所述全景区域的多个实时视频图像,并基于每个所述视频获取端的拍摄视角,从所述3d模型中获取与所述拍摄视角对应的3d图像;融合所述3d图像与所述实时视频图像获得融合图像,拼接所述融合图像获得全景视频图像。
6.可选的,所述多个具有预设视角的视频获取端,包括:每个所述视频获取端的畸变中心与所述全景视频柱面映射的投影中心重合。
7.可选的,所述预设视角包括:每个所述视频获取端与相邻的视频获取端获取的实时视频图像具有重叠部分。
8.可选的,所述拼接所述融合图像获得全景视频图像之前还包括:调整所述实时视频图像的亮度,使所述每个所述实时视频图像的重叠部分亮度一致。
9.可选的,所述拼接所述融合图像包括:提取每个所述融合图像的图像特征点;基于所述图像特征点配准每个所述融合图像;基于配准的所述融合图像,通过预设拼接算法对所述融合图像拼接。
10.本技术还提供一种全景视频生成装置,包括:建模模块,用于为预设的全景区域建立3d模型;视频模块,用于设置多个具有预设视角的视频获取端获取所述全景区域的多个实
时视频图像,并基于每个所述视频获取端的拍摄视角,从所述3d模型中获取与所述拍摄视角对应的3d图像;拼接模块,用于融合所述3d图像与所述实时视频图像获得融合图像,拼接所述融合图像获得全景视频图像。
11.可选的,所述多个具有预设视角的视频获取端,包括:每个所述视频获取端的畸变中心与所述全景视频柱面映射的投影中心重合。
12.可选的,所述预设视角包括:每个所述视频获取端与相邻的视频获取端获取的实时视频图像具有重叠部分。
13.可选的,所述视频模块还包括:亮度单元,用于调整所述实时视频图像的亮度,使所述每个所述实时视频图像的重叠部分亮度一致。
14.可选的,所述拼接模块还包括:提取单元,用于提取每个所述融合图像的图像特征点;配准单元,用于基于所述图像特征点配准每个所述融合图像;拼接单元,用于基于配准的所述融合图像,通过预设拼接算法对所述融合图像拼接。
15.本技术相对与现有技术的优点:本技术提供一种全景视频生成方法,包括:为预设的全景区域建立3d模型;设置多个具有预设视角的视频获取端获取所述全景区域的多个实时视频图像,并基于每个所述视频获取端的拍摄视角,从所述3d模型中获取与所述拍摄视角对应的3d图像;融合所述3d图像与所述实时视频图像获得融合图像,拼接所述融合图像获得全景视频图像。通过融合实时视频图像和3d模型,使得最终合成的全景图像能够保持最多细节。
附图说明
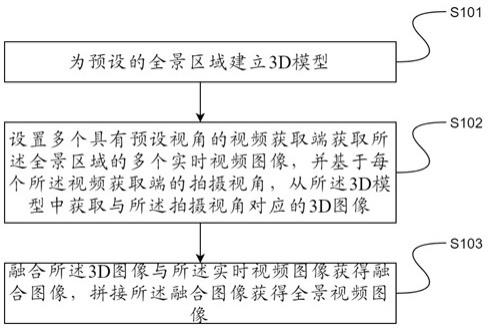
16.图1是本技术中全景视频生成的流程图。
17.图2是本技术中所述实时视频图像和3d图像融合流程图。
18.图3是本技术中的高斯正太分布图。
19.图4是本技术中像素点比较示意图。
20.图5是本技术中关键点描述示意图。
21.图6是本技术中全景视频生成装置示意图。
具体实施方式
22.在下面的描述中阐述了很多具体细节以便于充分理解本技术。但是本技术能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本技术内涵的情况下做类似推广,因此本技术不受下面公开的具体实施的限制。
23.本技术提供一种全景视频生成方法,包括:为预设的全景区域建立3d模型;设置多个具有预设视角的视频获取端获取所述全景区域的多个实时视频图像,并基于每个所述视频获取端的拍摄视角,从所述3d模型中获取与所述拍摄视角对应的3d图像;融合所述3d图像与所述实时视频图像获得融合图像,拼接所述融合图像获得全景视频图像。通过融合实
时视频图像和3d模型,使得最终合成的全景图像能够保持最多细节。
24.图1是本技术中全景视频生成的流程图。
25.请参照图1所示,s101为预设的全景区域建立3d模型。
26.所述3d模型是全景区域的模型,所述全景区域是指待监控区域。具体的,所述3d模型包括全景区域中的待监控物体。例如,所述全景区域为一间车间,所述待监控物体可以是所述车间中的车床以及其他相关机器,所述待监控物体还可以是所述车间的墙壁获取其他需要被监控的物体。
27.建立所述3d模型可以通过3d工程软件进行,例如pro/e,ug,autocad,solidwerk等。
28.请参照图1所示,s102设置多个具有预设视角的视频获取端获取所述全景区域的多个实时视频图像,并基于每个所述视频获取端的拍摄视角,从所述3d模型中获取与所述拍摄视角对应的3d图像。
29.所述视频获取端可以是,包括:摄像头,红外热像仪等可以获取连续视频的成像设备。所述视频获取端具有多个,分别部署到不同位置,其中相邻的每个视频获取端的视角是部分重叠的,并且每个所述视频获取端的畸变中心是和相同的柱面映射投影中心重合的。优选的,所述视频获取端的数量是360除以所述视频获取端的视角取整加1。可以清楚的是,所述视频获取端的具体数量是本领域技术人员根据实际需求设置的,并不是固定不变的。
30.布置完成所述视频获取端后,分别调整所述视频获取端的畸变参数和视频获取端畸变中心和柱面映射的投影中心的位置关系,以克服畸变和透视失真。
