控制农业生产区域的制作方法
本申请要求于2016年11月2日提交的澳大利亚临时专利申请no2016904465和2017年10月9日提交的澳大利亚完整专利申请no2017245290的优先权,其内容通过引用并入本文。
本发明涉及用于控制农业生产区域的系统和方法。
背景技术:
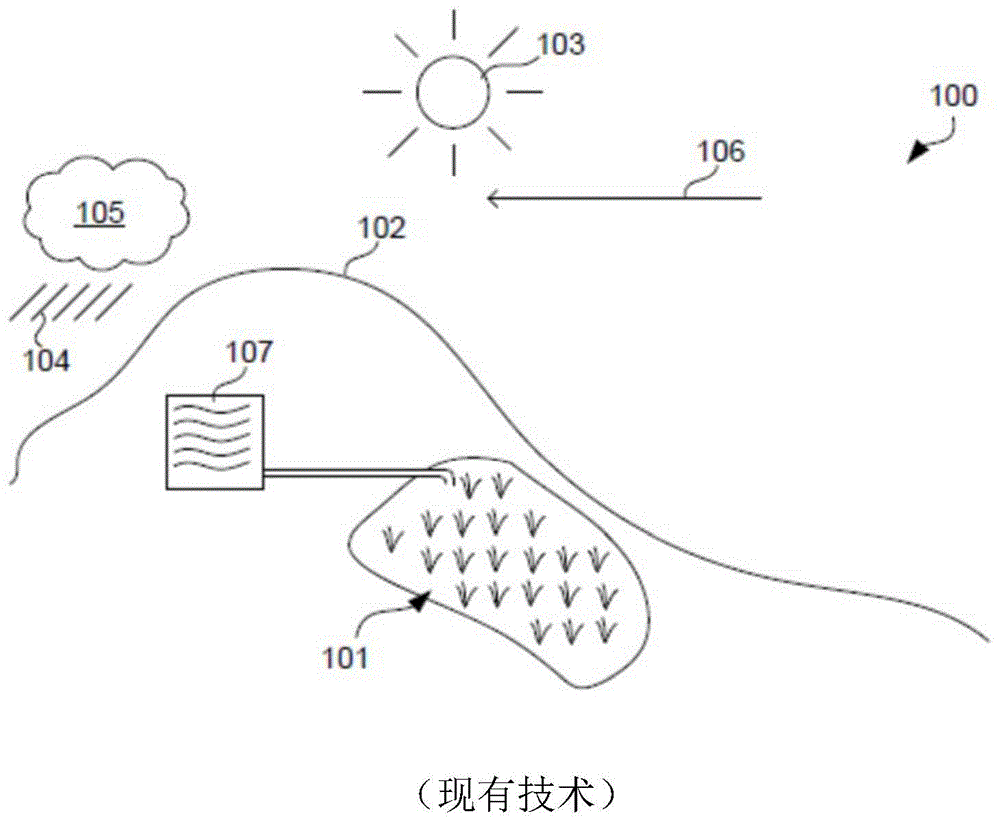
农业生产易被环境影响。图1示出了一农业生产的过程100,其中农作物101生长在山丘102的斜坡上。太阳103为农作101生长提供光,但也引起土壤水分的蒸发,这种蒸发由来自云105的降水104平衡。然而,降水104取决于云105是否在到达农作物101上方的区域之前经过山丘102,依次地,农作物101依赖于风106。为了弥补降水的缺失,必要时农民可以通过保持水库107的储量以灌溉庄稼101。
然而,农民通常很难做出最好的决定,因为众多的影响印象因素使得这个决定变得复杂。因此,估量通常是不准确的,这导致次优生产。因此,需要更准确的预测,使农民能够更有效地对他们的农场采取行动。
对本说明书中包含的文件、法案、材料、装置、物品等的任何讨论不应被视为承认任何或所有这些事项构成现有技术基础的一部分或者是在本申请的每个权利要求的优先权日之前存在的与本公开相关的领域的公知常识。
在整个说明书中,词语“包括”或诸如“包含”或“由…组成”的变体将被理解为暗示包括所述元素、整数或步骤,或元素组、整数组或步骤组,但是不排除任何其他元素、整数或步骤,或元素组、整数组或步骤组。
技术实现要素:
一种农业生产区的灌溉系统,包括:
灌溉执行器;
广域气象预测数据接收器;
传感器网络,包括部署在农业生产区域内的传感器,用于收集局域传感器数据;
处理器,配置为
将来自所述接收器的数据存储为历史广域气象预测数据;
将来自所述传感器网络的数据存储为历史局域传感器数据;
基于所述历史广域气象预测数据和所述历史局域传感器数据,确定所述历史广域气象预测数据与所述历史局域传感器数据之间的相关性;
从所述接收器接收当前的广域气象预测数据;及
基于所述当前的广域气象预测数据,以及所述历史广域气象预测数据与所述历史局域传感器数据之间的相关性,
对所述农业生产区内供水量相对于需水量的多少的预测,
其中,基于相对于需水量的供水量的多少的预测来控制所述灌溉执行器,以限定用于灌溉所述农业生产区域的水量。
一种控制农业生产区域的方法,包括:
基于历史广域气象预测数据和历史局域传感器数据确定历史广域气象预测数据与历史局域传感器数据之间的相关性;
基于当前的广域气象预测数据,及所述历史广域气象预测数据和历史局域传感器数据之间的相关性,
计算局域农业参数上的预测;
基于对所述农业参数的预测控制所述农业生产区域。
较佳地,基于局域传感器数据计算预测数据更准确,因为在局域中计算预测数据的范围不可能体现广域预测。例如,与水路直接相邻的小围场具有明显不同的微气候,如,由于风向而比距离水路50米的小围场更潮湿。此外,确定来自传感器数据的相关性比建模局域的特征更稳健且更有成本效益。例如,在给定地形上模拟风是困难且容易出错的。确定的相关性可以得到风力对传感器数据的影响。因此,可以得到各种各样的微气候效应,而无需复杂且容易出错的建模。这使得该方法易于部署到任何地形和任何类型的传感器和广域预测。
预测可能与未来至少24小时有关。
历史广域气象预测数据和历史局域传感器数据可以涉及过去至少5天。
可以基于农业模型计算对局域农业参数的预测数据。
所述农业模型可以基于植物生长。
较佳地,鉴于植物生长使得结果比仅依赖于土壤类型的其他模型更准确,例如,因为植物生长可以得到相同土壤类型的不同类型的植物。
所述农业模型可以包括表征植物蒸发的值。
所述表征蒸发的值可以随时间变化而变化。
较佳地,计算的预测数据可以适用于植物生长的当前状态,因此随着植物生长“记录”蒸发。
历史广域气象预测数据和所述当前广域气象预测数据可以包括风力数据,并且确定相关性及计算预测数据可基于所述风力数据。
所述方法还可以包括基于进一步的广域气象预测数据和进一步的局域传感器数据重复更新所述相关性。
较佳地,随着时间的变化,该方法可以学习,并且随着更多数据的可用性变得更加准确。
所述农业生产区域可以包括多个子区域,在每一所述多个子区域中存在至少一个局域传感器;并且确定相关性及计算预测数据是针对每一所述子区域计算的。
较佳地,可以单独控制不同的子区域,这使得能够在整个区域内实现最佳利用。这可以得到不同子区域的地形,土壤和其他影响因素的变化。
计算对局域农业参数的预测数据可以包括计算对植物状态的预测数据及基于所述植物状态控制所述农业生产区域。
所述方法还可以包括计算对未来局域传感器数据的预测数据,其中基于所述植物状态和所述未来的局域传感器数据控制所述农业生产区域。
控制所述农业生产区域包括以下中的一个或多个:
种植;
灌溉;
收割;
保护;和
施肥。
所述方法还可以包括:创建图形用户界面以向用户呈现对所述局域农业参数的预测。
所述方法可以包括重复计算对多个未来时间预测数据及创建所述图形用户界面以呈现对所述多个未来时间的预测的时间序列的步骤。
较佳地,用户可以随时查看所述预测并考虑要采取的操作。例如,如果一个未来预测显示降雨,即便当前缺水量很大则用户可以决定停止灌溉。在另一个例子中,用户可能需要在接下来的7天内计划员工的使用率,但如果预测下雨,则可能只需要使用一半的员工,因为他们不会在下雨天进行灌溉,因此用户将根据未来对降雨量的预测来分配员工。
所述图形用户界面可以包括输入元件以允许用户输入计划的控制指令。
较佳地,用户可以参考预测值输入控制指令,这使得界面更直观。
所述方法还可以包括基于对所述农业参数的预测来确定用于控制所述农业生产区域的建议。
