一种基于XGBoost+SVM混合机器学习诊断圆锥角膜病例的方法与流程
本发明属于眼科医疗诊断领域,涉及机器学习技术,尤其是一种基于xgboost+svm混合机器学习诊断圆锥角膜病症的方法。
背景技术:
圆锥角膜(keratoconus)是一种以角膜扩张为特征,致角膜中央或旁中央区向前凸出呈圆锥形及产生高度不规则近视散光和不同视力损害的原发性角膜变性疾病,其可以是一种独立的疾病,也可以是多种综合征的组成部分。其多发生于青春期前后,不伴有炎症。晚期会出现急性角膜水肿,形成瘢痕,视力严重受损。明显的圆锥角膜易于确诊。当外观及裂隙灯所见不典型时,早期诊断较困难。最有效的方法为角膜地形图检查。但即便如此,早期圆锥角膜的诊断标准并未完全统一,对于相对复杂的疑似圆锥角膜病例多需由经验丰富的专家进行详细会诊讨论才能给予相对准确的诊断;同时大量的病例、有限的专家、复杂的角膜参数都给圆锥角膜的早期诊增加了很大的难度。因此圆锥角膜的早期筛查已成为亟待解决的关键问题。
本发明中涉及到的极值梯度提升模型(xgboost)算法是现今工业上应用最多的机器学习模型之一,其基分类器可以从决策树(gbtree)和线性(gblinear)核函数中任意选择。xgboost内部包含大量的决策回归树,使用残差来提升模型,并且加入了正则化以防止过拟合,保证模型的鲁棒性。本发明首先使用训练样本训练xgboost模型来扩充新特征,其方法为:基于xgboost迭代产生的决策树的结构特征,可以记录每条训练样本数据在各决策树叶子结点中的位置,依此对该训练样本进行one-hot编码,将其作为该训练数据的新特征,实现对训练数据的特征扩充。由于one-hot编码产生的新特征能较好的描述众多弱分类器(xgboost迭代产生的决策树)对该样本的分类决策,因此,这些扩充的新特征将有助于提升样本的类别区分度,即提升训练样本的预测价值,进而提升预测模型的精准度。基于样本扩充后的特征,本发明采用当下流行的支持向量机方法(svm)训练构建诊断模型,svm在解决小样本、高维特征模式识别问题中表现出许多特有的优势,其最终的目标函数将由少数的支持向量所决定,并不取决于样本空间的维数,某种程度上避免了维数灾难,而且具有较好的鲁棒性和预测效率。
在诊断临床早期圆锥角膜(疑似圆锥角膜)及圆锥角膜病例的应用上,本发明通过使用极值梯度提升模型(xgboost)模型对原始样本的特征进行扩充,并结合支持向量机(svm)预测模型进行筛查诊断,拥有较好的临床效果,能够有效辅助眼科医师,对临床病况做出高效且精准的诊断。
技术实现要素:
本发明提供一种基于机器学习诊断圆锥角膜病例的方法,进行圆锥角膜、疑似圆锥角膜、及正常角膜的判定,为眼科医师临床诊断提供可靠的辅助工具。
实现本发明目的的技术方案为:
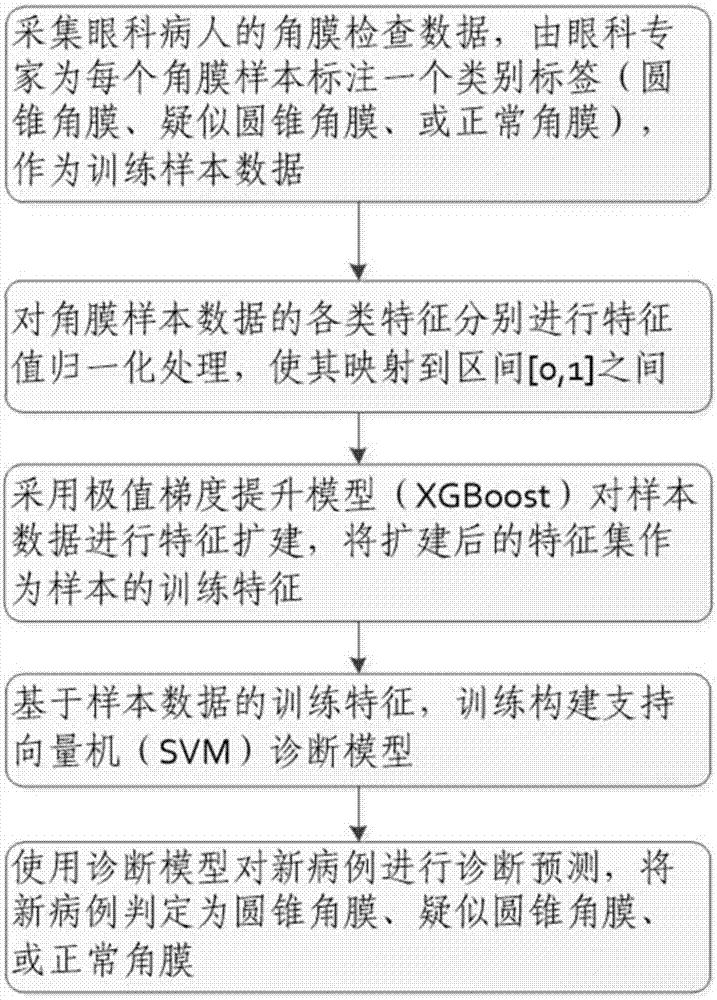
步骤1:采集眼科病人的角膜检查数据,由眼科专家为每个角膜样本标注一个类别标签(圆锥角膜、疑似圆锥角膜、正常角膜),作为训练样本数据;
步骤2:对角膜样本数据的各类特征分别进行特征值归一化处理,使其映射到区间[0,1]之间;
步骤3:采用极值梯度提升模型(xgboost)对样本数据进行特征扩建,将扩建后的特征集作为样本的训练特征,具体步骤如下:
步骤3.1:基于样本数据由xgboost训练构建n棵梯度提升树,即xgboost模型迭代次数设置为n;
步骤3.2:将每个训练样本在n棵梯度提升树中的位置分别进行1、0编码(又称one-hot编码,其中1用于记录样本位置,0用于表示样本缺省位置),并将生成的n组one-hot编码,作为新特征,并入样本原特征中;
步骤4:基于样本数据的训练特征,训练构建支持向量机(svm)诊断模型;
步骤5:使用诊断模型对新病例进行诊断预测,将新病例判定为圆锥角膜、疑似圆锥角膜、或正常角膜,具体步骤如下:
步骤5.1:对新病例样本数据的各类特征分别进行特征值归一化处理,使其映射到区间[0,1]之间;
步骤5.2:用已构建的极值梯度提升模型(xgboost)对归一化的新病例样本进行特征扩建,即将新样本映射(map)到已构建好的n棵梯度提升树上,记录该样本在n棵梯度提升树上位置,然后采用one-hot编码,对新病例样本进行特征扩建;
步骤5.3:将新病例样本扩建后的特征输入已构建的svm诊断模型,判定其标签为圆锥角膜、疑似圆锥角膜、或正常角膜。
优选地,步骤2所述,对角膜样本数据的各类特征分别进行特征值归一化处理,使其映射到区间[0,1]之间,具体公式如下:
其中,x为原始特征值,xmax为该类别特征最大值,xmin为该类别特征最小值,x*为该特征归一化后的取值。
本发明的优点和有益效果
1、本发明提出的一种基于机器学习诊断圆锥角膜病例的方法,通过分析大量已标注的角膜检测病例样本,提出使用xgboost+svm混合机器学习预测模型,识别圆锥角膜、疑似圆锥角膜、及正常角膜的方法。
2、本发明采用xgboost方法对角膜病例样本的原始特征进行扩充,并进行one-hot编码,获得对样本区分度较高的新特征,提高了样本原始非线性特征的分类性能。
3、试验表明,该方法的诊断效果已满足临床应用。使用该方法对圆锥角膜、尤其是疑似圆锥角膜的筛查,可减少对医学专家诊断的依赖,并基本可以提升诊断效率、准确率。
附图说明
图1为本发明方法的流程图;
图2为极值梯度提升决策树(xgboost)的one-hot编码。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
该方法包括以下步骤:
步骤1:采集眼科病人的角膜检查数据,由眼科专家为每个角膜样本标注一个类别标签(圆锥角膜、疑似圆锥角膜、正常角膜),作为训练样本数据;
步骤2:对角膜样本数据的各类特征分别进行特征值归一化处理,使其映射到区间[0,1]之间,具体公式如下:
其中,x为原始特征值,xmax为此类特征的最大值,xmin为此类特征的最小值,x*为归一化后的值。
步骤3:采用极值梯度提升模型(xgboost)对样本数据进行特征扩建,具体步骤如下:
步骤3.1:通过求解极小化的目标函数obj(1),初始化第一棵分类回归树f1(xi):
其中,xi为第i个训练样本,yi为xi对应的标签值,n样本数量,l为损失函数softmax,ω(f1(xi))为决策树f1(xi)的正则化项。
步骤3.2:通过求解极小化的目标函数obj(t),获得第t棵分类回归树ft(xi):
