一种针对单故障情形的路由保护方法
1.本发明属于互联网域内路由保护方案的技术领域,具体涉及一种针对单故障情形的路由保护方法。
背景技术:
2.自上个世纪70年代诞生之日起,互联网进入飞速发展,互联网上涌现了大量的新兴应用和服务,他们对互联网的路由可用性提出了更高的要求。因此,互联网在设计之初就非常重视路由可用性,设计并使用了自适应的动态路由协议。然而,当网络中的故障发生时,路由协议都需要一定的收敛时间来完成路由重计算,在路由收敛期间,路由的一致性无法得到保证,从而引发路由环路、路由黑洞等现象,最终导致丢包及传输服务中断的发生。为此,业界提出利用lfa(loop free alternates)方案来应对网络中频繁出现的故障,lfa以其实现简单和支持增量部署而受到业界的青睐,然而,lfa并不能保护网络中所有可能出现的单故障情形。为了解决该问题,研究者提出了基于not-via地址的快速重路由算法,然而,该算法需要辅助地址的协助,且计算开销和存储开销较大,因此,该算法很难得到互联网服务提供商的支持。
技术实现要素:
3.研究表明,网络中绝大多数的故障为单故障,为了解决上述技术问题,本发明专注于解决网络中单故障情形,从而提出了一种针对单故障情形的路由保护方法。
4.为了方便描述,我们先定义一些标记,这些标记适用于整个发明。网络拓扑可以用g=(v,e)来表示,其中v代表网络拓扑中所有节点的集合,e用来表示网络拓扑中所有链路的集合。对于网络中的节点m∈v,n(m)表示节点m的邻居节点的集合,其中邻居节点不包括父亲节点,id(m)表示节点m的节点标识,priority(m)表示节点m的优先级,ancestor(m)表示节点m的所有祖先节点中跳数为2的节点。由于针对每个目的节点的计算过程是相同的,因此,假设目的节点为d。对于网络中的目的节点d∈v,并用rspt(d)表示以节点d为根的反向最短路径树。对于网络中的任意节点对m,d,用bn(m,d)表示节点m到节点d的备份下一跳集合。
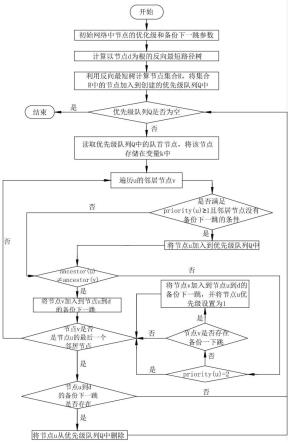
5.其技术方案为一种针对单故障情形的路由保护方法,包括以下步骤:
6.步骤1:对于网络中的节点目的节点d∈v,将节点m的优先级设置为0,即:priority(m)=0,将节点m到目的节点d的备份下一跳设置为空集,即:bn(m,d)=φ,其中priority(m)表示节点m的优先级,bn(m,d)表示节点m到节点d的备份下一跳,v表示网络中节点的集合;
7.步骤2:根据迪杰斯特拉算法计算以节点d为根的反向最短路径树rspt(d);
8.步骤3:利用反向最短路径树rspt(d)计算节点集合r,该集合中的节点满足步骤3:利用反向最短路径树rspt(d)计算节点集合r,该集合中的节点满足其中ancestor(u)表示节点u的所有祖先节点中跳数为2的节点,ancestor(v)表示节点v的所有祖先节点中跳数为2的节点,n(v)表示节点v的邻居节点
的集合,节点v表示节点u的邻居节点;
9.步骤4:创建一个优先级队列q,该队列q中元素的结构为(u,priority(u),id(u)),其中priority(u)表示节点u的优先级,id(u)表示节点u的节点标识;
10.步骤5:对于网络中的节点且该节点的优先级设置为2,并将该节点加入到优先级队列q中;
11.步骤6:判断优先级队列q是否为空,如果不为空,则执行步骤7,否则,则结束;
12.步骤7:读取优先级队列q中的队首节点u,并将该节点u存储在变量k中;
13.步骤8:遍历节点u的邻居节点v;
14.步骤9:判断是否满足priority(u)大于等于1且邻居节点v没有备份下一跳的条件,如果满足,则将邻居节点v加入到优先级队列q中,进一步执行步骤10,如果不满足,直接执行步骤10;
15.步骤10:判断ancestor(u)与ancestor(v)是否相同,如果ancestor(u)≠ancestor(v),则将节点v加入到节点u到d的备份下一跳bn(u,d)=bn(u,d)∪{v},执行步骤13,如果ancestor(u)=ancestor(v),则执行步骤11;