所述方法还可以包括:基于当前广域气象预测数据和历史广域气象预测数据与历史局域传感器数据之间的相关性,确定对局域传感器数据的预测,其中,基于与可能发生风险的局域传感器数据相关联的预设风险确定所述建议,并且基于对局域传感器数据的预测来确定建议以降低风险。
所述方法还可以包括创建用户界面以显示所述建议。
所述局域农业参数可以是缺水量或盈水量。
对所述局域农业参数的预测可以包括表征来自所述农业生产区域的农产品的预测质量的质量参数,并且控制所述农业生产区域可以包括优化所述质量参数。
较佳地,用户可以直接控制决定价值链盈利能力的实际产出。这避免了容易出错和不准确的猜测,并且即使在整个农场的条件存在很大程度的变化时也可以实现最佳质量结果。
所述方法还可以包括重复计算对多个未来时间预测数据及创建图形用户界面以呈现对所述多个未来时间的预测的时间序列的步骤。
较佳地,用户可以直接看到未来什么时候的质量是最优的。
所述质量参数还可以包括预期的保质期。
一种软件,当由计算机执行时,使计算机执行如上方法。
一种用于控制农业生产区域的计算机系统,包括:
广域气象预测数据和局域传感器数据的接收器;
处理器,用于
基于历史广域气象预测数据和历史局域传感器数据,确定历史广域气象预测数据与历史局域传感器数据之间的相关性;及
基于当前的广域气象预测数据以及历史广域气象预测数据与历史局域传感器数据之间的相关性计算对局部农业参数的预测数据;及
输出口,基于对所述农业参数的预测控制所述农业生产区域。
在适当的情况下,描述的方法、计算机可读介质、计算机系统或灌溉系统的任何方面的可选特征类似地适用于这里也描述的其他方面。
附图说明
图1示出了根据现有技术的农业生产。
现在将参考以下内容描述示例:
图2示出了受控制的农业生产。
图3更详细地示出了图2的服务器。
图4示出了用于控制农业生产区域的方法。
图5示出了历史数据的数据库。
图6示出了一块示例的用户界面。
图7示出了多块示例的用户界面。
图8示出了累积的用户界面。
图9示出了历史广域气象预测数据的散点图800。
图10示出了针对第一天气状况的预测风对测量风的散点图。
图11示出了相关矩阵。
具体实施方式
本公开提供了更准确的预测,因为本文提出的计算预测数据得到局域中的变化,这些变化实际上不可能体现广域预测中。所公开的方法比对局域的特征建模更稳健且更有成本效益,例如跨规定地形的风。可以得到各种各样的微气候效应,而无需复杂且容易出错的建模。
在本公开内容中并且除非另有说明,否则广域气象预测数据是指由具有有限空间分辨率的模型生成的数据。例如,广域可以指10km或更大的分辨率,这意味着在10km乘10km范围内的位置具有相同的预测。广域气象预报数据也可能忽略低于预定阈值的地质特征,例如水道和地形,例如100米宽的水道或100海拔的地势或水体或地形特征,其规格小于模型网格,或者在模型网格的分辨率下分辨率很差。
广域气象预测数据可包括由以下任何一种或多种模型计算的数据:
·noaa开发的gfs全球预测系统(以前的avn)
·美国海军开发的与gfs进行比较的nogaps
·加拿大气象局(msc)开发的gem全球环境多尺度模型
·欧洲中期天气预报中心开发的ifs
·英国气象局开发的um统一模型
·德国气象局、dwd、dwd的nwp全球模型开发的gme
·法国气象局(météo-france)开发的arpege
·igcm中间通用流通模型
·ncepncar和气象研究界共同开发的wrf天气研究和预报模型。wrf有几种配置,包括:
·wrf-nmm该wrf非流体中尺度模型是美国的主要短期天气预报模型,取代了eta模型。
·wrf-arw主要由美国国家大气研究中心(ncar)开发的高级研究wrf
·nam术语北美中尺度模型是指ncep在北美领域运作的区域模型。ncep于2005年1月开始使用这一指定系统。2005年1月至2006年5月期间,eta模型使用了这一名称。从2006年5月开始,ncep开始使用wrf-nmm作为执行的nam。
·rams科罗拉多州立大学开发的区域大气模拟系统,用于大气气象和其他环境现象的数值模拟,范围从数米到数百公里,在当前公共领域得到支持
·mm5第五代宾州州/ncar中尺度模型
·arps俄克拉荷马大学开发的先进区域预测系统是一个综合的多尺度非静水模拟和预测系统,可用于区域尺度的天气预报,直至龙卷风尺度模拟和预测。用于雷暴预测的先进雷达数据同化是该系统的关键部分。
·hirlam高分辨率有限区域模型,通过10个欧洲气象服务机构由欧洲nwp研究联盟hirlam共同资助。中尺度hirlam模型被称为harmonie,并与meteofrance和aladinconsortia合作开发。
·gem-lam全球环境多尺度有限区域模型,加拿大气象服务(msc)高分辨率2.5公里(1.6英里)的gem
·aladin由法国气象局领导的若干欧洲和北非国家开发和运营的高分辨率有限区域静水和非静水模型
·cosmo该cosmo模型,以前称为lm,almo或lami,是在小规模建模联盟框架内开发的有限区域非静水模型(德国,瑞士,意大利,希腊,波兰,罗马尼亚和俄罗斯)。
·ecmwf欧洲中期天气预报中心
·access澳大利亚气象局开发的澳大利亚社区气候和地球系统模拟器天气模型
局域传感器数据是指在农业生产区域内的一个特定点处收集的传感器数据。这意味着局域传感器数据所考虑的区域比广域气象预测数据所考虑的区域小至少一个数量级。
图2示出了来自图1的农业生产100,但是现使用具有用于控制农业生产100的灌溉系统200。灌溉系统200包括连接到灌溉执行器202的监测和控制服务器201,以及用于广域气象预测数据接收器203。还存在包括多个传感器的传感器网络204,例如部署在农业生产区域206内的用于收集局域传感器数据的示例传感器205。服务器201预测相对于农业生产区域206内的需水量的供水量,并相应地控制执行器206以补偿水的任何不足。
