一种基于使用量预测的容器资源动态调度方法及系统与流程
1.本发明涉及容器资源调度技术领域,具体涉及一种基于使用量预测的容器资源动态调度方法及系统。
背景技术:
2.目前,越来越多的应用程序被部署在容器中。通常,为了使托管的应用程序可以安稳运行,我们都会为其调配充足的资源。但大多数情况下托管的应用程序不是以最高负载的状态运行,并且cpu、内存等各项资源也不会同时处于最高负载的状态,因此预先调配的资源在大多数时候会处于空闲状态,从而造成了资源的浪费。此外当应用处在负载较高的状态,预先分配的资源也不一定够用。目前容器中的应用都是依靠宿主机的操作系统进行资源分配、限制和设置权重。这样做会出现的问题就是:每个容器的资源分配权重和限制都是一开始固定的,不能进行动态调整,很容易造成资源的浪费以及出现资源不足的情况。
3.为了解决此类问题,在云计算中通常使用特定的预测算法来预测虚拟机和应用的资源需求,并提前做好资源分配优化,来提高资源的使用率和服务质量,帮助提前做好资源分配,优化docker的资源管理。在现有的kubernetes系统中,资源调度的工作主要由scheduler组件负责。在应用首次被调度时,由scheduler根据应用的资源配置情况,在集群内所有的node节点上选择一个最适合的node节点来部署,即静态调度策略,该调度机制虽然简单,却缺乏灵活性。首先,该机制只能在应用初次部署时进行资源配置,无法在应用运行时按需对已分配的资源进行动态调整,这样会导致主机资源使用率低。其次,由于缺乏对资源使用情况的预测,报警机制不能在资源指标违例之前发出警报,scheduler也不能对应用在出现资源消耗瓶颈之前进行资源调度或实例自动伸缩。而且scheduler没有考虑应用对资源的敏感程度,很容易造成node节点上对单一资源的瓶颈。因此必须从资源利用最大化、应用对资源的敏感度等角度出发来制定相应的资源管理机制和调度策略,使其能够在应用出现瓶颈之前就能预先触发资源动态调度和实例自动伸缩,从而提高系统资源的使用率,增加调度的灵活性。
技术实现要素:
4.本发明的目的在于提供一种基于使用量预测的容器资源动态调度方法及系统,能够提高系统资源的使用率,增加调度的灵活性,实现容器能够对部署在容器上的应用程序的资源需求预先响应。
5.实现本发明目的的技术解决方案为:
6.一种基于使用量预测的容器资源动态调度方法,包括步骤:
7.设置扩容或者缩容的阈值,并且设置缩容判断次数的阈值以及监控周期;
8.监控集群中的容器和每一个节点的资源使用情况,对每个节点的机器上的资源及容器进行实时的监控和性能数据采集,获取应用所有副本的资源指标及使用率;
9.基于资源指标及使用率聚合系统状态、系统资源指标和应用程序性能指标,并将
聚合好的数据保存到对应的文件中;
10.计算应用历史的负载序列数据,通过深度学习算法搭建容器资源使用量预测模型,对未来时刻的容器资源使用量进行预测;
11.根据预测得到的负载数据计算出下一周期期望的副本数,同时采用响应式的伸缩算法计算出当前期望的副本数,两者比较后确定最终的副本数作为hpa策略的输入,进行容器资源的动态收缩。
12.进一步地,所述性能数据包括cpu使用情况、内存使用情况、网络吞吐量以及文件系统的使用情况。
13.进一步地,所述监控集群中的容器和每一个节点的资源使用情况,对每个节点的机器上的资源及容器进行实时的监控和性能数据采集,获取应用所有副本的资源指标及使用率具体步骤为:
14.步骤2-1:heapster采用kubernetes从master节点获取系统中所有的节点信息列表;
15.步骤2-2:在每个节点中,kubelet使用cadvisor收集部署在该节点上的容器和整个物理节点的资源利用信息;
16.步骤2-3:获取每个节点的资源利用信息后,heapster将这些数据存储数据库中,在influxdb中新建一个名为“k8s”的数据库,通过grafana查询“k8s”数据库中的数据,并且将查询数据显示在图形界面上。