31.每个所述视频获取端分别获取各种的实时视频,并根据所述视频获取端顺序编号。本领域技术人员应当清楚,所述编号是为区别所述视频之间的不同,其采用何种编号方式不影响本技术的保护内容。
32.完成所述实时视频获取,然后根据每个所述视频获取端在全景环境中的位置和视角,对应的截取所述3d模型的3d图像。
33.请参照图1所示,s103融合所述3d图像与所述实时视频图像获得融合图像,拼接所述融合图像获得全景视频图像。
34.所属3d图像的细节内容是完整清楚的,并不会因为视频拍摄、摄像头像素或者光线明暗的因素影响。通过所述3d图像和实时视频图像的融合,将使得视频图像的细节内容更为清楚。
35.基于所述实时视频图像,提取所述视频图像中的图像帧,并按照顺序缓存到内存中;然后对每一个所述图像帧和3d图像进行图像融合。
36.图2是本技术中所述实时视频图像和3d图像融合流程图。
37.请参照图2所示,s201提取图像特征。
38.具体的,所述图像特征的提取可以采用sift(尺度不变特征变换)算法进行,包括:1)尺度空间极值点检测:搜索所有尺度上的图像位置,通过高斯微分函数来识别潜在的对于尺度和旋转不变的兴趣点。
39.所述尺度空间是指在图像信息处理模型中引入一个被视为尺度的参数,通过连续变化尺度参数获得多尺度下的尺度空间表示序列,对这些序列进行尺度空间主轮廓的提取,并以该主轮廓作为一种特征向量,实现边缘、角点检测和不同分辨率上的特征提取。在
本技术中,所述尺度可以是图像模糊程度,即所述多尺度就是图像的多个模糊程度。
40.所述模糊程度是通过高斯模糊算法实现的,包括:使用正态分布(高斯函数)计算模糊模板,并使用该模板与原图像做卷积运算,达到模糊图像的目的。例如:二维模板大小为m*n,则模板上的元素(x,y)对应的高斯计算公式为:其中,所述表示正态分布的标准差。在二维空间中,这个公式生成的曲面的等高线是从中心开始呈正态分布的同心圆,如图3所示。
41.根据的值,计算出高斯模板矩阵的大小,使用上述公式计算高斯模板矩阵的值,与所述实时视频图像做卷积,包括:以分布不为零的像素组成的卷积矩阵与原始图像做变换,例如每个像素的值都是周围相邻像素值的加权平均。原始像素的值有最大的高斯分布值,所以有最大的权重,相邻像素随着距离原始像素越来越远,其权重也越来越小,由此即可获得所述实时视频图像的高斯模糊图像。
42.然后基于不同的值做出不同模糊尺度的模糊图像组成尺度空间,所述尺度空间是多张模糊图像按层次叠放的。
43.接下来,每一层模糊图像的像素点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。如图4所示,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9
×
2个点共26个点比较,以确保在尺度空间和二维的图像都检测到极值点。根据最后的比较结果最后确定该点为极值点。
44.2)关键点定位:在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。
45.具体的,上述的出的极值点并不是真正的极值点,需要利用已知的离散空间点插值得到的连续空间极值点的方法叫做子像素插值,然后通过曲线拟合的方式获得拟合函数,并获取所述拟合函数的极值点,该拟合函数的极值点才是真正的极值点,该极值点就是关键点。具体的,可以通过对所述拟合函数求导的方式获取极值点。
46.3)方向确定:基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。其中所述梯度方向是指关键点邻域像素的梯度分布特性来确定其方向参数,再利用图像的梯度直方图求取关键点局部结构的稳定方向。
47.4)关键点描述:在每个关键点周围的邻域内,在选定的尺度上测量图像局部的梯度。这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变化。包括:使用一组向量来描述关键点也就是生成关键点描述符,这个描述符不只包含关键点,也含有关键点周围对其有贡献的像素点。
48.如图5a所示,中央为当前关键点的位置,每个小格代表为关键点邻域所在尺度空间的一个像素,求取每个像素的梯度幅值与梯度方向,箭头方向代表该像素的梯度方向,长度代表梯度幅值,然后利用高斯窗口对其进行加权运算。如图5b所示,最后在每个4
×
44
×
4的小块上绘制8个方向的梯度直方图,计算每个梯度方向的累加值,即可形成一个种子点。每个关键点由4个种子点组成,每个种子点有8个方向的向量信息。
49.s202,图像融合匹配。
50.所述融合图像包括:提取每个所述融合图像的图像特征点;基于所述图像特征点配准每个所述融合图像;基于配准的所述融合图像,通过预设拼接算法对所述融合图像拼接。
