一种基于机器学习的经皮冠状动脉介入治疗心血管不良事件的预测装置的制作方法
本发明属于医学人工智能领域,具体涉及一种基于机器学习的经皮冠状动脉介入治疗心血管不良事件的预测装置。
背景技术:
随着机器学习在统计学领域取得的巨大发展,基于机器学习方法在医疗数据上也被广泛运用。
在冠心病领域,经皮冠状动脉介入治疗(percutaneouscoronaryintervention,pci)是目前最有效的治疗手段之一。在开通闭塞血管、改善心功能的治疗作用外,pci也常伴随着支架内再狭窄、再发心肌梗死等远期并发症的可能性。预测pci术后的主要心血管不良事件(majoradversecardiovascularevents,mace)也成为了临床研究的一个重要方向。其中,mace主要包括心肌梗死、支架内血栓、卒中、靶病变血运重建、靶血管血运重建和冠状动脉旁路移植(cabg)。
对术后mace事件的危险程度分类不仅有助于评估手术者术后施pci的必要性,亦为患者提供一个了解自身在接受pci后潜在的获益及面临的风险的途径。目前已经发表的预测pci术后死亡、术后mace、术后再入院、死亡和mace复合终点的风险评分都是基于logistics回归模型或cox回归模型。
纵然logistics回归模型或cox回归模型作为线性模型有着应用便捷、危险评分计算简单的优点,但是真实世界中人体各特征参数与其遭遇的临床事件之间关系复杂度必然远超过简单的线性关系。因此用线性模型的简单拟合可能使预测结果最终与实际偏离较大,线性模型对数据挖掘的有限能力也使其无法充分利用到大规模人群数据。
在上述的背景下,机器学习作为学习能力更强的工具比传统线性模型更吸引人的注意。机器学习研究目标在于寻找各种学习算法,以使得计算机从数据中产生模型,从而面对新的数据时提供相应的判断,而选择更具针对性的模型、改善模型对新数据的适应性是提升判断准确度的重要途径。
在数十年的发展过程中机器学习出现了包括线性模型、树模型等各种学习算法,不同的学习算法对于不同预测的适应性各异,而在心血管不良事件的临床研究中尚未有很多的学习算法应用经验。
技术实现要素:
本发明的目的是提供一种基于机器学习的经皮冠状动脉介入治疗心血管不良事件的预测装置。该预测装置中载有训练好的心血管不良事件预测模型,能够在输入的体征数据中筛选出影响mace的重要特征,并且能够基于该些重要特征,更准确地预测得到mace的概率。
为实现上述发明目的,本发明提供以下技术方案:
一种基于机器学习的经皮冠状动脉介入治疗心血管不良事件的预测装置,包括计算机存储器、计算机处理器以及存储在所述计算机存储器中并可在所述计算机处理器上执行的计算机程序,
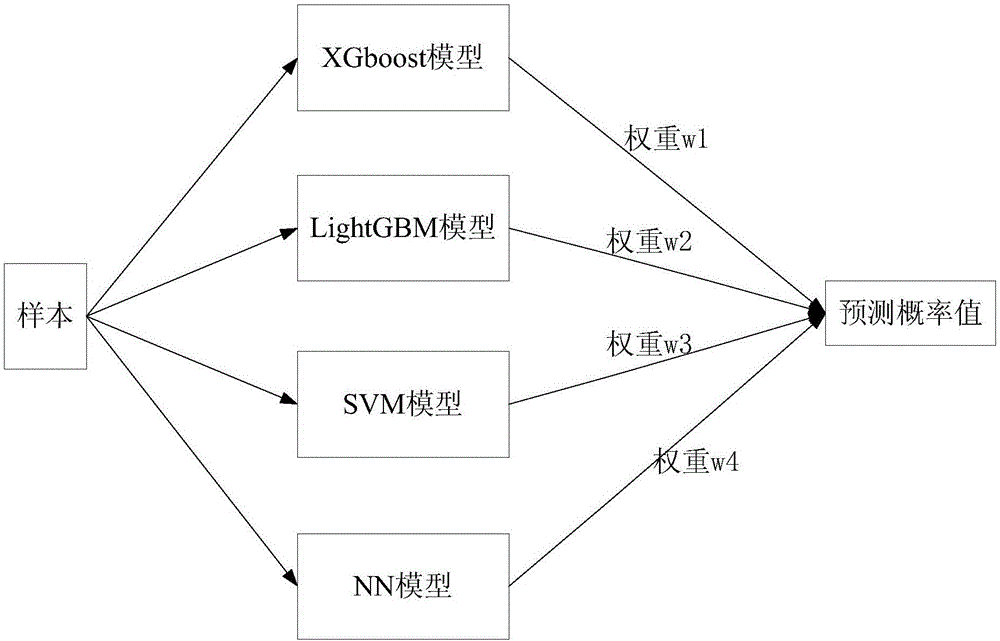
所述计算机存储器中存有心血管不良事件预测模型,其包括训练好的xgboost模型、lightgbm模型、svm模型以及nn模型和每个模型对应的权重值;
所述计算机处理器执行所述计算机程序时实现以下步骤:
接收待测的临床特征数据,并对该进行缺失值填充处理;
对缺失值填充处理后的临床特征数据进行相关性检测,去除具有交叉关系的临床特征数据;
分别利用训练好的xgboost模型、lightgbm模型、svm模型以及nn模型对相关性检测处理后的临床特征数据进行计算,获得4个预测概率;
