一种基于分层策略的异构任务调度方法
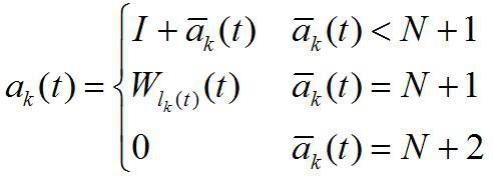
1.本发明涉及任务驱动下的通信传输,特别是涉及一种基于分层策略的异构任务调度方法。
背景技术:
2.近些年来,任务驱动下的通信传输成为了物联网领域的焦点。任务类型包括但不限于以信息年龄(age of information, aoi)为优化目标的时新型任务和以吞吐量为目标的数据型任务。相比基于预先划分信道资源这种传统调度方式,以信道资源共享为基础的联合调度算法能更好地迎合异构任务驱动通信的需求并极大地提升物联网的综合能效,但是,目前而言该问题是一个马尔科夫决策过程(markov decision process, mdp),并且存在高维状态和行动空间以及时变约束条件,并没有一个高效的解决方法,能够实现高维状态和行动空间以及时变约束条件下的异构任务调度。
技术实现要素:
3.本发明的目的在于克服现有技术的不足,提供一种基于分层策略的异构任务调度方法,适用于存在高维状态和行动空间以及时变约束条件的马尔科夫决策过程,有效实现了异构任务的联合调度。
4.本发明的目的是通过以下技术方案来实现的:一种基于分层策略的异构任务调度方法,包括以下步骤:s1.构建异构任务调度模型并确定调度的目标问题;步骤s1中所述的异构任务调度模型包括:设一个物联网系统中,有一个基站采用k个上行信道服务异构的两种任务,包括m个时新型任务和n个数据型任务;其中,第k个信道在第t个时隙选择服务的任务编号记为:如果,代表该信道在第t个时隙不会开启任何设备的数据传输;如果,代表该信道在第t个时隙开始服务第个时新型任务;如果,代表该信道在第t个时隙开始服务第个数据型任务;考虑服务一次第n个数据型任务需要占用信道个时隙,信道在被占用期间不能服务其他任务;用表征第k个信道在第t个时隙因为服务第n个数据型任务而被占用的情况:如果第k个信道在第t个时隙没有在服务第n个数据型任务,那么;否则,等于第k个信道距离服务完第n个数据型任务的剩余时隙数,也就是第k个信道被释放的时间。
5.步骤s1中所述确定调度的目标问题包括:
设优化目标有两个,第一个是时新型任务对应的信息年龄惩罚函数,其中是第m个时新型任务的信息年龄;第二个是数据型任务的吞吐量,其中第n个数据型任务在第t个时隙于第k个信道上产生的吞吐量为其中,为第k个信道的带宽,为基站端的信噪比,为第n个数据型任务在第t个时隙被第k个信道服务时对应的信道增益;吞吐量当第k个信道在第t个时隙开始服务或正在服务第n个数据型任务时才存在,目标问题总结为:务或正在服务第n个数据型任务时才存在,目标问题总结为:其中在x大于0的时候等于1,在x不大于0的时候等于0;同时,上述目标问题的解需要满足以下限制条件:的解需要满足以下限制条件:的解需要满足以下限制条件:(1.1)(1.2)(1.3)(1.4)其中,公式(1.1)为的更新方法,包括以下两种情况:一、如果至少有一个信道在第t个时隙服务了第m个时新型任务,即,那么时新型任务数据送达基站的概率为,此时;其中为单个信道在一个时隙内成功服务第m个时新型任务的概率;在x等于m的时候等于1,否则等于0;同时,时新型任务数据没有送达基站的概率为,此时;二、如果没有信道在第t个时隙服务了第m个时新型任务,即,则;公式(1.2)为的更新方法,包括三种情况:一、如果当前第k个信道正在服务第n个数据型任务,即,则在下个时隙,第k个信道的释放时间减少一个时隙;
二、如果当前第k个信道准备开始服务第n个数据型任务,即,则在下个时隙,第k个信道的释放时间为;三、如果当前第k个信道没有在服务也不准备服务第n个数据型任务,则的值为0;公式(1.3)为的更新方法,考虑具有平稳性和各态历经性,所以(1.3)成立,其中是一个常数;考虑,其中包含所有的取值,是一个有限实数集合;公式(1.4)给出了的取值约束,如果当前第k个信道正在服务数据型任务,即成立,则该信道不能再去服务其他任务,即;上述目标问题是一个具有高维状态和行动空间以及时变约束条件的马尔科夫决策过程,其中状态空间为,包含三个变量,定义为,,,行动空间为;其中,表示第n行第k列的元素,表示第n行第k列的元素;s2.