分布式系统全局唯一ID生成方法、系统、设备及介质与流程
分布式系统全局唯一id生成方法、系统、设备及介质
技术领域
1.本技术涉及分布式系统id处理技术领域,尤其涉及一种分布式系统全局唯一id生成方法、系统、设备及介质。
背景技术:
2.在分布式系统中,常常需要对业务数据打上唯一标识。如订单系统有订单id,商品系统有商品id,用户系统中有用户id等。对于这类id,通常会存在以下要求:第一,id全局唯一或某类业务内唯一;第二,id单调递增,以满足排序和增量拉取的需求。
3.目前,生成全局唯一id最常见的方法主要有以下几类:第一类是强依赖存储系统(mysql、mongodb、redis等),对存储系统的性能要求很高,同时对存储系统的压力也很大,生成的id还是连续的,容易泄露商业机密,并且业务量大的场景还要进行分库分表,导致开发和运维效率较低。第二类是以snowflake算法为基础,不依赖任何存储系统,本地生成全局id,但这种方式需要人工指定机器id,并且对机器时钟非常敏感,存在时钟回拨问题;第三类是再第二类基础上对snowflake算法进行一些局部优化,可以自动获取工作机器id,但是这类方法只是不断创建新的工作机器id,对已经分配出去的机器id不能够复用和再分配,导致在pod重启频繁的kubernetes环境下容易造成机器id不够用的情况,从而无法生成全局唯一id。
技术实现要素:
4.本技术的目的在于提供一种分布式系统全局唯一id生成方法、系统、设备及介质,以解决现有基于snowflake算法生成全局id时存在的需要依赖人工分配工作机器id以及时钟回拨的问题。
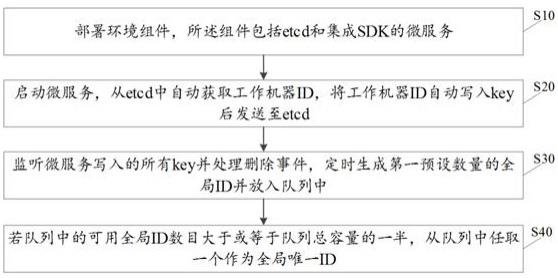
5.为实现上述目的,本技术提供一种分布式系统全局唯一id生成方法,包括:部署环境组件,所述组件包括etcd和集成sdk的微服务;启动微服务,从etcd中自动获取工作机器id,将工作机器id自动写入key后发送至etcd;监听微服务写入的所有key并处理删除事件,定时生成第一预设数量的全局id并放入队列中;若队列中的可用全局id数目大于或等于队列总容量的一半,从队列中任取一个作为全局唯一id。
6.进一步,作为优选地,所述定时生成第一预设数量的全局id并放入队列中,包括:基于改进的snowflake算法定时生成第一预设数量的全局id并放入队列中;其中,生成的全局id的时间戳为相对于某一时间基点的增量值。
7.进一步,作为优选地,所述的分布式系统全局唯一id生成方法,还包括:若队列中的可用全局id数目小于队列总容量的一半,异步生成第二预设数量的全局id并放入队列中,再从队列中任取一个作为全局唯一id。
8.进一步,作为优选地,所述将工作机器id自动写入key后发送至etcd,包括:在key中附带租约,并启动自动续约机制;若服务宕机,key在超时后会自动删除,且对应的工作机器id会被回收,并被分配至其他服务。
9.进一步,作为优选地,在所述启动微服务之前,还包括:在etcd中存放带有第一前缀、第二前缀以及第三前缀的key;所述第三前缀包括多种。
10.进一步,作为优选地,所述从etcd中获取工作机器id,包括:启动微服务,判断在etcd中是否能匹配带有第三前缀的其他key;若是,则将当前带有第三前缀的其他key作为工作机器id;若否,则在etcd中设置kv键值对,并以kv键值对中key对应的version值作为工作机器id。
11.进一步,作为优选地,所述version值会根据kv键值对中的value值的变化而递增。
12.本技术还提供一种分布式系统全局唯一id生成系统,包括:部署单元,用于部署环境组件,所述组件包括etcd和集成sdk的微服务;工作机器id获取单元,用于启动微服务,从etcd中自动获取工作机器id,将工作机器id自动写入key后发送至etcd;监听单元,用于监听微服务写入的所有key并处理删除事件,定时生成第一预设数量的全局id并放入队列中;全局唯一id生成单元,用于若队列中的可用全局id数目大于或等于队列总容量的一半,从队列中任取一个作为全局唯一id。
13.本技术还提供一种终端设备,包括:一个或多个处理器;存储器,与所述处理器耦接,用于存储一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上任一项所述的分布式系统全局唯一id生成方法。
