基于声音识别的健康管理方法、装置、计算机设备和存储介质与流程
本发明涉及到健康管理技术领域,特别是涉及到一种基于声音识别的健康管理方法、装置、计算机设备和存储介质。
背景技术:
现在人们对于自身健康安全越来越关注,大部分都希望对自身健康有实时的监控,此外保险行业对于投保人的健康问题难以监测,每年都会存在大量投保人隐瞒自身健康问题而进行骗保的现象,因此健康管理系统应运而生。
但是目前健康管理系统大多采用传感器作为可穿戴设备穿戴于用户身上,进而采集心跳、血压等数据来分析,这样不但成本昂贵、会给用户带来不适感,推广面窄,且传感器仅是采集到穿戴者的信息,难以判断采集对象身份是否属实,可能采集到虚假数据,如应用在保险行业,容易造成被骗保的后果,另外,传感器应用在动物养殖健康管理中,成本花费极大,会影响养殖场的经济效益。
技术实现要素:
本发明的主要目的为提供一种成本低、推广面宽的基于声音识别的健康管理方法、装置、计算机设备和存储介质。
本发明提出一种基于声音识别的健康管理方法,包括:
获取声音信息;
提取所述声音信息的目标声音特征;
将所述目标声音特征输入到预设的健康数据库中进行匹配,其中,所述健康数据库包括多个声音特征以及各声音特征分别对应的健康状态数据;
所述健康数据库中的声音特征对应的健康状态数据为所述声音特征经健康状态模型预测得到的预测结果;所述健康状态模型为多个已知健康状态数据的声音特征训练得到的模型;
获取匹配结果,并根据所述匹配结果输出所述声音信息对应的目标发声生物的健康状态。
进一步地,所述获取所述声音信息的步骤之后,包括:
提取所述声音信息的声纹特征;
将所述声纹特征输入声纹识别模型中获取所述声音信息对应的目标发声生物的身份;
将所述目标发声生物的身份以及所述目标发声生物的健康状态结合,并输出结合结果。
进一步地,所述预设的健康数据库包括多个,各健康数据库与生物种类一一对应,所述将所述目标声音特征输入到预设的健康数据库中进行匹配的步骤之前,包括:
根据所述声纹特征判断所述声音信息对应的目标发声生物的生物种类;
调用与所述声音信息对应的生物种类对应的健康数据库。
进一步地,所述健康状态数据包括疾病数据、亚健康数据、完全健康数据;所述将所述目标声音特征输入到预设的健康数据库中进行匹配的步骤,包括:
判断所述目标声音特征与所述健康数据库的疾病数据是否匹配;
若所述目标声音特征与所述疾病数据匹配,则确定所述声音信息对应的所述目标发声生物为疾病状态;若所述目标声音特征与所述疾病数据不匹配,则判断所述目标声音特征与所述健康数据库的亚健康数据是否匹配;
若所述目标声音特征与所述亚健康数据匹配,则确定所述声音信息对应的所述目标发声生物为亚健康状态;若所述目标声音特征与所述健康数据库的亚健康数据不匹配,则判断所述目标声音特征与所述健康数据库的完全健康数据是否匹配;
若所述目标声音特征与所述完全健康数据匹配,则确定所述声音信息对应的所述目标发声生物为健康状态。
进一步地,所述判断所述目标声音特征与所述健康数据库的完全健康数据是否匹配的步骤之后,包括:
若所述目标声音特征与所述完全健康数据不匹配,则将所述目标声音特征输入所述健康状态模型以得到所述目标声音特征对应的健康状态数据,并将所述目标声音特征以及对应的健康状态数据添加到所述健康数据库。
进一步地,所述根据所述匹配结果输出所述声音信息对应的目标发声生物的健康状态的步骤之后,包括:
根据所述健康状态对所述目标发声生物的身体健康程度打分,并匹配对应所述身体健康程度的休养建议。
进一步地,所述方法,还包括:
获取指定量的样本数据,并将样本数据分成训练集和测试集,其中,所述样本数据包括已提取出的声音特征,以及与所述声音特征对应的健康状态数据;
将训练集的样本数据输入到预设的hmm中进行训练,得到结果训练模型;
利用所述测试集的样本数据验证所述结果训练模型;
如果验证通过,则将所述结果训练模型记为所述健康状态模型。
本发明还提供了一种基于声音识别的健康管理装置,包括:
获取单元,用于获取声音信息;
提取单元,用于提取所述声音信息的目标声音特征;
匹配单元,用于将所述目标声音特征输入到预设的健康数据库中进行匹配,其中,所述健康数据库包括多个声音特征以及各声音特征分别对应的健康状态数据;所述健康数据库中的声音特征对应的健康状态数据为所述声音特征经健康状态模型预测得到的预测结果;所述健康状态模型为多个已知健康状态数据的声音特征训练得到的模型;
输出单元,用于获取匹配结果,并根据所述匹配结果输出所述声音信息对应的目标发声生物的健康状态。
本发明还提供一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述方法的步骤。
本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述方法的步骤。
本发明的有益效果为:这样成本大大降低;当用户用于管理自己的身体健康时,不需贴身穿戴采集仪器,不会给用户带来不适感,推广面拓宽;另一方面,可通过声音信息进行身份识别,杜绝出现虚假数据。
附图说明
图1为本发明一实施例中的基于声音识别的健康管理方法的步骤示意图;
图2为本发明另一实施例中的基于声音识别的健康管理方法的步骤示意图;
图3为本发明一实施例中的基于声音识别的健康管理装置的结构示意框图;
图4为本发明另一实施例中的基于声音识别的健康管理装置的结构示意框图;
图5为本发明另一实施例中的基于声音识别的健康管理装置的结构示意框图;
图6为本发明另一实施例中的基于声音识别的健康管理装置的结构示意框图;
图7为本发明一实施例中的匹配单元的结构示意框图;
图8为本发明一实施例的计算机设备的结构示意框图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
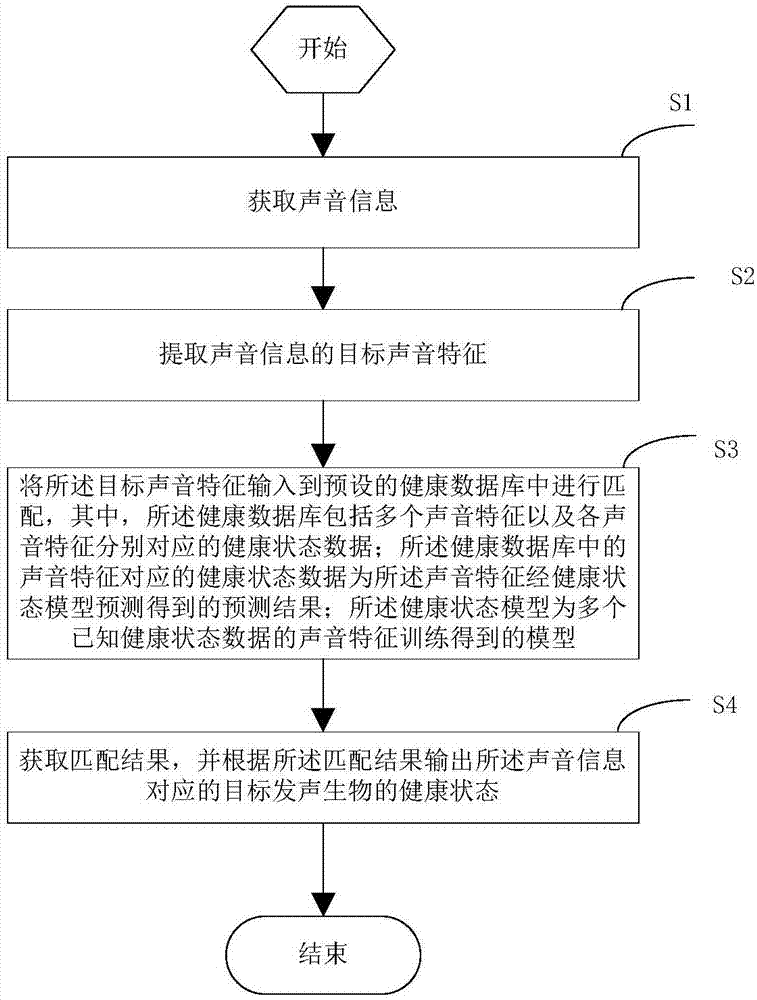
参照图1,本实施例中的基于声音识别的健康管理方法,包括:
步骤s1:获取声音信息;
步骤s2:提取所述声音信息的目标声音特征;
步骤s3:将所述目标声音特征输入到预设的健康数据库中进行匹配,其中,所述健康数据库包括多个声音特征以及各声音特征分别对应的健康状态数据;所述健康数据库中的声音特征对应的健康状态数据为所述声音特征经健康状态模型预测得到的预测结果;所述健康状态模型为多个已知健康状态数据的声音特征训练得到的模型;
