用于改善疾病诊断的系统和方法与流程
本申请要求2016年1月22日提交的美国临时申请第62/281,797号的权益,其整体通过引用并入本文。
2014年3月13日提交的相关专利申请pct/us2014/000041(通过引用以其整体并入本文)描述了使用用于相关性分析的自变量来改善疾病预测的方法,该自变量不是直接测量的分析物的浓度,而是称为“邻近度分数”(proximityscore)的计算值,该值根据浓度计算得到并且还针对特定年龄(或其他生理参数)被归一化,以消除年龄偏移和当疾病状态从非疾病转变为疾病时浓度值随生理参数(例如,年龄、绝经状态等)偏移或改变的非线性。
本发明涉及用于改善疾病诊断准确性的系统和方法,并且涉及所测分析物与二元结果(例如,非疾病或疾病)以及更高阶结果(例如,疾病的多个阶段中的一个)的相关性的关联诊断测试。
背景技术:
诊断医学长期以来一直承诺,蛋白质组学,即与疾病状态相关的多种蛋白质的测量会产生突破性诊断方法,用于迄今为止针对疾病的研究尚未产生简单可行的血液测试的疾病。癌症和阿尔茨海默病便是两个。在很大程度上,一个主要问题归结为样品的蛋白质(或其他生物分子)浓度测量受到与其他病症或药物相关的因素(如对酒精是否有规定)干扰,或受到对生物分子浓度测量反映出地理影响和环境影响的因素干扰。在将被用作评估相关性的模型基础的具有已知疾病和非疾病状态的大群体中,如果没有数千种也有数百种影响所选生物标志物的上调或下调的病症或药物。此外,生物系统表现出复杂的非线性行为,这使得在相关性方法中难以建模。
附图说明
当结合附图考虑时,通过参考以下详细描述,将更容易获得本发明及其许多伴随的优点的更好和更完整的理解,其中:
图1显示了400名已被诊断患有乳腺癌(红色)或未患有乳腺癌(蓝色)的女性中两种典型的重要生物标志物il6和vegf。
图2显示了图1中所示400名女性的相同的两种生物标志物il6和vegf的邻近度分数图。
图3显示了400名被诊断患有乳腺癌和未患有乳腺癌的女性的生物标志物vegf的群体分布。
图4显示了生物标志物psa和tnfα平均浓度值的年龄分布。
图5显示了在水平轴上绘制的il6和vegf邻近度分数以及在垂直轴上绘制的群体分布的3d图。
图6是图5的水平轴向下旋转得到的图,其显示蓝色(非癌症)和红色(癌症)样品的水平分离。
图7是显示绘制的il6、vegf和il8的3d图。
图8显示了图7绕垂直轴旋转并向后倾斜得到的图。
图9显示了图7通过绕原点旋转以看见背面的图。
图10显示了图7向上旋转以显示在前面的红色(癌症)样品的图。
图11显示了随着癌症从健康进展至乳腺癌3期,对五种乳腺癌生物标志物的作用。
图12是用于卵巢癌的生物标志物ca125和he4的3d图,其中在垂直轴上示出了邻近度分数的群体分布。
图13是图12旋转以更清楚地显示he4生物标志物的群体分布的图。
图14是图12向下旋转以更清楚地显示这两种肿瘤标志物的两个轴分布的图。
图15显示了在3d空间中绘制的ca125、he4和afp肿瘤标志物。
图16显示了用于卵巢癌的roma测试的单独的ca125、he4的roc曲线和复合roc曲线。
图17显示了本申请中讨论的乳腺癌测试的roc曲线。
图18显示了图17中放大的roc曲线,其显示了图表左上部分附近的分数。
图19显示了一个方程组的浓度向邻近度分数的转换。
图20显示了另一个方程组的浓度向邻近度分数的转换。
图21显示了具有折叠在另一区域之上的区域的另一个方程组的浓度向邻近度分数的转换。
图22显示了用于构建训练集模型的任务流程图。
图23显示了具有大的非线性分布的程式化的邻近度分数分布。
图24显示了具有被抑制的大的非线性分布的程式化的邻近度分数分布。
图25显示了如训练集要求的具有50%:50%的疾病与非疾病分布的程式化的邻近度分数分布。
图26显示了具有疾病与非疾病真实分布的程式化的邻近度分数分布。
图27显示了具有通过折叠修正的疾病与非疾病真实分布的程式化的邻近度分数分布。
图28显示了生物标志物vegf转换后得到的群体分布。
技术实现要素:
传统的蛋白质组学方法认为“真理”在于测量的原始浓度值,并且他们的实践者来自生物学或临床化学背景。相反,本发明的方法完全偏离“真理”在于这些原始浓度值这一概念,并且基于如下所述的浓度意指什么的更深层解释。这些显著改善了回归方法的性能、神经网络解决方案、使支持向量机降噪,并使其他更强大的相关方法向前发展。解决方案部分来自测量值的数学运算和随机噪声抑制。所有测量值由所需的信号和噪声组成。数学运算证明,通过对所需信号进行多次采样可以消除噪声。通过这种采样将噪声分离成相关噪声(与测量采样方案同步)和不相关或随机噪声。通过样品数的平方根来减少随机噪声。通过这种多次采样可以非常准确地推导出信号和相关噪声(称为偏移)。最后,可以在没有信号的情况下通过测量来确定偏移。这些方法例如用于在比期望信号大数百倍或数千倍的噪声的存在下从冥王星轨道之外传输来自具有极低瓦数发送器的航天器的图像。
在蛋白质组学的情况下,对于任何一个样品(针对疾病进行检测的个体),噪声得到及时固定。本领域技术人员会理解,本发明的方法可以应用于所有类型和类别的生物标志物和生物分子的评估,但是为了方便起见,在以下很多的讨论中使用了蛋白质和蛋白质组学。诊断必须立即进行,而不是在采样的几个月后进行。因此,必须使用稍微不同的策略,并且返回的信息与航天器情况稍有不同,但基础数学运算是相同的。在蛋白质组学的情况下,来自已知组(疾病和非疾病)的个体的数百个不同样品测量值被用于确定信号(疾病)和偏移(非疾病)的平均值。这些参数的准确性仅受采样数的限制。一旦确定了这些平均值,便可以开始将一些合理性应用于图1所示的图中。对于个体而言,该方法不能完全确定疾病或非疾病的准确值,因为任意给定样品的“噪声”是及时固定的。然而,简短的思维实验表明该参数不仅无用而且并不存在。例如,个体必须得病以尝试测量疾病的“平均值”,而非疾病平均值对于一个样品则没有意义。对于该个体,可以长时间测量基线,但其也会被上述蛋白质组学差异干扰。当然,在一个个体中对这些差异的认识进行管理会更容易。然而,疾病平均值将需要再次基于庞大的群体调查。在这种情况下,有用的信息通常是群体的平均值,然后通过处理如下所述的原始浓度,这些平均值可以用于将未知的样品放入正确的“桶”中,即疾病或非疾病。
本申请描述了对先前技术的改进。例如,本发明教导了如何将第61/851,867号申请中提到的年龄或其他生理参数应用为元变量。另外,本发明教导了为何需要以及如何抑制蛋白质组学差异。因此,本申请讨论了使用从物理科学和数学中迁移过来的噪声抑制方法来抑制蛋白质组学中嵌入的信息,这些信息干扰了蛋白质组学浓度测量并且折损了使相关性预测能力最大化的能力。这种干扰是浓度测量中的差异,该差异例如是由个体患者可能患有或患过过多的病症或可能服用或服过过多的药物引起的。在癌症的情况下,这些病症是非恶性的,但在功能上仍然干扰样品并影响癌症和非癌症患者中的生物标志物水平和噪声。这些病症或药物引起浓度测量中的差异,这些差异通常将会与感兴趣的病症,例如乳腺癌相关。这些差异无处不在,并且不可能在一个个体中获得关于它们大小的知识以进行修正。该专利讨论了如何抑制或消除这些差异。
本申请还讨论了使用某些具有特定功能的生物标志物。这些生物标志物包括:细胞因子,其功能性(主要但不完全作为信号传导蛋白)在某些组内;免疫系统炎症标志物;抗肿瘤发生、细胞凋亡和肿瘤血管化和血管生成标志物以及已知的肿瘤组织标志物。这些生物标志物在疾病中具有活性,并且确实在癌症中具有活性。它们是免疫系统对肿瘤的存在或肿瘤对身体作用的反应。实际上,这些生物标志物度量了肿瘤周围的微环境,或免疫系统杀死肿瘤的行为或肿瘤生存和生长的行为。另外,这些生物标志物具有互补的功能性。即与相关性分析互补。当使用多维空间邻近度或支持向量机相关方法(也称为邻域搜索或聚类分析)进行分析时,这些生物标志物极大地改善了预测能力。当在该相关方法中使用的正交多维轴上查看时,这些生物标志物具有互补的功能性。即,正交性改善了分离,并因此改善了预测能力。下面讨论使用这些生物标志物来改善预测能力的方法。这种预测能力的改善通过使用保持正交分离的相关方法(例如,基于生物标志物的空间取向的相关方法)来实现。
用于减少或抑制基于蛋白质组学的浓度测量中嵌入的差异的方法使用电子和通信中所用的数学概念来抑制噪声。在蛋白质组学的情况下,疾病检测的过程始于收集已知患有疾病和未患有疾病的样品集。所收集的样品集可以包括血液样品、血浆样品、尿液样品、组织样品、其他生物样品等。所收集的样品集被称为训练集。然后通过相关算法将这些样品与两种状态,即非疾病状态或疾病状态相关联。该过程因蛋白质组学差异而降低。在测量物理学领域中通过应用随机噪声与样品测量值相差90度的概念来抑制随机噪声。这在数学上使随机噪声减少了与所采用的样品测量次数的平方根成比例的量。蛋白质组学差异由许多病症和药物引起,并且可能与用于诊断的感兴趣病症完全无关,这些差异可以被认为与感兴趣的测量值无关。因此,可以使用本申请中描述的技术来抑制该差异。
许多癌症生物标志物研究集中于肿瘤标志物。例如,用于肺癌的clia实验室测试、paula测试在其测试组中使用4种肿瘤标志物和1种肿瘤标志物抗体。该策略的问题在于,如果测试组中包括一种肿瘤标志物,则对于相同肿瘤的第二种肿瘤标志物可能是多余的,并且因此不会像功能性蛋白质那样增加同样多有用的预测能力信息。本申请公开了用于选择癌症的生物标志物的更优策略。
通常,相关方法使用逻辑回归或线性回归,或旨在采用多个参数使受试者工作特征(roc)曲线下面积最大化以使预测能力最大化的方法。这些方法中的许多方法实现了约80%的预测能力。以下讨论描述了要求保护的发明和其中使用了通常不与癌症检测相关联的生物标志物的方法。通常认为这些生物标志物具有有用的对癌症不充分的特异性反应。描述了一种使用正交空间邻近度相关技术的方法,其中生物标志物由于其功能的正交性而被选择。即,它们的功能不会相互影响。使用多种肿瘤标志物似乎会迫使增加预测能力。然而显示出,使用不与某些组内的癌症特异性相关联的生物标志物,免疫系统炎症标志物,抗肿瘤发生、细胞凋亡和肿瘤血管化和血管生成循环标志物以及单一已知的肿瘤组织标志物可以产生远胜于仅肿瘤标志物的预测能力。使用这些组可以将可能冲突的病症的数量缩小到非常低的水平,所述可能冲突的病症会呈现假阳性测试结果。此外,本文已经表明,癌症使这些生物标志物以高特异性方式反应,从而产生非常高的测试灵敏度。
实际上,本发明解决了本领域中的许多问题。例如,本领域的方法破坏或消除了包含在生物测量中的许多信息。浓度测量总是跨越许多(5个或更多个)数量级。这些范围被压缩并强制取平均值,并且聚集在由这些平均值所固定的区域中。这些分析中使用的信号传导蛋白的高度非线性行为的信息被消除。远离的数据或离群数据被迫“看起来”像平均值附近的普通数据。
本发明如下解决了该问题。在一大组已知的疾病和非疾病样品中,仅有两条有用的信息可用于回答诊断问题,即疾病的平均值和非疾病的平均值。如本申请中所讨论的,可以抑制所有其他信息。生物学中的传统观点是,原始浓度值或其有限变型(例如,浓度的对数)中的信息在确定疾病-非疾病诊断的准确性(真实性)方面是有意义的。两种生物标志物的对数/对数图主要由蛋白质组学差异(噪声)主导的概念一直未被注意到或似乎与当前的知识相反。
本领域方法的另一个缺点是,一个样品可以具有癌症(上调的炎性)和免疫抑制状况(下调的炎性),从而该样品可能具有低的促炎反应,由此迫使这些样品的“促炎”行为进入非癌症的箱中。
本发明通过包括阐明肿瘤和免疫系统的其他作用的其他信号传导蛋白来解决上述问题。这种迫使它们进入它们各自的“分组”区域的方法往往会有助于掩盖上述情况。在某种程度上,免疫抑制状况在这种情况下被包括在非癌症训练组中,并且许多类似的情况将得以缓和。这适用于此方法中使用的所有其他功能参数。只有当非疾病状况恰好模拟疾病状况时,才将导致假阳性。在癌症的情况下,只可能找出可以模拟癌症的多种异常非癌症状况。例如,具有bph(psa升高)、自身免疫疾病(il6和tnf升高)和引发强烈的血管化的状况、严重伤口(il8和vegf升高)的男性将会模拟疾病。此外,无论如何接近相关性,都会出现迫使炎症反应上调和下调的重复状况的这种情形。要求保护的发明的方法抑制了其影响,其他人可以简单地尝试与非疾病和疾病趋势线(例如,浓度值的逻辑回归)相关联。
本领域方法的缺点的另一个实例是单一样品的疾病或非疾病的生物标志物的平均值与组平均值是相同的。