对4个预测概率进行加权求和,获得利用心血管不良事件预测模型预测的概率值。
该预测装置融合了4个模型具有的优势,以此提高了最终的心血管不良事件的预测概率准确性,该预测概率可以辅助医生进行发生心血管不良事件的预测。
其中,所述心血管不良事件预测模型的获取过程为:
对获取pci手术后的临床特征数据进行缺失值填充和相关性检测处理,获得训练样本,以pci手术后t年为期限,pci手术后t年内发生mace的训练样本标记为0,t年以上发生mace的训练样本标记为1,构建训练集,其中,t取值为1.5~2.5;
预设xgboost模型、lightgbm模型、svm模型以及nn模型的对应权重值;
利用训练集对xgboost模型、lightgbm模型、svm模型以及nn模型进行训练,优化更新模型参数和每个模型对应的权值,以获得心血管不良事件预测模型。
训练时,每个训练样本分别输入到xgboost模型、lightgbm模型、svm模型以及nn模型,获得发生心血管不良事件的4个预测值,4个预测值的加权求和即为发生心血管不良事件的最终预测值,根据该最终预测值与训练样本的交叉熵的大小更新xgboost模型、lightgbm模型、svm模型以及nn模型的参数和每个模型对应的权重值。
具体地,训练时,采用重抽取采样法和交叉验证法训练心血管不良事件预测模型,以此来增加心血管不良事件预测模型训练的均衡性。
优选地,缺失值填充方法包括:
对于连续的临床特征数据,采用平均值填充、中值填充、众数填充、回归填充方法;
对于离散的临床特征数据,对离群数据进行剔除和替换处理。
优选地,xgboost模型、lightgbm模型、svm模型以及nn模型对应的权重值分别为0.323~0.358,0.389~0.492,0.184~0.263,0.102~0.353。
进一步地,xgboost模型、lightgbm模型、svm模型以及nn模型对应的权重值分别为0.32,0.38,0.18和0.12。
再者,模型训练和血管不良事件预测的过程中,
通过计算信息熵获得每个临床特征对发生心血管不良事件的影响重要程度,根据该影响重要程度对临床特征排序。
所述心血管不良事件预测模型在线下训练完成,然后存储在预测装置中;或在线上训练完成,且每次应用时接收的待预测的临床特征数据经处理后作为训练样本,对心血管不良事件预测模型做优化更新。
与现有技术相比,本发明具有的有益效果为:
本发明提供的心血管不良事件预测模型的融合了4中模型的优点,使得发生心血管不良事件的预测概率得到了很大的提高,再者,该心血管不良事件预测模型还能输出影响发生心血管不良事件的临床特征,给临床医生提供了更多参考来预测发生mace的可能性,此外,弥补了机器学习算法在pci介入mace治疗情况下的生存预测的空白。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。
图1是实施例提供的心血管不良事件的预测的流程框图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