51.具体的,所述融合图像是根据所述关键点进行每一帧视频图像和3d图像的配准、像素点融合,形成融合图像。所述特征点是根据上述提取出的关键点,根据所述关键点进行图像匹配,包括:两个视频获取装置拍同一空间上得到两幅图像a、b,其中图像a到图像b存在一种变换,而且这种变换是一一对应的关系,这个变换矩阵用单应矩阵表示。opencv(一种计算机视觉和机器学习软件库)中可以用函数findhomography(一种坐标变换函数)计算得到变换矩阵h。利用所述变换矩阵h把图像b变换后放到图像a相应的位置,实现图像匹配。
52.具体的,利用变换矩阵h对图像b做变换,然后把图像b与图像a重叠在一起,并重新计算重叠区域新的像素值。对于计算重叠区域的像素值,优选的,实现一个图像的线性渐变,对于重叠的区域,靠近左边的部分,让左边图像内容显示的多一些,靠近右边的部分,让右边图像的内容显示的多一些。基于此,本技术提供的图像匹配代码如下:from pylab import *from numpy import *from pil import image# if you have pcv installed, these imports should workfrom pcv.geometry import homography, warpfrom pcv.localdescriptors import sift"""this is the panorama example from section 3.3."""# set paths to data folderfeatname = ['c:\\users\dell\desktop\pcv\jmu\panorama/z0'+str(i+1)+'.sift' for i in range(5)]imname = ['c:\\users\dell\desktop\pcv\jmu\panorama/z0'+str(i+1)+'.jpg' for i in range(5)]# extract features and matchl = {}d = {}for i in range(5):
ꢀꢀꢀꢀ
sift.process_image(imname[i],featname[i])
ꢀꢀꢀꢀ
l[i],d[i] = sift.read_features_from_file(featname[i])matches = {}for i in range(4):
ꢀꢀꢀꢀ
matches[i] = sift.match(d[i+1],d[i])# visualize the matches (figure 3-11 in the book)'''
for i in range(4):
ꢀꢀꢀꢀ
im1 = array(image.open(imname[i]))
ꢀꢀꢀꢀ
im2 = array(image.open(imname[i+1]))
ꢀꢀꢀꢀ
figure()
ꢀꢀꢀꢀ
sift.plot_matches(im2,im1,l[i+1],l[i],matches[i],show_below=true)'''# function to convert the matches to hom. pointsdef convert_points(j):
ꢀꢀꢀꢀ
ndx = matches[j].nonzero()[0]
ꢀꢀꢀꢀ
fp = homography.make_homog(l[j+1][ndx,:2].t)
ꢀꢀꢀꢀ
ndx2 = [int(matches[j][i]) for i in ndx]
ꢀꢀꢀꢀ
tp = homography.make_homog(l[j][ndx2,:2].t)
ꢀꢀꢀꢀꢀꢀꢀꢀ
# switch x and y
ꢀ‑ꢀ
todo this should move elsewhere
ꢀꢀꢀꢀ
fp = vstack([fp[1],fp[0],fp[2]])
ꢀꢀꢀꢀ
tp = vstack([tp[1],tp[0],tp[2]])
ꢀꢀꢀꢀ
return fp,tp# estimate the homographiesmodel = homography.ransacmodel()fp,tp = convert_points(1)h_12 = homography.h_from_ransac(fp,tp,model)[0] #im 1 to 2fp,tp = convert_points(0)h_01 = homography.h_from_ransac(fp,tp,model)[0] #im 0 to 1tp,fp = convert_points(2) #nb: reverse orderh_32 = homography.h_from_ransac(fp,tp,model)[0] #im 3 to 2tp,fp = convert_points(3) #nb: reverse orderh_43 = homography.h_from_ransac(fp,tp,model)[0] #im 4 to 3# warp the imagesdelta = 500 # for padding and