如果这些参数对于单一分离的样品是已知的,那么它们可能会在检测非疾病向疾病转变的任务中做得更好。但事实是这些参数并非常规地(逐年)针对患者进行测量,实际上如今它们根本没有被测量。此外,直到个体患病之前,不可能确定对于疾病状态的个体平均值。因此,这种迫使它们看起来像组平均值的测定是当前进行这类诊断的有价值的策略。对于一项单独的专利(仅针对非疾病)年复一年地记录这些参数的概念可能正是最终解决该问题的更好方法。如果没有这种生物标志物行为的个人模式,试图了解疾病和非疾病的真实平均值不仅对单一个体而言是不可能的,而且也是不相关的。唯一有价值的信息是群体中疾病的组行为,即非疾病和疾病的平均值。
本发明涉及真实随机噪声,而不涉及与功能或行为相关的噪声,尤其是在该功能或行为与信号有关联的情况下。因此,当所谓的外来信息实际上是由这些生物体功能所必需的信号传导蛋白产生时,它就不能在蛋白质组学中起作用。在那些情况下,噪声不是随机的,而是与一些未知功能相关联。
这些测量的浓度水平确实与生物体的作用或反应有关,然而,与信号相比,它们不需要完全不相关(和随机)。测量相关噪声的行为理论上迫使噪声的其他分量不相关。此外,存在数百种驱动这些蛋白质的作用的病症,并且训练集中使用的数百个样品中的任一个或多个的存在使得它们可能的相关误差为零。
总之,许多实践者会担心在实施这些技术以消除外来信息时浓度信息丢失。然而,与传统技术相反,本发明人已经开发出分析方法,对于该方法,期望确定盲样在非疾病组还是疾病组的群体中的唯一有用的信息是总群体中组的平均值。当然,原始测量数据中还存在其他信息。例如,如果训练集还具有针对每个癌症病例的癌症阶段信息,并且期望确定癌症阶段为0还是更高,则0期的群体平均值和0期之上的所有阶段的平均值是有用的。在这种情况下,训练集模型将由分为两组的癌症样品组成:1)0期和2)1期及以上。如果这些组的平均值不同,那么如果在模型内再次将与平均值无关的信息归零,则将产生预测能力。该病例(癌症阶段)的平均值与癌症检测的情况不同,并且模型减少了差异信息。
可以预期,当创建或利用指示被检查患者中疾病状态的概率的评估模型时,将需要多于一种分析物以在疾病和非疾病状态之间提供足够的分离。本领域技术人员会理解,多种分析物使得分离更准确,并且通常会使用两种、三种、四种、五种、六种或更多种分析物。
具体实施方式
在描述附图中所示的本发明的优选实施方案时,为了清楚起见,将采用特定术语。然而,本发明不旨在限于因此选择的特定术语,应理解,每个特定术语包括以相似方式操作来实现相似目的的所有技术等同物。出于说明性目的描述了本发明的几个优选实施方案,应理解,本发明可以以附图中未明确示出的其他形式实施。
出于本申请的目的,为了便于理解,使用以下定义:
“分析物”指用于测量的感兴趣的化合物。在蛋白质组学的情况下,分析物是蛋白质,测量方法通常是免疫测定法。测量单位是以被采样的生物流体或组织的每单位体积的质量单位表示的浓度。浓度值与医学诊断程序相关。分析物会被认为是“生物标志物”的更通用的术语。分析物可以是化合物,例如在患者血液中和外部世界中发现的葡萄糖,以及通常仅在患者血液中发现的蛋白质。除非讨论具体差异,否则这些术语在本文中可以互换地使用。
“分析灵敏度”定义为零校准以上的三个标准差。低于该水平的浓度的诊断表现不被认为是准确的。因此,低于该水平的临床相关浓度不被认为是准确的,并且不用于临床实验室中的诊断目的。在统计学上,分析灵敏度水平的测量处于99.7%的置信水平。
“个体的基线分析物测量值”是个体患者从非疾病状态到疾病状态转变的感兴趣的生物标志物的测量值集合,其在一段时间内对单一个体进行多次测量。当个体患者没有患病时,测量非疾病状态的基线分析物测量值,或者,当个体患者患有疾病时,确定疾病状态的基线分析物测量值。这些基线测量值被认为对于个体患者是唯一的,并且可以有助于诊断该个体患者从非疾病到疾病的转变。疾病状态的基线分析物测量值可以用于诊断该个体中疾病第二次或更多次的发生。
“双标志物”是两个邻近度分数的集合,当以两轴图(或网格)绘制时,两个邻近度分数被归一化并且相对于从非疾病到疾病状态的生物转变在功能上与元变量的变化相关联,并且在下面被称为“双标志物平面”。
“生物样品”指从受试者抽取的组织或体液,例如血液或血浆,并且可以从该生物样品测定诊断上有意义的分析物(也称为标志物或生物标志物)的浓度或水平。
“生物标志物”或“标志物”指受试者的生物样品的生物成分,其通常是在体液中测量的蛋白质或代谢组学分析物,例如血清蛋白。实例包括细胞因子、肿瘤标志物等。本发明人预期,在本发明的方法中可以使用其他生物标记,例如身高、眼睛颜色、地理因素和/或在群体内变化并且是可测量的、可确定的或可观察的其他测量值或属性。
“盲样”是取自无已知的给定疾病诊断的对象的生物样品,并且期望为他们提供关于疾病的存在或不存在的预测。
“最接近”指训练集点与被评分的网格位置的距离。二维网格的距离将是从网格位置到训练集点的坐标距离的斜边。对于更高维度,距离将是距离的平方和的平方根。最接近的训练集点将是具有到被评分的网格位置这一距离的最小值的那个点。
“疾病相关功能”是生物标志物的特征,其是疾病继续或发展的作用,或者是身体阻止疾病进展的作用。在癌症的情况下,肿瘤将通过要求血液循环增长来生存和繁殖而作用于身体,并且免疫系统将增加促炎作用以杀死肿瘤。这些生物标志物与不具有疾病相关功能的肿瘤标志物形成对比,但是被丢弃到循环系统中并因此可以被测量。功能性生物标志物的实例是引起免疫系统的作用的白介素6,或肿瘤分泌以引起局部血管生长的vegf,而非功能性生物标志物的实例是ca125,其为一种位于眼睛和人类女性生殖道中的结构蛋白并且没有通过身体杀死肿瘤的作用或通过肿瘤来帮助肿瘤生长的作用。
“生物标志物运动行为”是当在正交轴上绘制浓度或邻近度分数时上述定义的疾病相关功能性生物标志物的运动。此外,如果这些疾病相关功能性生物标志物具有正交功能性,则它们将远离或朝向多维图的原点前进,其中每个轴表示测量的浓度或该测量值的替代值(例如,邻近度分数)。这种运动在图中引起非疾病与疾病的分离,并会显著改善预测能力。
“足够精细以适用于诊断”表明所绘制网格的划分具有足够的间隔尺寸以清楚地区分非疾病指征和疾病指征,并以足够的间隔尺寸对未知样品进行评分,以便可以对疾病的概率进行医学判断。诊断可以针对一些重要的医学问题,而不是仅仅针对非疾病和疾病,例如疾病状态的内部分类,包括癌症阶段或无症状与症状性莱姆病。本领域技术人员(例如,医生)可以容易地确定何时间隔尺寸是足够的。
“孤立点”是来自单一患者的训练集数据点,其远离其他训练集数据点。当通过邻近度对这些点附近的网格点进行非疾病和疾病的评分时,它们将通过该孤立点的诊断而过度影响这些周围点。未决申请的系统和方法解决了这种过度的影响。用于改善该孤立点问题的过程的最佳品质因数是网格上训练集数据点的多维空间的标准差。发现7或更高的标准差产生较差的结果,而3或更小的标准差产生更好的结果,即关联的准确性。当然,这些值是相对的,并且对于其他实例可能有所不同。
“检测限”(lod)定义为“零”浓度校准值以上的浓度值2个标准差。通常,零校准运行20次或更多次重复,以得到测量值标准差的准确表示。低于该水平的浓度测定值被认为是零或不存在,例如,对于病毒或细菌检测而言。出于本发明的目的,当样品以一式两份运行时,可以使用1.5个标准差,但是优选使用20次重复。需要单一浓度数的诊断表示通常并不导致低于该水平。检测极限水平的测量值在统计上处于95%的置信水平。使用本文讨论的方法预测疾病状态不是基于单一浓度,并且显示在基于lod的浓度以下的测量水平上进行预测是可能的。“低丰度蛋白质”是血清中非常低水平的蛋白质。本说明书中使用的该水平的定义包括血清或血浆中以及从中抽取样品的其他体液中小于约1皮克/毫升的水平。
“低丰度蛋白质”是血清中水平非常低的蛋白质。本申请中使用的该水平的定义包括血清或血浆中以及从中抽取样品的其他体液中小于约1皮克/毫升的水平。
“映射”是将给定集(域)中的每个元素与第二集(范围)中的一个或多于一个元素相关联的操作。在这种情况下,映射将测量的浓度值(域)与邻近度分数(范围)相关联。
“元变量”指给定对象的除分析物和生物标志物的浓度或水平之外的特征的信息,但其对对象而言不一定是个性化的或独特的。这样的元变量的实例包括但不限于对象的年龄、绝经状态(绝经前、绝经期和绝经后)以及其他条件和特征,例如青春期、体重、患者居住的地理位置或区域、生物样品的地理来源、体脂百分比、年龄、种族或种族混合或时代。
“归一化浓度-年龄变化”指在浓度测量中除去非疾病到疾病转变的固有的年龄相关的变化。这种“归一化”行为除去了降低(通过涂抹)浓度与疾病转变的相关性的年龄因素。这种归一化体现在“邻近度分数”变量中。
“归一化浓度的中点值”指浓度测量值,其是疾病和非疾病的两个平均值的平均数。该参数随年龄而偏移。当映射为邻近度分数时,除去浓度测量的年龄偏移。
“群体分布”指给定对象群体的生物样品中特定分析物的浓度范围。特定“群体”是指但不限于:从地理区域、特定种族或特定性别中选择的个体。并且,如本申请中所述选择使用的群体分布特征还预期在较大的限定群体中使用两个不同的亚群,这些亚群是已被诊断为具有给定疾病状态(疾病亚群)和不具有疾病状态(非疾病亚群)的群体成员。群体可以是期望预测疾病的任何组。此外,预期适当的群体包括那些具有相对于疾病进展的其他阶段已进展到特定临床阶段的疾病的对象。
“群体分布特征”可在生物标志物的群体分布内确定,例如特定分析物的浓度的平均值,或其中值浓度值,或浓度的动态范围,或者群体分布如何落入根据各种生物标志物的上调或下调程度可识别为不同峰的组中,以及随着患者经历从非疾病到疾病状态的生物转变或进展而受到疾病的发作和进展影响的感兴趣的元变量。
“预测能力”指诊断测定或测试的灵敏度和特异性的平均值,或者1减去错误预测的总数(假阴性和假阳性)除以样品总数。
“邻近度分数”指测量的生物标志物的浓度的替代或替换值,实际上,其是可用于诊断相关性分析的新的自变量。邻近度分数与测量的生物标志物分析物的浓度相关并且由其计算,其中这样的分析物对于给定疾病状态具有预测能力。使用感兴趣的经元变量调整的群体分布特征来计算邻近度分数,以针对期望进行诊断的给定患者转换预测性生物标志物的实际测量浓度。
“切割多维网格”对于减少构建模型所需的计算时间是有用的。在这种情况下,沿每组正交轴将多维空间(5维)切割成2维切片。对于5维的情况,这产生10个“双标志物平面”(6维将产生15个平面)。然后将训练集数据绘制到每个平面上,并且再次将平面切割成每个轴上的网格部分。因此,每个双标志物平面是双平面上的完整多维网格的投影。
“拓扑不稳定性”是双标志物平面的网格上的区域,该区域中的点位于拓扑的陡坡部分。拓扑是多维相关计算的形状,其考虑所有测量的自变量(即,所确定的生物标志物的浓度)和元变量。对于元变量的单一值,这种拓扑对于五种生物标志物测量(可以更多)至少是五维的。拓扑的形状随着元变量值的变化而变化。这种多维拓扑可以使十个双平面切片分别经过拓扑而使其通过眼睛可视化。这使得计算的疾病分数由于测量噪声而处于错误的“风险”。可以通过对疾病和非疾病状态的预测能力的各个双标志物图加权并通过考虑其他因素如拓扑测量不稳定性和简单的测量误差来导出分数。分数范围可以是任意的,并且该值表示患者处于疾病或非疾病状态的百分比概率。
“训练集”是具有已知的生物标志物浓度、已知的元变量值和已知诊断的一组患者(200个或更多个,通常达到统计显著性)。训练集被用于确定“双标志”平面的坐标轴值“接近度分数”以及来自用于对单独的盲样进行评分的聚类分析的分数网格点。
“训练集模型”是由训练集构建的一种算法或一组算法,其允许评估关于受试者(或患者)患有疾病或没有疾病的概率的预测结果的盲样。然后使用“训练集模型”来计算盲样的分数用于临床和诊断目的。为此目的,提供任意范围的分数,该分数指示疾病或非疾病的百分比可能性或正为患者开发诊断的医疗保健提供者所优选的一些其他预定指示读数。
“不一致训练集模型”(或“辅助算法”)是辅助训练集模型,其使用不同的现象学数据还原方法,使得双标志物平面的网格上的单独的点不太可能在主相关训练集模型和次辅助算法中不稳定。
“空间邻近度相关方法”(或邻域搜索或聚类分析)是用于确定独立变量与二元结果之间的相关关系的方法,其中独立变量被绘制在正交轴上。盲样的预测是基于与所谓的“训练集”数据点的数目(3个、4个、5个或更多个)的邻近度,其中结果是已知的。二元结果评分是基于从相对结果的多维点至训练集点的盲点计算的总距离。最短距离决定了单个盲数据点的评分。可以在穿过多维网格的双标志物平面上进行相同的分析,其中单个双标志物平面分数与其他平面的分数组合以产生总分。通过空间使用切割或二维正交投影可以减少计算时间。