步骤s4:获取匹配结果,并根据所述匹配结果输出所述声音信息对应的目标发声生物的健康状态。
在步骤s1中,本实施例中的基于声音识别的健康管理方法,需要获得待测的声音信息,具体的说,可以通过声音采集器采集声音,为了保证声音被准确完全采集,可以在上述声音的主人的活动区域放置多个声音采集器,且多个声音采集器放置在活动区域内的不同位置。这样,无需如传统采集数据仪器一样佩戴于被采集者身上即可获得声音,避免了给声音主人带来不适,扩宽了推广面,上述声音采集器包括麦克风阵列。通过声音采集器获得声音后,对上述声音进行降噪处理得到可以提取特征的声音信息。
在步骤s2中,对声音进行检测匹配之前,需要对声音信息进行声音特征提取,提取出的特征记为目标声音特征,上述目标声音特征包括时域特征参数和频域特征参数,其中,时域特征参数包括短时平均能量、短时平均幅度、短时平均过零率、共振峰、基音频率等,频域特征参数包括线性预测系数、线性预测倒谱系数、梅尔频率倒谱系数等。上述共振峰体现声道响应的特性,基音频率体现声门激励特征,线性预测系数、线性预测倒谱系数同时体现声门激励和声道响应的特性,梅尔频率倒谱系数模拟了人耳听觉特性,由于提取上述参数的方法为现有技术,故这里不再赘述,而不同健康状态对应不同的特征参数值,即对应不同的目标声音特征,因此,经过特征提取得到的目标声音特征能够反映健康状态。
在步骤s3中,将待测的声音信息经过特征提取后得到目标声音特征,然后输入到预设的健康数据库中进行匹配,其中,上述健康数据库包括多个声音特征以及各声音特征分别对应的健康状态数据,当将目标声音特征输入健康数据库进行匹配,则可以匹配到对应的健康状态数据,具体的说,上述健康数据库中的健康状态数据由上述声音特征经健康状态模型预测得到的预测结果,其中健康状态模型为多个已知健康状态数据的声音特征训练得到的模型,具体地,上述健康状态模型由指定样本集通过隐马尔可夫模型(hiddenmarkovmodel,hmm)进行训练得到,该指定样本集包括已知健康状态数据的声音特征、以及与声音特征一一对应的健康状态数据,上述健康状态数据包括完全健康数据、多种不同的疾病数据、多种不同的亚健康数据。
在步骤s4中,将目标声音特征输入到健康数据库后获得匹配结果,根据该匹配结果可输出声音信息对应的目标发声生物的健康状态。其中健康状态包括完全健康状态、多种不同的亚健康状态、多种不同的疾病状态。举例地,当将对应患有心脏病患者的目标声音特征输入到上述健康数据库中进行匹配,则该目标声音特征会与健康数据库的心脏病数据匹配,输出该匹配结果,即可输出声音信息对应的目标发声生物患有心脏病。
在一实施例中的基于声音识别的健康管理方法,所述获取所述声音信息的步骤s1之后,包括:
步骤s10:提取所述声音信息的声纹特征;
步骤s11:将所述声纹特征输入声纹识别模型中获取所述声音信息对应的目标发声生物的身份;
步骤s12:将所述目标发声生物的身份以及所述目标发声生物的健康状态结合,并输出结合结果。
在步骤s10中,在根据声纹特征分析声音信息对应的发声生物的身份之前,首先将获得的声音进行降噪处理得到声音信息,将上述声音信息分割为帧,然后对分割为帧的声音信息进行mfcc(mel-frequencycepstralcoefficients)特征提取,本步骤中,具体提取过程为,先将分割为帧的声音信息转化成梅尔频率,然后进行倒谱分析,最后将声纹特征提取出来。
在步骤s11中,先将上述声纹特征以及声纹纹征对应的目标发声生物的身份进行训练得到声纹识别模型。当再次采集到该声纹特征时,即可将该声纹特征输入声纹识别模型中进行匹配,进而可以匹配出该声纹特征的目标发声生物的身份。对上述目标发声生物进行身份识别,其原因在于需要确定上述声音信息的目标发声生物,由于每个生物经过mfcc特征提取后的声纹特征都是不同且唯一的,所以能避免获得发出该声音的生物与其健康状态虚假匹配的结果。
其中,训练声纹识别模型具体如下:将大量声纹特征以及上述声纹特征对应的发声生物的身份作为样本,上述声纹特征由对已降噪的声音进行mfcc特征提取得到,然后将上述声纹特征以及对应该特征的目标发声生物身份输入预设的基于声纹识别神经网络进行训练,从而得到声纹识别模型。
在步骤s21中,当识别出上述目标发声生物的身份,以及获得目标发声生物的健康状态之后,可以将上述目标发声生物的身份以及健康状态结合,然后输出结合结果,如输出张三身体完全健康、李四患有心脏病等。
上述方法可以应用于人类或动物,例如应用在保险行业,当被投保的为一个宠物狗,在投保之前先采集该宠物狗的声音,用于训练声纹识别模型,若该宠物狗的主人申请疾病理赔,但是该宠物狗并没有患病时,则可通过对该宠物狗的声纹特征进行身份识别,同时将对应的目标声音特征输入健康数据库匹配出宠物狗的健康状态,能确保被投保对象与对应采用上述声音信息得到的健康状态的发声生物一致,从而杜绝该宠物狗的主人通过各种手段表明该宠物狗患病而成功骗保;同理,当被投保的为人类,在投保之前先采集该被保人的声音,用于训练声纹识别模型,若投保人申请疾病理赔,但是被保人并没有患病时,则可通过对该被保人的声纹特征进行身份识别,以及通过将对应的目标声音特征输入健康数据库匹配出被保人的健康状态,能确保被投保对象与对应采用上述声音信息得到的健康状态的发声人一致,从而杜绝该投保人通过各种手段表明被保人患病而成功骗保。
在一具体实施例中,a需要实时监控自己的身体健康状态,以便在患病时得到及时治疗或休养,可在活动区域内放置声音采集器,如大厅或卧室等,声音采集器可采集a日常生活的说话声音,无需刻意对着声音采集器说话,当声音采集器采集到a的声音,将该声音输送至系统,然后对该声音进行特征提取得到声纹特征,并将该声纹特征输入声纹识别模型中进行匹配,得到a的身份,且将a的目标声音特征输入健康数据库中进行匹配,从而获得a的身体健康状态,这时结合a的身份以及健康状态结合,并将上述结合结果发送到a的手机上,从而让a实时了解自己的身体健康状态。让待测者可以监控自己的健康状态,同时避免诸如传统的佩戴设备采集数据的不适感。
参照图2,在另一实施例中的基于声音识别的健康管理方法,所述预设的健康数据库包括多个,各健康数据库与生物种类一一对应,所述将所述目标声音特征输入到预设的健康数据库中进行匹配的步骤s3之前,包括:
步骤s30’:根据所述声纹特征判断所述声音信息对应的目标发声生物的生物种类;
步骤s31’:调用与所述声音信息对应的生物种类对应的健康检数据库。