translationim1 = array(image.open(imname[1]), "uint8")im2 = array(image.open(imname[2]), "uint8")im_12 = warp.panorama(h_12,im1,im2,delta,delta)im1 = array(image.open(imname[0]), "f")im_02 = warp.panorama(dot(h_12,h_01),im1,im_12,delta,delta)im1 = array(image.open(imname[3]), "f")im_32 = warp.panorama(h_32,im1,im_02,delta,delta)im1 = array(image.open(imname[4]), "f")im_42 = warp.panorama(dot(h_32,h_43),im1,im_32,delta,2*delta)figure()imshow(array(im_42, "uint8"))
axis('off')show()另外,因为视频获取设备和光照强度的差异,会造成一幅图像内部,以及图像之间亮度的不均匀,拼接后的图像会出现明暗交替,这样给观察造成极大的不便。室外场景的拼接效果比室内的要好很多,多图拼接对图片的要求也比较高,差异性大或太小(几乎相同)的拼接效果都很差。本技术优选用于室外场景的全景图像合成。优选的,所述拼接所述融合图像获得全景视频图像之前还包括,调整所述实时视频图像的亮度,使所述每个所述实时视频图像的重叠部分亮度一致。
[0053]
本技术还提供一种全景视频生成装置,包括:建模模块301,视频模块302,拼接模块303。
[0054]
图6是本技术中全景视频生成装置示意图。
[0055]
请参照图6所示,建模模块301,用于为预设的全景区域建立3d模型。
[0056]
所述3d模型是全景区域的模型,所述全景区域是指待监控区域。具体的,所述3d模型包括全景区域中的待监控物体。例如,所述全景区域为一间车间,所述待监控物体可以是所述车间中的车床以及其他相关机器,所述待监控物体还可以是所述车间的墙壁获取其他需要被监控的物体。
[0057]
建立所述3d模型可以通过3d工程软件进行,例如pro/e,ug,autocad,solidwerk等。
[0058]
请参照图6所示,视频模块302,用于设置多个具有预设视角的视频获取端获取所述全景区域的多个实时视频图像,并基于每个所述视频获取端的拍摄视角,从所述3d模型中获取与所述拍摄视角对应的3d图像。
[0059]
所述视频获取端可以是,包括:摄像头,红外热像仪等可以获取连续视频的成像设备。所述视频获取端具有多个,分别部署到不同位置,其中相邻的每个视频获取端的视角是部分重叠的,并且每个所述视频获取端的畸变中心是和相同的柱面映射投影中心重合的。优选的,所述视频获取端的数量是360除以所述视频获取端的视角取整加1。可以清楚的是,所述视频获取端的具体数量是本领域技术人员根据实际需求设置的,并不是固定不变的。
[0060]
布置完成所述视频获取端后,分别调整所述视频获取端的畸变参数和视频获取端畸变中心和柱面映射的投影中心的位置关系,以克服畸变和透视失真。
[0061]
每个所述视频获取端分别获取各种的实时视频,并根据所述视频获取端顺序编号。本领域技术人员应当清楚,所述编号是为区别所述视频之间的不同,其采用何种编号方式不影响本技术的保护内容。
[0062]
完成所述实时视频获取,然后根据每个所述视频获取端在全景环境中的位置和视角,对应的截取所述3d模型的3d图像。
[0063]
请参照图6所示,拼接模块303,用于融合所述3d图像与所述实时视频图像获得融合图像,拼接所述融合图像获得全景视频图像。
[0064]
所属3d图像的细节内容是完整清楚的,并不会因为视频拍摄、摄像头像素或者光线明暗的因素影响。通过所述3d图像和实时视频图像的融合,将使得视频图像的细节内容更为清楚。
[0065]
基于所述实时视频图像,提取所述视频图像中的图像帧,并按照顺序缓存到内存
中;然后对每一个所述图像帧和3d图像进行图像融合。
[0066]
请参照图2所示,s201提取图像特征。
[0067]
具体的,所述图像特征的提取可以采用sift(尺度不变特征变换)算法进行,包括:1)尺度空间极值点检测:搜索所有尺度上的图像位置,通过高斯微分函数来识别潜在的对于尺度和旋转不变的兴趣点。
[0068]
所述尺度空间是指在图像信息处理模型中引入一个被视为尺度的参数,通过连续变化尺度参数获得多尺度下的尺度空间表示序列,对这些序列进行尺度空间主轮廓的提取,并以该主轮廓作为一种特征向量,实现边缘、角点检测和不同分辨率上的特征提取。在本技术中,所述尺度可以是图像模糊程度,即所述多尺度就是图像的多个模糊程度。
[0069]
