基于叫名反应范式的孤独症早期筛查装置的制作方法
本发明涉及语音识别、图像处理领域,尤其涉及到一种基于叫名反应范式的孤独症早期筛查装置,采集叫名者叫名时的音频和被试观测人被叫名时的反应图像数据并加以分析,以评估预测孤独症谱系障碍的装置。
背景技术:
社会对孤独症谱系障碍(autismspectrumdisorder,asd)的关注在过去几年大幅上升,在美国,每68人中就会有1人患上孤独症。虽然现有的asd评估方法非常有效,但却费时费力;并且大多数诊断方法主要是对语言交流障碍、社会交往障碍、重复刻板行为这三方面的测评。叫名反应分析是被广泛运用于筛查孤独症的方法之一。这种方法需要一个临床经验丰富的专业人员操作实验,并根据临床经验大致判断。这不仅需要诊疗人员拥有多年的诊断经验,非量化、非标准化的判断方式也限制了孤独症被早期筛查的准确性。
叫名反应分析,研究了asd个体如何回应被叫名字。这些研究一致认为asd个体与正常生长的小孩相比,在被叫名时经常有不同的行为特征。目前为止,大多数研究都停留在发现统计意义上的规律很少有人将其应用到孤独症的早期筛查上。
基于人工的叫名反应范式在实际应用中的缺点是它对于个体反应时间、回应动作头部角度的测量及其困难。如何系统性的采集实验数据,并使用机器学习方法进行自动化的评价,变成了一个有挑战性的问题。
技术实现要素:
针对上述技术问题,本发明的目的在于提供一种基于叫名反应范式的孤独症早期筛查装置,本发明能够标准化叫名反应数据的采集过程,预测asd的患病风险程度,筛查asd个体,辅助asd诊断,提高asd早期预测的机会。
为实现上述目的,本发明是根据以下技术方案实现的:
一种基于叫名反应范式的孤独症早期筛查装置,其特征在于,包括:
采集模块,用于采集参与工作人员叫名的声音信号,实验人员行为活动的图像信号,参与的实验人员包括患有asd个体与正常个体;
语音识别模块,用于识别和定位进行叫名反应测试时叫名的时间点;
人脸检测标记模块,用于从摄像机的原始数据中提取人脸特征并使用标记点识别技术标记处人脸的五官和轮廓;
人脸鉴别模块,用于从图像数据中鉴别成人脸和儿童脸,并进行区分,将儿童人脸数据被保留用于后续分析;
特征提取模块,从检测到的儿童人脸的图片和标记点数据,提取实验人员的反应延迟时间、反应持续时间、反应头部姿势特征;
预测模块,所述预测模块利用训练数据中已知的asd标签和提取到的特征,训练有监督学习分类器,并对测试数据中提取到的特征进行分类测试,对测试者是否为asd患者进行评估预测。
上述技术方案中,所述反应延迟时间用于提取实验人员的叫名应答延迟时间,根据以下公式计算:
latency=tf-tc1,
其中tf表示摄像机第一次检测到人脸的时间,tc1表示第一声叫名开始的时间。
上述技术方案中,所述反应持续时间用于提取实验人员的叫名应答持续时间,根据以下公式计算:
duration=nf/framerate,
其中,nf表示检测到实验人员人脸的图像帧数,framerate每一秒有多少用于分析的帧数据。
上述技术方案中,所述反应头部姿势特征由n个人脸关键特征点(landmarker)的画面坐标数据,根据以下公式进行计算:
f=[x′1-x′2,…,x′1-x′n,x′2-x′3,…,x′n-1-x′n,
y′1-y′2,…,y1-y′n,y2-y′3,…,y′n-1-y′n]
其中xi,yi是第i个关键点的坐标,xi′和yi′根据以下公式归一化公式计算:
本发明与现有技术相比,具有如下优点:
