高α亚麻酸亚麻的制作方法
本申请要求2016年2月26日早先提交的美国临时申请序列号61/300,364的优先权,其通过引用整体并入本文。
本公开内容一般涉及一种亚麻植物栽培品种,其产生新的亚麻酸谱。描述了植物、油产品和栽培品种的独有基因。通过基因组谱进一步描述了产生具有高浓度α亚麻酸的种子的栽培品种。亚麻籽油的化学分析、基因组ssr、cdna和蛋白质测序用于描述该栽培品种。
背景技术:
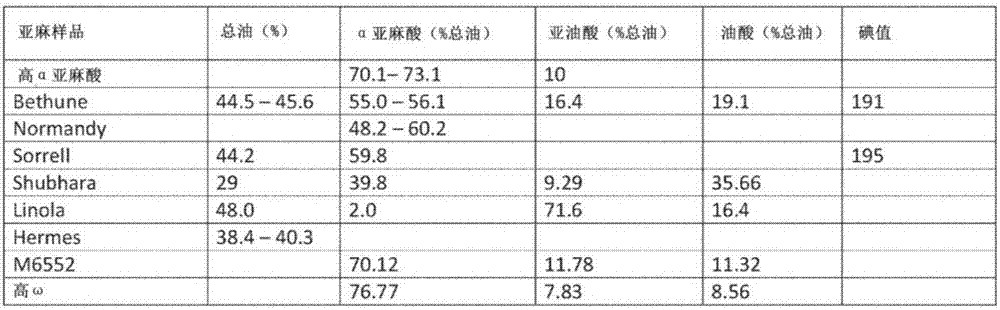
亚麻是一种一年生自花授粉的亚麻科植物,具有古老的人类使用历史。可以种植亚麻品种,茎用于制造纤维或种子用于榨油。纤维亚麻,如hermes,几乎不分枝,而油籽亚麻,如normandy、bethune、或sorrell,是高度分枝或浓密的。为了结合油籽亚麻和纤维亚麻的特征,一些努力正在进行。亚麻油是必需脂肪酸α亚麻酸(ala)和亚油酸(la)的天然来源。来自纤维亚麻或油籽亚麻的油的脂肪酸谱是每个品种的特征。例如,solin具有极低的α亚麻酸含量和较高的亚油酸含量。该品种旨在替代其他食用油。与solin相比,野生型normandy、bethune和sorrell具有较高的α亚麻酸含量(48至60%)和较低的亚油酸含量(16%)(图1)。与其他亚麻品种或栽培品种相比,高α亚麻酸亚麻具有极高的α亚麻酸含量(68%或更高)和较低的亚油酸含量(10%)(图1)。在wo2007/051302和fdagrn#256中更完整地描述了高α亚麻酸亚麻油的特征,两者均通过引用包括在本文中。
α亚麻酸也称为植物来源ω3(c18:3n3)。亚油酸也称为ω6脂肪酸或(c18:2n6)。α亚麻酸和亚油酸被称为必需脂肪酸,因为人体不能内源性地产生这些脂肪。个人必须在饮食中摄入这些脂肪酸。机体以多种方式使用这些脂肪酸,这些方式会影响总体健康状况,包括改善心血管功能、改善大脑和眼睛的发育、改善皮肤健康状况等。美国食品和药物管理局(fda)已批准高α亚麻酸亚麻油是一般认为安全的(gras)。高α亚麻酸亚麻油也有益于动物健康和生产。膳食中ala摄入量的增加减少牛的流产,改善马和狗的皮毛外观和健康,减少猪的断奶时间以及增加动物对疾病的抵抗力。高α亚麻酸亚麻也对工业用途有影响。在环氧化之后,高α亚麻酸含量导致环氧化天然油具有高于平均的环氧乙烷值。用环氧化高α亚麻酸制成的环氧树脂具有更快的干燥速度和更强、更耐化学性的键。类似地,基于高α亚麻酸亚麻油的醇酸树脂更耐溶剂、更强和更耐用。此外,这种高α亚麻酸亚麻油环氧树脂和醇酸树脂基于“绿色”化学,因此可用于替代旧技术并有益于环境。因此,高α亚麻酸亚麻油在人类健康、动物饲料和工业用油等多种领域具有经济重要性。
来自亚麻不同品种和栽培品种的油的α亚麻酸含量仅有一小部分原因由环境因素决定。较长的光周期生长期和较低的温度对于任何特定品种/栽培品种都会造成油中具有较高的α亚麻酸含量。然而,在大多数情况下,α亚麻酸含量是遗传决定的。具体地,成熟种子的α亚麻酸含量由fad3a和fad3b基因决定。这些基因编码ω3/δ15去饱和酶,这些酶能催化亚油酸中的双键产生α亚麻酸(图5)。与野生型normandyfad基因相比,solin是一种具有极低α亚麻酸含量的亚麻,在fad3a基因和fab3b基因中具有突变。这些突变导致截短的氨基酸序列,其产生无活性的fad去饱和酶蛋白质,随后导致低水平的α亚麻酸。
亚麻物种具有高度的可变性。已培育出多种栽培品种,每个品种都具有各种所需的特性。对亚麻基因组的遗传分析表明,该物种在遗传上适应了栽培品种的生产。多达20%的基因组由转座因子组成。它非常适合生产各种各样的argobotanic特征的栽培品种。因此,已经研究和开发了栽培品种的遗传描述方法。
亚麻基因组的整体可以通过简单重复序列区域的模式以及其他方法来表征。简单重复序列(ssr)区域(也称为微卫星或可变长度串联重复区域)是由重复的核苷酸单元组成的dna序列。该特定区域的总长度是可变的,这取决于核苷酸单元序列本身的长度和核苷酸单元重复的次数。在基因组中的许多基因座处发现ssr区域。每个ssr区域可以由不同的dna重复单元组成,并且可以具有不同的长度。每个基因座由独有的引物序列鉴定。每个基因座是多态的并且可以具有许多等位基因,即在任何一个特定基因座处的ssr区域在个体之间变化。该多态性导致一种基因组ssr区域的模式,其对于特定个体是特有的。ssr区域的特征和独有模式是遗传标记、dna指纹分析、亲子鉴定、个体识别、数量性状基因座定位、遗传多样性研究、关联映射和指纹图谱栽培品种的基础。在植物中,特征ssr区域用于栽培品种鉴定和dna变异的评估。在亚麻中,已经报道了28种ssr标记。对亚麻ssr标记的大规模研究确定了许多亚麻品种的谱系。基于ssr数据,高α亚麻酸亚麻形成新的种质。