电脑系统
图3更详细地示出了服务器201。服务器201是计算机系统,其包括连接到程序储存器304、数据存储器306、通信端口308和用户端口310的处理器302。程序存储器304是非暂时性的计算机可读介质,例如硬盘驱动器、固态磁盘或cd-rom。软件,即存储在程序存储器304上的可执行程序,使处理器302执行图4中的方法,即处理器302收集局域传感器数据确定与广域气象预测数据的相关性,例如天气预报数据预测农业生产区域206内相对于需水量的供水量,并相应地控制执行器206以补偿水的任何不足。
处理器302可以存储计算出的相对于需水量的供水量或者生成显示数据存储器306上的计算出的相对于需水量的供水量的用户界面,例如ram上的html代码或处理器寄存器。处理器302还可以经由通信端口308将确定的值和/或用户界面发送到网络服务器320,网络服务器320使得html代码可供用户316使用。
处理器302可以从数据存储器306以及从通信端口308和用户端口310接收数据,例如局域传感器数据,广域气象预测数据或用户输入数据,其连接到显示器312,显示器312向用户316显示用户界面的直观表示314。应注意,计算机系统201可以是个人计算系统,例如个人计算机、智能电话、平板电脑、平板手机或其他计算设备。在某些情况下,处理器302和显示器312是同一设备的一部分。在其他示例中,数据在服务器上处理,并且处理器302以html或其他基于web的格式的形式生成用户界面。在某些情况下,显示器312是不同设备的一部分,例如具有安装的web浏览器或专有程序应用程序(app)的个人计算设备,以呈现由处理器302生成的用户界面。
在一个示例中,处理器302经由通信端口308从传感器204接收传感器数据,例如通过使用根据wsn技术标准的无线传感器网络(wsn),包括ieee802.11-wifi、支持6lowpan的ieee802.15.4和zigbee以及lorawan,以支持局域网络,并使用3g/4g移动电信回传至处理器302。wsn可以是分散的ad-hoc网络以使得无需专用管理基础设施,例如路由器,所述基础设施是必需的或具有管理网络的路由器或接入点的集中式网络。
在一个示例中,处理器302实时接收并处理局域传感器数据。这意味着处理器302每次从传感器124接收传感器数据时生成或更新用户界面,并在传感器124发送下一传感器数据更新之前完成该计算。这是一个优点,因为广域降雨数据通常累积超过24小时,这不允许评估较短的时间范围,例如1小时。相反,来自传感器124的局域传感器数据可以以高达或超过每分钟一次的速率被捕获,这允许短时间进行评估。通过这种方式,可以在数小时而不是整天的时间范围内控制农业生产100。
虽然通信端口308和用户端口310被示为不同的实体,但是应该理解,可以使用任何类型的数据端口来接收数据,例如网络连接、存储器接口、处理器302的芯片封装的引脚或逻辑端口,例如ip套接字(ipsockets)或存储在程序存储器304上并由处理器302执行的功能参数。这些参数可以存储在数据存储器306上,并且可以在源代码中作为指针按值或按引用进行处理。
处理器302可以通过所有这些接口接收数据,其包括易失性存储器(例如高速缓存或ram)或非易失性存储器(例如光盘驱动器、硬盘驱动器、存储服务器或云存储器)的存储器访问。计算机系统300还可以在云计算环境中实现,例如托管动态数量的虚拟机的互连服务器的管理组。
应当理解,在任何接收步骤之前,处理器302可以确定或计算稍后接收的数据。例如,处理器302预处理传感器数据并将处理后的传感器数据存储在数据存储器306中,例如ram或处理器寄存器。然后,处理器302从数据存储器306请求传感器数据,例如通过提供读信号和存储器地址。数据存储器306在物理位线上提供数据作为电压信号,并且处理器302通过存储器接口接收传感器数据。
应当理解,除非另有说明,否则在整个本公开中,气象预测、降雨、变量、传感器数据等指的是数据结构,包括物理存储在数据存储器306上或由处理器处理的任何相关元数据。此外,为了简洁起见,当参考特定变量名称时,例如“时间段”或“降雨量”,这应理解为指代作为物理数据存储在计算机系统300中的变量的值。
控制农业生产的方法
图4示出了由处理器302执行的用于控制农业生产区域206的方法400。图4将被理解为用于软件程序的模型并且可以逐步地实施,每个图4中的步骤由编程语言中的函数表示,例如c++或java。然后将得到的源代码编译并存储为程序存储器304上的计算机可执行指令。
如上所述,处理器302通过接收器203和/或数据端口308接收402广域气象预测数据。气象预测数据可包括表征在接下来的24小时时间段内预测的降雨量的数据或者在接下来的24小时内以10分钟为间隔的风速和风向。接收广域气象预测数据可以包括经由ftp从气象服务提供商的基于网络的接口或数据文件服务请求数据,或者可以包括爬取气象服务提供商的网站。数据文件可以是xml文件或其他格式的文件,包括axf、grb、dbf、shp、shx、csv、txt、netcdf。
处理器302随时间从接收器存储该数据以建立历史广域气象预测数据的数据库。处理器302可以存储预测数据以获得最接近的预测时间。例如,如果对于接下来的五天中的每一天都有可用的天气预报,则处理器302存储第二天的天气预报并且每天重复该天气预报。更详细地说,1月1日处理器302存储1月2日的天气预报。1月2日,处理器302存储1月3日的天气预报,依此类推。这样,处理器302建立多天的天气预报数据库。也就是说,在1月31日,处理器302已经创建了31个历史广域气象预测数据条目的数据库。