本发明提出了基于机器学习的框架,从行为外表型特征出发,对被试者被叫名时应答反应的不同模式进行分析,提出来一种预测asd的早期筛查装置。相比于传统的人工叫名范式诊断方法,本发明提出的方法数据更标准化,更有利于判断和分析,且可以自动得到结果。虽然本发明提出的装置并不能完全替代传统的asd诊断方法,但能被视作一个asd评估的辅助早期筛查装置,使得早期的asd评估预测更加准确与方便。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
图1是本发明预测asd装置总框架结构图;
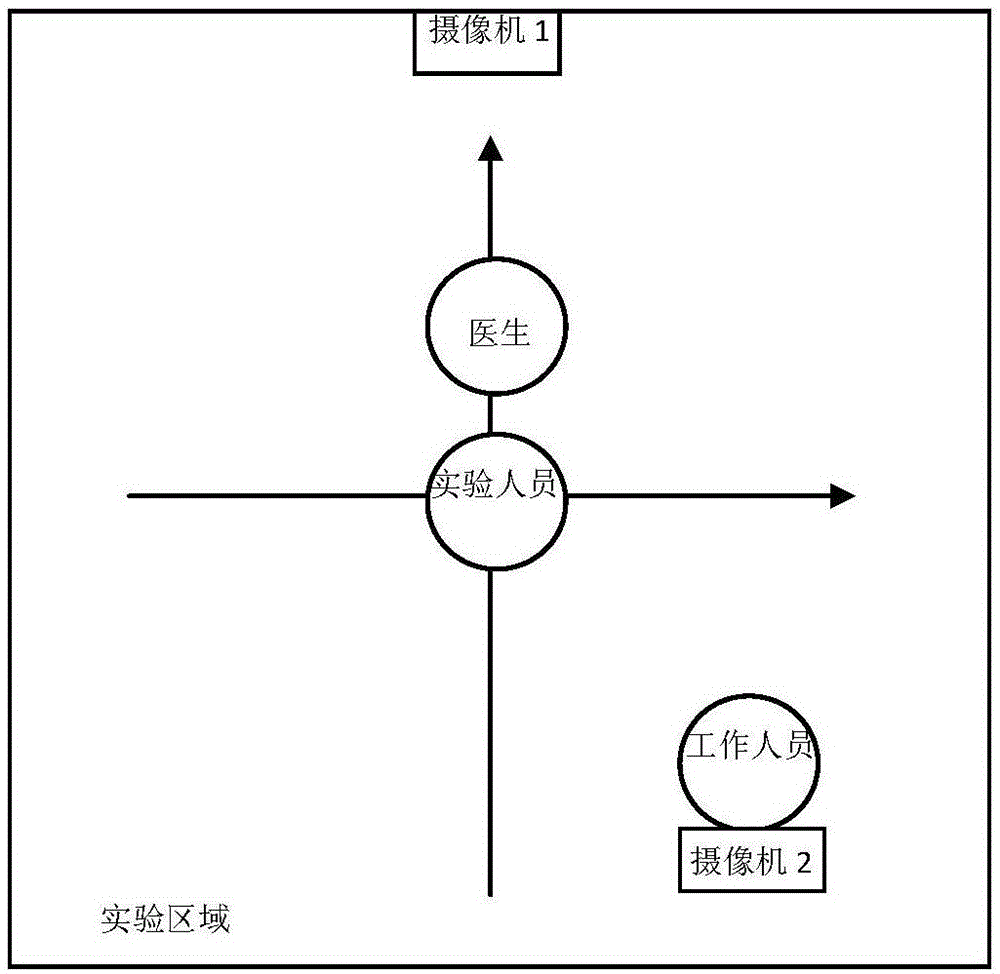
图2本发明中装置使用的过程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
如图1所示,本发明的一种基于叫名反应范式的孤独症早期筛查装置,包括:
采集模块,用于采集参与工作人员叫名的声音信号,实验人员行为活动的图像信号,参与的实验人员包括患有asd个体与正常个体;
在本实施例中,对43人进行实验,其中22人为asd儿童,21人为正常儿童。
语音识别模块,用于识别和定位进行叫名反应测试时叫名的时间点;
具体地,采集实验现场声音信号,得到工作人员第一次叫名的时间点。
人脸检测标记模块,用于从摄像机的原始数据中提取人脸特征并使用标记点识别技术标记处人脸的五官和轮廓;
人脸鉴别模块,用于从图像数据中鉴别成人脸和儿童脸,并进行区分,将儿童人脸数据被保留用于后续分析;非被试儿童的人脸数据被忽略;
特征提取模块,从检测到的儿童人脸的图片和标记点数据,提取实验人员的反应延迟时间、反应持续时间、反应头部姿势特征。
本实施例中,识别实验人员的反应头部姿势特征和图像帧数进行识别实验人员是否作出应答反应及应答的时间点和时间长度。
上述技术方案中,所述反应延迟时间用于提取实验人员的叫名应答延迟时间,根据以下公式计算:
latency=tf-tc1,
其中tf表示摄像机第一次检测到人脸的时间,tc1表示第一声叫名开始的时间。
上述技术方案中,所述反应持续时间用于提取实验人员的叫名应答持续时间,根据以下公式计算:
duration=nf/framerate,
其中,nf表示检测到实验人员人脸的图像帧数,framerate每一秒有多少用于分析的帧数据。
上述技术方案中,所述反应头部姿势特征由n个人脸关键特征点坐标数据,根据以下公式进行计算:
f=[x′1-x′2,…,x′1-x′n,x′2-x′3,…,x′n-1-x′n,
y′1-y′2,…,y1-y′n,y2-y′3,…,y′n-1-y′n]
其中xi,yi是第i个关键点的坐标,xi′和yi′根据以下公式归一化公式计算:
本次实施例中,为了避免过高维度的情况,主成分分析pca被应用于提取信息量最高的若干个维度的数据。
本发明还包括预测模块,所述预测模块利用训练数据中已知的asd标签和提取到的特征,训练有监督学习分类器,并对测试数据中提取到的特征进行分类测试,对测试者是否为asd患者进行评估预测。
具体地,将测试者的数据特征,使用logistic模型进行二分类分析,评估将被结果显示仪器显示为患孤独症的风险值。
本次实施例中,评估结果的混淆矩阵如下表1:
表1
反应延迟时间的准确率为90.7%,加权应答持续时间的准确率为90.7%,叫名反应范式的自动评估装置的准确率为93%。
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!