最近理解的是,高α亚麻酸亚麻在各种营养和工业用途中是有用的和理想的。众所周知,α亚麻酸是人类和其他哺乳动物必需的油。还可以理解,含有65%或更高α亚麻酸的高α亚麻酸亚麻(亚麻仁)油可用于生产醇酸树脂环氧化油、涂料、油漆、搪瓷、清漆、防剥落表面混凝土防腐剂、固化亚麻仁油、马来酸化亚麻仁油、环氧树脂、油墨、玉米醇溶蛋白膜涂层和本领域技术人员可识别的其它有用的应用。与用野生型亚麻酸亚麻(亚麻仁)油制成的类似产品相比,高α亚麻酸的产品通常更强、更干燥。peterson和golas的美国专利9,179,660中充分描述了高α亚麻酸的工业和农业用途。
应理解,亚麻中亚麻酸还原为α亚麻酸是由fab3a基因和fab3b基因调节的,每个基因编码一个ω3/δ15去饱和酶。ω3/δ15去饱和酶能够催化亚油酸中双键的形成,以形成α亚麻酸。认为核酸序列中fab3a/b基因的修饰和/或基因调节被认为控制α亚麻酸的产生并调节α亚麻酸与亚油酸的比例。
存在一种对能够产生高α亚麻酸亚麻籽的亚麻植物的生物学特征的遗传表征的需要。这种植物适用于生产高α亚麻酸亚麻籽油,特别是其中18:3亚麻酸的含量为70%或更高,更优选高于75%的亚麻籽油。还期望栽培品种产生高α亚麻酸种子,而不是也含亚油酸和油酸的种子。这种植物也适用于作为亲本生产具有这些所需特征和其他表型的栽培品种。
技术实现要素:
高α亚麻酸亚麻的特征如ssr区和fad3a/b基因序列是独有的。本发明的一个实施例是高α亚麻酸亚麻植物的一组染色体,其特征在于基因组包含在由引物对seqidno:1和seqidno:2、seqidno:3和seqidno:4、seqidno:5和seqidno:6、seqidno:7和seqidno:8、seqidno:9和seqidno:10、seqidno:11和seqidno:12、seqidno:13和seqidno:14、seqidno:15和seqidno:16、seqidno:17和seqidno:18、seqidno:19和seqidno:20、seqidno:21和seqidno:22、seqidno:23和seqidno:24、seqidno:25和seqidno:26、seqidno:27和seqidno:28、seqidno:29和seqidno:30、seqidno:31和seqidno:32、seqidno:33和seqidno:34定义的基因座处,与栽培品种m6552的简单重复序列模式的碱基对长度具有85%、87.5%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相等性的简单重复序列模式;其中植物的种子具有大于65%、70%、71%、72%、73%、74%或75%(冷压油的重量%)的α亚麻酸含量。本发明的一个优选实施例与上述相似,其中由引物对seqidno:19和seqidno:20定义的简单重复序列模式大约等于226个碱基对,并且下列中的至少一个也是真的:由引物对seqidno:1和seqidno:2定义的简单重复序列模式等于或大于约231个碱基对;由引物对seqidno:2和seqidno:4定义的简单重复序列模式等于或大于约197个碱基对;以及,由引物对seqidno:9和seqidno:10定义的简单重复序列模式等于约371个碱基对。另一个优选实施例与第一个实施例相似,其中由引物对seqidno:13和seqidno:14定义的简单重复序列模式大于约305个碱基对。
本发明的另一个实施例是包含与seqidno:35中列出的fad3a基因的编码序列具有65%、70%、75%、80%、85%、87.5%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的核酸序列的核苷酸序列;其中所述序列编码具有足以用于从亚油酸合成α亚麻酸的脂肪酸去饱和酶活性的蛋白质。
本发明的另一个实施例是包含与seqidno:41中所列的fad3b蛋白的编码序列具有65%、70%、75%、80%、85%、87.5%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的核酸序列的核苷酸序列,其中所述序列编码具有足以用于合成α亚麻酸的脂肪酸去饱和酶活性的蛋白质。
本发明的另一个实施例是包含与seqidno:36中所列的fad3a蛋白的氨基酸序列具有65%、70%、75%、80%、85%、87.5%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的氨基酸序列的蛋白质,其中所述蛋白质能够催化亚油酸中双键的形成以产生α亚麻酸。
本发明的另一个实施例是包含与seqidno:42中所列的fad3b蛋白的氨基酸序列具有65%、70%、75%、80%、85%、87.5%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的氨基酸序列的蛋白质,其中所述蛋白质能够催化亚油酸中双键的形成以产生α亚麻酸。