17.进一步地,所述基于资源指标及使用率聚合系统状态、系统资源指标和应用程序性能指标,并将聚合好的数据保存到对应的文件中具体包括步骤:
18.步骤3-1:使用kubernetes cli kubectl在系统中获取信息,从整个系统中检索有关节点、名称空间、pod和服务的信息;对于每个命名空间,比较每个pod和每个服务的标签,然后记录pod和服务的映射;
19.步骤3-2:通过influxdb中的http接口以及influxdb数据库的influxql语句从数据库中查询存储在数据库中的资源指标值;
20.步骤3-3:将查询的数据整理保存到json文件中。
21.进一步地,所述计算应用历史的负载序列数据为:采用动态加权的来计算每一个应用的负载,综合考虑到每一种资源指标,根据每一种资源指标的使用率进行加权计算,得出应用的综合负载序列数据。
22.进一步地,所述计算应用历史的负载序列数据具体包括步骤:
23.假设在采集到的数据中在某一时刻一个应用有n个pod副本,表示为p=[p1,p2,
…
,pd],每一个pod副本的资源请求量为r=[r1,r2,
…
,rd],资源使用量为q=[q1,q2,
…
,qd],另d=[1,2,3,
…
,d]表示每一个pod副本的资源维度;
[0024]
每一个应用的资源使用率表示为u=[u1,u2,
…
,ud],其计算公式如下:
[0025][0026]
每一维资源的权重为:
[0027][0028]
则综合负载为:
[0029][0030]
将上式计算的某一时刻的负载加入到负载队列中,直到负载队列里面的序列个数达到预先设置的大小时,更新负载队列,将最早的那个负载值从队列里面删除,将最新计算的负载值加入到负载队列里面。
[0031]
进一步地,所述容器资源使用量预测模型的输入为cpu使用率、内存使用量、网络使用量和磁盘使用量,输出为容器负载,其包括编码器和解码器;所述编码器由6个同构的网络层堆叠而成,每一个网络层包含有多头注意力子层和基于位置的前馈神经网络;所述解码器和编码器结构一致,在输入序列提取特征时采用的是masked多头注意力层,整个模型使用残差连接和规范化处理对各层输出优化。
[0032]
进一步地,所述容器资源使用量预测模型将模型输入数据预处理,得到输入x=[x1,x2,...,xn]
t
∈rn×d,其中,n表示时间窗口长度,d表示输入量维度,xi表示第i个时间点的系统性能数据,i=1,2,...,n,则每个时间点的系统性能数据的位置向量为:
[0033][0034][0035]
其中,pos表示输入序列x中每个时间序列数据的具体位置,i表示维度;
[0036]
每个系统性能数据的向量化为:
[0037]
rei=wei+pei[0038]
其中,wei表示输入x中第i个数据的值,pei表示x中第i个数据的位置向量;
[0039]
所述多头注意力子层为:
[0040]
multihead(q,k,v)=concat(head1,head2,...,headh)wo[0041][0042][0043]
其中,q为查询向量,k为键向量,v为值向量,q、k和v通过输入向量矩阵x乘以3个不同的权值矩阵wq,wk,wv得到:
[0044]
q=x
·
wq[0045]
k=x.wk[0046]
v=x.wv[0047]
所述前馈神经网络由两个线性变换组成,即ffn(x)=max(0,xw1+b1)w2+b2其中,w1和w2为状态矩阵,b1和b2为补偿参数;两个线性变换之间有一个relu的激活函数;
[0048]
所述编码器输出序列特征向量z=(z
a1
,z
a2
,...,z
an
);
[0049]
ffn(x)=max(0,xw1+b1)w2+b2[0050]
所述解码器解码时,首先使用masked多头注意力层得到连续表征向量z=(z
b1
,z
b2
,...,z
bn
),利用编码器输出序列特征向量得到的queries、keys和masked多头注意力层的连续表征向量的values进行多头注意力计算与翻译对齐,将源序列与目标序列的高层特征进行关联。
[0051]
