基于人体PPG信号分段的身份识别方法与流程
本发明属于信息处理技术领域,具体涉及一种身份识别方法,可作为金融、政府机构等领域中维护个人信息安全的一种手段。
背景技术:
当今社会,安全问题越来越突出,人们不得不记忆复杂的密码或者携带额外的电子密码器,这使得传统的身份识别方法越来越失去它的实用性和可靠性,这一现状使人们对生物识别的需求越来越大。今天,大多数的系统比如金融交易、计算机网络和对安全领域的访问系统仍是通过身份证或口令进行识别授权的。这样的系统并不足够安全,因为身份证或口令信息很容易被窃取或者遗忘。生物识别系统可以提供更多的可靠性和隐秘性,因为它是根据个人的生理信号和行为特征进行身份认证的,这种生理信号或行为特征是个人独有的,并可以用来区分开不同个体。人体或行为属性独特的特性,如指纹、人脸、声音、脑电图和心电图等被用来进行身份识别。基于这些特征的应用提供了一种有发展前景和不可取代的识别方法。然而,指纹可以用乳胶提取特征,人脸识别可以用伪造的照片进行欺骗,声音可以被模仿,基于脑电信号或者心电信号的方法因需要各种各样的电极采集信号而不能广泛使用。
光电容积脉搏波ppg信号是一种非入侵式的光电方法,通过靠近皮肤测试身体的某一部位,获取关于血管中血液流动体积变化的信息。ppg信号作为人体固有的一种生理特征,具有难以被复制和模仿的特点,具有较高的安全性,且采集简单。目前基于ppg信号的时域身份识别方法,识别率不足够高,难以满足实际应用需求。
目前已提出的基于ppg信号的身份识别方法有:
a.
nimohammednadzr,msulaimi,lfumadi,kasidek等人2016年在“indianjournalofscienceandtechnology”期刊上发表的文章“photoplethysmogrambasedbiometricrecognitionfortwins”中,研究了一种利用ppg信号对双胞胎的身份进行识别的方法,该方法首先利用低通滤波器对原始ppg信号进行去噪,然后对ppg信号波形进行分割,提取单周期波形,再利用径向基函数网络和朴素贝叶斯分类器分别对单周期波形进行识别分类,最终身份正确识别率达到97%以上,该方法验证了ppg信号的单周期波形特征对个体身份识别的有效性,但身份识别率仍有待进一步提升。
技术实现要素:
本发明的目的在于针对上述已有技术的不足,提出一种基于人体ppg信号分段的身份识别方法,以提高身份识别的正确率。
本发明的技术方案是通过对人体ppg信号单周期波形进行分段处理,再利用鉴别式非负矩阵分解dnmf方法获取各子波段的特征向量,最后将各子波段的特征向量加权融合,生成融合的特征向量,进行身份识别,其实现步骤如下:
(1)获取训练数据库和测试数据。采集m个人在规定时间段内的光电容积脉搏波ppg信号,组成训练数据库s;再采集其中一人在另一时间段内的ppg信号,作为被鉴定者的测试数据xg;
(2)对训练数据库s依次进行去噪,归一化处理,波峰检测,波形分割,插值,去除差异性大的波形和进行波形平均,得到单周期平均波形数据库w;
(3)将单周期平均波形数据库w中每一个单周期波形进行分段处理,得到训练数据的上子波形集v1、中子波形集v2和下子波形集v3,并计算各子波形集中同一个人两两子波形之间的相似度,得到训练数据上子波形集的权重因子d1、中子波形集的权重因子d2和下子波形集的权重因子d3;
(4)利用鉴别式非负矩阵分解dnmf方法分别对训练数据的上子波形集v1、中子波形集v2和下子波形集v3进行分解,得到训练数据上子波形集的基空间z1、中子波形集的基空间z2、下子波形集的基空间z3、训练数据上子波形特征集h1、中子波形特征集h2和下子波形特征集h3;
(5)利用训练数据上子波形集的权重因子d1,中子波形集的权重因子d2和下子波形集的权重因子d3分别对训练数据上子波形特征集h1,中子波形特征集h2下子波形特征集h3中相应的子特征进行加权融合,得到训练模板库h;
