一种电影场景内镜头视频排序系统及方法与流程
1.本发明属于视频制作领域,尤其涉及一种电影场景内镜头剪辑合成系统及方法。
背景技术:
2.随着互联网的发展,人民生活水平的不断提高,电影作为一种新型的内容记录和媒体表达的方式,丰富着人们的物质文化生活。
3.在视频生产领域。传统的视频制作剪辑过程比较繁琐,随着视频剪辑软件的越来越普及、数码设备功能的强大,一个电影通常包含成千上万个镜头,使电影剪辑制作需求也不断提升,缺乏一种对电影场景图镜头视频的剪辑合成方法。
技术实现要素:
4.本发明目的在于提供一种电影场景内镜头视频排序系统及方法,以解决上述的技术问题。
5.为解决上述技术问题,本发明的一种电影场景内镜头视频排序系统及方法的具体技术方案如下:
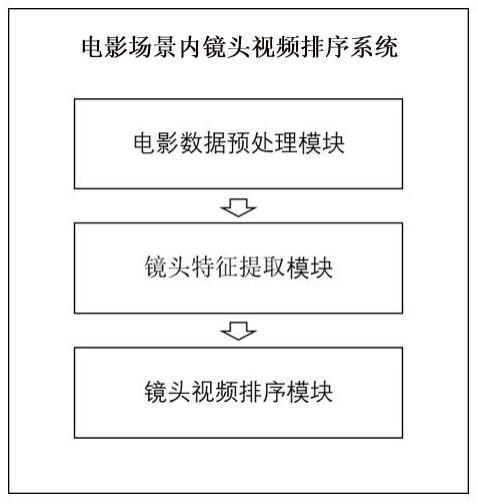
6.一种电影场景内镜头视频排序系统,包括电影数据预处理模块、镜头特征提取模块、镜头排序模块;
7.所述电影数据预处理模块包括镜头检测与分割,用于将输入的整个电影按照镜头进行切分;
8.所述镜头特征提取模块用于提取单个镜头的多个关键帧图像的内容特征;
9.所述镜头排序模块,用于将一个场景下的图像时序特征进行组合为一组特征图,多个场景的多组特征图进行输入;选定一个视频片段作为初始片段,预测出下一个视频片段是其中的哪一个镜头,直至完成所有视频片段的排序。
10.本发明还公开了一种电影场景内镜头视频排序方法,包括如下步骤:
11.步骤101:通过transnet模型对输入的电影进行分割:基于transnet方法对完整的电影视频进行镜头边界帧的识别,并按照镜头边界帧的时间节点,实现对电影视频的切分,得到多个镜头片段;
12.步骤102:使用transnet对步骤101中得到的镜头视频片段提取多帧图片:基于transnet方法提取每个镜头片段的第一帧、中间关键帧、结尾转场帧;
13.步骤103:基于resnet50对多图像进行特征提取并拼接获得视频片段特征:基于resnet50方法对每个镜头片段的第一帧、中间关键帧、结尾转场帧的图像进行特征提取,并将得到的特征向量进行拼接,作为代表该镜头片段的特征向量;
14.步骤104:使用transformer模型对电影片段进行预测分类:随机选出初始镜头片段,基于transformer方法将代表镜头片段的特征向量作为输入,通过时序分类的方法预测下一个镜头片段,然后根据开端选定的镜头特征和已预测的镜头特征,继续进行预测下一镜头,直至将其串联成一个完整的视频。
15.进一步地,所述步骤101将电影视频输入transnet模型进行边界帧判别并按照边界帧对电影视频进行切分;电影视频通过transnet模型中的4个ddcnn单元进行处理,4个ddcnn单元具有相同的卷积核大小和不同的扩张率,将经过4个卷积操作之后分别得到的4个输出进行拼接,再经过1层池化层和2层全连接层,最终输出对电影视频中的每一帧的判别,即该帧是否为边界帧,由此得到边界帧的时间节点;然后根据得到的边界帧时间节点对电影视频进行切分,从而获取每一个镜头的视频。
16.进一步地,所述步骤101的具体步骤为:
17.transnet的输入为n帧长的电影视频,输出为预测得到的视频边界帧,transnet共有4个ddcnn单元,其中4个单元的卷积运算均为3
×3×
3,每个单元的扩张率分别为1、2、4、8,输入的视频先经过4个ddcnn,将4个ddcnn得到的4个输出拼接起来,再经过1层池化层与2层全连接层,输出每一帧的判别结果;
18.训练时,网络的输入为长度为n的完整电影视频,且被统一调整大小为n
×w×h×
3,其中w表示图像的宽度,h表示图像的高度,n帧序列视频帧通过4个ddcnn单元,再经过1层池化层和两层全连接层,最后输出n
×
2维向量,表示对每一帧图像是否为边界帧的判别,transnet的模型的训练具体为:训练集为n个编码向量图像帧的视频序列,通过随机梯度下降反向传播算法降低cross-entropy损失函数的损失值,具体loss函数如下:
[0019][0020]
训练:采用adam优化器,初始学习率为0.001;
[0021]
预测:对于按照上述步骤训练完成的transnet,输入任意电影m
test
全部帧,判断每一帧是否是镜头边界,进而得到边界帧,通过边界帧对视频进行划分进而获取每一个镜头的视频,用于步骤102。
[0022]
