一种使用多通道信息融合的个人情感唤醒度识别方法与流程
本发明是一种人类情感唤醒度识别的方法。主要涉及计算机科学和心理学的相关技术领域。
背景技术:
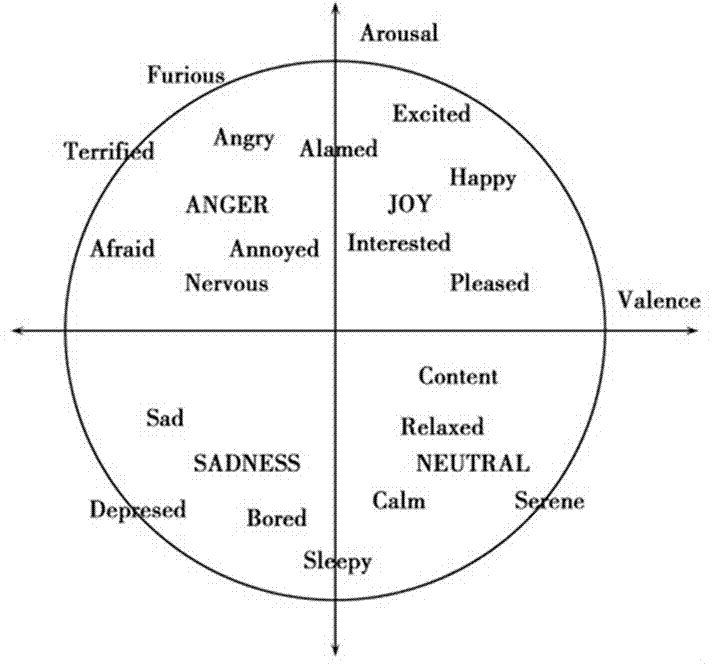
jamesa.russel在1980年提出了arousal-valence情感模型(如附图1),目前该模型是心理学界进行情感度量的重要模型之一。该模型主要采用唤醒度(arousal)和效价(valence)作为度量指标来衡量人类情感状态。其中,“唤醒”是指生理或心理被吵醒或是对外界刺激重新产生反应。激活脑干,自律神经系统和内分泌系统,使得机体提高心率和血压准备接受外界刺激、运动和反应。唤醒性情绪包括:悲伤、愤怒和愉悦等。情感唤醒度是人类情感被唤醒程度高低的度量,在本方法中,我们将情感唤醒度定义在[-1,1]数学空间,其中-1表示负面情感唤醒度最大值,0表示没有唤醒,1表示正面情感唤醒度最大值。所以唤醒度的识别是进行情感状态和水平识别的重要一环。
情感识别是实现和谐人机交互的关键技术,其目的是赋予计算机识别用户情感的能力。来自社会和认知心理学的研究表明在相关的外界刺激下,情感能够快速地、轻易地、自动地甚至无意识地唤起。情感计算最初由美国麻省理工学院的picard教授在1997年提出的。情感计算的目标是赋予计算机感知、理解与表达情感的能力,从而与人更加主动、友好、声情并茂地交流。随后,情感计算迅速引起人工智能与计算机领域专家的兴趣,并成为近几年一个崭新的、充满希望的研究领域。情感计算的提出与迅速发展,一方面是由于人机交互和谐性的要求,希望计算机像人一样不但具备听、说、看、读的能力,而且能够理解与表达喜、怒、哀、乐等情绪;另一方面也是基于强计算主义的心理,希望把计算延伸至人的内心世界。
情感计算提出后,基于面部表情、语音、姿势和生理信号的情感识别在得到广泛研究。语音是人类情感的重要外在表现,有效体现人类的情感状态和变化情况。tomkins指出面部活动在情感体验中扮演了重要角色。picard认为,基于生理信号的情感识别更接近于情感的内在心理感受。ekman的团队最先在1983年的science上发文陈述了离散情感可区分性的证据。其中心电(ecg)和皮肤电(eda)是反映人的交感神经兴奋变化的最有效、最敏感的生理指标,是国际上最早最广泛应用并得到普遍承认的多导心理测试指标。综合利用上述信息进行情感唤醒度的识别是未来技术发展的重要趋势。
同时,由于人类个体之间的生理结构和心理水平存在较大的差异,以往的研究往往试图建立普适性的情感识别模型,这必然导致识别水平的下降,使得技术缺乏实用性。因此,本技术的针对不同的人类个体建立正对特定个体的情感唤醒度识别模型,以提高识别的准确性和实用性。
技术实现要素:
本发明的内容是提供一种使用多通道信息融合的个人情感唤醒度识别的方法。
为了得到上述目的,采用以下技术方案:采集个体基本数据建立情感唤醒度识别模型,该方法主要包括如下步骤。
s1:通过前期数据采集,得到被试个体在不同情感状态下的心电信号(eeg),皮肤电信号(eda),声音信号(audio)和面部视频信号(video),共10个样本,每个样本时间在180-300秒不等。
s2:由3名专业人员使用对用户唤醒度状态进行评价。
s3:计算提取对应信号的数值特征,生理信号(ecg,eda)计算时间窗口长度为0.02秒,音频信号参数计算时间窗口长度为0.05秒,视频信号计算时间窗口长度为0.2秒,主要使用的22个特征包括:
表1情感唤醒度评估信号特征数据类型。
s4:对所有信号特征进行标准化处理得到模型训练数据,以便能够提高模型训练的准确性,避免模型训练过拟合。
s5:使用s4中获得的标准化训练数据和s2中获得的评价数据,训练支持向量机回归识别模型(svr),从而获得针对该被试个体的情感唤醒度识别模型。并将训练好的识别模型进行参数化保存。
在获得情感唤醒度识别模型后,在需要进行情感唤醒度预测/检测时,按照以下步骤进行情感唤醒度检测。
s1:实时采集的心电信号(eeg),皮肤电信号(eda),声音信号(audio)和面部视频信号(video)。