(6)对被xg鉴定者的测试数据依次进行步骤(2)-(3)操作,得到测试数据xg的上子波形集α1,中子波形集α2,下子波形集α3和测试数据上子波形集的权重因子a1,测试数据中子波形集的权重因子a2和测试数据下子波形集的权重因子a3;
(7)将测试数据xg的上子波形集α1,中子波形集α2,下子波形集α3分别在训练数据上子波形集的基空间z1,中子波形集的基空间z2,下子波形集的基空间z3上进行投影,获得测试数据上子波形特征集f1,中子波形特征集f2和下子波形特征集f3;
(8)利用测试数据xg的各子波形集的权重因子a1,a2和a3,将测试数据xg的上子波形特征集f1,中子波形特征集f2和下子波形特征集f3进行加权融合,得到测试特征集f;
(9)利用训练模板库h和被鉴定者的测试特征集f,对被鉴定者的身份进行识别。
本发明与现有技术相比具有以下优点:
第一,本发明充分挖掘并利用ppg信号单周期波形的特征,通过将被鉴定者ppg信号的单周期波形进行分段处理,利用余弦相似公式计算各段子波形的权重因子,并利用权重因子对各段子波形进行加权融合,利用获得的融合特征向量进行身份识别,提高了被鉴定者身份正确识别率。
第二,本发明利用鉴别式非负矩阵分解方法提取ppg信号单周期波形的主要特征,使得相同个体的单周期波形特征之间的差异性变小,不同个体单周期波形特征之间的差异性增大,从而提高了被鉴定者身份的正确识别率。
附图说明
图1为本发明的实现总流程图;
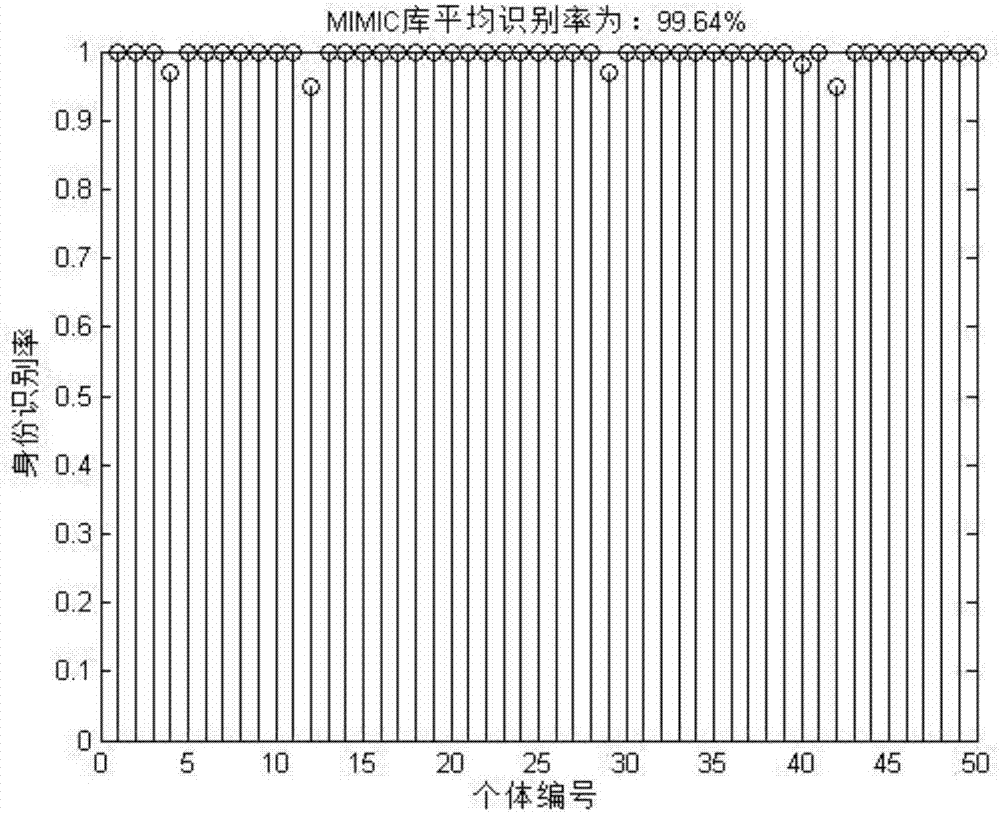
图2为mimic数据库的身份识别率结果图;
图3为mimic2数据库的身份识别率结果图;
图4为capnobase数据库的身份识别率结果图。
具体实施方式
下面结合附图对本发明的实施及效果作进一步详细描述。
参照图1,本发明的实现如下:
步骤1.采集ppg信号,得到训练数据库和测试数据。
采集m个人在规定时间段内的ppg信号,设采集的每个人的ppg信号采样点数为n,将采集的每个人的ppg信号作为一个行向量,构造一个m×n大小的矩阵,作为训练数据库s;再采集其中一人在另一时间段内的ppg信号,作为被鉴定者的测试数据,用符号xg表示,则测试数据xg是一个包含多个采样点的向量。
本发明以mimic数据库中的ppg信号作为实验数据,模拟从人体采集到的ppg信号,从mimic数据库中随机选取其中50个个体的ppg数据文件,读取每个人的ppg数据文件的前200秒的ppg信号,组成训练数据库s;再从该50个个体中随机读取其中一个人的ppg数据文件后200秒的ppg信号,作为被鉴定者的测试数据xg;mimic数据库中的ppg信号的采样频率f为125hz,所以训练数据库s是一个50×25000大小的矩阵,测试数据xg是一个1×25000维的向量。
步骤2.对训练数据库s进行预处理,获取单周期波形数据库。
(2a)对训练数据库s每行ppg信号进行去噪处理,由去噪后的所有行ppg信号组成去噪后的训练数据库s1,其中,训练数据库s1中每行的ppg信号s1i由n个采样点组成,表示为:s1i={s1(i,j)|j∈[1,n]},i∈[1,m],s1(i,j)表示去噪后的训练数据库s1第i行第j列的采样点,n表示每人ppg信号的采样点数;
常用的去噪方法有低通滤波器、小波去噪、傅里叶分析等,本实例采用2014年胡广书编著的清华大学出版社出版的“现代信号处理教程第2版”的第12.4节“小波去噪”;
(2b)对去噪后训练数据库s1的每行ppg信号的每个采样点进行归一化处理,使归一化后的所有采样点的取值都在区间[0,1]之内,得到归一化后的训练数据库s2,其中,归一化后的训练数据库s2中第i行第j列的采样点s2(i,j)计算公式为:
(2c)对归一化后的训练数据库s2的每行ppg信号进行收缩期波峰检测,获取所有收缩期波峰的位置,去除第一个位置和最后一个位置,由剩余的所有位置组成每行ppg信号收缩期波峰位置的集合
ppg信号是周期性信号,ppg信号的一个周期包括两个波峰,即收缩期波峰和舒张期波峰,收缩期波峰的幅度值高于舒张期波峰的幅度值。常用的波峰检测方法有极大值检测法、差分阈值法、自适应阈值法等,本实例使用王黎,韩清鹏编著的2011年科学出版社出版的“人体生理信号的非线性分析方法”一书的第4.4.1节“p波波峰点的提取方法”;
(2d)波形分割,获取单周期波形;
以第i行ppg信号的位置集合loci中的所有元素为分割点,将相邻两个分割点之间的波形作为一个单周期波形,对归一化后的训练数据库s2的第i行ppg信号s2i进行波形分割,使ppg信号s2i分割后变成
(2e)对所有类单周期集合中每一个单周期波形进行插值,使插值后的每个单周期波形的采样点数均为n,得到插值后的单周期波形为
(2f)去除差异性较大的单周期波形;
计算第i类所有插值后的单周期波形的平均周期波形,作为参考波形;将每个单周期波形作为//随机变量,计算第i类的每个单周期波形与参考波形的皮氏积矩相关系数;然后将相关系数与设定的阈值th进行比较,若相关系数小于设定的阈值th,则删除相应的单周期波形,否则保留相应的单周期波形;由保留下来的所有单周期组合成第i类去除杂波的单周期波形集合
(2g)对第i类去除杂波的单周期波形集合
步骤3.对单周期平均波形数据库w的单周期波形进行分段处理。取单周期波形数据库w的第1行到第
步骤4.计算训练数据的上子波形集v1、中子波形集v2和下子波形集v3各自的相似因子,并根据相似因子,得到各子波形集的权重因子。
(4a)将两个向量夹角的余弦值作为两个子波形之间的相似度,设vi,θ和vi,χ分别为上子波形集v1的第i类的第θ个子波形和第χ个子波形,则上子波形集v1的第i类所有子波形之间的相似度simi计算公式如下:
其中,θ,χ∈[1,ki],(·)t表示向量或矩阵的转置,||·||l2表示向量的l2范数;
(4b)按照步骤(4a)的计算公式,计算训练数据的上子波形集v1的每一类子波形的相似度,再利用下列公式,得到上子波形集v1的相似因子s1:
(4c)按照步骤(4a)-(4b),求出训练数据的中子波形集v2的相似因子s2和下子波形集v3的相似因子s3;
(4d)利用训练数据的上子波形集的相似因子s1,中子波形集的相似因子s2和下子波形集的相似因子s3,按照下列公式,求得各子波形集的权重因子d1,d2和d3:
其中,d1,d2和d3分别为训练数据的上子波形集的权重因子,中子波形集权重因子和下子波形集权重因子,d1,d2和d3都是0到1之间的实数。
步骤5.获取基空间和训练模板库。
利用鉴别式非负矩阵分解dnmf方法分别对训练数据的上子波形集v1,中子波形集v2和下子波形集v3进行分解,得到上子波形集的基空间z1,中子波形集的基空间z2,下子波形集的基空间z3和各子波形的子特征集h1,h2,h3;并对各子波形的子特征集h1,h2,h3进行融合,得到训练模板库h。
此处的鉴别式非负矩阵分解方法是采用的2006年stefanoszafeiriou,anastasiostefas等人在“ieeetransactionsonneuralnetworks”期刊发表的“exploitingdiscriminantinformationinnonnegativematrixfactorizationwithapplicationtofrontalfaceverification”一文中描述的鉴别式非负矩阵分解方法dnmf。
(5a)利用鉴别式非负矩阵分解方法对训练数据的上子波形集v1进行分解:
(5a1)随机初始化基矩阵z(0)和系数矩阵h(0),使基矩阵z(0)中的任意元素满足
(5a2)根据如下公式,对基矩阵z(t)中的元素
首先,按照如下公式更新,得到中间变量值
然后,对中间变量值
将
(5a3)根据步骤(5a2)得到的迭代t次后的基矩阵z(t),按如下迭代规则更新系数矩阵h(t)中的元素
其中,γ,δ分别为类内散度约束项和类间散度约束项的约束因子,μφ表示系数矩阵h(t-1)中所有列向量的均值向量μ中的第φ个元素;
(5a4)采用预定义的最大迭代次数iter作为停止迭代条件,当迭代次数t达到iter次后,停止迭代,输出基矩阵z(iter)和系数矩阵h(iter);否则,返回步骤(5a2);
(5b)将基矩阵z(iter)作为上子波形集v1的基空间z1,将系数矩阵h(iter)的每列作为一个子特征向量,组成上子波形的子特征集
(5c)按照步骤(5a),分别对训练数据的中子波形集v2和下子波形集v3进行分解,得到中子波形集的基空间z2和子特征集
(5d)利用训练数据的上子波形集的权重因子d1,中子波形集的权重因子d2和下子波形集的权重因子d3对上子波形的子特征集h1中的子特征向量
步骤6.对被鉴定者的测试数据xg进行处理,得到测试数据xg的各子波形集及各子波形集的权重因子。
(6a)对测试数据xg进行步骤2-3操作,得到测试数据xg的上子波形集α1,中子波形集α2和下子波形集a3;其中,
(6b)对测试数据xg的上子波形集α1,中子波形集α2和下子波形集a3进行步骤4操作,得到测试数据上子波形集的权重因子a1,中子波形集的权重因子a2,下子波形集的权重因子a3,其中,a1,a2,a3∈(0,1)。
步骤7.按照下式,将测试数据xg的上子波形集α1,中子波形集α2和下子波形集a3分别在训练数据的上子波形集基空间z1,中子波形集基空间z2和下子波形集基空间z3上进行投影,获得测试数据上子波形的子特征集f1,中子波形的子特征集f2和下子波形的子特征集f3:
f1=inv((z1)t×z1)×(z1)t×a1,
f2=inv((z2)t×z2)×(z2)t×a2,
f3=inv((z3)t×z3)×(z3)t×a3,
其中,
步骤8.获取测试特征集。按照步骤(5d),利用权重因子a1,a2和a3,对f1,f2和f3的对应列加权融合,得到测试特征集f={ξ1,ξ2,…,ξg,…,ξg},其中,ξg表示测试特征集f的第g个测试特征向量,
步骤9.利用支持向量机svm对被鉴定者的身份进行识别。
(9a)将训练模板库h中所有模板输入到支持向量机中进行训练,得出支持向量机模型;
(9b)将被鉴定者的测试特征集f中的所有测试特征向量依次输入到训练好的支持向量机模型中进行类别预测,得到预测类别信息;
(9c)根据所有测试特征向量的预测类别信息,分别统计各类中测试特征向量的个数,将测试特征向量个数最多的类预测为被鉴定者的身份。
本发明的效果可通过以下仿真做进一步说明。
1.仿真条件
本发明的仿真实验使用三个公开的ppg信号数据库mimic,mimic2和capnobase数据库,模拟从人体采集到的ppg信号,仿真实验在intelpentiume58003.2ghzcpu、内存2gb的计算机上进行。
2.仿真内容
首先,分别从mimic数据库,mimic2数据库和capnobase数据库中随机选取50个人,50个人和42个人的ppg信号,使用本发明分别对数据库中的每个人进行身份预测,计算每个人的识别率:
身份识别率=类别预测正确的测试特征数目/被鉴定者的测试特征总数;
然后,取数据库中所有人身份识别率的平均值作为数据库的身份识别率,得到每个库身份识别率的结果图,如图2、图3和图4。
从图2、图3和图4可以看出,每个库的正确身份识别率均达到99.62%以上,充分说明了本发明的有效性和高识别率。
- 还没有人留言评论。精彩留言会获得点赞!