进一步地,所述步骤102对校验后的镜头视频片段进行提取多帧图片,需要提取的内容包含第一帧、中间关键帧、结尾转场帧,将步骤101中的得到的每一镜头的边界帧分别作为该镜头片段的第一帧和结尾转场帧,中间关键帧为镜头片段中经过transnet之后的帧表征向量与其他帧表征向量计算平均余弦相似度,其中余弦相似度最大的作为关键帧;将每个视频片段提取的帧进行拼接,用于表示该片段;以此组合成一个新的时序视频序列。
[0023]
进一步地,所述步骤102余弦相似度的计算公式如下:
[0024][0025]
其中θ表示视频片段特征向量集合,a表示进行平均余弦相似度计算的视频片段特征向量,b表示视频片段集合θ中非a的视频片段的视频片段特征,m为集合θ的大小,n为单个特征向量的维度。
[0026]
进一步地,所述步骤103选定一个镜头作为起始镜头,将开始图像i
strat
,中间关键帧图像i
middle1...n
,结尾转场图像i
end
送入resnet50预训练模型中,进行图像特征向量提取,然后经过concat操作连接第一帧、中间关键帧、结尾转场帧的特征向量,获得该镜头片段的特征向量f
n embedding
,重复以上步骤,提取当前电影视频下所有镜头的特征向量。
[0027]
进一步地,所述步骤103包括如下具体步骤:为了获得镜头视频片段的特征向量f
n embedding
,使用预训练模型resnet50对图像进行特征提取,再将同一片段的图像特征进行拼接得到片段特征,其中resnet50的基本结构描述如下:
[0028]
resnet50模型由5个阶段组成,第1阶段是1个卷积操作,其余4个阶段都由bottleneck组成,第2至5阶段分别包含3、4、6、3个bottleneck;第1个阶段:输入为(n,h,w,c),其中n表示批量样本个数,h表示高度、w表示宽度、c表示通道数,h=224,w=224,c=3;该阶段包括4个先后操作:卷积,卷积核大小为7
×
7;batch normalization;relu和maxpooling,输出大小为(n,112,112,64);
[0029]
第2个阶段由3个bottleneck模块组成,每个bottleneck中经过三个卷积操作,卷积核大小分别为1
×
1,3
×
3,1
×
1,输入大小为(n,112,112,64),输出大小为(n,56,56,256);
[0030]
第3个阶段由4个bottleneck模块组成,每个bottleneck中经过三个卷积操作,卷积核大小分别为1
×
1,3
×
3,1
×
1,输入大小为(n,55,55,256),输出大小为(n,28,28,512);
[0031]
第4个阶段由6个bottleneck模块组成,每个bottleneck中经过三个卷积操作,卷积核大小分别为1
×
1,3
×
3,1
×
1,输入大小为(n,28,28,512),输出大小为(n,14,14,1024);
[0032]
第5个阶段由3个bottleneck模块组成,每个bottleneck中经过三个卷积操作,卷积核大小分别为1
×
1,3
×
3,1
×
1,输入大小为(n,14,14,1024),输出大小为(n,7,7,2048);
[0033]
训练:使用resnet50预训练模型;
[0034]
预测:输入为步骤102中得到的每个镜头片段中包含的图像,通过对resnet50中第5阶段得到的特征向量进行提取,提取之后将每个片段所包含的图像的特征向量进行拼接,拼接之后得到片段的特征向量f
n embedding
。
[0035]
进一步地,所述步骤104使用transformer模型进行视频片段的排序,使用transformer中的decoder部分来实现,使用多头注意力机制和mask实现下一视频片段的预测,模型的输入为步骤103中得到的视频片段的编码向量f
n embedding
,先对编码向量f
n embedding
加入positional encoding,将特征f
n embedding
的顺序位置信息记作p
nx
;在模型训练阶段,输入特征f
n embedding
与位置信息p
nx