本发明的另一个实施例是衍生自高α亚麻酸亚麻的cdna序列,其中所述cdna序列具有seqidno:35中所列的高α亚麻酸亚麻的fad3a的cdna所描述的至少约至少一个突变。本发明的本实施例更优选是用cdna转化的细胞,特别是植物细胞、酵母细胞或细菌细胞。最优选地,是包含具有seqidno:35所列cdna的细胞的多细胞生物。
本发明的另一个实施例是衍生自高α亚麻酸亚麻的cdna序列,其中所述cdna序列具有seqidno:41中所列的高α亚麻酸亚麻的fad3b的cdna所描述的至少约至少一个突变。本发明的本实施例更优选是用cdna转化的细胞,特别是植物细胞、酵母细胞或细菌细胞。最优选地,是包含具有seqidno:41所列cdna的细胞的多细胞生物。
本发明的另一个实施例是fad3a蛋白,其与befad3a.pro或nmfad3a.pro相比,包含图8所示nofad3a.pro的至少一个突变。更优选地,在本实施例中,fad3a蛋白还能够催化亚麻酸脂肪酸中双键的形成。甚至更优选该蛋白质包含在细胞中,并且最优选地,该实施例是包含含有该蛋白质的细胞的生物体。
本发明的另一个实施例是fad3b蛋白,其与befad3b.pro或nmfad3b.pro相比,包含图9所示nofad3b.pro的至少一个突变。更优选地,在本实施例中,fad3a蛋白质还能够催化亚麻酸脂肪酸中双键的形成。甚至更优选该蛋白质包含在细胞中,并且最优选地,该实施例是包含含有该蛋白质的细胞的生物体。
本发明的另一个实施例是linumusitatissium植物,其包含308bp的lu17ssr,并且其中α亚麻酸与总油相比的百分比大于约70.1%。更优选地,所述linumusitatissium植物还包含图3中“高α”一列所示的ssr的整个模式。
本发明的另一个实施例是高α亚麻酸亚麻植物,其具有seqidno:35和seqidno:41中列出的修饰基因,并且表达seqidno:36和seqidno:42中列出的氨基酸序列。在另一个实施例中,本发明的特征在于分离的核酸序列,其编码高α亚麻酸亚麻中的fad3a基因。
在另一个实施例中,本发明的特征在于分离的核酸序列,其编码高α亚麻酸亚麻中的fad3b基因。在本发明的再一个实施例中,fad3a基因和fad3b基因编码高α亚麻酸亚麻独有的氨基酸序列。由该氨基酸序列形成的蛋白质是去饱和酶,其催化双键的形成。具体而言,这些蛋白质去饱和酶催化亚油酸形成α亚麻酸。
本发明的另一个实施例是亚麻植物的栽培品种,其中亚麻籽包含大于60%、65%、70%或73%的α亚麻酸,大于5%、6%、7%、8%、9%、或10%亚油酸和大于5%、6%、7%、8%、9%或10%的油酸(冷压油的重量百分比)。
附图说明
为了更完整地理解本公开内容,应参考以下详细描述和附图进行理解,其中:
图1:不同亚麻(linumusitatissimum)栽培品种的典型总油含量和ω3α亚麻酸水平。
图2:在高α亚麻酸亚麻中测试的每个简单重复序列基因座的引物序列。其示出了seqidno:1-34。
图3:在各种亚麻品种中鉴定的每个基因座1o的等位基因的ssr区域的碱基对长度(bp),包括高α亚麻酸亚麻(m6552)、极低亚麻酸亚麻(linola)、中等亚麻酸亚麻(shubhara)、常规油籽亚麻(bethune、normandy、sorrell)和纤维亚麻(hermes)。
图4:m6552norcan的ssr区域与具有不同α亚麻酸含量的其他亚麻品种的比较。在各种亚麻品种中鉴定的每个基因座的等位基因的ssr区域的长度(bp),包括高α亚麻酸亚麻(m6552)、极低亚麻酸亚麻(linola)、中等亚麻酸亚麻(shubhara)、常规野生型油籽亚麻(bethune、normandy、sorrell)和纤维亚麻(hermes)。
图5:植物中的α亚麻酸和其他脂肪酸的合成。
图6:高α亚麻酸亚麻m6552(nofad3a.seq)(seqidno:35),野生型bethune(befad3a.seq)(seqidno:37)和野生型normandy(nmfad3a.seq)(seqidno:39)之间的fad3a基因核苷酸序列比对。
图7:高α亚麻酸亚麻m6552(nofad3a.pro)(seqidno:36),野生型bethune(befad3a.pro)(seqidno:38)和野生型normandy(nmfad3a.pro)(seqidno:40)之间的fad3a氨基酸序列比对。
图8:高α亚麻酸亚麻m6552(nofad38.seq)(seqidno:41),野生型bethune(befad3b.seq)(seqidno:43)和野生型normandy(nmfad38.seq)(seqidno:45)之间的fad3b基因核苷酸序列比对。
图9:高α亚麻酸亚麻m6552(nofad3b.pro)(seqidno:42),野生型bethune(befad3b.pro)(seqidno:44)和野生型normandy(nmfad3b.pro)(seqidno:46)之间的fad3b氨基酸序列比对。
图10:将m6552亚麻栽培品种与常规亚麻籽油进行比较的表格。