16.步骤11:判断节点u的节点优先级是否等于2,如果是,则执行步骤13,否则,执行步骤12;
17.步骤12:判断节点v是否存在备份一下跳,如果不存在,则直接执行步骤13,否则,将节点v加入到节点u到d的备份下一跳bn(u,d)=bn(u,d)∪{v},并将节点u的优先级设置为1,执行步骤13;
18.步骤13:判断节点v是否节点u的最后一个邻居,如果是,则执行步骤14,如果不是,执行步骤8,继续遍历其下一个邻居节点;
19.步骤14:判断节点u到d的备份下一跳是否存在,如果是,则将节点u从优先级队列q中删除,重新执行步骤6,否则,直接执行步骤6。
20.作为上述技术方案中进一步解释,其中步骤3中计算节点集合r的方法如下:
21.步骤3.1:创建一个队列m,将网络中的节点加入到该队列中;
22.步骤3.2:判断队列m是否为空,如果不为空,则执行步骤3.3,否则,执行步骤4;
23.步骤3.3:从m中取出一节点u,遍历该节点u的邻居节点,将该邻居节点存储在变量g中,执行步骤3.4;
24.步骤3.4:判断ancestor(u)与ancestor(v)是否相同,如果是,直接执行步骤3.6,否则,则将节点u和节点v的优先级设置为2,执行步骤3.5;
25.步骤3.5:判断节点u和节点v是否在集合r中,如果是,直接执行步骤3.6,否则,则将节点u和节点v加入到集合r,执行步骤3.6;
26.步骤3.6:判断节点v是否是节点u的最后一个邻居,如果是,则执行步骤3.2,否则,执行步骤3.3,继续遍历其下一个邻居节点。
27.作为上述技术方案中进一步解释,其中步骤7中优先级队列q的队首节点满足以下要求:
28.(1)该队首节点选取队列q中所有节点中优先级最大的节点;
29.(2)如果多个节点具有相同的优先级时,该队首节点为具有最小节点标识的节点。
30.与现有技术相比,本发明具有以下优点:1.本发明具有支持逐跳转发,支持增量部
署,不仅具有较小的路径拉伸度,还可以应对网络中所有可能的单故障情形的特征。2.本发明可以应对网络中任意的单故障情形,极大的提高了路由可用性,降低了由于故障导致的网络中断时间,提升了用户对网络性能的体验度。因此,本发明为互联网服务提供商解决路由可用性问题提供了一种有效的方案。
附图说明
31.图1是本发明实施例的流程示意图;
32.图2是本发明实施例中计算节点集合r的流程示意图;
33.图3是本发明实施例的网络拓扑结构g示意图;
34.图4是本发明实施例的rspt(d)示意图。
35.其中:在图3中,链路旁边的数字表示该链路对应的代价;
36.在图4中,实线表示树的链路,虚线表示网络中的链路。
37.为使本发明的技术方案和优点更加清楚,以下结合附图1和2的流程思路,对照附图3中的网络拓扑结构g对本发明作进一步地详细说明,下面详细说明本实施例的具体实现方式:
38.步骤1:对于网络中的节点a,b,c,e将这些节点的优先级设置为0,即priority(a)=priority(b)=priority(c)=priority(e)=0,将这些节点的备份下一跳设置为空集,即bn(a,d)=bn(b,d)=bn(c,d)=bn(e,d)=φ;
39.步骤2:对于目的节点d∈v,根据迪杰斯特拉算法计算以节点d为根的反向最短路径树rspt(d),如图4所示;
40.步骤3:计算节点集合r,方法如下:
41.步骤3.1:创建一个队列m,将网络中的节点加入到该队列中,此时队列m为m={a,b,c,e};
42.步骤3.2:因为队列m不为空,执行步骤3.3;
43.步骤3.3:此时u=a,m={b,c,e};
44.步骤3.4:遍历节点a的邻居节点,此时v=b;
45.步骤3.6:因为节点b不是节点a的最后一个邻居节点,所以执行步骤3.4;
46.步骤3.4:遍历节点a的邻居节点,此时v=c;
47.步骤3.5:因为ancestor(a)=a,ancestor(c)=c,所以r={a,c},priority(a)=priority(c)=2;
48.步骤3.6:因为节点c不是节点a的最后一个邻居节点,所以执行步骤3.4;