,并使用mask方法来辅助实现训练过程,在训练过程中使用mask掩盖掉后续未知片段;在测试阶段,任意选定一个视频片段的特征作为初始片段p0,从视频资源集合中分别输入视频预测模型中,选择概率最大的作为第二个视频片段,以第一个和第二个视频片段特征作为已知输入,从视频资源中通过模型选择概率最大的第三个视频片段,并以此类推,直到合成一个完整的视频;transformer模型训练:通过adam随机梯度反向传播算法降低transformer训练损失函数值,得到最优解的模型;测试:将选定的作为开端的镜头特征作为输入,通过模型对一镜头的视频片段进行预测,直至完成当前电影场景内镜头视频的排序。
[0036]
进一步地,模型训练阶段的训练损失函数为交叉熵损失函数:
[0037][0038]
本发明的一种电影场景内镜头视频排序系统及方法具有以下优点:本发明以transnet、resnet50以及transformer为基础建立模型,实现对电影中镜头的剪辑合成。transnet对电影视频进行镜头边界帧的识别,然后按照镜头边界帧的时间节点实现电影镜
头片段的切分,使用resnet50对电影镜头片段进行表征;transformer则是对镜头片段顺序进行预测排序,当已知前序序列对其余片段进行预测判断为后续片段的概率,从而找到后续片段。在本发明中主要使用了transformer中的decoder部分,以此类推直到合成一个完整的视频。本发明可实现以每一个分镜的多个镜头作为输入,自动的从中选择一个最符合此视频风格的镜头并将其串联成一个完整的视频。
附图说明
[0039]
图1为本发明系统结构示意图;
[0040]
图2为本发明方法的流程图;
[0041]
图3为电影数据预处理模块整体架构图;
[0042]
图4为多图像时序特征生成模块整体架构图;
[0043]
图5为transfomer结构图;
[0044]
图6为镜头视频排序示例展示图。
具体实施方式
[0045]
为了更好地了解本发明的目的、结构及功能,下面结合附图,对本发明一种电影场景内镜头视频排序系统及方法做进一步详细的描述。
[0046]
如图1所示,本发明的一种电影场景内镜头视频排序系统,包括:
[0047]
电影数据预处理模块,包括镜头检测与分割,将输入的整个电影按照镜头进行切分;
[0048]
镜头特征提取模块,提取单个镜头的多个关键帧图像的内容特征;
[0049]
镜头排序模块,将一个场景下的图像时序特征进行组合为一组特征图,多个场景的多组特征图进行输入。选定一个视频片段作为初始片段,预测出下一个视频片段是其中的哪一个镜头,直至完成所有视频片段的排序。
[0050]
参照图2所示,本发明的一种电影场景内镜头视频排序的方法包括如下几个步骤:
[0051]
步骤101、通过transnet模型对输入的电影进行分割。
[0052]
本发明采用transnet模型对输入的电影进行镜头边界的检测,得到电影镜头的边界帧,再通过边界帧对电影视频进行切分。如图3所示,transnet算法的详情如下:
[0053]
transnet的输入为n帧长的电影视频,输出为预测得到的视频边界帧。transnet主要部分为ddcnn单元,共有4个ddcnn单元,其中4个单元的卷积运算均为3
×3×
3,每个单元的扩张率分别为1、2、4、8。输入的视频先经过4个ddcnn,将4个ddcnn得到的4个输出拼接起来,再经过1层池化层与2层全连接层,输出每一帧的判别结果。
[0054]
训练时,网络的输入为长度为n的完整电影视频,且被统一调整大小为n
×w×h×
3,其中w表示图像的宽度,h表示图像的高度。n帧序列视频帧通过4个ddcnn单元,再经过1层池化层和两层全连接层,最后输出n
×
2维向量,表示对每一帧图像是否为边界帧的判别。transnet的模型的训练具体为:训练集为n个编码向量图像帧的视频序列,通过随机梯度下降反向传播算法降低cross-entropy损失函数的损失值,具体loss函数如下:
[0055][0056]
训练:采用adam优化器,初始学习率为0.001。
[0057]
预测:对于按照上述步骤训练完成的transnet,输入任意电影m
test
全部帧,判断每一帧是否是镜头边界,进而得到边界帧,通过边界帧对视频进行划分进而获取每一个镜头的视频,用于步骤102。
[0058]
步骤102、使用transnet对步骤101中得到的镜头视频片段提取多帧图片。
[0059]