构建基于分层策略的异构任务调度的离线学习模型;s201.搭建第一层策略模块,包含k个完全相同的深度强化学习模块,即drl模块, 其中第k个模块称为drlk;每一个drl模块包含一个评估行动网络,一个评估价值网络,一个目标行动网络,一个目标价值网络和一个经历缓存模块;第一层策略模块的搭建包括以下子步骤:s2011.搭建drlk模块的行动网络:评估行动网络的输入是,输出是一个整数,记为;其中,,表示中第k列元素构成的向量,,表示中第k列元素的和;评估行动网络包含一个全连接神经网络,其中为其参数;其中输入层节点数量为m+n+1,输出层节点数量为n+2,预先设定隐藏层数量、隐藏层节点以及激活函数(默认为两层隐藏层,64个节点,激活函数选择sigmod函数);在将送入参数为的全连接神经网络后,在输出层得到j+2个归一化后的输出值,对归一化的输出值采样即可得到的值;同时成立,令;目标行动网络和评估行动网络的结构完全一致,其参数用来表征;s2012.搭建drlk模块的价值网络:
评估价值网络的输入是和,其中,输出是的价值,记为;评估价值网络包含一个全连接神经网络,其参数用来表征,其中输入层节点数量为m+nk+k+1,输出层节点数量为1,预先设定隐藏层数量、隐藏层节点以及激活函数;目标价值网络和评估价值网络的结构完全一致,其参数用来表征,输出为;s2013.搭建drlk模块的经历缓存模块,每条经历包含,其中中(1.5)经历缓存模块用于缓存条经历;s2014.将集合中的值分别赋给k,并对于每一个k值都执行步骤s2011~s2014,完成第一层策略模块中所有drl模块的搭建;s202.构建第二层策略模块,该模块的输入为,输出为,该模块的搭建包含以下两个步骤;s2021.构建一个m行列的惠特尔指数表格,第m行第x列的元素通过求解以下方程得到其中其中通过求解以下方程组得到其中,为第m个时新型任务在时的惠特尔指数;为中间变量;s2022.基于惠特尔指数表格得到:通过下面的公式得到的值其中,为第t个时隙时,m个时新型任务中惠特尔指数排在第大的那个设备的编号,的等于中值等于n+1的元素的个数。
6.s3.进行离线训练得到成熟的模型;
s301.初始化,,并随机初始化;其中,即时的;由于第n行第k列的元素;而,其中包含所有的取值,是一个有限实数集合;故的每一个元素均随机取中的一个取值,即得到了随机初始化后的;s302.得到;s303.基于步骤s2021中惠特尔指数表格的构建方法,构建惠特尔指数表格;s304.令;s305.调用步骤s2011中搭建的评估行动网络,将作为的输入,得到第一层策略的输出;s306.基于步骤s2022中的计算方法,得到第二层策略的输出;s307.基于公式(1.1),(1.2),(1.3)得到,基于(1.5)得到;s308.执行步骤s2013,将新的m条经历分布缓存进m个drl的经历缓存模块;s309.如果,令并回到步骤s305,否则执行步骤s310;s310.对于每一个drl模块,从经历缓存模块中取出条经历;s311.基于条经历计算条经历计算s312.基于的值后向传播更新;s313.基于的值后向传播更新;s314.更新:,即:更新前的乘以0.9,然后再加上乘以0.1,得到的结果作为更新后的;s315.更新:,即:更新前的乘以0.9,然后再加上乘以0.1,得到的结果作为更新后的;s316.如果,令并回到步骤s305,否则结束循环,并将此时的值赋给,并构建出相应的评估行动网络,其中是一个给定的常数,表征最大学习轮数,初始值设置为10000。
7.s4.对训练得到的模型进行在线应用,实现异构任务调度:s401.初始化,,并观测得到的值:
在时刻,对第n个数据型任务在第t个时隙被第k个信道服务时对应的信道增益进行实时观测,并将其作为中第n行第k列的元素,时;最终得到观测的;s402.得到;s403.基于步骤s2021中惠特尔指数表格的构建方法,构建惠特尔指数表格;s404.令;s405.调用步骤s316中构建的评估行动网络,将作为的输入,得到第一层策略的输出;s406.基于步骤s2022中的计算方法,得到第二层策略的输出;s407.执行,即为第t个时隙的联合调度方案;s408.观测得到,令并回到步骤s405。