14.本技术还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上任一项所述的分布式系统全局唯一id生成方法。
15.相对于现有技术,本技术的有益效果在于:本技术公开了一种分布式系统全局唯一id生成方法,包括部署环境组件:etcd和集成sdk的微服务;启动微服务,从etcd中获取工作机器id,将其自动写入key后发送至etcd;监听微服务写入的所有key并处理删除事件,定时生成第一预设数量的全局id并放入队列中;若队列中的可用全局id数目大于或等于队列总容量的一半,从队列中任取一个作为全局唯一id。
16.本技术使用嵌入式sdk的方式实现,所有的操作步骤都封装在sdk中,使用方只需集成本sdk 即可,使用方便且可适用范围广。本技术无需强依赖存储系统etcd,只在服务启动时从etcd中自动获取工作机器id,后续的全局唯一id只在本地计算完成。本技术不完全依赖本地机器时钟,而是使用未来时间来解决时钟回拨问题,同时使用异步预生成的方法来加快获取全局id的速度。此外本技术中通过利用微服务与etcd之间的租约的动态配合,
使得分配出去的工作机器id还可以回收复用,节约了开发成本。
附图说明
17.为了更清楚地说明本技术的技术方案,下面将对实施方式中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
18.图1是本技术某一实施例提供的snowflake算法的模型结构示意图;图2是本技术某一实施例提供的分布式系统全局唯一id生成方法的流程示意图;图3是本技术某一实施例提供的部署的系统架构示意图;图4是本技术某一实施例提供的针对kubernetes环境部署的系统架构示意图;图5是本技术某一实施例提供的改进的snowflake算法的模型结构示意图;图6是本技术又一实施例提供的分布式系统全局唯一id生成方法的流程示意图;图7是本技术某一实施例提供的分布式系统全局唯一id生成系统的结构示意图;图8是本技术某一实施例提供的终端设备的结构示意图。
具体实施方式
19.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
20.应当理解,文中所使用的步骤编号仅是为了方便描述,不对作为对步骤执行先后顺序的限定。
21.应当理解,在本技术说明书中所使用的术语仅仅是出于描述特定实施例的目的而并不意在限制本技术。如在本技术说明书和所附权利要求书中所使用的那样,除非上下文清楚地指明其它情况,否则单数形式的“一”、“一个”及“该”意在包括复数形式。
22.术语“包括”和“包含”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。
23.术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。
24.需要说明的是,现有生成全局唯一id的技术及其缺点一般包括以下内容:1)使用数据库自增主键作为全局id。
25.缺点:a) 每次都要向数据库插入一条记录,性能很差;b) 瓶颈在数据库,只能通过水平扩容不断叠加服务器来解决;c) id是连续递增的,容易被黑客算出下一个id,造成敏感信息泄露。
26.2)使用uuid作为全局id。
27.缺点:生成的id为字符串,没有任何语义,无法进行排序。
28.3)使用zookeeper的临时顺序节点作为id。
29.缺点:每次都要和zookeeper交互来生成id,网络开销和zookeeper本身会造成性
能较弱。
30.4)使用redis的incr自增命令来生成id。
31.缺点:id是连续递增的,容易被黑客算出下一个id,造成敏感信息泄露。
32.5)使用snowflake算法生成id。
33.缺点:a) 需要手动指定工作机器id,一旦业务集群很庞大的话,这项工作是不可接受的;b) 强依赖机器时钟,无法解决时钟回拨问题,即如果一台机器突然把时钟调整到以前的某个时间,则会出现重复id,这对业务系统来说是一大灾难。
34.6)使用其它存储系统的主键,如mongodb的objectid、elasticsearch的_id等。
35.缺点:和1)一样,瓶颈在存储系统。