“正交功能”是在适用于例如衔接子、效应子、信使、调节蛋白等低水平信号传导功能的方法的描述中使用的术语。这些蛋白质具有特定于身体对疾病的反应或疾病对身体的作用的功能。在癌症的情况下,这些蛋白质通常被认为是免疫系统作用物,例如炎症或细胞凋亡和血管化功能。一种肿瘤标志物被认为达到正交的程度,它不代表特定的信号传导功能。应尽可能选择标志物,使其独立于其他标志物。换句话说,一种标志物的不同水平不应该与其他标志物相互作用,除非疾病本身影响两者。因此,如果出现一个正交函数的变化,则这些变化本身不会驱动其他变化。血管化和炎症功能被认为是正交的,因为可以选择主要仅执行这些功能之一的蛋白质。当在多维空间邻近度网格上绘制时,这些蛋白质将独立地起作用,并且如果疾病引起两者的作用,它们将放大预测能力。许多细胞因子具有多种相互作用的功能,因此任务是选择功能和蛋白质,使得这种相互作用被限制。“功能正交性”的程度是相对的,事实上可以认为所有细胞因子都有一定程度上的相互作用。许多细胞因子具有严格重叠的功能,而许多细胞因子则没有。白介素8涉及促炎和抗炎作用以及血管生成。在例如癌症的疾病中,白介素8主要通过血液循环发挥作用,但是生物体内的其他现存病症很可能正好驱动该细胞因子的作用,从而导致蛋白质组学差异。具有功能正交性的最佳生物标志物的选择至多是根据被诊断的病症而折衷。
本申请中使用的“个体蛋白质组学差异”包括蛋白质组学测试结果、浓度测量的概念,根据定义,其包含与诊断感兴趣的任何特定病症或疾病无关的或有帮助的过多信息。这种差异是由影响感兴趣的蛋白质组学生物标志物的上调或下调的数百种病症所引起的。这些生物标志物可以与疾病具有非常高的相关性并且实际上与疾病有因果关系。这些不相关的病症影响生物标志物并掩盖或干扰关于感兴趣的疾病的信息,从而使得疾病与非疾病的关联变得困难。这种差异虽然本身不是随机噪声,但可以被比作随机噪声,因为它与感兴趣的病症(例如乳腺癌)以及例如这种癌症的筛查诊断不相关。因此,通过对许多单独样品进行取样并确定仅针对乳腺癌的每种生物标志物的平均值,可以准确地提取关于筛查诊断的实际信息。相反病症,即非乳腺癌的平均值可以通过测量许多这样的已知非乳腺癌样品来确定,以达到一定程度的准确性。参见thecomplexityparadox(kennethl.mossman,oxforduniversitypress,2014),其中适当地总结了蛋白质组学研究者所面临的挑战:“复杂生物系统中固有的非线性动力学导致不规则和不可预测的行为”。
“信号(疾病)或空值偏移(非疾病平均值)”定义为针对足够大的群体测量的平均值,以有效地抑制或除去上文定义的蛋白质组学差异(噪声)。用于测量这些参数的队列的定义是重要的。信号(疾病)平均值将由医学科学确定为真正具有该病症。该病症可以是确定的疾病或者是这些具有可能在治疗中感兴趣的特定特征的疾病的子集。它可以恰好是疾病(例如,乳腺癌),或者它可以是疾病、癌症阶段或肿瘤生长侵袭性的特征。还必须根据诊断需要分离的病症小心定义空值偏移(非疾病)。就疾病筛查而言,通常接受健康筛查的人群是适当的。例如,这将排除仅遭受创伤的样品,但会包括影响筛查群体的年龄以及最重要的所使用的生物标志物的病症。信号(疾病群体)也会受到这种蛋白质组学噪声影响。在不具有感兴趣的亚病症的疾病组内,空值偏移(非疾病)可能是相反的(例如,对于前列腺癌,这可能是疾病的非侵袭性形式)。同样,这两个参数的平均值必须由诊断病症的医学科学预先确定,以确定准确的平均值。
“蛋白质组学平均值分离”决定了感兴趣的生物标志物是否可以实际将两种感兴趣的病症的信号(疾病)或空值偏移(非疾病)分离开。如果在已知群体中精确测量平均值并且它们产生分离(值不同),则将实现诊断预测能力。
“蛋白质组学差异抑制”是抑制上述蛋白质组学差异(噪声)的方法。这种抑制首先在被称为训练集的已知样品组上完成。目标是调整训练集样品的浓度值,使得它们与医学确定的诊断一致。数学方法仅限于强制使预测模型的预测评分与已知样品一致的目标。该方法可以涉及压缩、扩展、倒置、反转、将所测变量的部分折叠到其自身上,得到多个输入(浓度)产生相同输出(邻近度分数)的函数。其原因有几个(参见下面的群体分布偏差),并包括抑制差异“噪声”的目的。此外,查找表或类似工具可用于转换,以及用于其他数学方案。这种相同的噪声抑制方法在应用于盲样或验证样品时,将产生相同的噪声抑制。转换后的结果称为邻近度分数。抑制蛋白质组学差异是消除或抑制与感兴趣的病症不相关的差异的数学变换,在这种情况下,非乳腺癌和乳腺癌由如在每个庞大已知群体中所测量的两者的平均值限定。
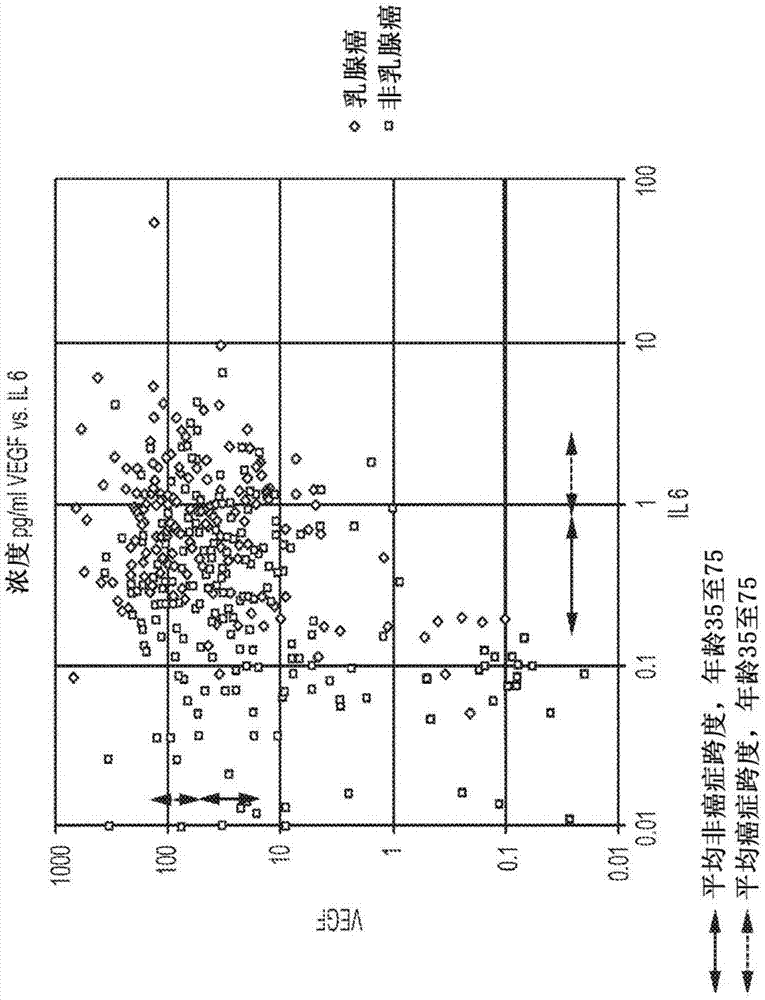
现在参考附图,图1显示了400名已被诊断患有乳腺癌(红色)或未患有乳腺癌(蓝色)的女性中两种典型的重要生物标志物il6和vegf。它是本文件中描述的乳腺癌蛋白质组学诊断方法中使用的两种生物标志物白介素6和vegf的二维图。该图是这些生物标志物的原始测量浓度的对数图。红色数据点通过活组织检查被诊断为患有癌症。蓝色数据点是每年筛查乳房造影的女性代表群体。没有作出努力来消除该群体中的任何非恶性病症或疾病状态。红色和蓝色箭头显示出每种生物标志物根据年龄的乳腺癌和非乳腺癌的平均值的浓度跨度。换句话说,在35岁至75岁的年龄范围内,il6的乳腺癌浓度的平均值为约0.9pg/ml至约2.1pg/ml。该数据针对约400名50%癌症和50%非癌症的女性,并使用otracescdx免疫化学系统和otracesbcseradx乳腺癌检测试剂盒在俄罗斯联邦莫斯科的gertsen研究所进行测量。
该图是数百个具有其他生物标志物的这类图的典型,在这类图中,非疾病和疾病两种状态难以区分。事实上,这种不良区分在所有生物标志物中都是特有的。随着女性从非疾病转变为疾病,生物标志物有一些向上调节,但转变显然不明显。该图的问题在于,该图中大多数(如果不是全部)女性具有许多与乳腺癌无关的病症,这些病症中的一些可能已知,但大部分未知。许多人服用处方药,这也会影响这些细胞因子的上调或下调。因此,图受到干扰或具有不可知的信息噪声,这些不可知的信息扰乱这些浓度与疾病转变的相关性。在thecomplexityparadox(kennethl.mossman,oxforduniversitypress,2014)中,适当地总结了蛋白质组学研究者所面临的挑战:“复杂生物系统中固有的非线性动力学导致不规则和不可预测的行为”。
蛋白质组学研究倾向于通过应用大数计算方法尝试将疾病与非疾病状态之间的分离最大化来解决该问题。这些研究往往分为两类,神经网络和所谓的支持向量机。生物信息学中的计算智能技术;aboulellahassanien,eimantamahal-shammari,neveeni.ghali;computationalbiologyandchemistry47(2013)37–47。神经网络策略是在输入(生物标志物浓度)和输出(疾病和非疾病)之间放置“神经”节点。通常存在足够的节点,使得每个输入具有通过“神经”节点到达每个输出的唯一路径。然后,大数计算通过为每个输入至每个输出的每条路径分配增益或衰减(在神经节点内)来尝试解决相关性问题。支持向量机通过穿过生物标志物曲线空间的弯曲平面或曲面来工作。这些曲面或平面通过所有可能的独特方案被弯曲、折叠、折弯、移动和旋转,从而寻找具有最佳分离能力的弯曲面。这些方法全部使用所谓的具有已知结果的训练集以试图将智能融入复杂性中。原理是如果训练集生成的模型正确,模型将使总群体中的未知样品得到正确的结果。这些方法不能消除图1中典型的复杂混乱。
第一步是调和关于图1中乳腺癌的可知的内容。图中只有四条有用的信息。它们是非乳腺癌和乳腺癌的两种生物标志物的平均值。除了这些平均值,可以通过每个单独样品与平均值的关系对其进行评级。只有四个等级,1)单独样品小于非乳腺癌的平均值;2)大于该值但小于乳腺癌/非乳腺癌平均值之间推导的中点平均值;3)在该平均值的中点以上且低于癌症的平均值;和4)在乳腺癌的平均值以上。除此之外对于单独样品的任何信息是无用的,并且可以被认为是噪声。
该问题进一步显示在如下所示的表1中。该表显示了影响乳腺癌检测板中使用的蛋白质的上调或下调的各种病症或药物。该表必须被认为是非常有限的调查,并且事实上,可能存在许多未知的影响血清中这些蛋白质浓度的病症或药物(如对酒精是否有规定)。注意,仅对于il6和vegf列出了35种病症或药物。有趣的是要注意表格下面的图例。黄色高亮表明了影响两种蛋白质的病症或药物,褐色表明了影响三种蛋白质的病症或药物,浅红色表明了四种或更多种受影响的蛋白质。只有乳腺癌影响四种或更多种蛋白质,实际上所有五种蛋白质都受到影响。
表1
一些物理学家可能反对使用术语“噪声”,因为噪声通常被认为是随机的。这里讨论的蛋白质组学噪声是由病症、药物、环境因素或个体差异(例如遗传差异等)的一般不可知的行为引起的。“噪声”也可被称为“蛋白质组学差异”。然而,由于引起这些差异的情况如此众多并且在群体中随机分布,因此它们可以被合适地视为不相关的,或者像随机噪声一样,并因此如同随机噪声一样进行处理。这意味着,例如在一些样品中测量的离群很远的浓度中包含的信息是无用的信息,并且可以被削弱(数学上抑制)。
该评级和噪声削弱过程存在显著的复杂性。即,平均值随年龄的变化而显著变化。因此,通过上文1至4的等级将这些样品分类的数学方法也必须解决年龄偏移问题。该问题可能足够糟糕以致非疾病平均值在一些情况下将与不同年龄的疾病平均值重叠。需要一种基于年龄相关等级和噪声阻尼的新的自变量。将该新的变量称为“邻近度分数”。邻近度分数必须包含上述属性,包括:1)通过疾病和非疾病的方式被锚定;2)使疾病转变中的年龄偏移归一化(归零);3)通过它们与平均值的关系强制对单独样品进行排名;和4)在数学上抑制或压缩远离平均值的样品中的离群噪声。此外,必须保留远离或离群“噪声”样品中的原始浓度的聚类行为,以将其应用于下面讨论的保留空间关系的相关方法中。如果相关的关联性能得到改善,则实际上可以反转邻近度分数与原始浓度的关系。
图2显示了上述图1中所示的400名女性的相同的两种生物标志物il6和vegf的邻近度分数图。它是在通过执行本文所述分析步骤的otraces蛋白质组学计算引擎处理后上述图1中所示的相同的400名女性的图。该计算将原始浓度转换为邻近度分数。非乳腺癌和乳腺癌的平均值现在分别归一化为4和16,且中点或非癌症至癌症的转变点固定在略小于11处。现在,图1中显示的每个单独的数据点被强制放置在由邻近度分数平均值锚定的区域中,并且每个点保持其与经年龄调整的平均浓度值的关系,该平均浓度值与样品的年龄相关。对于两种生物标志物,非乳腺癌和乳腺癌的平均值现在分别被固定在7和15的邻近度分数处。对于该实例选择的接近性分数为0至20,然而,可以选择其他范围。此外,各个样品数据点被强制进入所固定平均值内的评级(1至4)区域中。在所固定的邻近度分数为11时,两种生物标志物处于非乳腺癌平均值和乳腺癌平均值之间推导的平均点处。邻近度分数为5、11和17的这些固定点针对年龄进行归一化。因此,无论年龄如何,恰好处于样品年龄的平均值或平均值之间的中点的浓度的原始样品将分别获得5、11或17的邻近度分数。当然,评分范围和固定的或归一化的点是任意的。包括很远的离群值在内的所有其他单独样品被压缩到平均值之间的空间中,并且每个原始浓度值通过其原始浓度与平均值及平均值中点的关系被强制进入平均值中点的适当侧。还注意到,区域1和2可以如区域3和4一样在维度图中重叠,以获得最佳分离。然而,1和2以及3和4根本不能重叠。
上面讨论的转换对于非乳腺癌至乳腺癌的转变非常有效。实际上,将非常远的离群值折叠到它们之间的空间对于疾病与非疾病的正常群体相差很远的情况是独特的(参见下面的讨论)。其他转换方法可以指示原始浓度分布的其他分布。该方法直接与原始数据分布的性质以及疾病状态分布的特征相关,并且是从模型构建过程导出而不是从第一原理推导出的因素。然而,平均值锚定与关于平均值的强制评级一样是重要的。
当这些新的自变量应用于根据本发明的各种相关方法时,结果得到显著改善。注意到大多数原始浓度数据现已转换为将其置于非乳腺癌和乳腺癌的新的固定平均值之间。该原因将在下面讨论。下面所示的表2证明了预测能力的改善,并且下面讨论了更多的改善。从表中可以看出,简单地从原始浓度转换为邻近度分数使回归方法改善5%,使神经网络改善7%。支持向量机改善10%。另一种相关方法称为空间邻近度相关法,其与支持向量机方法具有类似的改善。空间邻近度相关方法将在下面进一步讨论,但应该注意,该方法实际上使得支持向量机没有实际意义。支持向量机是一种数学方法,旨在找到两个状态之间的最佳相关分离面,其中两个状态的训练集数据的混合程度高并且该最佳面在视觉上是不可辨别的。支持向量机用作二元线性分类器,它将空间中的点映射成尽可能大的分离(面)。本文描述的计算方法将通过抑制上述噪声来产生这种分离。本发明要求保护的系统和方法将最佳分离平面还原到人眼可以看到的多维图上的位置,例如图2实例中的邻近度分数为11的中点。