49.步骤3.4:遍历节点a的邻居节点,此时v=e;
50.步骤3.6:因为节点e是节点a的最后一个邻居节点,所以执行步骤3.2;
51.步骤3.2:因为队列m不为空,执行步骤3.3;
52.步骤3.3:此时u=b,m={c,e};
53.步骤3.4:遍历节点b的邻居节点,此时v=e;
54.步骤3.6:因为节点e是节点b的最后一个邻居节点,所以执行步骤3.2;
55.步骤3.2:因为队列m不为空,执行步骤3.3;
56.步骤3.3:此时u=c,m={e};
57.步骤3.4:遍历节点c的邻居节点,此时v=a;
58.步骤3.5:因为ancestor(a)=a,ancestor(c)=c,所以r={a,c},priority(a)=priority(c)=2;
59.步骤3.6:因为节点a不是节点c的最后一个邻居节点,所以执行步骤3.4;
60.步骤3.4:遍历节点c的邻居节点,此时v=e;
61.步骤3.5:因为ancestor(e)=a,ancestor(c)=c,所以r={a,c,e},priority(e)=2;
62.步骤3.6:因为节点e是节点c的最后一个邻居节点,所以执行步骤3.2;
63.步骤3.2:因为队列m不为空,执行步骤3.3;
64.步骤3.3:此时u=e,m={};
65.步骤3.4:遍历节点e的邻居节点,此时v=b;
66.步骤3.6:因为节点b不是节点e的最后一个邻居节点,所以执行步骤3.4;
67.步骤3.4:遍历节点e的邻居节点,此时v=c;
68.步骤3.5:因为ancestor(e)=a,ancestor(c)=c,所以r={a,c,e},priority(e)=priority(a)=priority(c)=2;
69.步骤3.6:因为节点c是节点e的最后一个邻居节点,所以执行步骤3.2;
70.步骤3.2:因为队列m为空,执行步骤4;
71.步骤4:创建一个优先级队列q,该队列中元素的结构为(u,priority(u),id(u));
72.步骤5:对于网络中的节点a,c,e,将这些节点的优先级设置为2,并且将这些节点加入到优先级队列q中,此时优先级队列q={(a,2,id(a)),(c,2,id(c)),(e,2,id(e)};
73.步骤6:因为优先级队列q此时不为空,则执行步骤7;
74.步骤7:读取优先级队列的队首节点,将该节点存储在变量u中,此时u=a;
75.步骤8:遍历节点a的邻居节点,将节点a的邻居节点存储在变量v中,此时v=b;
76.步骤9:因为priority(a)=2并且节点b没有备份下一跳,所以将节点b加入优先级队列,此时优先级队列q={(a,2,id(a)),(c,2,id(c)),(e,2,id(e),(b,0,id(b))};
77.步骤11:因为ancestor(a)=ancestor(b),priority(a)=2,所以执行步骤13:
78.步骤13:因为节点a还有邻居节点,所以执行步骤8;
79.步骤8:遍历节点a的邻居节点,将节点a的邻居节点存储在变量v中,此时v=c;
80.步骤9:priority(c)=2,因为节点c已经在队列中,所以不执行任何操作;
81.步骤10:因为ancestor(a)≠ancestor(c),所以将节点c加入到节点a到d的备份下一跳
82.bn(a,d)={c};
83.步骤13:因为节点a还有邻居节点,所以执行步骤8;
84.步骤8:遍历节点a的邻居节点,将节点a的邻居节点存储在变量v中,此时v=e;
85.步骤9:因为priority(e)=0,所以不执行任何操作:
86.步骤11:因为ancestor(a)=ancestor(e),priority(a)=2,所以执行步骤13;
87.步骤13:因为节点e是节点a的最后一个邻居节点,所以执行步骤14;
88.步骤14:因为节点a到d的备份下一跳存在,则将节点a从优先级队列q中删除,此时优先级队列q={(c,2,id(c)),(e,2,id(e),(b,0,id(b))};;
89.步骤15:执行步骤6。
90.步骤6:因为优先级队列q此时不为空,则执行步骤7;