图11:将m6552亚麻栽培品种与其他植物油(如卡诺拉油菜油、玉米油、橄榄油、花生油、红花油、大豆油、向日葵油和核桃油)进行比较的表格。
图12:示出了m6552栽培品种的主要脂肪酸组分(包括α亚麻酸、亚油酸、油酸、硬脂酸和棕榈酸)的分子式的表格。
虽然在附图中示出了特定实施例,但是应理解本公开旨在是说明性的,这些实施例不旨在限制在此描述和说明的本发明。
具体实施方式
除非另外定义,否则本文使用的所有技术术语和科学术语具有与本发明所属领域的普通技术人员通常理解的含义相同的含义。尽管与本文描述的那些类似或等同的任何方法和材料可用于本发明的实践或测试,但现在描述优选的方法和材料。在整个说明书中,种子和油以某些化合物的百分比来描述,这些百分比基于冷压油或来自种子的冷压油的重量百分比。
定义:
术语“高亚麻酸亚麻仁油”和“高亚麻酸亚麻籽油”和“高α亚麻酸亚麻(亚麻仁)油”在本文中可互换使用,是指油,例如未改性或天然油,即油从亚麻籽中提取后未进行化学、酶促或其他改性以增加其α亚麻酸含量,其来自占总脂肪酸含量至少65%的α亚麻酸的亚麻籽,或65-95%α亚麻酸、65-94%α亚麻酸、65-93%α亚麻酸、65-92%α亚麻酸、65-91%α亚麻酸、65-90%α亚麻酸、65-89%α亚麻酸、65-88%α亚麻酸、65-87%α亚麻酸、65-86%α亚麻酸、65-85%α亚麻酸、65-84%α亚麻酸、65-83%α亚麻酸、65-82%α亚麻酸、65-81%α亚麻酸、65-80%α亚麻酸、65-79%α亚麻酸、65-78%α亚麻酸、65-77%α亚麻酸、65-76%α亚麻酸、65-75%α亚麻酸、65-74%α亚麻酸、65-73%α亚麻酸、65-72%α亚麻酸、65-71%α亚麻酸、65-70%α亚麻酸、65-69%α亚麻酸、65-68%α亚麻酸、65-67%α亚麻酸、65-66%α亚麻酸、67-95%α亚麻酸、67-94%α亚麻酸、67-93%α亚麻酸、67-92%α亚麻酸、67-91%α亚麻酸、67-90%α亚麻酸、67-89%α亚麻酸、67-88%α亚麻酸、67-87%α亚麻酸、67-86%α亚麻酸、67-85%α亚麻酸、67-84%α亚麻酸、67-83%α亚麻酸、67-82%α亚麻酸、67-81%α亚麻酸、67-80%α亚麻酸、67-79%α亚麻酸、67-78%α亚麻酸、67-77%α亚麻酸、67-76%α亚麻酸、67-75%α亚麻酸、67-74%α亚麻酸、67-73%α亚麻酸、67-72%α亚麻酸、67-71%α亚麻酸、67-70%α亚麻酸、67-69%α亚麻酸、67-68%α亚麻酸、70-95%α亚麻酸、70-94%α亚麻酸、70-93%α亚麻酸、70-92%α亚麻酸、70-91%α亚麻酸、70-90%α亚麻酸、70-89%α亚麻酸、70-88%α亚麻酸、70-87%α亚麻酸、70-86%α亚麻酸、70-85%α亚麻酸、70-84%α亚麻酸、70-83%α亚麻酸、70-82%α亚麻酸、70-81%α亚麻酸、70-80%α亚麻酸、70-79%α亚麻酸、70-78%α亚麻酸、70-77%α亚麻酸、70-76%α亚麻酸、70-75%α亚麻酸、70-74%α亚麻酸、70-73%α亚麻酸、70-72%α亚麻酸、或70-71%α亚麻酸。
如本文所述的具有大于65%α亚麻酸的高α亚麻酸亚麻(亚麻仁)油通过冷压高α亚麻酸亚麻籽而不使用溶剂或己烷来制备。这种全天然工艺粉碎高α亚麻酸亚麻(亚麻仁)籽以产生油。高α亚麻酸亚麻(亚麻仁)油天然含有如本文所述的高α亚麻酸含量。如美国专利第6,870,077号和pct申请wo03/064576所述、并通过引用并入本文,具有大于65%的α亚麻酸含量的高α亚麻酸亚麻籽是细心的植物育种和田间选择的结果。如本领域技术人员所理解的,美国专利第6,870,077号和pct申请wo03/064576可与其他亚麻品种一起繁殖,以产生具有如其中所述的其他所需性状的新型高α亚麻酸品种。
术语“低亚麻酸亚麻(亚麻仁)油”和“常规亚麻(亚麻仁)油”和“普通亚麻(亚麻仁)油”和“非高亚麻酸(亚麻仁)油”在本文中可互换使用,是指来自α亚麻酸含量低于65%的亚麻籽的油。
术语“亚麻籽油”和“亚麻仁油”在本文中可互换使用,均指从亚麻植物(linumusitatissimum)的种子获得的相同的油。
如本文所用,术语“共轭双键”是本领域公认的,包括含有共轭双键的共轭脂肪酸(cfa)。例如,共轭双键在由式--ch.dbd.ch--ch.dbd.ch--表示的相对位置包括两个双键。共轭双键通过碳1和4的饱和形成添加剂化合物,从而在碳2和3之间产生双键。
如本文所用,术语“脂肪酸”是本领域公认的,包括基于长链烃的羧酸。脂肪酸是包括甘油酯在内许多脂质的组分,其可以是饱和的或不饱和的。“不饱和”脂肪酸在碳原子之间含有顺式双键。“多不饱和”脂肪酸含有多于一个的双键,并且双键排列在亚甲基中断系统中(--ch.dbd.ch--ch.sub.2--ch.dbd.ch。