表2
证据表明,通过关注生物标志多维空间中的上调/下调聚类而不是依据浓度测量中的信息的数据趋势,特别是在从原始浓度转换为邻近度分数之后,更加增强了预测能力的改善。回归方法和神经网络关注数据趋势,且不能保留任何空间分离信息。支持向量机和空间邻近度方法捕获这种空间分离信息(下面将详细讨论)以及蛋白质组学数据的聚类。
在该乳腺癌实例中,这些生物标志物因以下功能而被选择:作为免疫系统参与者对癌症发挥作用,或作为癌症对生物体作用(通常是肿瘤生长的血管化)的生物标志物,这些功能最好尽可能地独立于其他生物标志物功能。换句话说,一种生物标志物的不同水平不应该与其他标志物相互作用,除非疾病本身影响其他标志物的功能。因此,如果出现一个正交函数的变化,则这些变化本身不会驱动其他变化。这些蛋白质具有特定于身体对疾病的反应或疾病对身体的作用的功能。在癌症的情况下,这些蛋白质通常被认为是活性蛋白,例如炎症、细胞凋亡和血管化功能。许多细胞因子具有多种相互作用功能。因此任务是选择功能和蛋白质,使得这种相互作用被限制。
如果蛋白质组学差异被抑制,那么当这些蛋白质(或其他生物标志物)被绘制到正交轴上时,可以容易地看到它们的这种功能正交作用。如果它们在向疾病的转变中上调,那么移动将会是肉眼可见的,即生物标志物在维度网格中的疾病状态位置远离纵坐标。通过转换为邻近度分数,该维度运动中的这一信息得到显著增强(事实上,当使用其他分析技术时,蛋白质组学差异的干扰几乎完全掩盖了这一信息)。然而,当使用回归或神经网络相关方法时,该信息被丢失。
当使用相关方法固有的维度网格时捕获该信息。支持向量机方法如空间邻近度方法一样捕获该信息。如上所述,通过转换为邻近度分数而使支持向量机方法没有实际意义。在图2中,对于两种生物标志物,最佳相关性的最大分离面在邻近度分数约11处,即平均值的推导中点处。如果在该邻近度分数图上运行支持向量机,则只会确认眼睛对最佳分离的适当平面的识别,浪费了计算机计算时间和能量。因此,这些复杂功能的细胞因子的最佳可能用途包括与空间邻近度相关方法结合的功能正交性,从而产生预测能力的改善。还要注意,支持向量机没有指定如何完成实际的相关加权,只是指定了多维图中的最大分离平面。空间邻近度首先关注数据的聚类,然后关注从非疾病至疾病的转变中的数据趋势。
在本发明的实施方案中应用的空间邻近度方法包括多维空间,其中每种生物标志物一个空间。训练集中每种生物标志物的邻近度分数被绘制在多维空间中(在该乳腺癌实例中有5个维度)。该图被分解为网格,然后该五维网格中的每个点通过其与网格上的若干(15个至20个)训练集点最接近的邻近度来评分为乳腺癌或非乳腺癌。在被评分的空网格点的局部附近,通过乳腺癌和非乳腺癌的计数来评分。当仅“看到”乳腺癌时,在空网格点获得最大分数,反过来对于非乳腺癌也一样。然后将未知样品放置在该网格上并相应地评分。表2显示,将生物标志物的这种功能正交选择与邻近度分数转换(降噪和年龄归一化)相结合,对乳腺癌病例中的这些生物标志物产生了96%的预测能力。
空间邻近度相关方法存在三个必须处理的问题:(1)群体分布局部偏差;(2)空间密度局部偏差;(3)拓扑不稳定性。问题(1)和(2)可以在转换成邻近度分数的过程中处理,而问题(3)则通过不稳定盲样的相关性来处理。
群体分布局部偏差可以进行如下处理。根据设计,训练集应该具有非疾病与疾病样品的50%与50%的相等分割,否则模型将有偏差。如果群体中的疾病表现远达不到均等,那么这将产生疾病样品远远超过现实的网格中的区域,从而引起该局部群体分布偏差。乳腺癌仅占群体的0.5%。该问题可以通过将非乳腺癌样品的极低浓度和高比例的区域折叠到非疾病平均值附近的区域来缓解,从而改善该区域中对于疾病状态上调的生物标志物的分布。图3显示了这400名女性的原始浓度值以及这些蛋白质在向乳腺癌转变中的行动的复杂非线性性质。在图3中,蓝色和红色箭头显示这种折叠的方向。该行动还具有抑制这些极低水平样品中的无关信息的作用,并且再次作用于在上面讨论的图的较高乳腺癌优势侧。图3显示了患有和未患有乳腺癌的女性中vegf的原始浓度的群体分布,这种表现对于包括肿瘤标志物psa在内的所有五种生物标志物是共同的。这表明免疫系统的高度复杂和非线性行为。顶部的红色条是非乳腺癌和乳腺癌随样品的年龄改变的平均值范围。通常,平均值随年龄增加而增加(并非总是如此)。图3具有折叠到刚超过现在固定的非乳腺癌平均值的区域的极低浓度水平,并且它们现在与在非乳腺癌平均值附近及以上的浓度值重叠。对于图3中的图的乳腺癌优势侧进行相反的操作。
空间密度局部偏差是由蛋白质的复杂非线性上调和空间邻近度相关方法人为导致的。在非常高和低浓度的聚集之间的中间部分的孤立样品点将倾向于迫使网格的大部分被称为孤立点指示,即乳腺癌或非乳腺癌。当随着对原始数据的整个复合体进行压缩而向邻近度分数转换时,该问题也会得到纠正。
最后,必须保留上述聚类效果。因此,这种转换移位不能是随机的,并且必须通过可以在训练集和未知样品上重复的连续数学运算来完成。在非疾病至疾病转变伴随着完全或甚至部分年龄调整的下调的情况下,这些原则同样适用。
空间邻近度相关方法基于非疾病和疾病区域的拓扑呈现。当未知样品点位于深锥形或山谷形的拓扑区域时,这可能产生不稳定的输出。该方法中通过稳定性测试对这些点进行识别。然后,如果发现数据点不稳定,则通过二次模型纠正或确认,这被称为不一致,即现象学上的不同。通常在100个未知样品中,发现三至四个不稳定的样品,且一个或两个将被纠正,其他则被确认。
测量方法
在测量科学中,有一些在存在显著噪声的情况下进行测量的策略,其可以通过多次测量信号和噪声来降低或有效消除噪声。这些方法将通过数学方式利用以下事实,以任何所需的准确度来测量所需信号:1)存在一个待测信号,并且其可以被多次采样;2)如果信号随时间变化,则必须知道时间上的变化性;和3)测量方案必须与这种变化性相关。如果满足上述1、2和3,则噪声(或无关信息)将被分为两个部分:1)测量相关的噪声;和2)测量不相关的噪声。测量相关的噪声被称为空值信号或偏移(在电子学中有时称为dc偏移)。平均而言,不相关的噪声与相关的测量方案异相90°。该噪声可以通过对信号和偏移进行多次采样而降低。用样品数的平方根来降低噪声。通过关闭信号(使天线远离信号源)可以以相同的方式确定空值或偏移。在生物学或蛋白质组学中,传统观点认为,准确地预测疾病或非疾病状态的“真理”在于测量的原始浓度值,并且实践者来自生物学或临床化学背景。本发明的方法完全偏离“真理”在于这些原始浓度值的概念,而是认为“真理”在于浓度值含义的更深层解释(见下文)。因此,迄今为止还没有人将这些测量科学技术中的某些应用于生物学状态分离,因为本发明的方法必然消除了迄今为止被理解为必要的某些生物信息。
对于这些技术存在两种情况。这些技术都依赖于这样的概念:不相关的噪声平均与信号异相90°,并且所有测量由且仅由三个部分组成:1)信号;2)与信号同相的dc偏移或空值偏移;和3)噪声(或无关信息),其一般与信号和空值或偏移异相90°。信号是所需结果,空值或偏移是“噪声”的一部分,其在时间上不随测量采样方案而变化,并且噪声由于与期望信息无关的行为而随机或半随机变化。
第一种情况是采样率远低于噪声谱。在这种情况下,可以重复测量单一样品,并且每次测量将通过所采取的测量次数的平方根来减少噪声分量。如果信号在电磁载体上,则必须知道波长,并且接收器必须能够与其同步或相关(例如,锁相回路)。900次测量将使噪声降低30倍。只需要关闭信号重复这一过程来减去偏移,并为每个样品推导出最终结果,即准确的信号。
第二种情况是测量样品速率远快于单一样品的噪声(或无关信息)变化率。在这种情况下,一个样品的噪声固定在实际测量时间速率内。因此,不能通过随时间多次测量从一个单一样品中提取信息并降噪。这是针对单一样品的蛋白质组学测量所面临的情况,其目标是疾病状态检测。多天内相同患者的多个测量样品将不会产生可用于平均该样品中的无关信息的变化。噪声是静态的。
这种降噪方法的常见用途是在地球地形上进行多参数测量,目的是辨别目标与非目标或将对象识别为“特定对象”和“非特定对象”。在可能的情况下,测量可以是红外的、听觉的、视觉瞄准的(通过机器)和两个雷达带。单个测量可能是“静态的”,因此可以在许多地形情况和可能的目标和非目标上进行测量。最终,得到的纠正答案是基于目标、非目标的平均和噪声抑制的数学方案。
蛋白质组学中发现的差异不是随机噪声,而是基于一些病症或药物原因。然而,它们数量众多、无处不在,并且随机分布在感兴趣的群体样品中。此外,关于它们的发生和/或对单个患者的影响大部分是未知的,因此认为它们与测量方案不相关。因此,它们可以正当地被视为随机噪声。表1(上文)显示了这些病症或药物的非常有限的列表,这些病症或药物影响该乳腺癌实例中使用的生物标志物。
为了使用这些科学概念,空值或偏移将被认为是非疾病样品的平均值,并且信号将是针对每个测量和每个生物标志物的疾病平均值和空值之间的差异。所有与平均值不同的测量被视为无关信息或噪声。在这种情况下,不需要确定特定样品信号的实际值(癌症平均值减去非癌症平均值),而是在两种类型的许多样品中对其进行测量。然后使用未知样品的测量值来确定它是在具有癌症平均信号的组内还是在仅具有空值的非癌症组内。通过减少无关信息(噪声)的数学操作来减少这种情况。这可以通过相关方法来完成,其中锚定点是对于癌症和非癌症而言的每种生物标志物的群体平均值。数学操作的规则是简单的,只要对训练集和盲样进行相同的处理,任何改善相关性的操作都是可行的。本领域技术人员可以基于本公开中包含的解释和实例来调整分析。下面将讨论适合于这些生物测量的方法。
在针对任何一种具有已知非疾病和疾病状态的生物标志物进行的原始浓度值的大型采样中,存在两条有用的信息和无用的蛋白质组学差异。有用的信息是非疾病的平均值和疾病的平均值。然后,在针对任何一种生物标志物的原始浓度的一个样品中,只存在一条有用的信息,即浓度值相对于两个平均值以及平均值之间的推导中点的评级或位置,并且还存在无用的蛋白质组学差异。任务是抑制已知组内的蛋白质组学差异,然后将其应用于未知样品。
通过对具有已知疾病和非疾病状态病症的大量样品进行取样,可以将测量策略应用于这种情况。在这种情况下,策略是通过将许多测量来值取平均值来确定每个测量参数的平均值。100个患者样品使平均值不相关噪声“误差”降低10倍。然后,在数学上操纵这些已知组,以尽可能地消除将各个样品与平均值区分开的无关信息(噪声)。数学方法仅受限于强制使预测模型的预测评分与已知样品一致的目标。该方法可以涉及压缩、扩展、反转、变换、将测量变量的部分折叠到其自身上,得到多个输入(浓度)产生相同输出(邻近度分数)的函数。这样操作存在若干原因(见下面的群体分布偏差),并出于抑制“噪声”的目的。此外,查找表或类似工具可用于转换,以及其他数学方案。该方法可以包括这些方案中的一些或全部。该过程的目标是使每个已知的样品组进入其各自的正确组,即疾病组或非疾病组,其中相应的平均值作为锚定点。最后,得到的自变量值可能根本不像原始浓度值。将这一用于插入相关方法的新变量称为邻近度分数。它可能根本不像原始浓度测量值,事实上,浓度值可能无法从邻近度分数中唯一地恢复,因为最佳预测能力拟合可能导致邻近度分数值折叠回浓度值(一个邻近度分数值可以恢复为许多浓度值以供最佳“拟合”)。
然后可以使用复制这种精确方法以使未知样品或盲样进入各自的组,即疾病或非疾病组,这是基于各个样品的强制入组行为特征将会积极地推动模型对盲样的预测能力的概念。模型的第一级证据是其内部预测能力,以正确地推动已知组或训练集样品。最终的证明是产生的模型将未知(盲)样品正确地放入正确组(验证组)的能力。该最终证明还将要求模型或训练集大小足够大,以准确地表示在训练集模型之外的感兴趣总群体内测量的参数的统计。该方法可以被描述为在假设这种完全相同的强制将正确放置未知样品的情况下,在数学上已知样品集的强制入组行为。
如上所述,图1和图2显示了在双平面中绘制的两种生物标志物vegf和il6的实例。图1显示了以原始浓度值绘制的生物标志物。红色数据点是乳腺癌样品,蓝色数据点是非乳腺癌样品。红色和蓝色箭头显示乳腺癌和非乳腺癌样品的经年龄调整的平均值的浓度分布。倾向于认为该图是癌症与非癌症状态的事实。然而,更深层的事实是,该图已经覆盖了大量的信息,这些信息无法通过因果关系重新获取或被理解或合理化为研究中的两种病症,即乳腺癌或非乳腺癌。嵌入了分散的数据,即影响癌症(红色)和非癌症(蓝色)数据点的未知数量的非恶性病症。这些病症使数据分散并降低了相关性的准确性。此外,平均值的年龄偏移往往再次掩盖非癌症向癌症的转变。