类似地,处理器302将来自传感器网络204的数据存储为历史局域传感器数据。更详细地,处理器302存储每天的传感器数据。传感器数据可以是来自传感器205的测量值的总值,例如日平均值、累积值、最大值或最小值。例如,降雨量可以在24小时内累积存储。风可以以平均值存储。在霜冻保护的应用中,处理器302可以将最小测量温度存储为历史局域传感器数据。在一个示例中,处理器302分别存储来自每个传感器的数据。在另一示例中,处理器302计算跨多个传感器的聚合值,例如所有传感器的平均值、累积值、最大值或最小值。例如,通过这种方式,可以存储在整个区域206内测量的最低温度。
图5示出了包括第一记录501和第二记录502的历史数据的数据库500。在该示例中,历史局域传感器数据和历史广域气象预测数据一起存储在同一记录中。特别地,第一记录501和第二记录502均包括用于预测风速503、预测风向504、预测温度505、第一传感器风测量506、第一传感器温度测量507,第二传感器风测量508和第二传感器温度测量509的数据字段。
在第一天501的这个数据集中,风的预测是东部12公里/小时,预测温度是20摄氏度。第一传感器测量到明显地更低的风速(在506处),这可以表征第一传感器受到保护免受东风的影响。不出所料,第一传感器也测量到高于预测的温度(在507)。相反,第二传感器的测量到较预测的风速较高的风速(在508处)和较低的温度(在509处)可以表征第二传感器位于东风的导风漏斗(windfunnel)中。在第二天502,预测的风变为南风,并且因此第一传感器测量到更高的风速(在506处)并且第二传感器(在508处)测量到更低的风速(在508处),这表征传感器的遮风屏(windshielding)对特定风向有效。
在以上示例中,测量值直接对应于预测值,这意味着预测和测量都包括风速和温度。然而,应注意,在其他示例中,没有直接对应。例如,预测可以是温度和土壤湿度的测量。
如上所述,预测和测量之间存在复杂的相互关系。回到图4,处理器302基于历史广域气象预测数据(503,504,505)和历史局域传感器数据(506,507,508,509)确定402历史广域气象预测数据(503,504,505)与历史局域传感器数据(506,507,508,509)之间的相关性。该相关性可以以各种形式体现,如下将进一步详细描述这种相关性,如下的描述可以包括线性回归模型或k均值聚类方法的因子。
接下来,处理器302从接收器接收当前的广域气象预测数据。在此上下文中,当前预测数据涉及用于未来时间点的预测数据,即,预测的是接收数据时当前的数据。例如,1月1日收到的1月2日的天气预报是1月1日的当前天气预报,并于1月2日或1月3日成为历史数。虽然这些示例涉及天数,但是同样可以使用其他预测时间段,例如三小时。在一个示例中,预测涉及到将来至少24小时。在另一示例中,历史广域气象预测数据和历史局域传感器数据涉及过去至少5天。这意味着在统计每天数据的情况下数据库中有5条记录,或者每天有x条记录的情况下数据库中有5*x条记录。
处理器302现在基于当前的广域气象预测数据以及历史广域气象预测数据与历史局域传感器数据之间的相关性,计算404关于农业生产区域206内的与需水量相关的供水量的预测数据。与需水量相关的供水量的预测数据可能是对缺水量或盈水量的预测。例如,明天的天气预报为30度,风速为40公里/小时。处理器302可以使用先前计算的相关性来预测明天的30毫米的缺水量。
为了计算预测的农业参数,处理器302可以首先基于相关性和当前的广域气象预测数据来计算对局域传感器数据的预测数据。然后,处理器302可以使用局域传感器数据和农业参数之间的预设关系来计算农业参数的预测数据。如下面更详细描述的,处理器302可以使用农业模型或训练的机器学习模型,例如回归模型,从局域传感器数据计算农业参数。虽然由于局部环境变化,每个传感器的广域气象预测数据和局域传感器数据之间的相关性是不同的,但是局域传感器数据和农业参数之间的关系对于所有传感器或所有系统的用户可以是相同的。因此,可以将更多资源投入到该关系的准确量化中,并且可以获得更多数据用于该关系的机器学习。
最后,处理器302基于相对于需水量的供水量多少的预测数据来控制灌溉执行器202,以限定用于灌溉农业生产区域的水量。例如,为了补偿30毫米的缺水,处理器302可以定义100升/小时的水流量。
农业模式
在一个示例中,在步骤404中基于农业模型计算对局域农业参数的预测数据。农业模型是定量定义农业特定产出的任何方法。例如,农业模型可以是叶子随时间生长的模型。当第一次种植幼苗时,蒸发造成的水分损失很小,但随着幼苗生长,蒸发量会增加。这意味着对于其他恒定的环境参数,水分不足会随着时间的推移而增加。处理器302通过在预测中使用农业模型来考虑这种影响。例如,考虑到每天增加的叶子蒸发量,处理器302接收接下来5天的预测的风力数据并预测接下来五天的缺水量。
在另一个示例中,农业模型包括植物状态。在小麦作物的例子中,状态可以包括发芽、幼苗生长、分蘖、茎伸长、孕穗、头部出苗、开花(anthesis(flowering))、乳汁发育、半成熟发育和成熟或zadoks十进制生长标准的其他状态。在樱桃树的例子中,状态可以包括休眠、肿胀芽、芽爆裂、早白芽、白芽、开花、花瓣凋落和座果。
植物根据局域传感器数据推进状态的进程。特别地,当存在大量阳光时,植物推进状态的进程更快,当存在少量阳光时,植物推进状态的进程更慢。结果是处理器302可以基于当前的广域气象预测数据以及历史广域气象预测数据和历史局域传感器数据之间的相关性来预测未来的植物状态。也就是说,处理器302基于预测的局域传感器数据(其又基于广域气象预测数据和与局域传感器数据的相关性)来选择多个可能状态中的一个。确定状态转换的值可以以状态转换矩阵或状态机的形式存储在数据存储器306上。