在步骤s30’中,不管是人类还是不同种类的动物均可以发出声音,且由于生理原因均有可能患有疾病,所以上述基于声音识别的健康管理方法可以应用于人类,也可以应用于动物。对于人类与不同种类的动物,实现上述方法的采用不一样的检测系统。本步骤中,需要指出的是,用于训练不同物种的健康状态模型的数据不同,其预测得到的健康数据库也不同,故不同物种之间不能采用同一个检测系统,所以依据发声生物的种类将上述声音信息分配到对应的检测系统中,以便进行下一个步骤。举例地,上述检测系统具有多个,如人类检测系统、动物检测系统,其中动物检测系统包括各种动物的检测系统,如狗检测系统、羊检测系统、牛检测系统、鸡检测系统等等,对应的,健康数据库也有多个,且各健康数据库与上述检测系统一一对应,即与生物种类一一对应。具体地,根据声纹特征判断声音信息对应的目标发声生物的生物种类,可采用物种数据库进行匹配,如当上述声纹特征为动物狗的声纹特征时,该声纹特征与物种数据库中的动物狗的数据匹配,即可判断该声纹特征的发声生物为动物狗,这时可将上述提取出的目标声音特征分配到狗检测系统,上述物种数据库可通过神经网络模型训练生成,其中用于训练的数据包括不同生物的声纹特征以及对应声纹特征的生物种类。
在步骤s31’中,当根据声纹特征判断声音信息对应的目标发声生物的生物种类时,将该声音特征分配至对应的检测系统,然后调用与上述声音信息对应的生物种类对应的健康数据库,由于用于训练不同物种的健康状态模型的数据不同,所以预测得到的健康数据库也不一样,即每一个生物种类均对应有一个相应的健康数据库,如,当判断出发声生物为动物狗时,将其声音特征分配至狗检测系统,调用动物狗的健康数据库,其中动物狗的健康数据库是由动物狗的声音特征以及对应该声音特征的健康状态数据输入隐马尔可夫模型进行训练得到。
在一具体实施例中,上述方法可以应用在养殖场,如在养殖场的不同空间位置放置分别放置声音采集器,通过声音采集器采集养殖场内各种动物的声音,并经处理即可通过上述方法得出不同动物的健康状态:健康或患有某种疾病。这样大大地降低养殖成本,及时了解养殖场的动物健康状态,避免瘟疫发生。
本实施例中的基于声音识别的健康管理方法,所述健康状态数据包括疾病数据、亚健康数据、完全健康数据;所述将所述目标声音特征输入到预设的健康数据库中进行匹配的步骤s3,包括:
步骤s30:判断所述目标声音特征与所述健康数据库的疾病数据是否匹配;
步骤s31:若所述目标声音特征与所述疾病数据匹配,则确定所述声音信息对应的所述目标发声生物为疾病状态;若所述声音目标特征与所述疾病数据不匹配,则判断所述目标声音特征与所述健康数据库的亚健康数据是否匹配;
步骤s32:若所述目标声音特征与所述亚健康数据匹配,则确定所述声音信息对应的所述目标发声生物为亚健康状态;若所述目标声音特征与健康数据库的亚健康数据不匹配,则判断所述目标声音特征与所述健康数据库的完全健康数据是否匹配;
步骤s33:若所述目标声音特征与所述完全健康数据匹配,则确定所述声音信息对应的所述目标发声生物为完全健康状态。
在步骤s30中,上述健康数据库中包括多个声音特征以及与上述各声音特征对应的健康状态数据,该健康状态数据包括疾病数据以及健康数据,其中由于疾病的多样性,每一种疾病的数据都不一样,所以疾病数据包括多种不同的疾病数据;由于健康包括亚健康以及完全健康,即上述健康数据包括多种不同的亚健康数据以及完全健康数据,而多种不同的亚健康数据以及完全健康数据具有共性,即声音特征对应的亚健康数据以及完全健康数据具有部分相同的数据,为便于表述将上述部分相同的数据称为共同数据。本步骤中,将上述目标声音特征与上述健康数据库的多种疾病数据进行对比,进而判断是否匹配。
在步骤s31中,若上述目标声音特征与上述健康数据库的其中一种疾病数据匹配,则可确定该目标声音特征对应的目标发声生物为疾病状态,且患有该疾病,可以结合上述通过声纹识别模型识别出的目标发声生物身份输出结果,如可输出该声音主人的名字以及患有的疾病类型。若判定上述目标声音特征与上述健康数据库的所有疾病数据均不匹配,则进一步地判断上述目标声音特征与上述健康数据库的亚健康数据是否匹配。
在步骤s32中,若上述目标声音特征与上述健康检测模型的其中一种亚健康数据匹配,则可以确定声音信息对应的目标发声生物为亚健康状态,举例地,采集b的声音,对b的声音进行特征提取,若该目标声音特征对应的健康状态数据为有睡眠紊乱的亚健康数据,当在上述健康数据库中进行匹配时,则与上述健康数据库里亚健康状态的睡眠紊乱数据匹配,这时即可输出b具有亚健康睡眠紊乱的结果。当上述声音特征与健康数据库的亚健康数据不匹配,则判断目标声音特征与健康数据库的完全健康数据是否匹配。
在步骤s33中,当上述目标声音特征与上述健康数据库的完全健康数据匹配时,则表明这个声音特征对应的健康状态数据为完全健康数据,则确定该声音特征的目标发声生物完全健康,没有患病也没有亚健康,这时输出上述声音信息对应的目标发声生物的健康状态,即完全健康,没有患病的状态。
进一步地,所述判断所述目标声音特征与所述健康数据库的完全健康数据是否匹配的步骤s32之后,包括:
步骤s34:若所述目标声音特征与所述完全健康数据不匹配,则将所述目标声音特征输入所述健康状态模型以得到所述目标声音特征对应的健康状态数据,并将所述目标声音特征以及对应的健康状态数据添加到所述健康数据库。
本步骤中,若目标声音特征与完全健康数据不匹配,则获取现实中的该目标声音特征对应的发声生物的健康状态,该健康状态的数据与上述目标声音特征相对应,将该目标声音特征以及上述对应的健康状态数据输入上述健康状态模型,从而预测得到可以添加进健康数据库中的与上述目标声音特征对应的健康状态数据,最后将上述目标声音特征以及对应的健康状态数据添加到健康数据库。