上面的表1显示了可以不同程度地影响可用于诊断乳腺癌的血清中这些蛋白质浓度的各种病症中的一些。这些病症被嵌入总群体中,如表所示,痕量高达10%。还有更多。该表应被视作仅为有限的调查,通过调查科学文献而汇编得到。必须担心的是,导致该蛋白质组学差异的这些病症或药物中的大多数实际上是未知的。科学文献只关注这些病症或药物以及具有科学意义的这些生物标志物。
在寻求筛查特定疾病(例如,乳腺癌)的患者中,这些病症的存在通常是未知的,并且所提出的问题是未知患者适合哪个组,即非乳腺癌组或乳腺癌组。必须抑制未知差异,如在蛋白质组学差异中进行的测量科学中的“噪声”抑制,以回答该问题。注意到乳腺癌阳性患者和非乳腺癌浓度测量都被该无关信息干扰。此外,对于“健康”个体以及患有疾病的个体,这些生物标志物的“适当”值的概念是没有意义的。使这种浓度数据的分散有意义的唯一方法是通过锚定平均值并抑制浓度数据中的所有其他信息来显著抑制两个队列的噪声。结果是邻近度分数。可以说,对于“健康”或患病个体而言,这些浓度的“适当值”的概念是没有意义的。无关信息,即蛋白质组学差异“噪声”是导致图1中分散的原因。正是这种噪声抑制产生了图2中较干净的图。
第一步是调和图1中关于乳腺癌的可知的内容。图中与以下问题相关的信息是有限的:未知患者可能患有非乳腺癌疾病状态还是乳腺癌疾病状态。图中的信息是非乳腺癌和乳腺癌的两种生物标志物的平均值。除了这些平均值,可以通过每个个体样品与平均值的关系对样品进行评级。仅存在四个等级或区域:1)个体样品小于非乳腺癌的平均值;2)个体样品大于非乳腺癌的平均值但小于乳腺癌/非乳腺癌平均值之间推导的中点平均值;3)个体样品高于平均值的中点且低于癌症的平均值;和4)个体样品高于乳腺癌的平均值。此外,所述每种状态和每种生物标志物的平均值随年龄而偏移。因此,必须知道年龄与平均值之间的关系。对于任何一名患者,上述每个评级必须被限制为该患者年龄的平均值。对于个体样品除此之外的任何信息是没用的,并且可以被认为是蛋白质组学差异(噪声)。这五条信息(年龄以及平均值与中点的关系)是原始浓度测量的更深层解释。如上所述,当根据本发明评价该信息时,出人意料地反映了关于手头问题,即患者是非疾病还是疾病的真理。从而提供了一种指示根据检查患者中存在疾病状态的概率的方法。
最后,从原始浓度转移平均值和评级,使得平均值被归一化,并且所记录的等级被绘制在特定区域中。这种从原始浓度的转变以经年龄调整的平均值和经年龄调整的等级相对于平均值被锚定,为空间邻近度图和相关方法产生新的自变量。该变量被称为邻近度分数。
如上所述,图2显示了在将原始浓度调节为邻近度分数之后得到的双平面图。此外,年龄偏移被归一化,使得所有年龄组定位在每种生物标志物的固定点或设定点处。因此,如果未知患者样品的浓度值恰好位于其年龄的非癌症平均值处,那么其邻近度分数将固定在设定值处,并且所有年龄为平均值的所有患者样品将获得相同的邻近度分数的值。
在该实例中,任意地,非癌症平均值的设定值是4,癌症平均值的设定值是16。可以使用其他值,例如更宽的范围。此外,注意到在该实例中,通过将这些浓度折叠到现在新设定的用于伪浓度的固定平均值之间的空间中,原始离群浓度值实现了向已知患者诊断的训练集的最佳拟合。这实现了所需的噪声抑制,并且该转换被设计为保持相关方法所依据的聚类行为,即空间邻近度相关性。
然后基于每个单独的原始浓度值相对于浓度空间中其年龄所处的平均值的位置,将原始浓度值置于4个“等级”中的一个内。一旦转变为邻近度分数后,即从用于相关性的新自变量中除去年龄(细节参见下文)。这不是针对此任务以及最适合实际诊断的训练集而设置的唯一方程。该转换的设计基于要拟合的原始数据的基本特征和空间邻近度方法的潜在特征。通过迭代试验可以找到可行的解决方案。
本申请中描述的这五种生物标志物,il6、il8、vegf、tnfα和psa用于乳腺癌,并产生上述表2中所述的对于各种相关方法的预测能力。尽管这些特定标志物是足够正交的并且提供足够的信息来分离疾病状态,但发明人预期可以使用其他的生物标志物组,并且这些组中的不同数量的生物标志物可以变化。
这些生物标志物利用标准逻辑回归方法产生预测能力,该标准逻辑回归方法的典型特征在于任意组的五种此类标志物。这种预测能力水平也是各种受试者工作特征(roc)曲线方法的典型特征,用于使roc曲线下的总面积最大化(即,约80%)。转换为对数标度也是典型的,因为原始浓度范围通常超过5个数量级。此外,支持向量机和空间邻近度相关方法使用浓度的对数产生更好的预测能力(即,84%至85%)。这可能是由于这些生物标志物的空间分离效应。向邻近度分数的转换(无关信息的减少)还导致预测能力的甚至更显著的改善(即,87%至90%)。然而,最佳预测能力结果归因于这些功能正交的生物标志物、空间邻近度相关性和向邻近度分数转换这全部三种的组合(即96%)。最后,纠正拓扑不稳定性的空间邻近度方法将该预测能力改善到大于96%。
包括本发明方法的实施方案的分析模型通常遵循以下步骤:
1)收集大量已知的非疾病和疾病患者样品。不应该对这些样品的任何其他无关病症(非恶性癌症)进行筛查,但应当收集,以使其在统计学上与总群体相似。
2)测量生物标志物参数浓度。
3)计算非疾病和疾病组的这些生物标志物的平均值(参见以下根据平均值的年龄偏移的其他考虑因素)。
4)以数学方式操作原始浓度,以使它们进入模拟平均值的组中。这可能涉及压缩、扩展、反转、变换,查阅转换表,和其他数学运算。该方法可以包括这些模式中的一些或全部。得到的数值可能根本不像原始浓度值,并且可能无法从结果值返回到浓度,因为转换曲线可能折回其自身上。这种用于相关性的新自变量称为邻近度分数。实际上,由此产生的分布可能在两个平均值附近堆积,并保留平均值锚定点。
5)操作还必须强制未知样品基于样品与上述平均值的关系而经受评级。本文定义了区域,其分别是:1)低于未知样品在其年龄处的非疾病平均值;2)高于其年龄处的非疾病平均值,但低于其年龄处的非疾病平均值与疾病平均值之间的推导中点;3)高于非疾病平均值和疾病平均值之间的推导中点,但低于其年龄处的疾病平均值;和4)高于未知样品在其年龄处的疾病平均值。这些区域可以被压缩到相应平均值附近和/或之上的空间中,以抑制由不相关的干扰病症或药物引起的差异。
6)上述平均值必须考虑每个贡献了生物样品的患者的年龄。每个样品的区域定位必须与相应患者的年龄以及患者年龄处的疾病和非疾病平均值相关。
7)用于浓度向邻近度分数转换的可能方程
用于otraces乳腺癌和前列腺癌测定的比率对数线性方程为:
在参考申请中讨论的浓度向邻近度分数转换的一个方程为:
psh=k*log10((ci/c(h))-(cc/ch))2+偏移
方程2
psc=k*log10((ci/cc)-(ch/cc))2+偏移
其中:
psh=非癌症的邻近度分数
psc=癌症的邻近度分数
k=用来设定任意范围的增益因子
ci=实际患者分析物的测量浓度
ch=经患者年龄调整的非疾病患者分析物的平均浓度
cc=经患者年龄调整的疾病患者分析物的平均浓度
偏移=用来设定数值范围(任意)的纵坐标偏移
图19的实施方案显示了区域1折叠到区域2之上和区域4折叠回区域3之上(参见关于群体分布偏差的部分)。在癌症与非癌症的情况下,癌症队列在训练集中存在大幅度的过度呈现。折叠改善了由非癌症主导的区域的分布偏差。该实施方案如图所示。
8)另一个实施方案使用直接的对数浓度来进行线性转换。
其中:
ps=m(log(ci)+b
ps=邻近度分数浓度
ci=实际患者分析物的测量浓度
m=转换斜率
b=偏移
图20和图21中显示了该实施方案。图20显示了邻近度分数轴上按维持的顺序排列的四个区域的顺序。图21显示了区域1和区域2重叠,如区域3和区域4重叠一样(参见下面的群体分布偏差)。当两个状态“a”和非“a”的群体分布在一定程度上相同时,区域1折叠到区域2之上和区域4折叠回区域3之上的折叠是有用的。
7)该称为邻近度分数的新变量用于选择的相关方法(参见本文中关于此讨论的部分)。8)使用与所开发的相同的模式使训练集模型内的预测能力最大化,确定未知样品“适合”非疾病组还是疾病组。
年龄相关的平均值函数是用于从原始浓度转变的锚定点和空间邻近度网格上的在相关性中使用的新邻近度分数。该函数由大量已知的疾病和非疾病样品确定,并且群体可以包括训练集但也可以包括更大的组。非疾病和疾病群体的定义如下。它是一种将非疾病和疾病的平均值与年龄偏移相关联的函数。它用于将平均值放置在邻近度分数轴上的固定位置,其中原始浓度被转换为邻近度分数。它通常会产生一系列执行转换的方程,其中每个方程用于每个年龄的转换。该函数允许年龄偏移的归一化。
图4显示了在莫斯科gertsen研究所进行的tnfα和激肽释放酶3(psa)市场清除试验中,乳腺癌和非乳腺癌的这些函数。注意到该图可以给出非常好的生物标志物指示,当以本申请中描述的方式与其他生物标志物结合时,所述生物标志物将产生预测能力。从测量科学的角度来看,所有年龄段的分离程度表明存在强烈的“信号”,这种信号将使非信号病症、疾病和非疾病得以区分。在大多数情况下,这将比单一的roc曲线更好地指示预测能力。
功能正交的生物标志物的使用和空间邻近度相关方法
该方法使用空间邻近度搜索(邻域搜索)进行关联。该方法将每个自变量放置到空间轴上,并且所使用的每种生物标志物有其自己的轴。将五种生物标志物放置到5维空间中。通过专利pct/us2014/000041及以上讨论的元变量方法转化每种生物标志物。该方法在浓度作用和免疫系统非线性方面强制年龄相关偏移的归一化。本文讨论的测试板用于乳腺癌,并且它使用炎症标志物,白介素6;肿瘤抗血管生成或细胞凋亡标志物,肿瘤坏死因子α;肿瘤血管化标志物,血管内皮生长因子(vegf);和血管生成标志物,白介素8;以及已知的肿瘤组织标志物,激肽释放酶-3(或psa)。这些标志物在用于相关性的邻近度方法中是高度互补的,因为它们的功能不显著重叠。因此,当正交绘制时,它们增强对于非癌症和癌症的分离,因为每个添加的轴将生物标志物数据点拉开,如图中所示。其他标准相关方法,如回归分析或roc曲线区域最大化方法不能保留这种正交分离,因为数学分析会查找单独的标志物趋势(线性回归-线性和逻辑-对数)。任何空间信息都会丢失。
上面提到的现象,即功能的正交性或不一致性也可以在图5和图6中以图形方式看到。这些图显示了促炎生物标志物的浓度群体分布,il6相对于水平正交轴上的血管生成生物标志物vegf而绘制。图5显示了旋转的3d图,使得水平面几乎是水平的,图6显示了旋转的x、y平面,使得可以在该水平面上看到标志物的平面分布。水平浓度轴显示该参数不是以浓度单位绘制的,而是以本文所讨论的计算邻近度分数绘制的。垂直轴显示了群体分布占总数的百分比。每个垂直条的箱尺寸为0.5单位的邻近度分数。注意到该图形绘制描述不允许两个群体组,即非癌症(蓝色)和癌症(红色)的并排分离。因此,这些条彼此重叠。当蓝色群体高于红色时,蓝色显示在红色之上,反之亦然,但它们不相加,蓝色背后的红色仍然显示垂直轴上的正确红色高度。注意到非癌症在癌症群体上的相当大的重叠,反之亦然,正如对任何一种生物标志物所期望的那样。还注意到与非癌症的蓝色样品相比,癌症的红色样品通常沿每个轴具有更高的邻近度分数水平,正如对单一生物标志物所期望的那样。图6显示了这些相同的3d轴向下旋转45°以显示水平轴。注意到各个标志物的显著分离。促炎标志物il6表现出低反应但是呈红色,癌症倾向于显示高水平的血管化反应,反之亦然。对于因与所选择的其他生物标志物的不相关功能性而选择的任何生物标志物可以预期这种效果,并且这些生物标志物通常对于癌症会上调。这可以通过简单的概率来预期,两种蛋白质在疾病转变中上调,对一种功能具有低反应的那些可能会显示出对另一种功能的更强反应。该效果在具有炎症和血管化功能的正交性的乳腺癌中得到甚至更多的增强。图16显示了随癌症阶段的乳腺癌中每种蛋白质的上调程度。注意到在初期阶段0开始时,促炎标志物首先高度上调。然而,随着肿瘤的进展,血管化标志物随着肿瘤的生长,在阶段1至阶段4更大程度地上调。因此,晚期的低水平促炎反应与高水平的血管化反应相关联。在疾病的早期,高水平的促炎反应与相对低水平的血管化反应相关联。当在多维相关方法中绘制时,这种行为将在癌症中将低水平血管化反应与高水平促炎反应分开,从而使这些样品点远离原点(反之亦然)。在癌症中,相关信息被远离正交轴的函数拉动用于其他函数。注意到这种增强在例如回归或roc曲线区域最大化等方法中丧失,因为失去了正交函数的关联。