8.本发明的有益效果是:本发明提供的分层策略方法,适用于有高维状态和行动空间以及时变约束条件的马尔科夫决策过程,有效实现了异构任务的高效联合调度。
附图说明
9.图1为本发明的方法流程图;图2为基于分层策略的异构任务调度的离线学习模型原理图。
具体实施方式
10.下面结合附图进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下所述。
11.如图1所示,一种基于分层策略的异构任务调度方法,包括以下步骤:s1.构建异构任务调度模型并确定调度的目标问题;步骤s1中所述的异构任务调度模型包括:设一个物联网系统中,有一个基站采用k个上行信道服务异构的两种任务,包括m个时新型任务和n个数据型任务;其中,第k个信道在第t个时隙选择服务的任务编号记为 :如果,代表该信道在第t个时隙不会开启任何设备的数据传输;如果,代表该信道在第t个时隙开始服务第个时新型任务;如果,代表该信道在第t个时隙开始服务第个数据型任务;考虑服务一次第n个数据型任务需要占用信道个时隙,信道在被占用期间不能服务其他任务;用表征第k个信道在第t个时隙因为服务第n个数据型任务而被占用的情况:如果第k个信道在第t个时隙没有在服务第n个数据型任务,那
么;否则,等于第k个信道距离服务完第n个数据型任务的剩余时隙数,也就是第k个信道被释放的时间。
12.步骤s1中所述确定调度的目标问题包括:设优化目标有两个,第一个是时新型任务对应的信息年龄惩罚函数,其中是第m个时新型任务的信息年龄;第二个是数据型任务的吞吐量,其中第n个数据型任务在第t个时隙于第k个信道上产生的吞吐量为其中,为第k个信道的带宽,为基站端的信噪比,为第n个数据型任务在第t个时隙被第k个信道服务时对应的信道增益;吞吐量当第k个信道在第t个时隙开始服务或正在服务第n个数据型任务时才存在,目标问题总结为:务或正在服务第n个数据型任务时才存在,目标问题总结为:其中在x大于0的时候等于1,在x不大于0的时候等于0;同时,上述目标问题的解需要满足以下限制条件:的解需要满足以下限制条件:的解需要满足以下限制条件:(1.1)(1.2)(1.3)(1.4)其中,公式(1.1)为的更新方法,包括以下两种情况:一、如果至少有一个信道在第t个时隙服务了第m个时新型任务,即,那么时新型任务数据送达基站的概率为,此时;其中为单个信道在一个时隙内成功服务第m个时新型任务的概率;在x等于m的时候等于1,否则等于0;同时,时新型任务数据没有送达基站的概率为,此时;二、如果没有信道在第t个时隙服务了第m个时新型任务,即,则;
公式(1.2)为的更新方法,包括三种情况:一、如果当前第k个信道正在服务第n个数据型任务,即,则在下个时隙,第k个信道的释放时间减少一个时隙;二、如果当前第k个信道准备开始服务第n个数据型任务,即,则在下个时隙,第k个信道的释放时间为;三、如果当前第k个信道没有在服务也不准备服务第n个数据型任务,则的值为0;公式(1.3)为的更新方法,考虑具有平稳性和各态历经性,所以(1.3)成立,其中是一个常数;考虑,其中包含所有可能取值,是一个有限实数集合;公式(1.4)给出了的取值约束,如果当前第k个信道正在服务数据型任务,即成立,则该信道不能再去服务其他任务,即;上述目标问题是一个具有高维状态和行动空间以及时变约束条件的马尔科夫决策过程,其中状态空间为,包含三个变量,定义为,,,行动空间为;其中,表示第n行第k列的元素,表示第n行第k列的元素。
13.s2.构建基于分层策略的异构任务调度的离线学习模型,如图2所示;s201.搭建第一层策略模块,包含k个完全相同的深度强化学习模块(deep reinforcement learning, drl), 其中第k个模块称为drlk;每一个drl模块包含一个评估行动网络,一个评估价值网络,一个目标行动网络,一个目标价值网络和一个经历缓存模块;第一层策略模块的搭建包括以下子步骤:s2011.搭建drlk模块的行动网络:评估行动网络的输入是,输出是一个整数,记为;其中,,表示中第k列元素构成的向量,,表示中第k列元素的和;评估行动网络包含一个全连接神经网络,其中为其参数;其中输入层节点数量为m+n+1,输出层节点数量为n+2,预先设定隐藏层数量、隐藏层节点以及激活函数(默认为两层隐藏层,64个节点,激活函数选择sigmod函数);在将送入参数为的全连接神经网络后,在输出层得到j+2个归