s2:提取如表1所示的唤醒度识别特征值。
s3:对提取得到的特征值进行数据标准化处理。
s4:将计算提取获得的特征值输入情感唤醒度识别模型,由该模型计算出被试个体在当前状态下的情感唤醒度水平。
本发明的主要特点包括。
(1)通过前期研究,在各种数据的200余个数据特征中,使用特征选择技术,确定了用于情感唤醒度识别效果最好的22个信号特征,从而极大的降低了计算复杂度,提高了计算效率。
(2)建立的模型针对特定个人,能够有效避免由于个体差异带来的识别误差,很好的提高了识别的有效性和准确性。
(3)该方法适用于所有人类个体,能够针对每个个体的实际情况,建立具有较高识别率的独立情感唤醒度识别模型。
附图说明
图1为arousal-valence情感模型示意图。
图2为情感唤醒度信号采集示意图。
图3为情感唤醒度预测值与评估值对比图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步的阐述。
1.个人情感唤醒度预测识别模型建立方法,该方法主要实在预测之前通过预先采集个人情感唤醒度信号,进行数据预处理,并使用采集的数据训练针对该个体的情感唤醒度预测识别支持向量机回归模型,以提供后续实时预测识别使用。
(1-1)训练数据采集与获取
被试前期需要根据自身回忆,在采集环境中讲述自己记忆最为深刻的经历,建议被试讲述中包括高兴,悲伤,愤怒,恐惧等典型情感状态事件。在讲述过程中使用美国biopac公司提供的多导生理记录仪mp150。该仪器采集出ecg信号和eda信号。使用麦克风记录被试语音信号,使用摄像头记录被试个体的面部表情图像(如附图2所示)。训练数据采集量不少于30分钟。
(1-2)情感唤醒度评价数据采集
由3名经过训练的人员(心理学专业)观看被试视频,收听被试表述,对不同时刻被试情感唤醒度进行评分,评分范围为[-1,1],评分数据保留小数点后两位,其中-1表示负面情感唤醒度最大值,0表示没有唤醒,1表示正面情感唤醒度最大值。取3人评分平均分作为该时刻唤醒度评价值。
(1-3)提取被试信号特征
对于采集到的心电信号(eeg),皮肤电信号(eda),声音信号(audio)和面部视频信号(video)计算如表1所示的信号特征。
(1-4)对计算得到的信号特征进行数据标准化
为了避免由于特征数据量值大小差异造成的过拟合等问题,采用标准数据归一化方法对(1-3)中计算得到的特征数据进行标准化。该方法将原始数据归一化成均值为0、方差1的数据,归一化公式如下:
其中,μ和σ分别为原始数据的均值和方差。
(1-5)训练个人情感唤醒度识别模型
使用(1-4)中计算得到的标准化特征值作为训练数据,(1-2)中的情感唤醒度评价值作为评价数据,进行支持向量机回归模型(svr)训练。最终得到针对该被试个人的情感唤醒度识别模型。将所有训练好的模型参数保存,作为后续实时预测的回归计算模型。该支持向量机的损失函数度量为:
根据该损失函数,可以定义对应的目标函数为:
回归模型训练数据量要求不少于30分钟数据量。
2,进行实时情感唤醒度预测,该方法主要通过实时采集和计算唤醒度想关情感信号特征,使用之前建立的情感唤醒度预测计算模型计算出该时刻的情感唤醒度数值。
(2-1)使用与(1-1)相同的设备采集个体实时心电信号(eeg),皮肤电信号(eda),声音信号(audio)和面部视频信号(video)。
(2-2)计算提取如表1所示的信号特征。
(2-3)对信号特征进行数据标准化处理,得到标准化后的信号特征值。
(2-4)读取(1-5)中训练得到的个人情感唤醒度预测识别模型,将标准化后的信号特征值作为输入,计算得到该时刻个人情感唤醒度预测值。
在已有的实验中,该方法的预测效果已经达到了较好的水平(如附图3所示)。其中,实线为情感唤醒度评估值(即人为评估值),虚线为情感唤醒度预测值(即使用上述方法计算得到的预测值)。通过对于实验数据的分析可以发现,预测结果有效性为81.34%。同时,由于在传统的心理学评估中主要关注情感唤醒度变化趋势和取值区间,少量的数值误差并不影响其预测值的使用。
- 还没有人留言评论。精彩留言会获得点赞!