图7至图10显示了主要在血管生成中发挥作用的第三种生物标志物il8,其以具有上面讨论的另外两种生物标志物的3d图呈现。注意到血管生成(il8)和血管化(vegf)都参与血管生长但并不相同。血管生成(il8)驱动由具有现有循环的组织产生血管,而血管化(vegf)驱动在大量没有预先存在的循环的组织中产生新血管。已知肿瘤产生上述两种反应。再次参见图16,当肿瘤在血管化组织内并且血管化随着大块肿瘤生长而增加时,血管生成在早期阶段是强烈的。图为:图7显示了从所有轴上方45°向下俯视图原点得到的图。图8显示了旋转的图,其显示水平轴高于水平面10度,并且垂直轴向右旋转约35°。蓝色(非癌症)明显位于红色(癌症)下方,并且更接近原点。图9显示了整个图旋转到背面以通过原点看非癌症(蓝色)和背面的癌症(红色),图10显示了图9稍微向上旋转以显示在非癌症(蓝色)前面的癌症(红色)。注意到如上所述(例如,临时申请第61/851,867号及其后续专利申请)和本申请中,通过不使用实际浓度而使用在相关申请中讨论的邻近度分数使该分离大大增强。这些图清楚地显示了选择具有互补功能(即正交)的生物标志物如何得到分离和预测能力的显著改善。这种改善将通过未显示的其他两种标志物tnfα(抗肿瘤发生)和激肽释放酶3(psa)肿瘤标志物而继续。当然,它们不能与前三种生物标志物一起绘制,因为这将超过3个维度,并且眼睛无法看到这一点。当针对上述三种生物标志物之一绘制时,这两种标志物将看起来基本相同,从而显示在每个轴上的分离高度。计算机化的5维空间邻近度相关方法保留了这种正交性。
总之,初生乳腺癌肿瘤(阶段0)产生非常强烈的促炎反应,如图11所示。这种反应本身不能与感染、过敏或自身免疫性疾病(和其他疾病)区分开。然而,这种相同的初生肿瘤将产生强烈的血管生成反应,组织周围血管化的循环增加。因此,在图7至图10中,初生肿瘤样品将在促炎轴上向外移动,并在血管生成轴(以及第四和第五维度中的抗肿瘤发生轴和肿瘤生物标志物轴)上向上移动。晚期肿瘤阶段3或4往往会显示出强烈的血管化反应(在没有血管化的大块肿瘤组织中生长)和较弱的抗肿瘤发生,从vegf轴的原点向外移动。这些不能与创伤、心肌缺血或怀孕区分开,因为这些病症需要血管化。然而,再次,不相关的功能,即肿瘤抗发生和肿瘤标志物的上调将产生区别。
随着其他三种生物标志物被添加到5维相关网格中,这种改善成倍增加。仔细选择不一致功能性的生物标志物相比选择多种肿瘤标志物的方法提高预测能力。相同肿瘤的肿瘤标志物倾向于测量相同的现象,这不会使生物标志物在这些正交轴上分离,它们只会将聚类的群组旋转45度。回归和其他方法不保留这种正交信息。这种改善只能通过功能正交的生物标志物和空间邻近度相关方法来实现。
对于空间邻近度相关方法,测量的浓度值本身不用于5轴网格中。使用邻近度分数。该计算值消除了从非癌症向癌症转变过程中与年龄相关的偏移,实际浓度平均值、非癌症平均值和癌症平均值中的年龄变化被归一化。此外,小心扩展和压缩实际浓度,以消除所谓的局部空间和群体密度偏差,以确定邻近度分数的值。该数值无单位,并且在0至20的任意范围内变化。这两个修正将使预测能力提高约6%。与使用多种肿瘤标志物作为生物标志物相比,使用不一致的功能性细胞因子组将获得高约10%至15%的预测能力。与传统的邻近搜索方法相比,年龄偏移和非线性上下调节的归一化使预测能力提高6%至7%。
相比之下,图12、图13和图14显示了对于卵巢癌的ca125、he4的群体分布,其再次在水平轴上呈现,以及垂直轴上的群体分布。图13显示了这些轴向下旋转以观察这些生物标志物彼此的正交关系。当在水平的二维双标志物平面上绘制时,该3d图还显示出这两种标志物的空间分布(垂直轴显示了群体分布)。将浓度绘制为1至20的归一化的对数浓度。ca125和he4是众所周知的卵巢癌生物标志物。事实上,对于单一高丰度蛋白质癌症标志物,这些是非常好的。对于男性的前列腺癌,he4远远优于psa。然而,它们还不足以获得监管机构的批准用于筛查。即使两者组合也没有效果。注意到,对于两者而言,单一的生物标志物相对较好。ca125在90%的灵敏度下将达到约50%的特异性。he4在90%的灵敏度下将达到约45%的特异性。注意到当在二维中观察时,正交分离与单一生物标志物本身相比没有太大差别。“he4anoveltumourmarkerforovariancancer:comparisonwithca125andromaalgorithminpatientswithgynaecologicaldiseases;”rafaelmolina,josem.escudero,josem.augé,xavierfilella,laurafoj,aurelitorné,joselejarcegui,jaumepahisa;tumorbiology;2011年12月,32卷,第6期,第1087至1095页。图15显示了另一种通用的卵巢癌生物标志物afp的添加。相对于ca125和he4没有观察到额外的改善。这三种生物标志物正在测量同一事物的相似方面,因此在保持正交性的情况下,这三种生物标志物在改善预测能力方面并不是互补的。综合性能(使用标准方法)与he4本身大致相同。图16显示了当与卵巢癌关联时单独的ca125和he4的roc曲线,然后是两者组合的roc曲线。该组合几乎与he4roc曲线重叠。根本没有性能改善(除了绝经后女性的轻微改善)。“he4andca125asadiagnostictestinovariancancer:prospectivevalidationoftheriskofovarianmalignancyalgorithm;”tvangorp,icadron,edespierre,aleunen,famant,dtimmerman,bdemoor,ivergote;brjcancer,2011年3月1日;104(5)863-870。使用具有这种所谓的正交函数特征的三种、然后四种、然后所有五种生物标志物的roc曲线的显著改善显示在图17和图18中。这些图都使用原始浓度的对数,注意到如果将这些原始浓度转换为邻近度分数,并且当蛋白质组学差异“噪声”被消除时,改善将被视为正交分离移动。剪切概率表明,当抑制该噪声时,具有低响应的一种癌症的肿瘤生物标志物可能会在正交轴上具有较高的响应。
仅通过转换为邻近度分数,在该正交网格上出现进一步分离。图5和图6以3d图显示了图2中的数据,其中垂直轴是每种生物标志物的群体分布。邻近度分数将样品数据分为两组,即接近原点的大部分非乳腺癌和远离原点的乳腺癌。这些分布近似呈泊松分布。注意到正常的单一生物标志物在每个水平轴上重叠。即使再多的数学操作也不能摆脱该问题。然而,注意到在促炎轴(il6)上的低位置的各个红色(乳腺癌)样品倾向于在血管化(vegf)轴上具有高位置。对于(vegf)的其他水平轴也是如此。注意到这种分离将在使用功能正交的生物标志物的情况下出现,或者与不具有固有的正交分离作用的肿瘤标志物一起出现。简单的概率将表明肿瘤标志物之一的低水平浓度很可能对应于癌症患者中所有其他肿瘤标志物的高水平。例如,如果测试板包括5种肿瘤标志物(非正交作用),则标志物测量相同的状况(例如,存在肿瘤)。所有标志物在大多数情况下上调。如果一种标志物具有不良响应,例如不存在上调时通常发现的水平,则在个体中,其他标志物可能也必须是活跃上调的。当蛋白质组学差异(或噪声)被抑制时,这种分离作用会显现。在原始浓度值内,这种分离效果被噪声干扰。还注意到,这种分离通过网格中的所有正交维度(在该实例中为5个正交维度)而保持堆积,无论是被选择用于功能正交性的生物标志物还是仅作为指示相同肿瘤的存在的肿瘤标志物,具有功能的正交性到目前为止产生最好的分离。注意到这些维度中的每一个与所选择的每种生物标志物相关联。因此,五种生物标志物将需要5个维度,而6种生物标志物需要6个维度等。
空间邻近度方法
该方法包括多维空间,每个生物标志物一个空间。训练集中每种生物标志物的邻近度分数被绘制在多维空间(该乳腺癌实例中为5个维度)中。该图被分解为网格,然后该五维网格中的每个点通过其与网格上的若干(5%至15%)训练集点的最邻近程度来评分为乳腺癌或非乳腺癌。在被评分的空网格点的局部附近,通过乳腺癌和非乳腺癌的计数得到癌症分数。当空网格点仅“看到”乳腺癌时,其获得最大分数,对于非乳腺癌反之亦然。然后将未知样品放置在该网格上并相应地评分。表2显示,生物标志物的这种功能正交选择与邻近度分数转换(降噪和年龄归一化)的结合,在该乳腺癌病例中对于这些生物标志物产生了96%的预测能力。
也可以通过每种生物标志物二维平面上的5维网格对各个双标志物位片进行同样的操作,以减少计算时间。这产生了10个所谓的双标志物平面。通过与疾病或非疾病训练集的邻近度,通过与训练集点的二维邻近度再次对二维网格点进行评分。在这种情况下,3%至10%的最近数据点被用于邻近度距离。这产生了针对每个网格点的分数。其中含有训练集数据点的网格点忽略对用于网格点评分的训练集点的实际诊断。然后通过通常的定义计算训练集点的正确与不正确来对平面的预测能力、灵敏度和特异性进行评分。然后将10个所得平面与单独的平面预测能力加权相加。每个双标志物平面的这种加权是该平面的预测能力(也可以使用灵敏度)。然后移动并获得所有十个平面的附加分数以得到0至200的范围,其中0至100标记为非癌症,101至200标记为癌症。然后,通过使用训练集由构建的模型进行预定评分而将它们放置在这些双标志物平面上,从而对未知样品数据点进行评分。
五种生物标志物乳腺癌诊断测试板的roc曲线
图17显示了完整的5个测试板的组合roc曲线,该曲线来自gertsen研究所对于癌症和非癌症组总共407个血清样品测量的浓度值。该总体图显示了五条roc曲线:1)黑色是单独的vegf;2)棕色曲线用于il6和vegf的组合;3)蓝色曲线仅用于psa、il6和vegf;4)绿色曲线仅用于psa、il6、vegf和il8;5)红色曲线用于所有五种生物标志物。当观察对应于100(任意0至200的癌症分数范围之间的中点)的癌症分数设定点时,预测能力的积累是明确的。图18显示了该范围的放大的roc曲线以更好地看到每种添加的生物标志物所实现的改善。x标记位于中点癌症分数100的数据点上。这将是从非癌症到癌症的推定转变点。但是医疗目标可能改变该值。肿瘤学家已将转变点设定在约80,以使假阴性预测最小化,代价是获得假阳性结果。这些数据显示了所有数据设定点,包括训练集和盲样,以及来自用于检测乳腺癌的otracesbcseradx检测试剂盒的第三方验证的数据,总共407个数据集。注意到训练集内的预测能力和盲数据集的最终预测能力评分具有大致相同的预测能力,为约97%至98%。在这种情况下报告的癌症分数是从0至200的任意评分,其中0至100是非癌症,100至200是癌症。注意到红色曲线(全部5种)不会在通常的轴终点0,0和1,1处终止。这是因为大量的数据设定点的癌症分数恰好为0和200。30%的非癌症样品分数为0,约50%的癌症点分数为200。在5维网格中的这些点仅分别看到网格中训练集点的0分的非癌症和200分的癌症。邻近度测试使用三个最接近的点在通过5维空间的每个2维正交切面上进行分数计算。这些切面被称为双标志物平面。5维空间产生10个离散的双标志物平面。在全部五个维度中,测试每个盲样与约20至25个不同训练集数据点的邻近度。这些分数为0或200的样品分别仅在网格中看到非癌症或癌症训练集点。因此,它们的分数分别为0和200,即任意范围的端点。同样如此,但对于3种和4种生物标志物曲线的程度较小。这证明了该方法的稳健性。
尽管这些生物标志物具有不足以用作筛查测试的预测能力,但是它们组合可以实现超过95%的预测能力。然而,这种表现不能从单独的roc曲线和一种生物标志物行为的测量中确定。vegf具有最差表现的roc曲线,但是当与促炎生物标志物组合时显示出预测能力非常高的提升。这是由于这些生物标志物的正交功能的放大效应。此外,具有这些特征的生物标志物继续放大预测能力。只有在空间邻近度相关方法中保留多个函数中包含的正交信息时才能看到该放大。
评估一种生物标志物自身的性能价值有限。它们需要以保持功能性关联(或解耦)的多维形式评估。或者,可以在正交矩阵中研究生物标志物。这些roc曲线中显示的预测能力的放大直接来自:1)通过转换为邻近度分数来抑制蛋白质组学差异;2)使用具有功能正交性的生物标志物与空间邻近度相关方法相结合;和3)从非疾病向疾病转变所固有的年龄偏移的归一化。
年龄归一化
在图3中的约400名患者中测量了vegf在女性中的测量浓度分布。vegf是一种抗肿瘤低丰度细胞因子,其一般在血清中随癌症的存在而上调,但也在其他病症中上调,如表1所示。垂直的红色和蓝色垂直条显示每个浓度水平的群体计数(百分比),显示在水平轴上,单位为pg/ml(红色是癌症,蓝色是非癌症)。