进一步地,所述两者比较后将最终预测的副本数作为hpa策略的输入,进行容器资源的动态收缩具体为:如果当前期望的副本数大于当前应用的副本数,则将下一周期期望的副本数和当前期望的副本数中最大的一个作为hpa策略的输入;否则如果下一周期期望的副本数大于当前应用的副本数,则将下一周期期望的副本数作为hpa策略的输入;当下一周期期望的副本数和当前期望的副本数连续多次都小于当前应用的副本数,则将最后一次下一周期期望的副本数作为hpa策略的输入,进行容器资源的动态收缩。
[0052]
一种基于使用量预测的容器资源动态调度系统,包括容器资源使用量监控模块、数据聚合模块、容器资源使用量预测模块和自动伸缩模块,其中:
[0053]
所述容器资源使用量监控模块用于监控集群中的容器和每一个节点的资源使用情况,对每个节点的机器上的资源及容器进行实时的监控和性能数据采集,获取应用所有副本的资源指标及使用率;
[0054]
所述数据聚合模块基于资源指标及使用率聚合系统状态、系统资源指标和应用程序性能指标,并将聚合好的数据保存到对应的文件中;
[0055]
所述容器资源使用量预测模块用于计算应用历史的负载序列数据,并通过深度学习算法搭建的容器资源使用量预测模型,对未来时刻的容器资源使用量进行预测;
[0056]
自动伸缩模块根据预测得到的负载数据计算出下一周期期望的副本数,同时采用响应式的伸缩算法计算出当前期望的副本数,两者比较后确定最终的副本数作为hpa策略的输入,进行容器资源的动态收缩。
[0057]
与现有技术相比,本发明具有以下有益的技术效果:
[0058]
本发明采用基于transformer模型对平台应用资源使用量进行预测,并根据预测结果以容器的负载均衡、容器距离作为容器调度的目标构建容器资源的动态调度与均衡模型,实现容器资源的快速分配。该技术能够提高系统资源的使用率,增加调度的灵活性,实现容器能够对部署在容器上的应用程序的资源需求预先响应,相比传统基于先验知识的静态资源分配方式,可以最大程度提升资源的使用率。
附图说明
[0059]
通过参考附图会更加清楚的理解本发明的特征和优点,附图是示意性的而不应理解为对本发明进行任何限制,在附图中:
[0060]
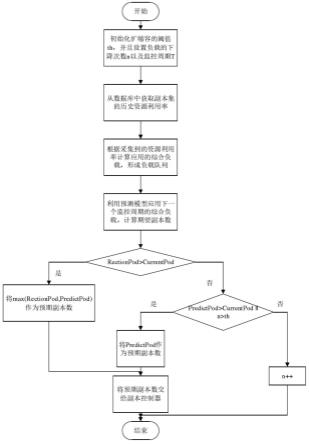
图1是本发明工作流程图。
[0061]
图2是本发明动态资源调度总体架构图。
[0062]
图3是本发明负载队列图。
[0063]
图4是本发明transformer模型图。
具体实施方式
[0064]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0065]
应用对容器资源要求并不是一成不变的,而是动态变化的,基于此,采用基于transformer的容器资源使用量预测模型对应用资源的使用进行预测,程序应用在不同时间节点对于cpu的使用率、内存使用量、网络使用量、磁盘使用量的需求也不相同,将这些资源的使用情况按时间序列进行采集,将其标准化后按合适的时间窗口整理成时序特征序列并将其输入到预测模型行中进行容器资源使用量预测;然后在预测结果的基础上计算出下一个周期期望的副本数,并与响应式的伸缩算法计算出当前期望的副本数进行比较,根据hpa策略进行容器资源动态调度,在保证可靠性的同时,达到提高系统的资源使用率、降低系统宕机风险的目的。
[0066]
本实施例提出一种基于使用量预测的容器资源动态调度系统,如图2所示,包括容器资源使用量监控模块、数据聚合模块、容器资源使用量预测模块和自动伸缩模块,下面对各模块具体为:
[0067]
(1)容器资源使用量监控模块
[0068]
该监控模块通过使用google的cadvisor工具来监控集群中的容器和每一个node节点的资源使用情况,对每个node节点的机器上的资源及容器进行实时的监控和性能数据采集,包括cpu使用情况、内存使用情况、网络吞吐量以及文件系统的使用情况。系统资源指标监视将使用以下过程:
[0069]