例如,每个状态可以与若干日照小时数或照射瓦特值相关联,例如樱桃树的白芽状态可以在局域阳光的持续30小时照射下然后变为开花状态。如前所述,局域的阳光可能会因为不同地方的条件不同而在区块之间不同,因为诸如山上的雾或云的变化会显着影响阳光的照射值,这反映在上述相关性中。使用转换的与植物状态相关联的值,处理器302可以预测植物何时将处于植物的每个状态。
在一个特别重要的示例中,处理器302可以基于当前天气预报以及当植物将开花时与历史局域传感器数据的相关性进行预测。开花状态具有特定的特征或危险因素,该特征或危险因素也可以存储在数据存储器306上的状态转换矩阵中。例如,植物在开花期间可能特别容易受到害虫、霉菌或其他疾病的影响。如果预测当植物处于开花状态时存在局域条件,则可以计划缓解措施以避免或减少这些负面因素所带来的影响。例如,当樱桃没有处于开花状态时,它们不易受霜冻(低霜冻风险)。然而,当它们处于开花状态(高霜冻风险)并且在局域预测到霜时,可以提供网、屋顶或进行湿度控制以减少霜对花的影响。换句话说,对局域农业参数的预测是对植物状态的预测,并且预测值是“开花”。控制农业生产区域包括减轻不利条件的影响,例如安装屋顶或网或进行湿度控制。
该方法的优点是可以提前计划加网、加屋顶和/或其他缓解措施,这很重要,因为安装这些设施通常需要数天。
更新模型
在一些示例中,处理器302执行重复计算的步骤402,以便基于进一步的广域气象预测数据和另外的局域传感器数据来更新相关性。从这个意义上讲,所述系统可以在部署后的几天内使用有限的数据集完全运行。随着时间的推移,数据集变得更加完整,这意味着预测在更广泛的条件下变得更加准确。
子区域
在进一步的示例中,农业生产区域206包括多个子区域,例如地区、农场、小围场、行甚至单个植物。特别是对于更细粒度的方法,例如小围场、行和植物,局域预测可以增加显着的益处,因为该预测允许以最佳方式且独立于其他子区域来控制每个小围场、行或植物。需要注意的是处理器302分别为每个子区域执行400。也就是说,至少一个传感器位于每个子区域中,并且处理器302基于来自该子区域的传感器数据确定每个子区域的相关性。在大多数示例中,广域气象预测数据对于所有子区域是相同的。换句话说,处理器302确定广域气象预测数据与来自位于第一子区域中的第一组传感器的历史传感器数据之间的第一相关性。然后,处理器302确定相同的广域气象预测数据与来自位于第二子区域中的第二组传感器的历史传感器数据之间的第二相关性,依此类推。这样,相关性特定于该特定子区域和传感器数据。在那些示例中,处理器302还可以基于所计算的特定于该子区域的预测来单独地控制子区域。子区域还可能包括受保护的种植区域,如温室、网下作物或其他形式的保护区域。例如,处理器302可以向倾斜的北行提供更多的水,因为它们在不同的倾斜度下可以比相邻行接收更强烈的阳光。在另一个示例中,广域气象预测数据与历史局域传感器数据之间的相关性反映了温室内的条件如何针对外部的不同天气而变化,例如当外面有阳光时温室如何变暖。由此可以计算出蒸发量的增加以及因此需水量的增加。
控制的例子
虽然上述示例涉及灌溉,但是也可以选择控制农业生产区域的其他手段。例如,可以优化新作物的种植,以当预测存在特别有利的条件时开始种植,例如特别高的土壤温度。此外,可以在生长和成熟模型下收割。也就是说,处理器302可以预测阳光在多天或几个月内的辐射,并因此预测作物将准备好收获的时间。其他控制措施涉及保护特别容易受到冰雹或破坏性的风的子区域的作物。例如,另一个例子关于受保护的种植,其中农作物被网或其他保护机构覆盖,这些措施可以基于预测数据和历史局域数据来控制。此外,可以基于植物状态的预测和其他天气限制来控制通过肥料喂养植物以改善其生长性能。
用户界面
在其他示例中,处理器302还创建图形用户界面以向用户呈现对局域农业参数的预测数据。图6示出了示例用户界面600,其包括植物类型601的表征和所选局域602的表征,例如农业生产区域206的子区域。计算出的在图6中显示的值用于如上所说的特定的植物类型(在该实施例中为樱桃)和特定区域(块1)。用户界面600包括基于当天的蒸发量和降雨量计算的当天的缺水量603的表征。用户界面600还包括将来3天611、5天612和7天613的预测的盈水量/缺水量的表征。需要注意的是611、612和613的这些值是基于那些未来时间的天气预报(即,广域气象预测数据)以及如上所述的天气预报和传感器数据之间的相关性来计算的。例如,基于未来7天的天气预报以及天气预报与传感器数据之间的相关性来计算7天的预测缺水量。
用户界面600还包括分别从天气预报621、622和623预测未来3天、5天和7天的降雨量的表征。用户界面600还分别包括和预测未来3天、5天和7天的蒸发量631、632、633。控制农业生产区域206可以包括农民观察用户界面600并相应地发起控制。用户界面600还提供输入元件以允许农民输入所应用的控制措施。特别地,用户界面包括分别在未来3天、5天和7天提供灌溉量641、642和643的输入。
图7示出了用于多个块的示例用户界面700,即,用于农业生产区域206的多个子区域。子区域可以具有种植在其上的不同植物类型,例如樱桃或苹果。如上所述,植物类型可以定义农业模型,该农业模型用于随时间变化来预测蒸发量。
用户界面700包括多个面板,该面板用于多个子区域中的每一个,包括第一面板701、第二面板711、第三面板721和第四面板731。在第一面板701内存在植物种类702及模块或子区域标志符703。面板701还包括对接下来3天704、5天705和7天706的预测的缺水量或盈水量的表征。如上所述,是基于那些天的天气预报以及天气预报与该特定块的传感器数据之间的相关性来预测的缺水量或盈水量。从图7中可以看出,每个块的缺水量/盈水量的值是不同的,这说明了来自该块的传感器数据与天气预报之间的相关性的差异以及不同植物种类的植物模型之间的差异。例如,在与第二块713相关联的第二面板710中,植物种类712是苹果,并且由于不同的植物种类及不同的块,预测的3天盈水量714与第一块预测的3天的缺水量704存在显着不同。在第三面板721中,尽管植物类型相同,预测的3天缺水量724与第一块面板701中预测的3天的缺水量704不同。这说明了天气预报与这些块的局域传感器数据之间的相关性的差异。