顶部的红色和蓝色水平条显示非癌症(蓝色)和具有乳腺癌的女性(红色)的群体平均值的变化,其随患者年龄的变化而变化。注意到这些平均值实际上是重叠的。65岁非癌症女性的平均群体值实际上高于35岁女性的癌症平均值。这种年龄偏移也见于图1,即图的右侧和底部的红色和蓝色箭头。该问题(用于相关性分析)可能出现在大多数(如果不是全部)可能在这些分析中有用的可能的信号传导蛋白中。参见上文,了解该问题如何矫正。
年龄引起上述讨论的复杂化,因为非癌症和癌症的群体平均值随年龄而变化。此外,在相关分析中使用年龄作为单独的自变量不会改善预测能力。因此,尽管上述方法改善了预测能力,但应考虑年龄偏移的因素。相关的临时申请61/851,867(及其后续专利申请)描述了如何将年龄作为元变量用于将浓度变量转换为年龄因素的邻近度分数值。下面的讨论描述了改善这种转换的方法。
如前所概述的,改善疾病预测的方法可以使用用于相关分析的自变量,该自变量不是直接测量的分析物浓度,而是根据浓度计算的计算值(邻近度分数),而且还对于特定年龄(或其他生理参数)进行归一化以消除这些参数的负面特征,例如年龄偏移和当疾病状态从健康转变为疾病时浓度值随生理参数(年龄)偏移或改变的非线性。该讨论提供了对该方法的改善。
在参考申请中讨论的将浓度转换为邻近度分数的一个方程是(参见上文浓度向邻近度分数转换的可能的方程):
方程1
psh=k*log10((ci/c(h))-(cc/ch))2+偏移
方程2
psc=k*log10((ci/cc)-(ch/cc))2+偏移
其中:
psh=非癌症的邻近度分数
psh=癌症的邻近度分数
k=用来设定任意范围的增益因子
ci=实际患者分析物的测量浓度
ch=经患者年龄调整的非疾病患者分析物的平均浓度
cc=经患者年龄调整的疾病患者分析物的平均浓度
偏移=用来设定数值范围(任意)的纵坐标偏移
这在下文中称为方程1和方程2。
这些方程选择性地压缩或扩展测量的浓度值,以允许更好地拟合邻近度相关方法。经年龄调整的平均浓度值用于非疾病状态和疾病状态。下面的年龄调整方法显示,这种改善的方法使用该方程和图中的部分或区域中的其他方程,其显示在相关分析中实际使用的测量浓度和得到的邻近度分数。
图19显示了绘制的方程1和方程2,其显示从浓度向邻近度分数的转换。注意到方程2被颠倒并在数学上反转,且其偏移值移位使得非癌症方程(一)与癌症方程(二)不在纵坐标上的重叠。年龄相关的平均值显示在横坐标上,如水平渐近曲线中非癌症靠左,癌症靠右。这些渐近曲线在横坐标上再次随年龄而变化。事实上,对于一些标志物,非癌症和癌症的经年龄调整的平均值在垂直轴上重叠,如图所示。如果不处理,这种生物学方面特别会使预测能力劣化。该实施方案显示了区域1折叠到区域2之上和区域4折叠回区域3之上(参见关于群体分布偏差的讨论)。在癌症与非癌症的情况下,癌症队列在训练集中存在大幅度的过度呈现。折叠改善了由非癌症主导的区域中的分布偏差。
图21显示了使用直接对数浓度进行线性转换的替代实施方案。在这种情况下,ps=m(log(ci)+b,其中ps=邻近度分数(浓度),ci=实际患者分析物的测量浓度,m=转换斜率,b=偏移。同样地,该实施方案显示了区域1折叠到区域2上,区域4折叠回区域3上。
通过调整偏移值,方程和得到的邻近度分数值被强制进入二维图上的区域。此外,实际测量值低于非癌症年龄平均值的特定年龄的所有个体样品将被强制进入区域1。同样地,实际测量值高于癌症平均值的特定年龄的所有样品将被强制进入区域4。类似地,实际值在该特定年龄的非癌症平均值与该特定年龄的非癌症和癌症平均值的中点之间的样品被强制进入区域2,同样适用于区域3。实际上,邻近度分数强制某个年龄的个体样品根据其与该年龄的非癌症和癌症的平均值的关系而选取四个位置中的一个。邻近度分数迫使浓度测量偏向一侧。注意到这不表示区域1中的样品不是癌症。其取决于其他四种标志物的表现。三个关键点,即非癌症平均值、癌症平均值以及它们之间的推导中点都在横坐标上独立地变化,并且可以重叠但是在组区域或纵坐标上的值(邻近度分数)中被归一化。
图22描述了用于构建蛋白质组学噪声抑制相关方法的示例性流程图。该流程图描述了开发高性能相关算法所涉及的步骤,该算法用于分离诊断疾病状态、与严重程度相关的疾病状态内的病症所需的两种相反状况(状态“a”和非状态“a”),以确定适合用特定药物治疗疾病的最佳群体。状态“a”和非状态“a”可以是疾病的存在和疾病的不存在。或者,它可以是疾病的严重状态和疾病的不太严重的状态。此外,它可以用于在一组预期患者中对特定药物或治疗方式进行疗效评分。对于癌症,具有正交功能性的优选细胞因子将是:促炎细胞因子、抗炎细胞因子、抗肿瘤发生细胞因子、血管生成细胞因子和血管化细胞因子。此外,至少一种肿瘤标志物将是合适的。年龄可以是不同的自变量。将该变量称为元变量。注意,在参考专利pct/us2014/000041中要求保护年龄、体重指数、种族和地理区域以及其他自变量。
示例性方法显示为2100,即“任务流程”。在步骤2101中,定义状态“a”示例性地为疾病状态,非状态“a”示例性地为非疾病状态。在步骤2102中,选择包含集的生物标志物,优选具有正交功能性的那些生物标志物。在步骤2103中,获得已知状态“a”和非状态“a”的大样品集。在步骤2104中,对于状态“a”和非状态“a”,测量每种生物标志物的平均值。在步骤2105中,对于状态“a”和非状态“a”,计算与年龄相关的偏移。在步骤2106中,计算状态“a”和非状态“a”的平均值之间的经年龄调整的中点。在步骤2107中,软件计算非状态“a”和状态“a”的平均值向邻近度分数转换的固定数值以及推导中点。在步骤2108中,将该集中每种生物标志物的浓度测量值转换为邻近度分数。在步骤2109中,使用该集中每种生物标志物的生物标志物邻近度分数来计算浓度邻近度分数,并选择状态“a”和非状态“a”的浓度方程。在步骤2110中,将邻近度分数绘制到正交网格上,使得该集中的每种生物标志物具有一个维度。在步骤2111中,基于例如邻近度分数转换方程集对生物标志物集进行评分。该生物标志物集的分数导致产生本文讨论的高度预测性诊断方法。
空间邻近度相关方法的消极方面
空间邻近度相关方法与其他方法相比具有非常显著的优点,因为当从健康至癌症的转变出现时,它保留了这些生物标志物中固有的正交空间分离。然而,该方法可能存在一些传统分析方法没有的缺点,这些缺点是可以克服的。该方法在多维网格上绘制训练集数据,然后通过与训练集点的邻近度对网格上的其他“盲”(未占用)点进行非癌症或癌症的评分。如果这些生物标志物数据点的移动是相对线性的,则通常会出现最佳相关性能。即,如果移动或上调/下调是高度非线性的或表现出高度孤立点的聚集,则可能出现相关性的降低。基本上,网格上高度孤立的点将影响所有附近的点,其中孤立点的评分以其他点为代价。第二个问题涉及训练集数据的相对总群体分布和总群体中疾病的实际分布。在乳腺癌的情况下,总群体分布为约0.5%的癌症至99.5%的非癌症。然而,训练集必须分配为50%/50%,否则相关性将出现偏差,利于较多群体的一侧。没有偏差要求50%/50%的分离。这可以导致以非癌症为主而癌症水平低的区域在这些区域被称为癌症,反之亦然。
空间邻近度相关方法与人类生物测量的特殊偏差问题
图3显示了对于癌症预测测试所讨论的生物标志物中的一种的群体分布。具有聚集和高度孤立的数据点的这种非线性分布对于所有五种这些生物标志物以及大多数(如果不是全部的话)这些低水平信号传导蛋白(细胞因子)而言是典型的。这指示免疫系统的非线性行为。该问题(以及上述的年龄偏移效应)显著地削弱了将这些蛋白质与疾病状态预测相关联的能力。该实例旨在教导如何纠正这种非线性上调行为。
在图3中,浓度分布是高度非线性的,其中浓度值块处于极低的水平以及非常高的水平。这指示免疫系统的非线性行为。这种行为对于所有这些细胞因子或基于信号传导的生物标志物是共同的。事实上,本文讨论的这种乳腺癌检测方法中使用的生物标志物看起来都非常类似于图3中的图。还注意到分布显示了聚集之间的孤立点。这将导致相关偏差,称为“局部空间分布偏差”。如上所述,使用方程1和方程2可以部分地缓解这两个缺陷。
局部空间分布偏差
如上所述,通过使用方程1和方程2可以部分地缓解该问题,但是可能存在许多其他可能的解决方案。图23显示了程式化的二维生物标志物图,其显示高水平和分散的癌症。此外,显示了较低水平和压缩的非癌症。还显示了这些聚集之间的孤立点。该图上绘制点间距的标准差为约8个单位。注意到图表上的两个孤立点将横扫邻近度图的大部分区域,从而使这些区域具有孤立点的诊断。
图24显示了由方程1和方程2执行的压缩和扩展所调整的这些相同点。该图上各点之间的标准差为约2.5,并且聚集和孤立大大降低。根据上面在测量科学的讨论中提到的规则,这种数学操作是完全可以接受的。实际上,距离标准差减小对于模型的预测能力是良好的经验法则。注意到间距的标准差仅减少至3个单位。在不改变间距顺序的情况下,该间距偏差应尽可能低。
群体分布局部偏差
图25、图26和图27显示了如何缓解该问题。图25显示了对于低于非癌症的年龄相关平均值的样品,非癌症空间中癌症的过度显现。右上方的区域通常是癌症样品。左下方的样品以非癌症为主,因此更正确。图26显示了如果通过真实的癌症较小分布来恰当地表示,该图将看起来如何。这些都有偏差的风险,并且可以通过将右下区域折叠到非癌症的年龄相关平均值附近的区域而在一定程度上缓解。这些非常低的浓度值(远低于1pg/ml)被归为较高浓度区域中,从而有助于缓解偏差。图27中示出了显示折叠和减少的局部群体分布偏差的程式化图。
数学规则是:
训练集模型应归为50%非癌症和50%癌症以除去模型偏差。
如果将该方法应用于训练集模型和待测试的盲样,则数学操作对于降低独立测量的物理特性的影响以减少无关信息噪声的影响是可接受的。
使用这些生物标志物对乳腺癌进行简单的逻辑回归将产生略低于80%的预测能力。使用简单的标准空间邻近度相关而不进行年龄和非线性校正(浓度的简单对数)产生约89%的预测能力。上面讨论的这些改进:1)年龄归一化;2)局部空间分布偏差校正;3)群体分布局部偏差校正,通过这些生物标志物产生约96%的预测能力。为拓扑不稳定性添加盲样的校正(参见临时申请第61/851,867号(及其后续专利申请))可以再增加1%至2%的改善。
空间偏差和群体分布偏差校正是差异(噪声)抑制方法的补充
上面讨论的用于校正与空间邻近度相关方法关联的两个偏差问题的方法与解决蛋白质组学差异(噪声)的问题是互补的。校正方法都涉及压缩原始浓度数据,并且该压缩朝向疾病和非疾病的预定平均值。事实上,校正群体偏差问题涉及将非常低的浓度值(远低于非疾病平均值)折叠到非疾病平均值附近或甚至高于非疾病平均值的区域中。非常高的浓度值也是如此。
对于vegf,该方法得到的邻近度分数分布如图28所示。其他四种看起来相似。该过程强制样品数据点进入两个大致重叠的泊松分布,其中非癌症在下侧占优势,癌症在上侧占优势。注意到癌症和非癌症样品仍然重叠。一种生物标志物不能高度准确地将健康与疾病完全分开。在该实例中使用的方程分别在高于和低于癌症和非癌症的经年龄调整的浓度平均值的区域中引起浓度值在转变为邻近度分数时顺序反转。本文讨论了两种情况。第一种情况是区域1和区域2高于非疾病平均值并低于中点;且区域3和区域4高于中点但低于疾病平均值。第二种情况是区域在邻近度分数轴上顺序分段,其中非疾病平均值置于区域1和区域2之间;疾病平均值置于区域3和区域4之间,并且推导中点置于区域2和区域3之间。第一种情况已被用于非疾病和疾病的群体分布不一致的情况(例如,乳腺癌-非乳腺癌分别为0.5%和99.5%,这反映了局部群体偏差)。第二种情况已被用于群体分布更接近训练集分布的情况(例如,侵袭性/非侵袭性前列腺癌)。
注意到现在非癌症、中点和癌症平均值的平均值年龄转换是纵坐标轴上的单一垂直线。还注意到非常低和非常高的值是对数压缩的,并且年龄相关平均值附近的值存在一定程度扩展。关于反转,重要的是要注意在邻近度相关方法中保持线性顺序并不重要,只需保持邻近度关系。换句话说,顺序可以颠倒。压缩和扩展将数据的大分布或整体分布归一化,但保持空间关系的邻近程度。这被称为除去空间偏差。该方法除去了由于年龄或其他生理变量如体重指数引起的数据的负空间偏差和模糊。实质上,训练集样品数据点被强制在4个区域之一中占据位置:1)低于非癌症的年龄相关平均值;2)非癌症的年龄相关平均值与转变为癌症的中点之间;3)高于中点转变且低于癌症的年龄相关平均值;4)高于癌症的年龄相关平均值,不管年龄或空间分布非线性。
注意到只要处理空间偏差,就可以在该方法中使用几种其他方程。简单对数压缩用于从低浓度至非癌症的年龄相关平均值,以及高于癌症的年龄相关平均值的高浓度,以及这些平均值之间可能的s形方程。先验确定该转变的方程关系是不可能的,并且必须通过实验和经由总体多标志物roc曲线对结果进行比较来确定最佳拟合。最佳方程取决于空间偏差的特征。