其中,obj(t)第t轮次的目标函数,ij表示分类回归树的第j个叶子中的样本集合,
步骤3.3:迭代执行步骤3.2共200次,依次获得分类回归树ft(xi),t=2,3,4,...,200,并记录各个样本在每棵树中的节点位置。
其中,构建xgboost分类器涉及到的参数包括:学习率设置为0.1,树的最大深度设置为3,最小叶子节点样本权重和设置为1,节点分裂所需的最小损失函数下降值设置为0,限制每棵树权重改变的最大步长设置为无约束,随机样本抽样比率设置为1,控制树的每一级的每一次分裂,每棵随机采样的列数占比设置为1,数据的度量方法设置为auc,生成伪随机数的种子设置为10。
步骤3.4:将每个训练样本在200棵梯度提升树中的位置分别进行1、0编码(又称one-hot编码,其中1用于记录样本位置,0用于表示样本缺省位置,见图2示例),并将生成的200组one-hot编码作为新特征并入样本原特征中;
示例:假设一条数据x在n=3颗树中的位置如图2所示,那么根据x在树叶子结点的位置(图2中黑色结点),它所构造的新特征为100000010010。
步骤4:基于样本数据的训练特征,训练构建支持向量机(svm)诊断模型,具体步骤如下:
步骤4.1:将原始训练样本划分成3个二分类的训练样本。划分方式以其中一类标签(圆锥角膜、疑似圆锥角膜、正常角膜)为正样本,其他两类为负样本(如:圆锥角膜为正样本,疑似圆锥角膜和正常角膜为负样本);
步骤4.2:以圆锥角膜为正样本,疑似圆锥角膜和正常角膜为负样本训练分类决策函数。求解分离超平面的目标函数:
0≤αi≤c,i=1,2,...,n
其中,x为训练样本特征,y表示正负样本标签,n为样本个数,惩罚参数c=1,i、j为训练样本编号,αi、αj表示拉格朗日乘子,生成伪随机数的种子设置为10。
根据目标函数,求得最优解
f1(x)=ω*·x+b*
步骤4.3:依照步骤4.2,以疑似圆锥角膜为正样本、圆锥角膜和正常角膜为负样本构建决策函数f2(x);
步骤4.4:依照步骤4.2,以正常角膜为正样本、圆锥角膜和疑似圆锥角膜为负样本构建决策函数f3(x);
步骤4.5:输入诊断样本,比较f1(x),f2(x),f3(x)取值大小,将最大取值的类别标签,作为最终预测标签,即f(x)=max[f1(x),f2(x),f3(x)]。
步骤5:使用诊断模型对新病例进行诊断预测,将新病例判定为圆锥角膜、疑似圆锥角膜、或正常角膜,具体步骤如下:
步骤5.1:对新病例样本数据的各类特征分别进行特征值归一化处理,使其映射到区间[0,1]之间;
步骤5.2:用已构建的极值梯度提升模型(xgboost)对归一化的新病例样本进行特征扩建,即将新样本映射(map)到已构建好的200棵梯度提升树上,记录该样本在200棵梯度提升树上位置,然后采用one-hot编码,对新病例样本进行特征扩建;
步骤5.3:将新病例样本扩建后的特征输入已构建的svm诊断模型,判定其标签为圆锥角膜、疑似圆锥角膜、或正常角膜。
下面通过三个具体病例来说明通过本发明方法诊断出的病患的正确性。
以上公开的仅为本发明的几个具体实施例,但是,本发明并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!