用户界面700还可以包括用户的输入707,例如滑块或数字的输入,其允许用户设置添加的用于在相应模块灌溉的水量。所选择的水量可以以mm表示,其可以等于每平方米每天的升数。处理器302可以在数据存储器306上存储子区域的表面面积区域并且将表面面积区域与所选择的值相乘以计算以升为单位的水量以达到以mm为单位的所选值。例如,对于4毫米的缺水,用户可以选择4毫米灌溉来补偿这种不足。处理器302还可以将计算的缺水量建议为灌溉值。服务器201可以根据所选择的量控制执行器202。
用户界面700还可以包括关于控制农业生产区域的自动建议。处理器203基于对农业参数的预测来确定建议。例如,农业参数可以是根据植物模型在预测的局域传感器数据下的对植物的预测的植物阶段。如本文所述,每个植物阶段具有与其相关的某些危险因素,并且危险因素事件的发生取决于由传感器感测的局域条件。
例如,在果实生长期间,晒伤是主要风险,其主要发生在温度高时,例如超过30度。在这种情况下,处理器203将果实生长阶段确定为农业参数并预测如本文所述的高局域温度。结果是处理器203自动决定遮蔽和/或降温来减少晒伤。因此,如图7所示,处理器203在用户界面700中包括第一推荐735以在+3天遮蔽和使该水果降温,第二推荐736在+5天遮蔽和使水果降温以及第三推荐737在+7天收获果实。然后农民可以通过遵循自动建议显著地降低晒伤的风险,这将增加来自生产区域的水果产量。
类似地,处理器203可以在一天的特定时间建议一些控制措施。例如,处理器203预测太阳辐射将由于云层增加而从中午开始下降,因此建议在下午施用钙叶(calciumfoliar)。应当理解,在一些示例中,用户界面700可以仅示出建议735,736和737而没有预测数据。
质量参数
在一个示例中,对局域农业参数的预测包括质量参数,该质量参数用于表征来自农业生产区域的农产品的预测质量。例如,莴苣的保质期取决于收获前24小时的土壤水分。不同土壤类型的土壤水分不同。例如,与粘土或壤土相比,沙质土壤含水量较少。同样地,不同的植物在相同类型的土壤中需要不同的土壤水分水平以最佳地生长。因此,农民可以通过在预测最佳土壤水分的预测收成下最佳地控制农场来优化莴苣的保质期。这还意味着用户界面600可以包括预测的保质期的表征,其可以代替或另外加上盈水量缺水量611、612、613。例如,用户界面600和/或700可以显示“中、低、好”以“分别在3天、5天和7天收获时预测产品保质期。
处理器302可以计算局域传感器数据和质量参数之间的相关性。例如,零售商可以反馈表征每批生产中每天丢弃的产品数量的数据。然后,处理器302可以查找该批次的收获时间和子区域,并用该丢弃产品的数量从该子区域标记该收获时间的局域传感器数据的记录。然后,处理器302可以确定回归或其他学习方法,以计算局域传感器数据与生产质量之间的相关性。基于该相关性,处理器302可以使用预测的局域传感器数据或预测的农业参数(例如缺水量)来计算预测质量。在其他示例中,可以直接测量产品质量,例如通过葡萄的含糖量或通过手动品尝来测量。
未来的控制
图8示出了累积用户界面800,其包括与第一子区域相关联的第一图表801。第一图表801包括时间轴801和缺水轴802。时间轴801表示未来的预测时间,并且用户界面800包括用于未来每天的累积缺水的列。例如,第一列811表示在第一天存在1mm的预测缺水。如在第二天还存在1毫米的缺水,处理器203增加第一天的缺水811以计算2毫米的累积缺水量,如第二列812所示。同样在第三天和第四天,累计缺水量分别上升至3毫米813和4毫米814。在某些情况下,如果超过两天不下雨农民就会开始灌溉。使用本文公开的系统和方法,特别是用户界面800,农民可以更准确地看到未来预测的缺水情况。在该示例中,农民可以设置阈值820并且可以看到在5天内预测的降雨事件之前,累积缺水量没有达到阈值。预测的降雨事件减少了预测的缺水量,这意味着农民可以决定不灌溉而不会对农场产生显著的负面影响。
用户界面800包括与第二子区域相关联的第二图表851。第一图表801和第二图表851示出了在相同时间段内的预测的累积缺水量,这意味着对于第一子区域和第二子区域的基础天气预报是相同的。然而,对于局域传感器数据的相关性是不同的。结果,第二模块中的缺水量超过阈值820,这表明应该为第二模块激活灌溉以提高生产率。有趣的是,灌溉可以在第一天、第二天、第三天或第四天中的任何一天或多天被激活,以减少第四天的累积的缺水量。如果所有子区域的水流量限制为每天的最大值,例如从河流灌溉时,可能具有重要价值。在这种情况下,第二模块可以在第一天灌溉,第三模块可以在第二天灌溉,以保持第四天的两个模块的累积缺水量低于阈值。
决策支持工具
从该描述中可以明显看出,存在用于农业的决策支持工具,其提供了农业特定参数,该参数从天气预测模型输出,该输出通过使用从原位观察和天气分类开发的偏差校正因子来定位。该决策支持工具通过ui和ux提供。农业特定参数包括蒸发速率(其用于灌溉),生长度日数(其在生长周期中的关键事件中)。
数值天气预报模型的输出可以是诸如2m气温、2m相对湿度、10m风速、太阳辐射量等参数的网格模型输出。在现场,用于测量相同变量或者在该兴趣点更易比较的变量的观测数据通过测量传感器收集。
相关性