具体的说,由于健康数据包括多种不同的亚健康数据以及完全健康数据,而多种不同的亚健康数据以及完全健康数据均具有共同数据,而疾病数据具有不确定性,完全健康数据与亚健康数据的共同数据具有确定性,由于疾病多种多样,且相差极大,使得每一种疾病数据都不一样,故而疾病数据具有不确定性;而每个人不患病时,且完全健康时,这时身体表现出的只有一种状态,所以完全健康数据具有确定性,且亚健康也属于身体健康的范畴,故而亚健康数据带有与完全健康数据部分相同的数据,该部分相同的数据即为上述共同数据,也必具有确定性,且由于每个人健康时身体表现出的状态为确定的,所以该共同数据可用于判断上述目标声音特征对应的健康状态数据是否属于健康数据。所以若上述目标声音特征与健康数据库的所有疾病数据以及亚健康数据均不匹配,且这时上述目标声音特征与健康数据库的安全健康数据也不匹配,那么则需判断目标声音特征对应的健康状态数据的部分数据是否与上述共同数据匹配,若匹配,则表明与上述目标声音特征对应的健康状态数据仍属于健康数据,且由于完全健康数据为确定的,所以该健康状态数据为新型亚健康数据,即该目标声音特征的发声生物的身体处于没有患病的健康状态,且处于新型的亚健康状态。由于训练健康状态模型的样本有限,故而在上述健康数据库中并没有这种数据,这时,将上述声音特征输送至后台系统,训练健康状态模型,把预测得到的声音特征以及对应的新型亚健康数据增加到上述健康数据库中去,避免前期健康数据库没有匹配到全部身体情况而造成误判断。当判断与目标声音特征对应的健康状态数据中的部分数据与上述共同数据不匹配,由于共同数据确定,即发声生物的没有患病的健康状态是确定的,这时若不匹配,则表明与上述目标声音特征对应的健康状态数据为新型疾病数据,由于训练健康状态模型的样本有限,故而在上述健康数据库中并没有这种数据,这时,将上述声音特征输送至后台系统,用于训练上述健康状态模型,把得到的声音特征以及对应的新型疾病数据增加到上述健康数据库中去,避免前期健康数据库没有匹配到新型疾病而造成误判断。
本实施例中的基于声音识别的健康管理方法,所述根据所述匹配结果输出所述声息信息对应的目标发声生物的健康状态的步骤s4之后,包括:
步骤s5:根据所述健康状态对所述目标发声生物的身体健康程度打分,并匹配对应所述身体健康程度的休养建议。
在步骤s5中,系统设置有与上述健康数据库中每种亚健康类型以及疾病类型配对的休养建议以及分数的表格,当根据匹配结果判断出上述声音信息对应的目标发声生物的健康状态时,不同的健康状态表明发声生物身体健康程度的不同,系统根据上述身体健康程度在表格中查寻对应的休养建议以及分数,如针对判断为完全健康状态时,建议为保持现状,分数为100分;针对判断出为疲劳过度睡眠紊乱的亚健康,对应的休养建议为合理饮食、适量运动、作息规律,其分数为85分等。
进一步地,系统将上述目标发声生物身份与上述亚健康类型、对应的休养建议及分数输出到指定地方,如输送到上述声音信息的主人的邮箱上,打分使得用户更直观知道身体的健康程度情况,同时用户可以通过执行休养建议有针对性地休养身体,使身体更健康,且该方法方便直观便捷。
在另一实施例中,由于疾病数据具有不确定性,完全健康数据与亚健康数据的共同数据具有确定性,所以基于声音识别的健康管理方法还包括通过以下步骤实现:获取目标声音特征,将该目标声音特征输入到的疾病资料库中进行匹配,若该目标声音特征与疾病资料库中的某种疾病数据匹配,则可根据该匹配结果确定该目标声音特征的目标发声生物患有某种疾病;若该目标声音特征与疾病资料库中的疾病数据不匹配,则将目标声音特征输入到健康资料库中匹配,若目标声音特征与健康资料库中的共同数据匹配,则可根据该匹配结果确定该声音特征的目标发声生物处于为不患病的健康状态。进一步地,若上述目标声音特征既不与疾病资料库的疾病数据匹配,也不与健康资料库的共同数据匹配,则判断与该目标声音特征对应的健康状态数据为新型疾病数据,可通过上述新型疾病数据以及对应的声音特征再次训练疾病检测模型,将该声音特征以及对应的新型疾病数据添加至疾病资料库,当上述目标声音特征与健康资料库中的共同数据匹配,且不与完全健康数据匹配时,即判断该声音特征的发声生物为亚健康状态,进一步,当上述目标声音特征与健康资料库中的共同数据匹配,但却与完全健康数据以及所有的亚健康数据均不匹配时,则判断与该目标声音特征对应的健康状态数据为新型亚健康数据,可通过上述新型亚健康数据以及对应的声音特征再次训练健康检测模型,将该声音特征以及对应新型亚健康数据添加至健康资料库。
上述疾病资料库以及健康资料库均可参照上述健康数据库的生成过程而得到,具体地,可以将声音特征以及声音特征对应的疾病数据输入预设的hmm模型进行训练,得到疾病检测模型,从而预测得到疾病资料库;将声音特征以及声音特征对应的健康数据输入到预设的hmm模型进行训练,得到健康检测模型,从而预测得到健康资料库。
本实施例中,所述方法还包括:
获取指定量的样本数据,并将样本数据分成训练集和测试集,其中,所述样本数据包括已提取出的声音特征,以及与所述声音特征对应的健康状态数据;
将训练集的样本数据输入到预设的hmm中进行训练,得到结果训练模型;
利用所述测试集的样本数据验证所述结果训练模型;
如果验证通过,则将所述结果训练模型记为所述健康状态模型。
对于健康状态模型,只有在训练完成之后,才能预测得到用于匹配对应的身体健康状态的健康数据库。而在对健康状态模型进行训练时,需要获取大量的样本数据,并将上述样本数据分成训练集和测试集,其中上述样本数据包括已提取的声音特征,以及与上述已提取的声音特征对应的健康状态数据。将上述训练集的样本数据输入到预设的隐马尔可夫模型中进行训练,得到用于进行健康检测的结果训练模型。
综上所述,通过上述基于声音识别的健康管理,只需安装声音采集器即可采集声音,然后将声音处理得到声音特征,并输入健康数据库中匹配得到匹配结果,可根据匹配结果判断发声生物的健康状态,这样成本大大降低;当用户用于管理自己的身体健康时,不需贴身穿戴采集仪器,不会给用户带来不适感,推广面拓宽;另一方面,可通过声音信息进行身份识别,杜绝出现虚假数据。
参照图3,本实施例中的基于声音识别的健康管理装置,包括:
获取单元100,用于获取声音信息;
提取单元200,用于提取所述声音信息的目标声音特征;
匹配单元300,用于将所述目标声音特征输入到预设的健康数据库中进行匹配,其中,所述健康数据库包括多个声音特征以及各声音特征分别对应的健康状态数据;所述健康数据库中的声音特征对应的健康状态数据为所述声音特征经健康状态模型预测得到的预测结果;所述健康状态模型为多个已知健康状态数据的声音特征训练得到的模型;
输出单元400,用于获取匹配结果,并根据所述匹配结果输出所述声音信息对应的目标发声生物的健康状态。