91.步骤7:读取优先级队列的队首节点,将该节点存储在变量u中,此时u=c;
92.步骤8:遍历节点c的邻居节点,将节点c的邻居节点存储在变量v中,此时v=a;
93.步骤9:因为priority(c)=2并且节点a已经有备份下一跳,所以不执行任何操作:
94.步骤10:因为ancestor(a)≠ancestor(c),所以将节点a加入到节点c到d的备份下一跳
95.bn(c,d)={a};
96.步骤13:因为节点c还有邻居节点,所以执行步骤8;
97.步骤8:遍历节点c的邻居节点,将节点c的邻居节点存储在变量v中,此时v=e;
98.步骤9:因为priority(c)=2,节点e已经在队列中,所以不执行任何操作;
99.步骤10:因为ancestor(e)≠ancestor(c),所以将节点e加入到节点c到d的备份下一跳
100.bn(c,d)={a,e};
101.步骤13:因为节点e是节点c的最后一个邻居,所以执行步骤14;
102.步骤14:因为节点c到d的备份下一跳存在,则将节点c从优先级队列q中删除,此时优先级队列q={(e,2,id(e),(b,0,id(b))};
103.步骤15:执行步骤6。
104.步骤6:因为优先级队列q此时不为空,则执行步骤7;
105.步骤7:读取优先级队列的队首节点,将该节点存储在变量u中,此时u=e;
106.步骤8:遍历节点e的邻居节点,将节点e的邻居节点存储在变量v中,此时v=b;
107.步骤9:因为priority(e)=2,节点b已经在队列q中,所以不执行任何操作:
108.步骤11:因为ancestor(e)=ancestor(b),priority(e)=2,所以执行步骤13;
109.步骤13:因为节点e还有邻居节点,所以执行步骤8;
110.步骤8:遍历节点e的邻居节点,将节点e的邻居节点存储在变量v中,此时v=c;
111.步骤9:因为priority(e)=2,节点c已经有备份下一跳,所以不执行任何操作:
112.步骤10:因为ancestor(e)≠ancestor(c),所以将节点c加入到节点e到d的备份下一跳
113.bn(e,d)={c};
114.步骤13:因为节点c是节点e的最后一个邻居,所以执行步骤14;
115.步骤14:因为节点e到d的备份下一跳存在,则将节点e从优先级队列q中删除,此时优先级队列q={(b,0,id(b))};
116.步骤15:执行步骤6;
117.步骤6:因为优先级队列q此时不为空,则执行步骤7;
118.步骤7:读取优先级队列的队首节点,将该节点存储在变量u中,此时u=b;
119.步骤8:遍历节点b的邻居节点,将节点b的邻居节点存储在变量v中,此时v=e;
120.步骤9:因为priority(b)=0,所以不执行任何操作;
121.步骤11:因为ancestor(e)=ancestor(b),priority(b)=0,所以执行步骤12;
122.步骤12:因为节点e存在备份下一跳,所以将节点e加入到节点b到d的备份下一跳
bn(b,d)={e};并且将节点e的优先级设置为1;
123.步骤13:因为节点e是节点b的最后一个邻居,所以执行步骤14;
124.步骤14:因为节点b到d的备份下一跳存在,则将节点b从优先级队列q中删除,此时优先级队列q={};
125.步骤15:执行步骤6。
126.步骤6:因为优先级队列q此时为空,则结束。
127.以上显示和描述了本发明的主要特征和优点,对于本领域技术人员而言,显然本发明的具体实施方式并不仅限于上述示范性实施例所描述的细节,因此在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明的创造思想和设计思路,应当等同属于本发明技术方案中所公开的保护范围。因此,无论从哪一点来看,均应将本实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。
128.此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1