所述模糊程度是通过高斯模糊算法实现的,包括:使用正态分布(高斯函数)计算模糊模板,并使用该模板与原图像做卷积运算,达到模糊图像的目的。例如:二维模板大小为m*n,则模板上的元素(x,y)对应的高斯计算公式为:其中,所述表示正态分布的标准差。在二维空间中,这个公式生成的曲面的等高线是从中心开始呈正态分布的同心圆,如图3所示。
[0070]
根据的值,计算出高斯模板矩阵的大小,使用上述公式计算高斯模板矩阵的值,与所述实时视频图像做卷积,包括:以分布不为零的像素组成的卷积矩阵与原始图像做变换,例如每个像素的值都是周围相邻像素值的加权平均。原始像素的值有最大的高斯分布值,所以有最大的权重,相邻像素随着距离原始像素越来越远,其权重也越来越小,由此即可获得所述实时视频图像的高斯模糊图像。
[0071]
然后基于不同的值做出不同模糊尺度的模糊图像组成尺度空间,所述尺度空间是多张模糊图像按层次叠放的。
[0072]
接下来,每一层模糊图像的像素点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。如图4所示,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9
×
2个点共26个点比较,以确保在尺度空间和二维的图像都检测到极值点。最后确定该点为极值点。
[0073]
2)关键点定位:在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。
[0074]
具体的,上述的出的极值点并不是真正的极值点,需要利用已知的离散空间点插值得到的连续空间极值点的方法叫做子像素插值,然后通过曲线拟合的方式获得拟合函数,并获取所述拟合函数的极值点,该拟合函数的极值点才是真正的极值点,该极值点就是关键点。具体的,可以通过对所述拟合函数求导的方式获取极值点。
[0075]
3)方向确定:基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。其中所述梯度方向是指关键点邻域像素的梯度分布特性来确定其方向参数,再利用图像的梯度直方图求取关键点局部结构的稳定方向。
[0076]
4)关键点描述:在每个关键点周围的邻域内,在选定的尺度上测量图像局部的梯
度。这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变化。包括:使用一组向量来描述关键点也就是生成关键点描述符,这个描述符不只包含关键点,也含有关键点周围对其有贡献的像素点。
[0077]
如图5a所示,中央为当前关键点的位置,每个小格代表为关键点邻域所在尺度空间的一个像素,求取每个像素的梯度幅值与梯度方向,箭头方向代表该像素的梯度方向,长度代表梯度幅值,然后利用高斯窗口对其进行加权运算。如图5b所示,最后在每个4
×
44
×
4的小块上绘制8个方向的梯度直方图,计算每个梯度方向的累加值,即可形成一个种子点。每个关键点由4个种子点组成,每个种子点有8个方向的向量信息。
[0078]
s202,图像融合匹配。
[0079]
所述融合图像包括:提取每个所述融合图像的图像特征点;基于所述图像特征点配准每个所述融合图像;基于配准的所述融合图像,通过预设拼接算法对所述融合图像拼接。
[0080]
具体的,所述特征点是根据上述提取出的关键点,根据所述关键点进行图像匹配,包括:两个视频获取装置拍同一空间上得到两幅图像a、b,其中图像a到图像b存在一种变换,而且这种变换是一一对应的关系,这个变换矩阵用单应矩阵表示。opencv(一种计算机视觉和机器学习软件库)中可以用函数findhomography(一种坐标变换函数)计算得到变换矩阵h。利用所述变换矩阵h把图像b变换后放到图像a相应的位置,实现图像匹配。
[0081]
具体的,利用变换矩阵h对图像b做变换,然后把图像b与图像a重叠在一起,并重新计算重叠区域新的像素值。对于计算重叠区域的像素值,优选的,实现一个图像的线性渐变,对于重叠的区域,靠近左边的部分,让左边图像内容显示的多一些,靠近右边的部分,让右边图像的内容显示的多一些。基于此,本技术提供的图像匹配代码如下:from pylab import *from numpy import *from pil import image# if you have pcv installed, these imports should workfrom pcv.geometry import homography, warpfrom pcv.localdescriptors import sift"""this is the panorama example from section 3.3."""# set paths to data folderfeatname = ['c:\\users\dell\desktop\pcv\jmu\panorama/z0'+str(i+1)+'.sift' for i in range(5)]imname = ['c:\\users\dell\desktop\pcv\jmu\panorama/z0'+str(i+1)+'.jpg' for i in range(5)]# extract features and matchl = {}d = {}for i in range(5):