本实施例中的基于声音识别的健康管理方法,获取单元100需要获得待测的声音信息,具体的说,可以通过声音采集器采集声音,为了保证声音被准确完全采集,可以在上述声音的主人的活动区域放置多个声音采集器,且多个声音采集器放置在活动区域内的不同位置。这样,无需如传统采集数据仪器一样佩戴于被采集者身上即可获得声音,避免了给声音主人带来不适,扩宽了推广面,上述声音采集器包括麦克风阵列。获取单元100通过声音采集器获得声音后,对上述声音进行降噪处理得到可以提取特征的声音信息。
在对声音进行检测匹配之前,提取单元200对声音信息进行声音特征提取,提取出的特征记为目标声音特征,上述目标声音特征包括时域特征参数和频域特征参数,其中,时域特征参数包括短时平均能量、短时平均幅度、短时平均过零率、共振峰、基音频率等,频域特征参数包括线性预测系数、线性预测倒谱系数、梅尔频率倒谱系数等。上述共振峰体现声道响应的特性,基音频率体现声门激励特征,线性预测系数、线性预测倒谱系数同时体现声门激励和声道响应的特性,梅尔频率倒谱系数模拟了人耳听觉特性,由于提取上述参数的方法为现有技术,故这里不再赘述,而不同健康状态的对应有不同的特征参数值,即对应不同的声音特征,因此,经过特征提取得到的目标声音特征能够反映健康状态。
匹配单元300将待测的声音信息经过特征提取后得到目标声音特征,然后输入到预设的健康数据库中进行匹配,其中,上述健康数据库包括多个声音特征以及各声音特征分别对应的健康状态数据,当将目标声音特征输入健康数据库进行匹配,则可以匹配到对应的健康状态数据,具体的说,上述健康健康数据库的健康状态数据由上述声音特征经健康状态模型预测得到的预测结果,其中健康状态模型为多个已知健康状态数据的声音特征训练得到的模型,具体地,上述健康状态模型由指定样本集通过隐马尔可夫模型(hiddenmarkovmodel,hmm)进行训练得到,该指定样本集包括已知健康状态数据的声音特征、以及与声音特征一一对应的健康状态数据,上述健康状态数据包括与完全健康数据、多种不同的疾病数据、多种不同的亚健康数据。
将目标声音特征输入到训练成功后的健康数据库则获得匹配结果,输出单元400根据该匹配结果可输出声音信息对应的目标发声生物的健康状态。其中健康状态包括完全健康状态、多种不同的亚健康状态、多种不同的疾病状态。举例地,当将对应患有心脏病患者的目标声音特征输入到上述健康数据库中进行匹配,则该目标声音特征会与健康数据库的心脏病数据匹配,输出该匹配结果,即可输出声音信息对应的发声生物患有心脏病。
参照图5,在一实施例中的基于声音识别的健康管理装置,还包括包括:
声纹单元500:用于提取所述声音信息的声纹特征;
身份单元510:用于将所述声纹特征输入声纹识别模型中获取所述声音信息对应的目标发声生物的身份;
结合单元520:用于将所述目标发声生物的身份以及所述目标发声生物的健康状态结合,并输出结合结果。
在根据声纹特征分析声音信息对应的发声生物的身份之前,首先将获得的声音进行降噪处理得到声音信息,将上述声音信息分割为帧,然后对分割为帧的声音信息进行mfcc(mel-frequencycepstralcoefficients)特征提取,本步骤中,具体提取过程为,先将分割为帧的声音信息转化成梅尔频率,然后进行倒谱分析,最后将声纹特征提取出来。
在获取上述目标发声生物的身份之前,先采用上述声纹特征以及声纹特征对应的目标发声生物的身份进行训练得到声纹识别模型。当再次采集到该声纹特征时,即可将该声纹特征输入声纹识别模型中进行匹配,进而可以通过声纹识别库匹配出该声纹特征的发声生物的身份。当匹配单元300将目标声音特征输入健康数据库进行匹配得到匹配结果,最后结合上述发声生物身份,输出最终结果。对上述目标发声生物进行身份识别,其原因在于需要确定上述声音信息的目标发声生物,由于每个生物经过mfcc特征提取后的声纹特征都是不同且唯一的,所以能避免获得发出该声音的生物与其健康状态虚假匹配的结果。
其中,训练声纹识别模型具体如下:将大量声纹特征以及上述声纹特征对应的发声生物的身份作为样本,上述声纹特征由对已降噪的声音进行mfcc特征提取得到,然后将大量的上述mfcc特征以及对应该特征的发声生物身份输入预设的基于声纹识别神经网络进行训练,从而得到声纹识别模型。
当身份单元500识别出上述目标发声生物的身份,以及获得出发声生物的健康状态之后,结合单元510可以将上述目标发声生物的身份以及健康状态结合,然后输出结合结果,如输出张三身体完全健康、李四患有心脏病等
上述装置可以应用于人类或动物,例如应用在保险行业,当被投保的为一个宠物狗,在投保之前先采集该宠物狗的声音,用于训练声纹识别模型,若该宠物狗的主人申请疾病理赔,但是该宠物狗并没有患病时,则可通过对该宠物狗的声纹特征进行身份识别,同时通过将对应的目标声音特征输入健康数据库匹配出宠物狗的健康状态,能确保被投保对象与对应采用上述声音信息得到的健康状态的发声生物一致,从而杜绝该宠物狗的主人通过各种手段表明该宠物狗患病而成功骗保;同理,当被投保的为人类,在投保之前先采集该被保人的声音,用于训练声纹识别模型,若投保人申请疾病理赔,但是被保人并没有患病时,则可通过对该被保人的声纹特征进行身份识别,以及通过将对应的目标声音特征输入健康数据库匹配出被保人的健康状态,能确保被投保对象与对应采用上述声音信息得到的健康状态的发声人一致,从而杜绝该投保人通过各种手段表明被保人患病而成功骗保。
在一具体实施例中,a需要实时监控自己的身体健康状态,以便在患病时得到及时治疗或休养,可在活动区域内放置声音采集器,如大厅或卧室等,声音采集器可采集a日常生活的说话声音,无需刻意对着声音采集器说话,当声音采集器采集到a的声音,将该声音输送至系统,然后对该声音进行特征提取得到声纹特征,并将该声纹特征输入声纹识别模型中进行匹配,得到a的身份,且将a的目标声音特征输入健康数据库中进行匹配,从而获得a的身体健康状态,这时结合a的身份以及健康状态结合,并将上述结合结果发送到a的手机上,从而让a实时了解自己的身体健康状态。让待测者可以监控自己的健康状态,同时避免诸如传统的佩戴设备采集数据的不适感。
参照图4,在另一实施例中的基于声音识别的健康管理装置,所述预设的健康数据库包括多个,各健康数据库与生物种类一一对应,还包括:
分类单元600,用于根据所述声纹特征判断所述声音信息对应的目标发声生物的生物种类;
调用单元700,用于调用与所述声音信息对应的生物种类对应的健康数据库。