一化后的输出值,对归一化的输出值采样即可得到的值;同时成立,令;目标行动网络和评估行动网络的结构完全一致,其参数用来表征;s2012.搭建drlk模块的价值网络:评估价值网络的输入是和,其中,输出是的价值,记为;评估价值网络包含一个全连接神经网络,其参数用来表征,其中输入层节点数量为m+nk+k+1,输出层节点数量为1,预先设定隐藏层数量、隐藏层节点以及激活函数;目标价值网络和评估价值网络的结构完全一致,其参数用来表征,输出为;s2013.搭建经历缓存模块,每条经历包含,其中 (1.5)经历缓存模块用于缓存条经历;s2014.将集合中的值分别赋给k,并对于每一个k值都执行步骤s2011~s2014,完成第一层策略模块中所有drl模块的搭建;s202.构建第二层策略模块,该模块的输入为,输出为,该模块的搭建包含以下两个步骤。
14.s2021.构建一个m行列的惠特尔指数表格,第m行第x列的元素通过求解以下方程得到其中其中通过求解以下方程组得到其中,为第m个时新型任务在时的惠特尔指数;为中间变量;s2022.基于惠特尔指数表格得到:
通过下面的公式得到的值其中,为第t个时隙时,m个时新型任务中惠特尔指数排在第大的那个设备的编号,的等于中值等于n+1的元素的个数。
15.s3.进行离线训练得到成熟的模型;s301.初始化,,并随机初始化;其中,即时的;由于第n行第k列的元素;而,其中包含所有的取值,是一个有限实数集合;故的每一个元素均随机取中的一个取值,即得到了随机初始化后的;s302.得到;s303.基于步骤s2021中惠特尔指数表格的构建方法,构建惠特尔指数表格;s304.令;s305.调用步骤s2011中搭建的评估行动网络,将作为的输入,得到第一层策略的输出;s306.基于步骤s2022中的计算方法,得到第二层策略的输出;s307.基于公式(1.1),(1.2),(1.3)得到,基于(1.5)得到;s308.执行步骤s2013,将新的m条经历分布缓存进m个drl的经历缓存模块;s309.如果,令并回到步骤s305,否则执行步骤s310;s310.对于每一个drl模块,从经历缓存模块中取出条经历;s311.基于条经历计算条经历计算s312.基于的值后向传播更新;s313.基于的值后向传播更新;s314.更新:,即:更新前的乘以0.9,然后再加上乘以0.1,得到的结果作为更新后的;s315.更新:,即:更新前的乘以0.9,然后再加上
乘以0.1,得到的结果作为更新后的;s316.如果,令并回到步骤s305,否则结束循环,并将此时的值赋给,并构建出相应的评估行动网络,其中是一个给定的常数,表征最大学习轮数,初始值设置为10000。
16.s4.对训练得到的模型进行在线应用,实现异构任务调度:步骤s3完成后, s201中构建的行动网络和价值网络都已完成学习,所述步骤s4包括以下子步骤:s401.初始化,,并观测得到的值:在时刻,对第n个数据型任务在第t个时隙被第k个信道服务时对应的信道增益进行实时观测,并将其作为中第n行第k列的元素,时;最终得到观测的;s402.得到;s403.基于步骤s2021中惠特尔指数表格的构建方法,构建惠特尔指数表格;s404.令;s405.调用步骤s316中构建的评估行动网络,将作为的输入,得到第一层策略的输出;s406.基于步骤s2022中的计算方法,得到第二层策略的输出;s407.执行,即为第t个时隙的联合调度方案;s408.观测得到,令并回到步骤s405。
17.上述说明示出并描述了本发明的一个优选实施例,但如前所述,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1