36.7)使用数据库来生成一批id,将本次分配的id最大值max和步长step作为数据库的两个字段,每次请求都拿到一批id范围(max,max+step]。
37.缺点:id是连续递增的,容易被黑客算出下一个id,造成敏感信息泄露。
38.8)基于snowflake算法的分布式id。
39.缺点:虽然可以自动分配工作机器id,但不能复用,在重启频率高的kubernetes环境下,工作机器id很容易就耗尽,即使此时微服务数量很少,也分配不了工作机器id,导致无法生成全局唯一id。
40.因此,本技术针对依赖人工分配工作机器id以及时钟回拨问题,想要提供一种分布式系统全局唯一id生成方法。
41.为了帮助理解,首先对本技术中涉及的术语进行解释:snowflake算法:一种分布式id生成算法,把一个长整形字段(64位)拆成如图1所示的四段:其中,1 bit:指的是最高位且为符号位,数值始终为0;因为生成的id为正数,所以在二进制中要求第一个bit统一为0;41 bits:表示的是时间戳,41位的时间序列,精确到毫秒级,41位的长度可以使用69年;10 bits:记录工作机器id,10位的长度最多支持部署1024个节点;12 bits:12位的计数序列号,序列号即一系列的自增id,可以支持同一节点同一毫秒生成多个id序号,12位的计数序列号支持每个节点每毫秒产生4096个id序号。
42.etcd:一种高性能的k-v存储系统,每个key都有一个version,从1开始,每次对key的value进行修改version递增1。
43.租约:etcd中的一个对象,可以施加在某个key上,得到的效果就是租约到期后该key会自动删除。
44.自动续约:etcd的客户端可以对某个租约自动续期,比如一个租约是30s,会在1/3的租约期内(即第10秒),自动又续上30s,达到一个永不过期的效果。
45.kubernetes:一种容器编排解决方案。
46.pod:在 kubernetes中创建和管理的、最小的可部署的计算单元。
47.请参阅图2,图2提供了一种分布式系统全局唯一id生成方法的流程示意图。如图2
所示,该分布式系统全局唯一id生成方法包括步骤s10至步骤s40。各步骤具体如下:s10、部署环境组件,所述组件包括etcd和集成sdk的微服务。
48.本步骤中,首先部署系统架构中的组件,包括etcd和集成sdk的微服务;其中,图3为该方法下部署的系统架构示意图。如图3所示,etcd可以是etcd集群形式,用于获取、回收及复用工作机器id。sdk通常为嵌入式sdk,用来简化获取全局id的开发套件,使用者只需引入该sdk即可。
49.作为一优选的实施方式,本技术能够完美支持传统虚拟机以及kubernetes运行环境,尤其对kubernetes环境中pod经常重启、被驱逐等特点进行了考量,因此提供了如图4所示的针对kubernetes环境的系统部署结构。
50.s20、启动微服务,从etcd中自动获取工作机器id,将工作机器id自动写入key后发送至etcd。
51.在某一实施例中,在所述启动微服务之前,还包括:在etcd中存放带有第一前缀、第二前缀以及第三前缀的key;所述第三前缀包括多种。
52.需要说明的是,本实施例为启动服务前的前置说明,包括在etcd中存放三种key,具体地,这三种key可以为:第一种:key=“/operation/workerid”;第二种:key=“/operation/nodes/{ip}:{port}:{workerid}”;第三种:key=“/operation/reuse/workerid1”、“/operation/reuse/workerid2”、“/operation/reuse/workeridn”等。
53.然后,执行步骤s20,启动微服务,从etcd中自动获取工作机器id。
54.在某一具体地实施方式中,所述从etcd中获取工作机器id,包括:2.1)启动微服务,判断在etcd中是否能匹配带有第三前缀的其他key;2.2)若是,则将当前带有第三前缀的其他key作为工作机器id;2.3)若否,则在etcd中设置kv键值对,并以kv键值对中key对应的version值作为工作机器id。作为优选地,所述version值会根据kv键值对中的value值的变化而递增。