不管是人类还是不同种类的动物均可以发出声音,且由于生理原因均有可能患有疾病,所以上述基于声音识别的健康管理装置可以应用于人类,也可以应用于动物。对于人类与不同种类的动物,实现上述装置采用不一样的检测系统。需要指出的是,用于训练不同物种的健康状态模型的数据不同,其预测得到的健康数据库也不同,故不同物种之间不能采用同一个检测系统,所以依据发声生物的种类将上述声音信息分配到对应的检测系统中,以便进行下一个步骤。举例地,上述检测系统具有多个,如人类检测系统、动物检测系统,其中动物检测系统包括各种动物的检测系统,如狗检测系统、羊检测系统、牛检测系统、鸡检测系统等等,对应的,健康数据库也有多个,且各健康数据库与上述检测系统一一对应,即与生物种类一一对应。具体地,分类单元600根据上述声纹特征判断声音信息对应的发声生物的生物种类,可采用物种数据库进行匹配,如当上述声纹特征为动物狗的声纹特征时,该声纹特征与物种数据库中的动物狗的数据匹配,即可判断该声纹特征的发声生物为动物狗,这时可将上述提取出的目标声音特征分配到狗检测系统,上述物种数据库可通过神经网络模型训练生成,其中用于训练的数据包括不同生物的声纹特征以及对应声纹特征的生物种类。
当分类单元600根据声纹特征判断声音信息对应的目标发声生物的生物种类时,将该声音特征分配至对应的检测系统,然后调用单元700调用与上述声音信息对应的生物种类对应的健康数据库,由于用于训练不同物种的健康状态模型的数据不同,所以预测得到的健康数据库也不一样,即每一个生物种类均对应有一个相应的健康数据库,如,当判断出发声生物为动物狗时,将其声音特征分配至狗检测系统,从而调用动物狗的健康数据库,其中动物狗的健康数据库是由动物狗的声音特征以及对应该声音特征的健康状态数据输入隐马尔可夫模型进行训练得到。
在一具体实施例中,上述装置可以应用在养殖场,如在养殖场的不同空间位置放置分别放置声音采集器,通过声音采集器采集养殖场内各种动物的声音,并经处理即可通过上述方法得出不同动物的健康状态:健康或患有某种疾病。这样大大地降低养殖成本,及时了解养殖场的动物健康状态,避免瘟疫发生。
参照图7,本实施例中的基于声音识别的健康管理装置,所述健康状态数据包括疾病数据、亚健康数据、完全健康数据;所述匹配单元300包括:
第一判断子单元310,用于判断所述目标声音特征与所述健康数据库的疾病数据是否匹配;
第二判断子单元320,用于判定所述目标声音特征与所述疾病数据匹配时,确定所述声音信息对应的所述目标发声生物为疾病状态;所述目标声音特征与所述疾病数据不匹配时,判断所述目标声音特征与所述健康数据库的亚健康数据是否匹配;
第三判断子单元330,用于判定所述目标声音特征与所述亚健康数据匹配时,确定所述声音信息对应的所述目标发声生物为亚健康状态;所述声音特征与健康数据库的亚健康数据不匹配时,则判断所述目标声音特征与所述健康数据库的完全健康数据是否匹配;
输出子单元340,用于判定所述目标声音特征与所述完全健康数据匹配,则确定所述声音信息对应的所述目标发声生物为完全健康状态。
上述健康数据库中包括多个声音特征以及与上述各声音特征对应的健康状数据,该健康状态数据包括疾病数据以及健康数据,其中由于疾病的多样性,每一种疾病的数据都不一样,所以疾病数据包括多种不同的疾病数据;由于健康包括亚健康以及完全健康,即上述健康数据包括多种不同的亚健康数据以及完全健康数据,而多种不同的亚健康数据以及完全健康数据具有共性,即声音特征对应的亚健康数据以及完全健康数据具有部分相同的数据,为便于表述将上述部分相同的数据称为共同数据。将提取出的声音特征输入到上述健康数据库中,第一判断子单元310将上述声音目标特征与上述健康数据库的多种疾病数据进行对比,进而判断是否匹配。
若上述目标声音特征与上述健康数据库的其中一种疾病数据一致,则可确定该目标声音特征对应的目标发声生物为疾病状态,且患有该疾病,可以结合上述通过声纹识别模型识别出的目标发声生物身份输出结果,如可输出该声音主人的名字以及患有的疾病类型。若在判定上述目标声音特征与上述健康数据库的所有疾病数据均不匹配,第二判断子单元320进一步地判断上述目标声音特征与上述健康数据库的亚健康数据是否匹配。
若上述目标声音特征与上述健康检测模型的其中一种亚健康数据匹配,则可以确定声音信息对应的目标发声生物为亚健康状态,举例地,采集b的声音,对b的声音进行特征提取,若提取到的目标声音特征对应的健康状态数据为有睡眠紊乱的亚健康数据,当将目标声音特征在上述健康数据库中进行匹配时,则与上述健康数据库里亚健康状态的睡眠紊乱数据匹配,这时即可输出b具有亚健康睡眠紊乱的结果。当上述目标声音特征与健康数据库的亚健康数据不匹配,则第三判断子单元330判断目标声音特征与健康数据库的安全健康数据是否匹配。
当上述目标声音特征与上述健康数据库的完全健康数据匹配时,则表明这个声音特征对应的健康状态数据为完全健康数据,则确定该声音特征的目标发声生物完全健康,没有患病也没有亚健康,这时输出子单元340输出上述声音信息对应的目标发声生物的健康状态,即完全健康,没有患病的状态。
进一步地,所述匹配单元300包括还包括:
添加子单元350,用于判定所述目标声音特征与所述完全健康数据不匹配时,则将所述目标声音特征输入所述健康状态模型以得到所述目标声音特征对应的健康状态数据,并将所述目标声音特征以及对应的健康状态数据添加到所述健康数据库。
当判定所述目标声音特征与所述完全健康数据不匹配时,获取现实中的该目标声音特征对应的发声生物的健康状态,该健康状态的数据与上述目标声音特征对应,将该目标声音特征以及健康状态数据输入上述健康状态模型,从而预测得到可以添加进健康数据库中的与上述目标声音特征对应的健康状态数据,最后将上述目标声音特征以及对应的健康状态数据添加到健康数据库。