分析步骤的概述
1)选择与感兴趣的疾病具有功能关系的生物标志物。生物标志物可能具有非常差的疾病预测能力(差的roc曲线)的事实不能排除它作为考虑,因为在从非疾病到疾病的转变中具有很大独立作用的两个差生物标志物可以产生非常大的预测能力的放大。这些生物标志物应该在其作用上具有功能的区别。
2)仔细定义训练集的疾病和非疾病队列。这些集应该模拟将要进行测试的群体。不应消除与疾病无关的无关非病症。对于癌症和非癌症队列,群体内的非恶性病症应该在统计学上是正确的。
3)用足够的年龄采样测量每个队列的浓度平均值,以准确地确定年龄如何影响平均值。
4)将原始浓度值转换为邻近度分数。在双轴图上,该转换将包括强制所有原始浓度值等于或非常接近各自的平均值到邻近度分数轴上的固定但不同(分离)的数值,而不管样品年龄如何。此外,不管样品年龄如何,在非疾病和疾病平均值之间的浓度计算中点或非常接近计算中点的原始浓度值必须在数学上强制为邻近度分数轴上的固定值。中点邻近度分数点应位于邻近度分数轴上的低非疾病(通常)和高疾病固定点之间。该位置排列通常是期望的,但可能并非总是如此(例如,在低年龄时上调但在较高年龄时下调的生物标志物可能需要不同的蛋白质组学差异抑制策略)。
5)在数学上压缩或扩展(或其他)原始浓度数据,使其关于其年龄的平均值的关系而落在适当的位置(使数据按等级排列)。在应用空间邻近度相关方法时,调整或用数学方案进行实验,以用训练集最大化预测能力。不存在先验规则,并且符合诊断目标的数学方案将根据从非疾病向疾病转变所涉及的原始测量的特征、非线性和复杂性而改变。thecomplexityparadox(kennethl.mossman,oxforduniversitypress,2014)适当地总结了蛋白质组学研究者所面临的挑战:“复杂生物系统中固有的非线性动力学导致不规则和不可预测的行为”。
6)使用完全相同的数学方案来计算测试群体的疾病分数,该测试群体等同于测试的目标群体。确定该验证样品集是否符合诊断标准。
使用肿瘤标志物的现有方法的讨论
研究基于血清的测试以使用肿瘤标志物检测癌症的典型实例包括发表在internationaljournalofmolecularsciences中、题为“abead-basedmultiplexedimmunoassaytoevaluatebreastcancerbiomarkersforearlydetectioninpre-diagnosticserum”的工作。“sensitivityofca15-3,ceaandserumher2intheearlydetectionofrecurrenceofbreastcancer.”pedersenac1,
表3
表3是在癌症诊断蛋白质组学中使用的肿瘤和生物标志物的列表
参考的出版物涉及从大数据集进行数据挖掘的方法。主成分分析(pca)和随机森林(rf)是用于数据挖掘的方法,特别是从大数据集中进行数据挖掘的方法,以学习从数据到结果之间的联系。这对于表中显示的情况是有用的,在表中,许多成分与其他成分以及所测量结果的联系未知。这些方法将阐明有效的联系(如果有的话)。这些方法对于本文描述的相关性是无用的。已知成分(自变量)与结果之间的联系或缺乏联系。这些讨论涉及一种大大改善这些变量与其特征和结果之间相关性的方法。
用于该癌症验证研究的装置和试剂
otracescdx仪器系统
下面包括的测试数据和上面讨论的大部分工作是以下面提到的装置和试剂测量的。数据在otraceslims系统上处理,或者在一些情况下,计算在基于pc的软件上完成。所有的计算软件由otraces,inc编写和验证。
cdx仪器系统基于hamiltonmicrolabstarlet系统。它用编程定制,以将otraces免疫分析方法转移到hamilton高速elisa机器人。hamilton公司是一家备受尊敬的公司,其在全球范围内销售自动液体处理系统,包括microlabstarlet。该单元由hamilton为otraces定制,以提供全自动化。otracescdx系统包括完整的微孔板清洗系统和读取器。这两个额外的装置允许系统在一轮中完成测试板中所有五个免疫测定的一次完整运行,而在初始设置后无需操作员干预。配置的系统每天将完成40个癌症评分。增强功能包括一次执行一个目标分析物的软件。当在完整测试运行中出现错误时,需要能够重新运行特定测试。
bcseradx测试试剂盒
该测试试剂盒包括执行120个癌症测试分数的所有试剂和一次性装置,包括所有缓冲液、封闭溶液、洗涤溶液、抗体和校准物。全面商业化该测试试剂盒所需的增强功能包括添加两个对照样品。这些对照提供独立验证,“盲”测试样品产生适当的癌症分数。两个对照被设计为分别产生50和150的邻近度分数。lims系统(见下文)qc程序将验证这些对照是否正确,从而验证现场的单个测试运行。测试试剂盒安置在gmp工厂中并已获得ce标记。微量滴定板在工厂预先用捕获抗体和蛋白质封闭溶液进行预涂覆。
实验室信息管理系统(lims)
今天由例如罗氏和雅培销售的所有临床化学系统都包含图形界面,其具有足以管理患者数据的软件、质量控制仪器和化学操作,并且有利于测试样品的识别和测试系统的介绍。这些菜单集成在交付的化学系统中。otraces的商业模式是将这些功能包含在位于otraces美国工厂的otraces计算机服务器上,并使用云计算通过互联网将cdx仪器整合到这些服务器上。这产生了几个显著的优点:1)lims软件并入了符合fda的归档软件,使得来自现场部署的每个cdx系统的所有测试运行的数据都在otraces服务器上运行。应用来自安装基础的反馈以及来自关键机构关于患者结果的输入,使otraces可以收集符合fda的数据,以供基于美国fda市场清除提交。2)优选地,条形码试剂包装允许仪器和lims连接来自工厂qc测试的所有qc测试结果。这些数据可以在现场运行测试时实时获得,以进一步验证现场测试结果。3)cdx系统只运行经otraces验证的试剂,因此无法使用非otraces试剂进行试运行。该系统以典型用户界面呈现给操作员,其所有功能实时运行,一旦试运行完成,便可获得患者报告。
乳腺癌预测概述
该报告记录了用于预测来自i期和ii期gertsen研究的乳腺癌阳性样品的乳腺癌阶段的相关性计算方法的性能。两项研究具有186个被诊断患有乳腺癌的样品。其中29个为阶段3(或4),86个为阶段2,71个为阶段1或阶段0。只有4个样品被诊断为阶段0,这些样品不足以开发适当的相关算法,因此将这些样品与阶段1分为一组。此外,只有一个样品被诊断为阶段4,并将其与阶段3诊断分为一组。当获得足够的样品时,分段算法将能够分离这些阶段。在gertsen研究所通过活组织检查诊断为具有乳腺癌的186个样品中,分段相关算法错误地将一个样品称为阶段1,而gertsen研究所将该样品诊断为阶段2(99.5%预测能力)。
gertseni期验证研究
gertseni期验证研究于2010年11月在gertsen研究所进行,旨在评估otracesbcseradx测试试剂盒和otraceslhs仪器系统的性能,以评估乳腺癌存在的风险。lhs化学系统是半自动液体处理系统,用于处理bcseradx乳腺癌测试试剂盒。该测试试剂盒测量五种非常低水平的细胞因子和组织标志物的浓度,并计算用于评估风险的分数。测量的蛋白质是il-6、il-8、vegf、tnfα和psa。实验包括测量100个患者样品,其中分为50%通过活组织检查诊断具有乳腺癌,50%被推定为健康(实际上只有97个被研究所收集)。该项目的癌症评分结果是不明确的,因为100个样品不足以完成完整的训练集模型。研究所还向otraces表示,他们认为仪器不够自动化,其吞吐量也不足以完成预期的任务,以筛查女性患癌症。lhs系统被设计用于早期研究,而otraces管理层未考虑其足以用于生产和市场发布。
gertsenii期验证研究
gertsenii期项目于2012年11月在gertsen研究所进行,旨在评估otracesbcseradx测试试剂盒和otracescdx仪器系统的性能,以评估乳腺癌存在的风险。cdx仪器系统是旨在用于市场发布的升级化学系统。它基于高速elisa机器人,由microlabstarlet开发并由hamilton公司销售。该测试试剂盒测量五种非常低水平的细胞因子和组织标志物的浓度,并计算用于评估风险的分数。测量的蛋白质是il-6、il-8、vegf、tnfα和psa。该实验包括测量300个患者样品,其分为大约50%的患者通过活组织检查诊断具有乳腺癌,50%被推定为健康。对于ii期项目,活组织检查结果向otraces公开了200个样品,其精确地分为50%健康和50%癌症,并分为特定年龄组。这些结果用于训练集以开发预测疾病状态的模型。然后通过该模型处理剩余的112个盲样,以得到癌症分数,然后将这些分数公开给gertsen研究所。然后由gertsen研究所分析这些盲样分数,以评估otraces预测的准确性。
联合i期/ii期的癌症预测研究结果
ii期训练集模型现已处理了来自gertseni期研究(作为盲样运行)和gertsenii期研究(盲样)的209个盲样,其假阴性和阳性率为2%,或预测能力为98%。
由gersteni期和ii期验证研究中恢复的bcseradx测试数据预测乳腺癌分期
otraces开发了一种预测乳腺癌阶段的相关模型。该算法与用于预测健康或乳腺癌状态的模型不同。训练集模型的数学设计用于将训练集数据分成两种状态,通常是“状态a”和“非状态a”(例如,乳腺癌和非乳腺癌)。因此,该模型不直接预测乳腺癌患者的癌症阶段。来自癌症评分模型的乳腺癌与健康分数不能准确估计癌症阶段,并且它不会获得对分期的高预测能力。癌症/健康模型中评分的增加程度不是基于癌症的严重程度,而是基于训练集数据点与5维网格中的盲样位置的接近程度。因此,如果阶段0的癌症位于5维网格中的一点,那么阶段0的癌症可以评分为200(0至100评分为健康,100至200评分为乳腺癌),该点被癌症的其他训练集数据包围,并且没有健康的点。实际上,该模型中的四个阶段0的病例在健康与癌症评分模型上评分高于190。这表明阶段0的病例与健康严格区分,并且在健康/癌症模型中其被主要是癌症的病例包围。
为了使用相关方法预测来自bcseradx测试试剂盒的癌症样品的癌症阶段,otraces构建了三种模型。这些模型遵循“状态a”和“非状态a”的相关模型的二元指令。因此,这三个模型可预测的阶段的组包括:1)阶段1与阶段2和3;2)阶段2与阶段1和3;3)阶段3与阶段1和2。这三个模型创建了分数矩阵,给出了每个样品落入三种情况的任一侧的概率。然后可以对该矩阵进行去卷积以确定预测的乳腺癌阶段。
癌症分期方法的其他应用
这种将疾病分解为子状态的技术当然是可能的,其中信号(疾病)和偏移(非疾病)被重新定义为疾病诊断状态内的状况。最明显的实例是将前列腺癌分为其两种医学相关的状态,即侵袭性(gleason分数为8,最高为10)和非侵袭性(gleason分数为7和更低)。目前,gleason分数以活组织检查确定。在医学上,gleason分数低的男性可能不应该接受治疗,但医学问题是这些男性可能转变为侵袭性前列腺癌,而目前对其进行检测的唯一可靠方法是进行另一次活组织检查。这对患者来说既不舒适并且在医学上也是困难的。使用这种方法可以通过提供简单且易于施用的血液测试来解决这种未满足的医疗需求。
本文描述的方法也可以同样有效地适用于其他五种实体癌肿瘤,如下表4所示。如表4所证明的,本发明的方法可用于诊断任何实体瘤。
表4
癌症之外的应用
所描述的方法可以用于任何诊断应用中,在这些应用中,需要两种或多于两种生物标志物来诊断单一病症,其中诊断描述是患者样品是否具有疾病。下面的表5列出了使用本文描述的方法评估的若干病症。
表5
这些方法还可以用于将药物分成药物有效组或药物无效组。这可以用于拯救由于统计不良而在临床试验中失败的药物,或用于预先试验以提高试验的成功率。
尽管上面已经详细描述了某些示例性实施方案,并且在附图中显示了这些实施方案,但是应理解,这些实施方案仅仅是对本发明的说明而非限制。特别地,应认识到,本发明的教导适用于多种生物状态和疾病,以及疾病的各个阶段。本领域技术人员将认识到,在不脱离本发明广泛的发明范围的情况下,可以对上述本发明的所示实施方案和其他实施方案进行各种修改。因此,应理解,本发明不限于所公开的特定实施方案或布局,而是旨在覆盖由所附权利要求限定的本发明的范围和精神内的任何改变、改编或修改。
- 还没有人留言评论。精彩留言会获得点赞!