步骤1-1:heapster将使用kubernetes api从master节点获取系统中所有的节点信息列表。
[0070]
步骤1-2:在每个节点中,kubelet通过使用cadvisor收集部署在该节点上的容器和整个物理节点的资源使用率信息,包括资源指标及使用率。
[0071]
步骤1-3:收到有关每个节点的资源利用信息后,heapster会将这些数据存储数据库中,在influxdb中新建一个名为“k8s”的数据库。我们系统中部署的grafana将会查询“k8s”数据库中的数据,并且将这些数据展示在图形界面上。
[0072]
(2)数据聚合模块
[0073]
数据聚合模块用于集成系统状态(包括节点和pod),系统资源指标和应用程序性能指标。将聚合好的数据输入保存到对应的文件中。其具体的过程如下:
[0074]
步骤2-1:使用kubernetes cli kubectl在系统中获取信息。从整个系统中检索有关节点,名称空间,pod和服务的信息。对于每个命名空间,比较每个pod和每个服务的标签,然后记录pod和服务的映射。
[0075]
步骤2-2:通过influxdb中的httpapi接口以及influxdb数据库的influxql语句从数据库中查询存储在数据库中的资源指标值。
[0076]
步骤2-3:将步骤2中查询的数据整理保存到json文件中,以供后面的模块使用。
[0077]
(3)容器资源使用量预测模块
[0078]
在针对单一资源不能很好的衡量应用的负载问题,本文采用动态加权的来计算每
一个应用的负载,动态加权算法在计算应用的负载时,它会综合考虑到每一种资源指标,根据每一种资源指标的使用率进行加权计算,最终得出应用的综合负载。
[0079]
假设在采集到的数据中在某一时刻一个应用有n个pod副本,可以表示为p=[p1,p2,
…
,pd]每一个pod副本的资源请求量为r=[r1,r2,
…
,rd],资源使用量为q=[q1,q2,
…
,qd],其中d=[1,2,3,
…
,d]表示的是每一个pod副本的资源维度。
[0080]
每一个应用的资源使用率可以表示为u=[u1,u2,
…
,ud],其计算公式如下:
[0081][0082]
每一维资源的权重计算公式如下:
[0083][0084]
最终可以根据式计算应用的综合负载:
[0085][0086]
可以将上式计算的某一时刻的负载加入到如图3所示的负载队列中,直到负载队列里面的序列个数达到预先设置的大小时,更新负载队列,将最早的那个负载值从队列里面删除,将最新计算的负载值加入到负载队列里面,然后使用基于transformer的容器资源使用量预测模型对集群中的负载进行预测。
[0087]
如图4所示,transformer模型由编码器和解码器构成。编码器由6个同构的网络层堆叠而成,每一个网络层包含有多头注意力子层(multi-head attention)和基于位置的前馈神经网络(feed forward);解码器和编码器大体一致,不过在输入序列提取特征时采用的是masked多头注意力层,整个模型使用残差连接与对各层输出使用规范化来更好的优化网络。
[0088]
预测模型的输入为cpu使用率、内存使用量、网络使用量和磁盘使用量,输出为容器负载。将模型输入数据预处理后,得到输入x=[x1,x2,
…
,xn]
t
∈rn×d。其中,n表示时间窗口长度,d表示输入量维度,xi表示第i个时间点的系统性能数据,i=(1,2,
…
,n)。每个时间点的系统性能数据的位置向量的计算如下所示:
[0089][0090][0091]
其中,pos表示输入序列x中每个时间序列数据的具体位置,i表示维度。
[0092]
最后每个数据的向量化表示如下所示:
[0093]
rei=wei+pei[0094]
其中,wei表示输入x中第i个数据的值,pei表示x中第i个数据的位置向量。
[0095]
自注意力机制用于计算数据之间的相关程度,通常可以用查询向量(q)、键向量(k)和值向量(v)这三个向量进行描述,其中,q、k和v是通过输入向量矩阵x乘以3个不同的