对校验后的镜头视频片段进行提取多帧图片,需要提取的内容包含第一帧、中间关键帧、结尾转场帧,将每个视频片段提取的帧进行拼接,用于表示该片段;以此组合成一个新的时序视频序列,以此方式来避免无效帧图片与减少重复帧图片,提高后续步骤的准确度、减少模型的计算量。在此步骤中具体使用的方法为将步骤101中的得到的每一镜头的边界帧分别作为该镜头片段的第一帧和结尾转场帧,中间关键帧为镜头片段中经过transnet之后的帧表征向量与其他帧的表征向量计算平均余弦相似度,其中余弦相似度最大的作为关键帧。余弦相似度的计算公式如下:
[0060][0061]
其中θ表示视频片段特征向量集合,a表示进行平均余弦相似度计算的视频片段特征向量,b表示视频片段集合θ中非a的视频片段的视频片段特征,m为集合θ的大小,n为单个特征向量的维度。
[0062]
通过该步骤,本发明用每个视频片段第一帧、中间关键帧、结尾转场帧组合得到的序列代表该视频片段。
[0063]
步骤103、基于resnet50对多图像进行特征提取并拼接获得视频片段特征。选定一个镜头作为起始镜头,将开始图像i
start
,中间关键帧图像i
middle1...n
,结尾转场图像i
end
送入resnet50预训练模型中,进行图像特征向量提取,然后经过concat操作连接第一帧、中间关键帧、结尾转场帧的特征向量,获得该镜头片段的特征向量f
nembedding
。重复以上步骤,提取当前电影视频下所有镜头的特征向量。具体的:
[0064]
如图4所示,该步骤输入步骤102中得到的镜头视频片段中的图片序列,输出镜头视频片段的特征。对输入的多图像时序序列中的每一图像使用resnet50预训练神经网络模型进行编码,获取每张图像的特征向量,将每个片段中的多张图像的特征向量进行拼接从而得到代表视频片段的特征向量f
n embedding
。
[0065]
为了获得镜头视频片段的特征向量f
n embedding
,使用预训练模型resnet50对图像进行特征提取,再将同一片段的图像特征进行拼接得到片段特征。其中resnet50的基本结构描述如下:
[0066]
resnet的核心思想是引入一个恒等快捷连接的结构,直接跳过一个或多个层。resnet50模型主要由5个阶段组成,第1阶段是1个卷积操作,其余4个阶段都由bottleneck组成,第2至5阶段分别包含3、4、6、3个bottleneck。下面对resnet50的5个阶段进行详细的描述:
[0067]
第1个阶段:输入为(n,h,w,c),其中n表示批量样本个数,h表示高度、w表示宽度、c表示通道数,h=224,w=224,c=3。该阶段包括4个先后操作:卷积,卷积核大小为7
×
7;batch normalization;relu和maxpooling。输出大小为(n,112,112,64)。
[0068]
第2个阶段由3个bottleneck模块组成,每个bottleneck中经过三个卷积操作,卷积核大小分别为1
×
1,3
×
3,1
×
1。输入大小为(n,112,112,64),输出大小为(n,56,56,256)。
[0069]
第3个阶段由4个bottleneck模块组成,每个bottleneck中经过三个卷积操作,卷积核大小分别为1
×
1,3
×
3,1
×
1。输入大小为(n,55,55,256),输出大小为(n,28,28,512)。
[0070]
第4个阶段由6个bottleneck模块组成,每个bottleneck中经过三个卷积操作,卷积核大小分别为1
×
1,3
×
3,1
×
1。输入大小为(n,28,28,512),输出大小为(n,14,14,1024)。
[0071]
第5个阶段由3个bottleneck模块组成,每个bottleneck中经过三个卷积操作,卷积核大小分别为1
×
1,3
×
3,1
×
1。输入大小为(n,14,14,1024),输出大小为(n,7,7,2048)。
[0072]
训练:本发明中使用resnet50预训练模型。
[0073]
预测:在本发明中输入为步骤102中得到的每个镜头片段中包含的图像,通过对resnet50中第5阶段得到的特征向量进行提取,提取之后将每个片段所包含的图像的特征向量进行拼接,拼接之后得到片段的特征向量f
n embedding
。
[0074]
步骤104、使用transformer模型对电影片段进行预测分类。
[0075]
随机选择某一镜头片段的特征向量作为视频镜头拼接的开端,将剩余镜头片段与其组合,判断剩余镜头片段是当前镜头片段特征向量下一特征向量的概率,概率最大的则为下一镜头场景。如图5所示,本发明使用了transformer模型。