本文通过编号系统描述脂肪酸,其中冒号前的数字表示脂肪酸中的碳原子数,而冒号后的数字是存在的双键数。就不饱和脂肪酸来说,其后面括号中的数字,表示双键的位置。括号中的每个数字是通过双键连接的两个较低编号的碳原子。例如,亚油酸可以描述为18:2(9,12),表示18个碳原子、在碳9和碳18上有一个双键、在碳9和碳12上分别有两个双键;油酸可以描述为18:1(9)。
如本文所用,术语“共轭脂肪酸”是本领域公认的,包括含有至少一组共轭双键的脂肪酸。生产共轭脂肪酸的方法是本领域公认的,包括例如类似于去饱和的方法,其可以在现有脂肪酸底物中引入一个额外的双键。
如本文所用,术语“亚油酸”是本领域公认的,包括18碳多不饱和脂肪酸分子(c17h29cooh),其含有2个双键(18:2(9,12))。术语“共轭亚油酸”(cla)是具有顺式或反式构型的共轭双键的亚油酸的一组位置异构体和几何异构体的通用术语。
如本文所用,术语“去饱和酶”是本领域公认的,包括负责将共轭双键引入酰基链的酶。在本发明中,例如,来自linumusitatissimum的ω-3去饱和酶/δ15去饱和酶是可以在亚油酸的15位引入双键的去饱和酶。
如本文所用,术语“在严格条件下杂交”旨在描述杂交和洗涤的条件,其中彼此明显相同或同源的核苷酸序列保持彼此杂交。优选地,该条件使得彼此至少约70%,更优选至少约80%,甚至更优选至少约85%、90%或95%相同的序列保持彼此杂交。这种严格条件是本领域技术人员已知的,尤其可以在《当前分子生物学技术(currentprotocolsinmolecularbiology)》,ausubel等人编辑,约翰威立国际出版公司(johnwiley&sons,inc)(1995),第2、4和6部分中找到。其他严格条件可参见《分子克隆:实验室手册(molecularcloning:alaboratorymanual)》,sambrook等人,冷泉港出版社(coldspringharborpress),纽约冷泉港(1989),第7、9和11章。严格杂交条件的优选的非限制性实例包括在约65-70℃下4×氯化钠/柠檬酸钠(ssc)中杂交(或在约42-50℃下4×ssc加50%甲酰胺中杂交),然后在约65-70℃下1×ssc中洗涤一次或多次。高度严格杂交条件的优选的非限制性实例包括在约65-70℃下1×ssc中杂交(或在约42-50℃下1×ssc加50%甲酰胺中杂交),然后在约65-70℃下0.3×ssc中洗涤一次或多次。降低的严格杂交条件的优选的非限制性实例包括在约50-60℃下4×ssc中杂交(或在约40-45℃下6×ssc加50%甲酰胺中杂交),然后在约50-60℃下2×ssc中洗涤一次或多次。上述值中间的范围,例如65-70℃或42-50℃,也包括在本发明的范围内。在杂交和洗涤缓冲液中,sspe(1×sspe是0.15mnacl,10mmnah2po4和1.25mmedta,ph7.4)可以代替ssc(1×ssc是0.15mnacl和15mm柠檬酸钠);杂交完成后,每次洗涤15分钟。本领域技术人员还将认识到,可以将另外的试剂添加到杂交和/或洗涤缓冲液中以减少核酸分子与膜的非特异性杂交,例如硝酸纤维素或尼龙膜,包括但不限于阻断剂(例如,bsa或鲑鱼或鲱鱼精子载体dna)、去污剂(例如sds)、螯合剂(例如edta)、聚蔗糖、pvp等。当使用尼龙膜时,特别是,严格杂交条件的另一个优选的非限制性实例是在约65℃下在0.25-0.5mnah2po4,7%sds中杂交,然后在0.02mnah2po4,1%sds中洗涤一次或多次,参见例如church和gilbert(1984)《美国国家科学院院刊(proc.natl.acad.sci.usa)》81:1991-1995,(或者0.2×ssc,1%sds)。
如本文所用,“同一性百分比”是两个核酸序列或两个氨基酸序列的相关性的数学比较,包括可称为多肽或蛋白质的较长氨基酸序列。可以使用数学算法完成序列的比较和两个序列之间的同一性百分比的确定。本领域技术人员将认识到有几种可接受的确定同一性百分比的方法。在一个优选的实施例中,使用needleman和wunsch(《分子生物学杂志(j.mol.biol.)》(48):444-453(1970))算法确定两个氨基酸序列之间的同一性百分比,该算法已被纳入gcg软件包(可从www.gcg.com获得)中的gap程序,使用blosum62矩阵或pam250矩阵,其空位权重为16、14、12、10、8、6或4,长度权重为1、2、3、4、5或6。在又一个优选实施例中,两个核苷酸序列之间的同一性百分比使用gcg软件包(可从www.gcg.com获得)中的gap程序,用nwsgapdna.cmp矩阵来确定,其空位权重为40、50、60、70或80,长度权重为1、2、3、4、5或6。与gap程序结合使用的参数的优选的非限制性实例包括blosum62评分矩阵,其空位罚分为12,空位延伸罚分为4,移码空位罚分为5。在另一个实施例中,使用e.meyers和w.miller的算法(《生物科学中的计算机应用(comput.appl.biosci.)》,4:11-17(1988))确定两个氨基酸或核苷酸序列之间的同一性百分比,该算法已被纳入align程序(版本2.0或版本2.0u),使用pam120权重残基表,其空位长度罚分为12,空位罚分为4。