具体的说,由于健康数据包括多种不同的亚健康数据以及完全健康数据,而多种不同的亚健康数据以及完全健康数据均具有共同数据,而疾病数据具有不确定性,完全健康数据与亚健康数据的共同数据具有确定性,由于疾病多种多样,且相差极大,使得每一种疾病数据都不一样,故而疾病数据具有不确定性;而每个人不患病时,且完全健康时,这时身体表现出的只有一种状态,所以完全健康数据具有确定性,且亚健康也属于身体健康的范畴,故而亚健康数据带有与完全健康数据部分相同的数据,该部分相同的数据即为上述共同数据,也必具有确定性,且由于每个人健康时身体表现出的状态为确定的,所以该共同数据可用于判断上述目标声音特征对应的健康状态数据是否属于健康数据。所以若上述目标声音特征与健康数据库的所有疾病数据以及亚健康数据均不匹配,且这时上述目标声音特征与健康数据库的安全健康数据也不匹配,那么则需判断目标声音特征对应的健康状态数据的部分数据是否与上述共同数据匹配,若匹配,则表明上述目标声音特征对应的健康状态数据仍属于健康数据,且由于完全健康数据为确定的,所以该健康状态数据为新型亚健康数据,即该目标声音特征的发声生物的身体处于没有患病的健康状态,且处于新型的亚健康状态。由于训练健康检测模型的样本有限,故而在上述健康数据库中并没有这种数据,这时,添加子单元350将上述声音特征输送至后台系统,训练上述健康状态模型,把预测得到的声音特征以及对应的新型亚健康数据增加到上述健康数据库中去,避免前期健康数据库没有匹配到全部身体情况而造成误判断。当判断与目标声音特征对应的健康状态数据的部分数据与上述共同数据不匹配,由于共同数据确定,即发声生物的没有患病的健康状态是确定的,这时若不匹配,则表明与上述目标声音特征对应的健康状态数据为新型疾病数据,由于训练健康检测模型的样本有限,故而在上述健康数据库中并没有这种数据,这时,添加子单元350将上述声音特征输送至后台系统,训练上述健康状态模型,把预测得到的声音特征以及对应的新型疾病数据增加到上述健康数据库中去,避免前期健康数据库没有匹配到新型疾病而造成误判断。
参照图6,本实施例中的基于声音识别的健康管理装置,还包括:
打分单元800,用于根据所述健康状态对所述目标发声生物的身体健康程度打分,并匹配对应所述身体健康程度的休养建议。
系统设置有与上述健康数据库中每种亚健康类型以及疾病类型配对的休养建议以及分数的表格,当根据匹配结果判断出上述声音信息对应的目标发声生物的健康状态时,不同的健康状态表明发声生物身体健康程度的不同,打分单元800根据上述身体健康程度在表格中查寻对应的休养建议以及分数,如针对判断为完全健康状态时,建议为保持现状,分数为100分;针对判断出为疲劳过度睡眠紊乱的亚健康,对应的休养建议为合理饮食、适量运动、作息规律,其分数为85分等。
进一步地,系统将上述目标声音特征的发声生物身份与上述亚健康类型、对应的休养建议及分数输出到指定地方,如输送到上述声音信息的主人的邮箱上,打分使得用户更直观知道身体的健康程度情况,同时用户可以通过执行休养建议有针对性地休养身体,使身体更健康,且该方法方便直观便捷。
在另一实施例中,由于疾病数据具有不确定性,完全健康数据与亚健康数据的共同数据具有确定性,所以基于声音识别的健康管理方法还包括通过以下步骤实现:获取目标声音特征,先将目标声音特征输入疾病资料库中进行匹配,若该目标声音特征与疾病资料库中的某种疾病数据匹配,则可根据该匹配结果确定该目标声音特征的目标发声生物患有某种疾病;若该目标声音特征与疾病资料库中的疾病数据不匹配,则将目标声音特征输入健康资料库中匹配,若目标声音特征与健康资料库中的共同数据匹配,则可根据该匹配结果确定该声音特征的目标发声生物处于为不患病的健康状态。进一步地,若上述目标声音特征既不与疾病资料库的疾病数据匹配,也不与健康资料库的共同数据匹配,则判断与该目标声音特征对应的健康状态数据为新型疾病数据,可通过上述新型疾病数据以及对应的声音特征再次训练疾病检测模型,将该目标声音特征以及对应的新型疾病数据添加至疾病资料库,当上述目标声音特征与健康资料库中的共同数据匹配,且不与完全健康数据匹配时,即判断该声音特征的发声生物为亚健康状态,进一步,当上述目标声音特征与健康资料库中的共同数据匹配,但却与完全健康数据以及所有的亚健康数据均不匹配时,则判断与该目标声音特征对应的健康状态数据为新型亚健康数据,可通过上述新型亚健康数据以及对应的声音特征再次训练健康检测模型,将该目标声音特征以及对应新型亚健康数据添加至健康资料库。
上述疾病资料库以及健康资料库均可参照上述健康数据库的生成过程而得到,具体地,可以将声音特征以及声音特征对应的疾病数据输入预设的hmm模型进行训练,得到疾病检测模型,从而预测得到疾病资料库;将声音特征以及声音特征对应的健康数据输入到预设的hmm模型进行训练,得到健康检测模型,从而预测得到健康资料库。
本实施例中,所述的方法还包括:
获取指定量的样本数据,并将样本数据分成训练集和测试集,其中,所述样本数据包括已提取出的声音特征,以及与所述声音特征对应的健康状态数据;
将训练集的样本数据输入到预设的hmm中进行训练,得到结果训练模型;
利用所述测试集的样本数据验证所述结果训练模型;
如果验证通过,则将所述结果训练模型记为所述健康状态模型。
对于健康检状态模型,只有在训练完成之后,才能预测得到用于匹配对应的身体健康状态的健康数据库。而在对健康检状态模型进行训练时,需要获取大量的样本数据,并将上述样本数据分成训练集和测试集,其中上述样本数据包括已提取的声音特征,以及与上述已提取的声音特征对应的健康状态数据。将上述训练集的样本数据输入到预设的隐马尔可夫模型中进行训练,得到用于进行健康检测的结果训练模型。
参照图8,本发明实施例中还提供一种计算机设备,该计算机设备可以是服务器,其内部结构可以如图8所示。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设计的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于预设的健康状态模型等数据。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种基于声音识别的健康管理方法。
上述处理器执行上述基于声音识别的健康管理方法的步骤:获取声音信息;提取所述声音信息的目标声音特征;将所述目标声音特征输入到预设的健康数据库中进行匹配,其中,所述健康数据库包括多个声音特征以及各声音特征分别对应的健康状态数据;所述健康数据库中的声音特征对应的健康状态数据为所述声音特征经健康状态模型预测得到的预测结果;所述健康状态模型为多个已知健康状态数据的声音特征训练得到的模型;获取匹配结果,并根据所述匹配结果判断所述声息信息对应的目标发声生物的健康状态。
上述计算机设备,基于隐马尔可夫模型,训练得到健康状态模型,对于待测声音信息特征提取得到目标声音特征,将上述声音特征输入到预设的健康数据库中进行匹配,获取匹配结果,可根据该匹配结果判断上述声音信息对应的发声生物的健康状态。