以下描述提供了关于确定历史广域气象预测数据与历史局域传感器数据之间的相关性以便创建局域预测。第一个例子说明了一个概要方法,第二个例子是一个使用神经网络的机器学习方法。
图9示出了历史广域气象预测数据的散点图800,其包括风速轴901、风向轴902和温度轴903。每个点也代表一天的广域气象预测数据,其称为一个数据点。处理器203可以聚类成第一簇911和第二簇912的数据点,例如通过执行k均值聚类方法。在其他示例中,处理器203基于局域传感器数据标记每个数据点。例如,如果测量的土壤湿度高于阈值,则处理器203将数据点分配给第一簇,如果测量的土壤湿度低于阈值,则处理器203将数据点分配给第二簇。在其他示例中,处理器203基于局域农业参数(例如缺水量)来聚类数据点。例如,处理器203使用3mm缺水量的阈值来聚类数据点。
每个数据点簇可以表示一天气条件。气象学是指该地区天气的概貌。例如,第一簇911表示具有强北风的炎热天气的天气状况。第二簇912表示来自不同方向中等温度的微风。处理器203可以分别计算每个簇或天气条件的广域气象预测数据和局域传感器数据之间的相关性。在一个示例中,处理器203开发一系列定义天气条件,这些天气条件平衡了较少数量的组,并且因此可以通过每组较少的数据来针对较大数量的组进行分析以进行分析和验证。这是使用混合系统知识/机器学习方法来执行的,其中使用环境系统知识确定初始的大类,使用自动ml方法评估这些类的扩展。在一个示例中,原始框架可以包含8个风向、3个风级和一个季节,给出96个离散的天气类别,对该类别将通过农业计算中使用的天气变量以持续和自动的方式来进行校正。
处理器203从全球0.25度(每区域)的预测模型(gfs)访问网格化天气预报数据的子集,需要注意的是该模型可以由任何天气预报模型替换。关键的天气预报参数,例如风向、风速、相对湿度、温度、表面太阳辐射、土壤湿度等都被用于产生离散的天气条件。在一个示例中,处理器203获取风速、风向、上周的平均温度和季节平均值以确定天气条件。一个典型的日子可能是一个炎热多风的北风条件。对于这种天气状况,过去的记录显示传感器站点a的降雨量通常低于模型预测的降雨量。该校正具有基于先前值的范围的数量(作为比例因子)和确定度。在计算农业参数之前,将该校正应用于天气变量。处理器203计算局部天气校正(并因此计算局部天气),其中存在基于传感器来构建校正矩阵的观测值(这可以是网格内的气象站)。
图10示出了第一簇911的散点图1000,其包括用于来自气象预测数据的历史预测风速的第一轴1001和用于来自局域传感器数据的测量风速的第二轴1002。从数据点可以看出,存在强相关性,但是测量的风速1002是预测风速的约0.5倍,如回归线1003所示。结果是处理器203存储“0.5”作为历史气象预测数据和历史传感器数据之间的相关性。然后,农业模型将当地风速与缺水量联系起来。在该示例中,来自气象预测数据的其余参数(例如温度)的影响是微不足道的并且可以忽略。换句话说,当风力强时,缺水不会明显依赖于温度。在其他示例中,关系更复杂。例如,可以存在由局域传感器205测量的10个参数,包括温度、相对湿度、风、雨、叶湿度、太阳辐照度、光合有效辐射、霜检测、土壤湿度和土壤温度。此外,在包括风、温度和降雨在内的广域气象数据中可能为3个预测参数。
图11示出了相关矩阵1100,其包括表示相关性的乘数,用于根据预测的气象预测数据计算预测的局域传感器数据。矩阵1100中的每个条目可以被称为偏差校正因子,并且可以基于多个模型输出变量从分类矩阵进行计算,对这些变量的共同考虑可以表示不同天气条件,这些天气条件对模型计算及其代表的对局部进行的测量有影响的。在一个示例中,对于多个天气条件中的每一个存在一个矩阵。
在其他示例中,处理器302执行参数选择算法以从数据中选择最重要的参数,例如通过执行主成分分析。
通过使用第二种方法,机器学习或神经网络方法开始于预处理数据以使其以合适的格式和合适的结构获得。然后,处理器302计算不同变量之间的相关性,以确定哪些变量是良好的预测变量。在一个示例中,当变量的绝对相关值高于0.7时,变量是良好的预测变量。然后将良好的预测变量包含在模型中。然后,处理器302从原始数据创建变量列表以表征模型的最佳参数。处理器302通过检索历史广域气象预测数据和历史局域传感器数据并确定每个变量对的pearson相关系数来确定相关性。pearson相关系数使用以下公式计算:
对适当的机器学习模型的初始确定可以确定最佳候选者。处理器302通过评估场景上的模型的初始候选者并基于粗略的初始结果来辨别最佳匹配度以选择一个或多个机器学习模型。
在处理器302选择具有最佳匹配的模型之后,可以通过改变隐藏层的数量和每层中的节点的数量来调整模型。在一些示例中,处理器302执行参数选择算法,以通过执行主成分分析来对变量进行分类以从数据中选择最重要的参数。
在一个示例中,神经网络模型用于预测风速和风向、相对湿度、温度、降雨量、降雨概率、叶湿度和土壤湿度。然而,可以使用参数组合的其它值。模型的调整可能包括:
·为模型添加最小最大缩放比例;
·应用主成分分析;
·通过添加图层构建神经网络(大多数模型具有3到4层)。
处理器302在训练数据集上测试模型,并将结果与测试集进行比较以确定准确度。根据结果,处理器302通过添加或移除层来调整模型,并自动调整模型使用的技术,例如输入权重和优化技术。
模型的输入数据是来自全球预测系统(gfs)的25度网格的广域气象预测数据的组合。从gfs获取的数据输入包括天气预报,如温度、湿度、压力、云层(及其各种形式)、露点、太阳辐射、风、降雨率和总降雨量、预测日照时数、不同风的位势高度水平、暴雨运动、地表阵风、对流降水、冻雨类别、冰粒类别、降雪和降雨类别、地热通量、冰盖、海恩斯指数、潜热网通量、蒸发率、显热净通量、土壤湿度、表面温度、土壤温度、水流枯萎点。过去12个月的gfs数据作为输入,因为它提供了一年的季节变化值。第二输入集是预测位置处的实际传感器数据(即,局域传感器数据)。传感器数据包括温度、湿度、压力、叶片湿度、土壤湿度、par、pyr,降雨、风速和风向。所有可用的传感器数据都可用作输入。