55.本实施例中,首先在etcd中获取例如以“/operation/reuse/”为前缀的key,只取第一条,如果找到了则将此key作为工作机器id返回;如果不存在此key,则在etcd中设置一个kv键值对,key=/operation/workerid,value=0(value可任意),然后获取此key的version值作为工作机器id返回。其中,version从1开始,会随着此key的value值修改而不断递增+1。
56.进一步地,微服务会将工作机器id自动写入key后发送至etcd。具体包括:a)在key中附带租约,并启动自动续约机制;b)若服务宕机,key在超时后会自动删除,且对应的工作机器id会被回收,并被分配至其他服务。
57.需要说明的是,本实施例中集成sdk的微服务启动时,会自动向etcd写一个kv键值对,key=/operation/nodes/。例如:本机ip:端口:workid(如/operation/nodes/192.168.3.1:9087:23),value任意,并附带租约,例如60s,同时启动自动续约机制。如果微服务突然宕机,此key在租约到期时
会被删除。然后把此工作机器id进行回收,分配给其他服务,达到复用的目的。
58.s30、监听微服务写入的所有key并处理删除事件,定时生成第一预设数量的全局id并放入队列中。
59.在某一示例性的实施例中,所述定时生成第一预设数量的全局id并放入队列中,包括:基于改进的snowflake算法定时生成第一预设数量的全局id并放入队列中;其中,生成的全局id的时间戳为相对于某一时间基点的增量值。
60.本实施例中,改进的snowflake算法的模型如图5所示,其中:1 bit:符号位,固定1位符号标识,即生成的id为正数。
61.31 bits:时间戳为31位,当前时间相对于时间基点"2016-01-01"的增量值,单位:秒,最多可支持约68年,位数可根据实际场景进行修改定制。
62.22 bits:工作机器id为22位,最多可支持约420w个节点同时在线,位数可根据实际场景进行修改定制。
63.10 bits:序列号为10位,每秒下的并发序列,可支持每秒1024个并发,位数可根据实际场景进行修改定制。
64.进一步地,sdk会监听etcd中以/operation/nodes/为前缀的key,如果有删除事件到来,会将删除key的workerid插入到一个新key中/operation/reuse/workerid。比如/operation/nodes/192.168.3.1:9087:23被删除,则会在etcd中插入一个新key,即/operation/reuse/23。
65.然后,sdk启动一个定时(例如每5分钟)线程,定时生成固定数量的全局id(=1024,10是序列号位数)放入一个队列中(最大容量3072),如果此时队列满了则忽略。需要说明的是,此处的时间戳不是真正的机器时间,而是使用一个基准时间戳为起点,不断递增得到,基准时间戳=当前时间减去“2016-01-01”的差值,单位为秒。
66.s40、若队列中的可用全局id数目大于或等于队列总容量的一半,从队列中任取一个作为全局唯一id。
67.若队列中的可用全局id数目小于队列总容量的一半,异步生成第二预设数量的全局id并放入队列中,再从队列中任取一个作为全局唯一id。
68.综上所述,本实施例基于etcd实现了工作机器id的自动获取,每个微服务启动时通过本方法的sdk向etcd中写入一个固定的key值,value任意,然后将此key的version作为工作机器id,每次修改该key的value,version+1。此外,本实施例通过使用未来的时间来解决时钟回拨问题,每个服务启动时获取新的工作机器id和当前时间戳,然后每次获取id时通过时间戳自增和序列号自增来解决时钟回拨问题。
69.在某一实施例中,还提供了获取全局唯一id的时序图,包括微服务与etcd的数据交互过程,如图6所示。其中,集成了嵌入式sdk的微服务需要先执行以下四步操作:1)获取工作机器id;2)将工作机器id写入一个key;3)监听所有微服务写入的key,处理删除事件;4)预生成一批全局id放入队列。
70.最后,微服务从队列中获取id,判断队列中的可用全局id数目是否小于队列总容