在一个实施例中,所述获取所述声音信息之后,包括:提取所述声音信息的声纹特征;将所述声纹特征输入通过声纹识别模型中获取所述声音信息对应的目标发声生物的身份;将所述目标发声生物的身份以及所述目标发声生物的健康状态结合,并输出结合结果。
在一个实施例中,所述预设的健康数据库包括多个,各健康数据库与生物种类一一对应,所述将所述目标声音特征输入到预设的健康数据库进行匹配之前,包括:根据所述声纹特征判断所述声音信息对应的目标发声生物的生物种类;调用与所述声音信息对应的生物种类对应的健康数据库。
在一个实施例中,所述健康状态数据包括疾病数据、亚健康数据、完全健康数据;上述将上述声音特征输入到预设的健康数据库中进行匹配的步骤,包括:判断上述目标声音特征与上述健康数据库的疾病数据是否匹配;若所述目标声音特征与所述疾病数据匹配,则确定所述声音信息对应的所述目标发声生物为疾病状态;若上述目标声音特征与所述疾病数据不匹配,则判断上述目标声音特征与上述健康数据库的亚健康数据是否匹配;若所述目标声音特征与所述亚健康数据匹配,则确定所述声音信息对应的所述目标发声生物为亚健康状态;若上述目标声音特征与所述健康数据库的亚健康数据不匹配,则判断上述目标声音特征与所述健康数据库的完全健康数据是否匹配;若上述目标声音特征与上述完全健康数据匹配,则确定上述声音信息对应的上述目标发声生物为完全健康状态。
在一个实施例中,判断上述目标声音特征与健康数据库的完全健康数据是否匹配之后,包括:若所述目标声音特征与所述完全健康数据不匹配,则将所述目标声音特征输入所述健康状态模型以得到所述目标声音特征对应的健康状态数据,并将所述目标声音特征以及对应的健康状态数据添加到所述健康数据库,避免前期健康数据库匹配不到新的声音特征而造成误判断。
在一个实施例中,所述根据所述匹配结果输出所述声息信息对应的目标发声生物的健康状态的步骤之后,包括:根据所述健康状态对所述目标发声生物的身体健康程度打分,并匹配对应所述身体健康程度的休养建议,用户更直观知道身体的健康程度情况。
本领域技术人员可以理解,图8中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定。
本发明一实施例还提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现一种基于声音识别的健康管理方法,具体为:获取声音信息;提取所述声音信息的目标声音特征;将所述目标声音特征输入到预设的健康数据库中进行匹配,其中,所述健康数据库包括多个声音特征以及各声音特征分别对应的健康状态数据;所述健康数据库中的声音特征对应的健康状态数据为所述声音特征经健康状态模型预测得到的预测结果;所述健康状态模型为多个已知健康状态数据的声音特征训练得到的模型;获取匹配结果,并根据所述匹配结果判断所述声息信息对应的目标发声生物的健康状态。
上述计算机可读存储介质,基于隐马尔可夫模型,训练得到健康状态模型,对于待预测声音信息特征提取得到目标声音特征,将上述声音特征输入到预设的健康数据库中进行匹配,获取匹配结果,可根据该匹配结果判断上述声音信息对应的发声生物的健康状态。
在一个实施例中,所述获取所述声音信息之后,包括:提取所述声音信息的声纹特征;将所述声纹特征输入声纹识别模型中获取所述声音信息对应的目标发声生物的身份;将所述目标发声生物的身份以及所述目标发声生物的健康状态结合,并输出结合结果。
在一个实施例中,所述预设的健康数据库包括多个,各健康数据库与生物种类一一对应,所述将所述目标声音特征输入到预设的健康数据库进行匹配之前,包括:根据所述声纹特征判断所述声音信息对应的目标发声生物的生物种类;调用与所述声音信息对应的生物种类对应的健康数据库。
在一个实施例中,所述健康状态数据包括疾病数据、亚健康数据、完全健康数据;上述将上述声音特征输入到预设的健康数据库中进行匹配的步骤,包括:判断上述目标声音特征与上述健康数据库的疾病数据是否匹配;若所述目标声音特征与所述疾病数据匹配,则确定所述声音信息对应的所述目标发声生物为疾病状态;若上述目标声音特征与所述疾病数据不匹配,则判断上述目标声音特征与上述健康数据库的亚健康数据是否匹配;若所述目标声音特征与所述亚健康数据匹配,则确定所述声音信息对应的所述目标发声生物为亚健康状态;若上述目标声音特征与所述健康数据库的亚健康数据不匹配,则判断上述目标声音特征与所述健康数据库的完全健康数据是否匹配;若上述目标声音特征与上述完全健康数据匹配,则确定上述声音信息对应的上述目标发声生物为完全健康状态。
在一个实施例中,判断上述目标声音特征与健康数据库的完全健康数据是否匹配之后,包括:若所述目标声音特征与所述完全健康数据不匹配,将所述目标声音特征输入所述健康状态模型以得到所述目标声音特征对应的健康状态数据,并将所述目标声音特征以及对应的健康状态数据添加到所述健康数据库,避免前期健康数据库匹配不到新的声音特征而造成误判断。
在一个实施例中,所述根据所述匹配结果输出所述声息信息对应的目标发声生物的健康状态的步骤之后,包括:根据所述健康状态对所述目标发声生物的身体健康程度打分,并匹配对应所述身体健康程度的休养建议,用户更直观知道身体的健康程度情况。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储与一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的和实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可以包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram一多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双速据率sdram(ssrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、装置、物品或者方法不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、装置、物品或者方法所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、装置、物品或者方法中还存在另外的相同要素。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!