本领域技术人员充分理解,序列同一性的许多水平可用于鉴定来自其他物种的多肽或天然或合成修饰的多肽,其中此类多肽具有相同或相似的功能或活性。同一性百分比的有用实例包括但不限于50%、55%、60%、65%、70%、75%、80%、85%、90%或95%,或50%至100%的任何整数百分比。实际上,50%至100%的任何整数氨基酸同一性均可用于描述本发明,例如51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%。
应用于植物细胞的术语“基因组”不仅包括在细胞核内发现的染色体dna,还包括在细胞的亚细胞组分(例如,线粒体或质体)内发现的细胞器dna。
如本文所用,“密码子修饰的基因”或“密码子优选的基因”或“密码子优化的基因”是具有密码子使用频率的基因,其设计用于模拟宿主细胞的优选密码子使用频率。
“等位基因”是占据染色体上给定基因座的基因的几种替代形式之一。当存在于染色体上给定基因座的所有等位基因相同时,该植物在该基因座处是纯合的。如果存在于染色体上给定基因座的等位基因不同,则该植物在该基因座处是杂合的。
“转基因”是通过转化程序引入基因组的基因。转基因可以,例如编码一种或多种蛋白质或未翻译成蛋白质的rna。然而,本发明的转基因不需要编码蛋白质和/或未翻译的rna。在本发明的某些实施例中,转基因包含一种或多种嵌合基因,包括包含,例如目的基因、表型标记、选择标记和用于基因沉默的dna的嵌合基因。
如本文所用,术语“基因座”是指基因组上对应于可测量特征(例如,性状)的位置。snp基因座由与基因座内包含的dna杂交的探针定义。
如本文所用,术语“标记”是指可用于鉴定具有特定等位基因的植物的基因或核苷酸序列。标记可以描述为给定基因组基因座的变异。遗传标记可以是短dna序列,例如围绕单个碱基对变化的序列(单核苷酸多态性或“snp”)。在优选的用途中,术语“标记”是指在表征特定等位基因的一个或多个特定基因座处的ssr图谱。
多态性:等位基因间遗传序列的变异。一个例子是单核苷酸多态性,其中等位基因之间的基因序列仅被一个核苷酸改变。
如本文所用,术语“ssr”是指简单重复序列或微卫星。基因序列的区域由重复的核苷酸或特定基因序列(短简单序列)的重复单元组成,在所有真核基因组中作为高度重复的元件出现。简单序列基因座通常显示出广泛的长度多态性。这些简单序列长度多态性(sslp)可以通过聚合酶链反应(pcr)分析检测,并用于鉴定试验、人口研究、连锁分析和基因组作图。发现ssr处的特定基因座通过dna的引物序列进行鉴定。每个特定基因座的ssr长度是典型和独有的,可用于鉴定linumusitatissimum中的栽培品种。如本文所用,术语“卫星”、“小卫星”、“微卫星”、“短串联重复序列”、“stp”、“可变数目串联重复序列”、“vntp”和“简单重复序列”都被认为是ssr的同义词。
栽培品种:一种植物的栽培出的品种,其被特意选择用于特定的所需特征,例如花的颜色、抗病性、作物产量等。为了本专利的目的,本文描述的基因序列对于linumusitatissimum的栽培品种是典型和独有的,该栽培品种是为了成熟种子的油中的高α亚麻酸含量而故意培养的。
引物:为了本专利的目的,引物是dna的短链,其在17个不同基因座的每一个处与目的dna杂交。本文使用的引物列表包括在图2中。
基因座:为了本专利的目的,基因座是ssr区域所在的染色体上的特定dna序列。高变的:ssr或微卫星区域是高变的,因为重复单元的总数可以变化,即ssr区域的总长度可以变化。
一些作者区分术语亚麻仁(linseed)和亚麻籽(flaxseed),其他人则没有。对于一些人,亚麻仁可能表示用于油、人类食品、牲畜和宠物食品的亚麻,而亚麻籽这一术语表示用于纤维的亚麻。然而,其他人将亚麻仁称为用于工业用途、油漆、环氧树脂和粘合剂的亚麻,而亚麻籽作为用于人类食品、牲畜和宠物食品的亚麻。为了本专利的目的,术语亚麻仁和亚麻籽可互换使用,用于描述用于任何目的的亚麻,即用于油、人类食品、宠物食品、纤维、工业用油、涂料、环氧树脂、粘合剂等。
亚麻植物
亚麻是一种自花授粉的二倍体物种,染色体数目为2n=30。亚麻栽培品种是纯合的。纤维亚麻的亚麻基因组已被完全表征。高α亚麻酸亚麻是使用常规植物育种方法开发的。这些方法涉及连续几代的近亲繁殖,并且是本领域技术人员公知的。高α亚麻酸亚麻定义为亚麻栽培品种,其产生含有65%、70%、75%或更高α亚麻酸的油的种子。图1提供了高α亚麻酸亚麻的脂肪酸谱和特征。为了比较,图1中提供了不同品种的总油含量/脂肪酸谱/α亚麻酸含量的实例。亚麻的不同品种和栽培品种产生含有具有不同ala水平和不同脂肪酸谱的油的种子。成熟种子中ala的水平受fad3a基因和fad3b基因的活性的影响强烈,所述fad3a基因和fad3b基因编码产生具有催化双键功能的多肽或蛋白质的氨基酸序列。此外,高α亚麻酸亚麻的基因组的特征在于简单重复序列区域的独特模式。