[0076]
特征编码解码器transformer主要分为两个部分:编码器部分与解码器部分。编码器部分有n个相同的layer,每个layer由两个sub-layer组成,分别是multi-head self-attention和feed-forward network。其中每个sub-layer都增加了residual connection和normalization。因此可以将sub-layer的输出表示为:
[0077]
sub_layer_output=layernorm(x+(sublayer(x)))
[0078]
传统的attention可由以下形式表示:
[0079]
attention_output=attention(q,k,v)
[0080]
multi-head self-attention通过h个不同的线性变换对q,k,v进行投影,最后将不同的attention结果拼接起来:
[0081]
mulithead(q,k,v)=concat(head1,
…
,headh)wo[0082][0083]
self-attention中q、k、v相同。
[0084]
transformer中还采取了scaled dot-product,即:
[0085][0086]
feed-forward networks层进行非线性变换。
[0087]
decoder与encoder结构相类似,同样具有n个layer,不同之处在于decoder的
layer有三个sub-layer,相较于encoder,其多了一层masked multi-head attention。
[0088]
在本发明中,将transformer模型应用到图像领域,本发明中只使用transformer中的encoder。
[0089]
将步骤103中得到的图像特征向量作为输入,使用transformer的decoder进行训练。首先对输入的特征向量f
n embedding
加上位置信息p
nx
。在训练阶段,使用mask,当输入第一个和第二个镜头的图像特征时,对余下的镜头特征向量的位置信息进行mask操作,判断当前镜头是否为正确的镜头序列和同一风格的镜头。当输入为第一个,第二个,第三个镜头的特征时,对余下的镜头特征的位置信息进行mask操作,判断当前的三个镜头是否为正常排序和同一风格。训练损失函数为交叉熵损失函数:
[0090][0091]
训练:优化器采用adam optimizer,学习率为0.0001。
[0092]
预测:在步骤103中得到的片段中随机选取一个片段作为初始片段p0,输入到训练完的模型中,然后选取余下的片段作为其后续的片段,选取输出概率最大的一个片段作为其后续片段。如图6所示,继续使用transformer将选定的初始镜头和已经的预测的镜头作为输入,预测其他镜头特征向量是当前镜头序列的下一镜头特征向量的概率,概率最大的则为下一镜头场景,以此类推进行3、4、5、6
…
个片段的选择,直到合成一个完整的视频。
[0093]
本发明以transnet、resnet50以及transformer为基础建立模型,实现对电影中镜头的剪辑合成。transnet对电影视频进行镜头边界帧的识别,然后按照镜头边界帧的时间节点实现电影镜头片段的切分,在本发明中使用了transnet模型,但不限制于transnet模型,可以使用transnetv2进行同等替换;使用resnet50对电影镜头片段进行表征;transformer则是对镜头片段顺序进行预测排序,当已知前序序列对其余片段进行预测判断为后续片段的概率,从而找到后续片段。在本发明中主要使用了transformer中的decoder部分,以此类推直到合成一个完整的视频。
[0094]
可以理解,本发明是通过一些实施例进行描述的,本领域技术人员知悉的,在不脱离本发明的精神和范围的情况下,可以对这些特征和实施例进行各种改变或等效替换。另外,在本发明的教导下,可以对这些特征和实施例进行修改以适应具体的情况及材料而不会脱离本发明的精神和范围。因此,本发明不受此处所公开的具体实施例的限制,所有落入本技术的权利要求范围内的实施例都属于本发明所保护的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1