ꢀꢀꢀꢀ
sift.process_image(imname[i],featname[i])
ꢀꢀꢀꢀ
l[i],d[i] = sift.read_features_from_file(featname[i])matches = {}for i in range(4):
ꢀꢀꢀꢀ
matches[i] = sift.match(d[i+1],d[i])# visualize the matches (figure 3-11 in the book)'''for i in range(4):
ꢀꢀꢀꢀ
im1 = array(image.open(imname[i]))
ꢀꢀꢀꢀ
im2 = array(image.open(imname[i+1]))
ꢀꢀꢀꢀ
figure()
ꢀꢀꢀꢀ
sift.plot_matches(im2,im1,l[i+1],l[i],matches[i],show_below=true)'''# function to convert the matches to hom. pointsdef convert_points(j):
ꢀꢀꢀꢀ
ndx = matches[j].nonzero()[0]
ꢀꢀꢀꢀ
fp = homography.make_homog(l[j+1][ndx,:2].t)
ꢀꢀꢀꢀ
ndx2 = [int(matches[j][i]) for i in ndx]
ꢀꢀꢀꢀ
tp = homography.make_homog(l[j][ndx2,:2].t)
ꢀꢀꢀꢀꢀꢀꢀꢀ
# switch x and y
ꢀ‑ꢀ
todo this should move elsewhere
ꢀꢀꢀꢀ
fp = vstack([fp[1],fp[0],fp[2]])
ꢀꢀꢀꢀ
tp = vstack([tp[1],tp[0],tp[2]])
ꢀꢀꢀꢀ
return fp,tp# estimate the homographiesmodel = homography.ransacmodel()fp,tp = convert_points(1)h_12 = homography.h_from_ransac(fp,tp,model)[0] #im 1 to 2fp,tp = convert_points(0)h_01 = homography.h_from_ransac(fp,tp,model)[0] #im 0 to 1tp,fp = convert_points(2) #nb: reverse orderh_32 = homography.h_from_ransac(fp,tp,model)[0] #im 3 to 2tp,fp = convert_points(3) #nb: reverse orderh_43 = homography.h_from_ransac(fp,tp,model)[0] #im 4 to 3# warp the imagesdelta = 500 # for padding and translationim1 = array(image.open(imname[1]), "uint8")im2 = array(image.open(imname[2]), "uint8")im_12 = warp.panorama(h_12,im1,im2,delta,delta)im1 = array(image.open(imname[0]), "f")
im_02 = warp.panorama(dot(h_12,h_01),im1,im_12,delta,delta)im1 = array(image.open(imname[3]), "f")im_32 = warp.panorama(h_32,im1,im_02,delta,delta)im1 = array(image.open(imname[4]), "f")im_42 = warp.panorama(dot(h_32,h_43),im1,im_32,delta,2*delta)figure()imshow(array(im_42, "uint8"))axis('off')show()另外,因为视频获取设备和光照强度的差异,会造成一幅图像内部,以及图像之间亮度的不均匀,拼接后的图像会出现明暗交替,这样给观察造成极大的不便。室外场景的拼接效果比室内的要好很多,多图拼接对图片的要求也比较高,差异性大或太小(几乎相同)的拼接效果都很差。本技术优选用于室外场景的全景图像合成。优选的,所述拼接所述融合图像获得全景视频图像之前还包括,调整所述实时视频图像的亮度,使所述每个所述实时视频图像的重叠部分亮度一致。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1