量的一半;若否,则从队列中直接任取一个作为全局唯一id;若是,则异步生成第二预设数量的全局id并放入队列中,再从队列中任取一个作为全局唯一id。
71.在某一实施例中,为了说明本方案的效果,将本方案和百度id做了一个压测分析,分析结果如表1所示。根据表1可知,本方案的吞吐量约760万/s,百度id吞吐量约650万/s,性能提升近16%。
72.表1吞吐量压测分析算法百度id本方案吞吐量6,581,6617,632,440请参阅图7,本技术某一实施例还提供一种分布式系统全局唯一id生成系统,包括:部署单元01,用于部署环境组件,所述组件包括etcd和集成sdk的微服务;工作机器id获取单元02,用于启动微服务,从etcd中自动获取工作机器id,将工作机器id自动写入key后发送至etcd;监听单元03,用于监听微服务写入的所有key并处理删除事件,定时生成第一预设数量的全局id并放入队列中;全局唯一id生成单元04,用于若队列中的可用全局id数目大于或等于队列总容量的一半,从队列中任取一个作为全局唯一id。
73.可以理解的是,本实施例提供的分布式系统全局唯一id生成系统用于执行如上述任一项实施例所提供的分布式系统全局唯一id生成方法,并实现与其相同的效果,在此不再进一步赘述。
74.请参阅图8,本技术某一实施例还提供一种终端设备,包括:一个或多个处理器;存储器,与所述处理器耦接,用于存储一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上所述的分布式系统全局唯一id生成方法。
75.处理器用于控制该终端设备的整体操作,以完成上述的分布式系统全局唯一id生成方法的全部或部分步骤。存储器用于存储各种类型的数据以支持在该终端设备的操作,这些数据例如可以包括用于在该终端设备上操作的任何应用程序或方法的指令,以及应用程序相关的数据。该存储器可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,例如静态随机存取存储器(static random access memory,简称sram),电可擦除可编程只读存储器(electrically erasable programmable read-only memory,简称eeprom),可擦除可编程只读存储器(erasable programmable read-only memory,简称eprom),可编程只读存储器(programmable read-only memory,简称prom),只读存储器(read-only memory,简称rom),磁存储器,快闪存储器,磁盘或光盘。
76.在一示例性实施例中,终端设备可以被一个或多个应用专用集成电路(application specific 1ntegrated circuit,简称as1c) 、数字信号处理器(digital signal processor,简称dsp) 、数字信号处理设备(digital signal processing device ,简称dspd)、可编程逻辑器件(programmable logic device,简称pld) 、现场可编程门阵列(field programmable gate array ,简称fpga) 、控制器、微控制器、微处理器或其他电
子元件实现,用于执行如上述任一项实施例所述的分布式系统全局唯一id生成方法,并达到如上述方法一致的技术效果。
77.在另一示例性实施例中,还提供一种包括计算机程序的计算机可读存储介质,该计算机程序被处理器执行时实现如上述任一项实施例所述的分布式系统全局唯一id生成方法的步骤。例如,该计算机可读存储介质可以为上述包括计算机程序的存储器,上述计算机程序可由终端设备的处理器执行以完成如上述任一项实施例所述的分布式系统全局唯一id生成方法,并达到如上述方法一致的技术效果。
78.以上所述是本技术的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本技术原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本技术的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1