与野生型bethune(befad3a.seq)序列相比,高α亚麻酸亚麻m6552(nofad3a.seq)的cdna序列含有两个缺失。第一个缺失是距离atg40bp的6个核苷酸。此缺失不会改变开放阅读框架。第二个缺失是从翻译起始位点起在260处的2个碱基对缺失。该第二个缺失导致阅读框架改变和位置306处的提前终止密码子。来自高α亚麻酸亚麻m6552(nofad3a.seq)的fad3a基因预计产生只有100个氨基酸的截短和改变的蛋白质。相比之下,来自野生型nomandy亚麻的fad3a基因含有一个874个碱基对的突变,将精氨酸密码子(cga)转化为终止密码子(tga)。这种野生型normandy亚麻fad3a基因预计产生291个氨基酸的截短的fad3a去饱和酶蛋白。与野生型bethune亚麻(befad3b.seq)相比,来自高α亚麻酸亚麻m6552(nofad3b.seq)的fad3b基因含有7个取代突变。这些突变位于位置28(a到g)、700(a到g)、8991o(a到g)、1170(c到t)、1174(t到c)和1175(g到c)。这些点突变改变了氨基酸:丙氨酸到苏氨酸(28)、缬氨酸到异亮氨酸(700)、精氨酸到组氨酸(899)、脯氨酸到半胱氨酸(1174和1175)。这些取代不会改变开放阅读框架,但预计会产生具有改变残基的fad3b去饱和酶蛋白质。来自高α亚麻酸亚麻m6552(nofad3b.pro)蛋白的fad3b蛋白可能仍然保留酶活性。在异源系统如酵母中测试该克隆的生物学和底物特异性可以为该基因与独有的高α亚麻酸油籽亚麻谱之间的任何可能的联系提供重要的见解。相比之下,野生型normandy的fad3b去饱和酶基因(nmfad3b.seq)在距离起始位点162bp处含有取代突变,其将trp密码子(tgg)转化为终止密码子(tga)。该基因预计产生仅具有53个氨基酸的截短的fad3b蛋白,并且可能不起作用。
fad3基因
fad3基因编码内质ω-3/δ-15去饱和酶,一种负责将亚油酸(c18:2)去饱和为亚麻酸(c18:3)的酶。在亚麻植物中,据报道特别是两种fad3基因(fad3a和fad3b)控制亚麻酸含量。fad3a和fad3b显示出高度保守性,具有约95%的同一性。在亚麻的低亚麻酸栽培品种中,这些基因已被证明是无活性的。
与befad3a(wt)序列相比,nofad3acdna序列含有两个缺失:第一个是位于距atg40bp处的6个核苷酸缺失,该缺失保持开放阅读框架;然而,在从翻译起始位点260处的长度2bp的第二个缺失导致在306处阅读框的改变和移位以及提前终止密码子。
nofad3a基因预计产生仅100aa的截短和改变的蛋白质。
与befad3b(wt)相比,nofad3b基因包含位于28(a到g)、700(a到g)、899(a到g)、1170(c到t)、1174(t到c)和1175(g到c)的7个取代突变。这些点突变改变了氨基酸:ala到thr(28)、val到ile(700)、arg到his(899)、pro到cys(1174和1175)。这些取代不改变开放阅读框架,但点突变改变fad3b蛋白质的几个位置的氨基酸密码子。已经证明nofad3b蛋白保留了酶活性。
ssr区域
一个ssr(简单重复序列)是一个基因组基因座,其包含通常2至7个核苷酸的重复序列元件。每个序列元件,即重复单元,在一个ssr内至少重复一次。亚麻的ssr序列的实例包括但不限于:(aat)5x、(tc)6x、(ta)8x、(tta)5x、(gag)6x、(tat)5x、(ttc)6x、(ctc)5x、(ta)6x、(at)10x。
在某些情况下,重复单元串联重复,如上所示。在其他情况下,重复单元可以通过插入碱基或缺失来分开,条件是至少在一种情况下重复单元串联重复一次。这些被称为“不完美重复”、“不完整重复”和“可变重复”。
ssr基因座优选用于确定同一性,因为这些标记可以实现强大的统计分析。个体可以在ssr基因座处具有不同数量的重复单元和序列变异。这些差异被称为“等位基因”。每个ssr基因座通常具有多个等位基因。随着分析的ssr基因座的数量增加,任何两个个体具有相同组等位基因的概率变得非常小。
ssr等位基因通常按其包含的重复单元数分类。例如,对于特定ssr基因座指定为12的等位基因将具有12个重复单元。不完整重复单元用整数后面的小数点表示,例如12.2。