权值矩阵wq,wk,wv得到,如下所示:
[0096]
q=x
·
wq[0097]
k=x
·
wk[0098]
v=x
·
wv[0099]
在获取自注意力信息时,首先利用q向量去查询所有的候选位置,每个候选位置会有一对k和v向量,查询的过程就是q向量和所有候选位置的k向量做点积运算的过程,点积结果经过softmax函数后加权到各自的v向量上,求和就得到了最终的自注意力结果,计算如下所示。
[0100][0101]
多头自注意力机制则相当于h个并行的自注意力层的集成,其计算方式如下所示:
[0102]
multihead(q,k,v)=concat(head1,head2,
…
,headh)wo[0103][0104]
然后经过基于位置的前馈神经网络(feed-forward network)处理,前馈神经网络由两个线性变换组成,ffn(x)=max(0,xw1+b1)w2+b2,其中,w1和w2为状态矩阵,b1和b2为补偿参数;两者之间有一个relu的激活函数。编码器输出序列特征向量z=(z
a1
,z
a2
,
…
,z
an
)。
[0105]
解码器(decoder)首先使用masked多头注意力(masked multi-head attention)计算后得到连续表征向量z=(z
b1
,z
b2
,
…
,z
bn
)。经过多头注意力与残差规范化处理后得到zb与编码器生成的特征向量za进行多头注意力计算;在这一步中利用编码器输出向量za得到的queries、keys和解码器得到的zb向量的values进行多头注意力计算与翻译对齐,也就是将源序列与目标序列的高层特征进行了关联,在编码器和解码器中都使用多头自注意力来学习序列的表示,然后通过同样的残差、规范化处理和基于位置的前馈网络处理以及线性优化和softmax一系列处理最终实现负载load的概率化输出。
[0106]
(4)自动伸缩模块
[0107]
根据容器资源使用量预测模块预测得到的负载数据计算出下一个周期期望的副本数,同时采用响应式的伸缩算法计算出当前期望的副本数b。如果采用的响应式计算出来的副本数b大于系统中当前应用的副本数c,则将预测的副本数a和响应式计算的副本数b中最大的一个作为hpa策略的输入;否则如果预测的副本数a大于系统中当前的副本数c,则将预测的副本数作为hpa策略的输入;当预测的副本数a和响应式的计算出来的副本数b连续多次(优选5次)都小于系统中当前的副本数c,则将最终预测的副本数a作为hpa策略的输入,进行容器资源的动态收缩。这样可以避免应用的负载出现抖动,而造成过早缩容,从而影响服务的质量。
[0108]
基于所述系统,如图1所示,一种基于使用量预测的容器资源动态调度方法,步骤如下:
[0109]
步骤1:设置扩容或者缩容的阈值,并且设置缩容判断次数的阈值th以及监控周期;
[0110]
步骤2:在每个监控周期通过监控模块获取应用所有副本的k个资源指标t个使用率;
[0111]
步骤3:根据步骤2采集的应用资源使用率,计算应用历史的负载序列数据;
[0112]
步骤4:使用transformer预测模型预测下一个监控周期的应用的负载,根据预测的负载计算期望的副本数predict pod,并且根据应用当前的负载计算期望的副本数rection pod,如果rection pod大于系统当前的副本数current pod,则将max(predict pod,rection pod)作为hpa(弹性伸缩)策略的输入,跳转至步骤7,否则转步骤5;
[0113]
步骤5:如果predict pod current pod或者n-th,则将predict pod作为hpa策略的输入并且重置负载预测下降的次数,跳转至步骤7,否则转步骤6;
[0114]
步骤6:负载预测下降的次数n自增一次;
[0115]
步骤7:根据输入的应用副本数触发动态伸缩。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1