为了创建预测,处理器203在一部分历史数据(即,在70%和100%之间)上评估模型,例如每天一次的规则间隔训练。这意味着处理器203不断改进模型,并且可以在没有任何本地条件的先验知识的情况下部署系统。几天之后,由处理器203计算的预测将变得比广域气象预测数据更准确。然后,处理器203以规则的间隔(例如每2-6小时)在从传感器和gfs接收的新数据上运行模型以创建最新的预测。该模型为每个变量创建接下来7天(即168小时点)每小时的预测。
用于预测8个增长变量的预测模型包括:
在一个示例中,可以从神经网络预测叶面湿度,所述神经网络学习广域气象预测数据与来自农场的传感器数据之间的相关性,并且使用处理器203运行。在另一个示例中,可以通过在处理器203上运行的支持向量机来预测土壤湿度。
传感器
在一个示例中,以下以下传感器组件被应用:这些组件中的一个或多个的任何组合构成一个传感器205:
示例
一个例子是由苹果种植者经营的农业生产区域。生产的苹果应符合具体和优质的标准----75毫米、175克、90%的红色、14.5%的糖分和恰到好处的压强。满足此规格的苹果越多,苹果种植者的利润就越高。在每公顷50吨的农作物上,包装增加10%,利润可以增加一倍,所述%为苹果不被拒绝的百分比,包装是对整体质量的直接衡量。
苹果季从芽爆发开始,树木应该积累足够的冬季的寒冷,这样才能结果,800个寒冷的小时可能是目标。第一项任务是控制结果。如果有太多的花朵结果,那么苹果就会太小,如果没有足够的花朵结果,它们就会太大。因此,需要在恰当的天气条件下将稀释剂应用于作物以平衡热量、日照时间、土壤湿度和产品选择。上面公开的方法和系统可以通过用户界面自动建议使用稀释剂作为对农民的生产区域的控制。所提出的方法和系统监测白天和夜晚的温度趋势。这种自动化解决方案避免了错误,该错误可能导致必须使工作人员高强度的劳作,而这可能会损失全年的全部利润。同样,如果花朵在开始时变薄,那么将几乎没有苹果产出。
同时,农作物正在开花,主要关注的是疾病和虫害的爆发以及管理枝条生长和根系生长。例如,在一天15℃下,超过六小时的叶面潮湿和黑点即是一个风险。如果检测到苹果蠹蛾爆发,则在蛆出来之前有一个110度天的窗口(每小时超过10℃)。然后可以选择何时及对哪个产品和果园的哪个部分进行回应。不同的产品在不同的条件下工作,并且成本差异很大。这里的错误可以抵消10%的包装增加。本文公开的系统和方法可以预测局域的参数,并因此自动建议对农业生产区域控制的最合适的产品。这降低了农民失去利润的风险。
下一阶段是细胞分裂。这4周时间内所有的苹果细胞都分裂完了,这最终决定了果实大小的潜力。苹果的坚硬程度也在这里决定,如果在树的正确部分以正确的形式施加适量的水和钙,则就奠定了脆果的基础。必须彻底施用钙叶面以避免因水果灼伤。即在当天的高温下喷洒可减少5%的包装。肥料也应该同时保持。同样,这里公开的系统和方法可以预测局域的参数,并因此自动建议最合适的应用模式作为对农业生产区域的控制并在用户界面上显示建议。
此阶段的另一个风险是小虫爆发,这对于有颜色的颜色目标是毁灭性的。此外,冰雹、鸟类和风都会造成损害。随着收获的临近,实现规模目标可能需要更多时间,因为当年eto已经很高并且具有挑战性。但灌溉可能不是解决方案,因为水果可能会变软并对擦伤敏感。如果果实长时间留在树上可能会被晒伤(这是澳大利亚的苹果在擦伤后不被接受的第二大原因)或者最糟糕的是,采摘可能为时已晚,严重影响了储存潜力和保质期。同样,本文公开的系统和方法可以预测局域的参数,并因此自动建议最合适的时间作为对农业生产区域的控制。
农民会在时间压力下做出关键决策的每一步。本文所述的方法和系统为种植者提供了工具,可以在每一步中做出自信的决策以减少不确定性并降低风险。
虽然本文的示例涉及控制农业生产区域,但是本文公开的系统和方法同样可以适用于其他操作,包括但不限于水产养殖、采矿、自然资源、环境监测、物流、保险、金融和建筑物。从这个意义上讲,提供了一种控制操作区域中的操作的方法。该方法包括基于历史广域气象预测数据和历史局域传感器数据确定历史广域气象预测数据与历史局域传感器数据之间的相关性。该方法还包括基于当前广域气象预测数据计算对局域操作参数的预测数据,以及历史广域气象预测数据与历史局域传感器数据之间的相关性。该方法还包括基于对操作参数的预测来控制操作。
本领域技术人员将理解,在不脱离权利要求限定的范围的情况下,可以对特定实施例进行多种变化和/或修改。
应该理解,可以使用各种技术来实现本公开的技术。例如,这里描述的方法可以通过存在于适当的计算机中的可读介质上的一系列计算机可执行指令来实现。适当的计算机可读介质可以包括易失性储存器(例如ram)和/或非易失性(例如rom,磁盘)存储器、载波和传输介质。示例性载波可以采用电信号、电磁信号或光信号的形式,该信号沿着本地网络或诸如因特网的公共可访问网络传送数字数据流。
还应该理解,除非从以下讨论中明确说明,否则应当理解,在整个说明书中,利用诸如“估计”或“处理”或“运算”或“计算”之类的术语进行讨论,“优化”或“确定”或“显示”或“最大化”等是指计算机系统或类似电子计算设备的动作和过程,其处理和变换表示为物理(电子)量的数据。计算机系统的寄存器和存储器代表其他数据,类似地表示为计算机系统存储器或寄存器或其他此类信息存储、传输或显示设备内的物理量。
因此,本发明的实施例在所有方面都被认为是说明性的而非限制性的。
- 还没有人留言评论。精彩留言会获得点赞!