本发明涉及高α亚麻酸亚麻中的简单重复序列区域基因标记,其产生含有至少65%、70%或75%ω3脂肪酸α亚麻酸(c18:3)的种子。高α亚麻酸亚麻可通过典型和独有的简单重复序列区域识别。在高α亚麻酸亚麻中测试的每个ssr区域的基因座与独有的引物序列相关(图2)。高α亚麻酸亚麻(高α)、常规野生型亚麻(bethune、normandy、sorrell)、低亚麻酸亚麻(linola)、中等亚麻酸亚麻(shubhara)和纤维亚麻(hermes)的每个基因座中的简单重复序列区域的长度表明,每种类型的亚麻都具有独有的ssr区域长度特征模式(图3)。高α亚麻酸亚麻、常规野生型亚麻(bethune、normandy、sorrell)、低亚麻酸亚麻(linola)、中等亚麻酸亚麻(shubhara)和纤维亚麻(hermes)之间ssr区域长度的比较表明,高α亚麻酸亚麻具有独有的ssr区域,即ssr区域与其他类型的亚麻不相同(图4)。基于ssr区域数据,高α亚麻酸亚麻在遗传上明显不同于“常规”亚麻、低亚麻酸亚麻和纤维亚麻。
如本领域技术人员所理解的,在本发明的一些实施例中,提供了高α亚麻酸亚麻的基因组,其特征在于在特定基因座处独有的简单重复序列模式,如图3所示,其中来自所述亚麻的种子的α亚麻酸含量为65%、70%或75%或更高。
如本领域技术人员所理解的,在本发明的一些实施例中,提供了一种通过在指定基因座处独有的简单重复序列模式鉴定亚麻品种为高α亚麻酸亚麻的方法,如图3所示,其中来自所述亚麻的种子的α亚麻酸含量为65%、70%或75%或更高。
在本发明的另一个方面,提供了一种纯化的或分离的核酸分子,其包含如图6所示的核苷酸序列。如本领域技术人员所理解的,该核酸分子编码从高α亚麻酸亚麻中分离的fad3a基因,其中该fad3a基因编码用于合成α亚麻酸的脂肪酸去饱和酶。
在本发明的另一个方面,提供了一种分离的或纯化的核酸分子,其包含如图8所示的核苷酸序列。对于本领域技术人员显而易见的是,核苷酸序列编码从高α亚麻酸亚麻中分离的fad3b基因,其中该fad3b基因编码用于合成α亚麻酸的脂肪酸去饱和酶。
在本发明的另一个方面,提供了一种分离的或纯化的多肽,其包含如图7所示的氨基酸序列。如本领域技术人员所理解的,该多肽由分离自高α亚麻酸亚麻的fad3a基因编码,其中该氨基酸序列产生独有的具有催化双键形成作用的多肽或蛋白质。
在本发明的另一个方面,提供了一种分离的或纯化的多肽,其包含如图9所示的氨基酸序列。如本领域技术人员所理解的,该多肽由分离自高α亚麻酸亚麻的fad3b基因编码,其中该氨基酸序列产生独有的具有催化双键形成作用的多肽或蛋白质。
虽然上面已经描述了本发明的优选实施例,但是应该认识到并理解,可以在其中进行各种修改,并且所附权利要求旨在覆盖可以落入本发明的精神和范围内的所有这些修改。
在一个实施例中,本发明的核酸分子包含长度至少为(或不大于)50-100、100-200、200-300、300-400、400-500、500-600、600-700、700-800、800-900、1000-1100、1100-1181或更多核苷酸的核苷酸序列,并在严格杂交条件下与seqidno:35和/或seqidno:41的核酸分子的互补物杂交。
m6552栽培品种
m6552亚麻栽培品种是在位于加拿大马尼托巴省莫登市的加拿大农业和农业食品部的莫登研究站开发的。m6552亚麻籽油天然地由三酰基甘油酯形式的脂肪酸混合物组成。m6552亚麻籽中的脂肪酸部分主要是70±3%的α亚麻酸(ala),10±2%的亚油酸(la),12±2%的油酸,4±2%的硬脂酸和4±2%的棕榈酸。如图10的表所示,将栽培品种m6552亚麻籽油与常规亚麻籽油进行比较。在图11的表中,还将其与其他植物油如卡诺拉油菜油、玉米油、橄榄油、花生油、红花油、大豆油、向日葵油和核桃油进行比较。将m6552亚麻籽油加工并制备成液体油。m6552亚麻籽油是脂肪酸的混合物,主要以三酰基甘油酯的形式存在。脂肪酸主要是α亚麻酸、亚油酸、油酸、硬脂酸和棕榈酸。在存在的脂肪酸中,α亚麻酸占68-73%,亚油酸占9-12%,油酸占9-14%,硬脂酸占2-6%,棕榈酸占3-6%。少量(1-2%)存在的其他组分包括甾醇、生育酚、色素和其他微量成分。m6552亚麻籽油是脂肪酸的混合物。α亚麻酸、亚油酸、油酸、硬脂酸和棕榈酸的分子式以及主要脂肪酸组分在本文中描述并列于图12中。
与befad3a(wt)序列相比,nofad3acdna序列含有两个缺失:第一个是距离atg40bp处的6个核苷酸缺失,它不改变开放阅读框架;第二个是在从翻译起始位点起260处的2bp缺失,导致阅读框架的改变和在306处的提前终止密码子。
预测nofad3a基因预计产生只有100aa的截短和改变的蛋白质。
与befad3b(wt)相比,nofad3b基因包含位于28(a到g)、700(a到g)、899(a到g)、1170(c到t)、1174(t到c)和1175(g到c)的7个取代突变。这些点突变改变了氨基酸:ala到thr(28)、val到ile(700)、arg到his(899)、pro到cys(1174和1175)。这些取代没有改变开放阅读框架,但预计会产生具有改变残基的fad3b蛋白。
已经证明nofad3b蛋白仍保留酶活性——据信nofad3b有助于独有的norcan油谱。
- 还没有人留言评论。精彩留言会获得点赞!