本实施例提供了一种基于机器学习的经皮冠状动脉介入治疗心血管不良事件的预测装置,包括计算机存储器、计算机处理器以及存储在所述计算机存储器中并可在所述计算机处理器上执行的计算机程序,所述计算机存储器中存有心血管不良事件预测模型,该预测模型在线上或线下通过以下三个阶段获得:
阶段1:临床特征数据的接收与预处理
临床特征数据来自于某医院心内科在2015年一整年内进行pci治疗的986例患者脱敏数据,具体包括基础信息、入院症状、入院查体、介入指征、既往史、合并用药、心脏超声、生化、血常规、心肌标志物、血糖、甲状腺功能、crp、pro-bnp、性激素、手术信息、靶血管部位、病变特点、靶病变分型、支架情况、球囊及扩张情况、手术过程并发症、抢救记录、术中用药、其他辅助技术、术后timi血流、血运重建出院带药和临床事件发生时间,多个大类方向数据。多个大类方向数据又分为众多独立特征。此外,再根据临床事件发生时间,将全部样本按一定时间阈值t分为2大类,分别记作0和1。即阈值时间内发生mace事件的样本标记为0,阈值时间以上发生mace事件的样本标记为1。
以上所有临床特征数据均进行了严格的脱敏处理,以保证数据安全和不可逆寻。
阶段2:训练样本的构建
针对采集的临床特征数据,首先,将文字信息进行分类编码,转化为结构数据,然后进行缺失值填充和相关性检测处理。
由于临床特征数据分布情况不一样,有些临床特征数据属于连续分布,有些临床特征数据属于离散分布,因此,本实施例根据数据的分布特征分别对临床特征数据进行缺失值填充处理。
具体地,首先对临床特征数据进行异常值检测后,区分连续的临床特征数据和离散的临床特征数据;然后,针对连续的临床特征数据,采用平均值填充、中值填充、众数填充、回归填充等方法对临床特征数据进行缺失值填充处理;针对离散的临床特征数据,对其进行热编码后,离群的临床特征数据进行剔除和替换处理。
本实施例中,连续的临时特征有112个,离散的临床特征有55个。
缺失值填充处理后,对临床特征数据进行相关性检测处理,以去除具有交叉关系的临床特征数据。
在医学上,某几个临床特征是具有相关性的,例如,身高、体重和身体质量指数,知道患者的身高和体重后,即可以知道患者的身体质量指数,则身高、体重和身体质量指数是具有相关性的,进行相关性检测时,将身体质量指数这个临床特征删除。临床特征的相关性可以根据医学知识获得,还可以根据实际经验获得。
对临床特征数据进行缺失值填充和相关性检测处理后,每个患者对应的一组临床特征数据即为一个训练样本。
对于训练样本的标签,根据临床经验,以pci手术后2年为期限,pci手术后2年内发生mace的训练样本标记为0,2年以上发生mace的训练样本标记为1,以此来获得训练样本的标签。
阶段3:心血管不良事件预测模型的构建
心血管不良事件预测模型中,以xgboost模型、lightgbm模型、svm模型以及nn模型这4个单分类器作为基本的预测模型,然后再根据每个模型对应的权重值获得最终预测概率。
xgboost模型是extreme梯度增强算法模型,lightgbm模型是light梯度增强算法模型,xgboost和lightgbm都属于决策树模型,都是根据梯度下降提升决策树(gbdt)改进而来,是目前在工业数据和数据竞赛运用最多的模型之一。svm模型作为传统机器学习模型的代表,其依靠超平面分割思想,在小规模高纬度数据分类上依然有着非常优越的性能。nn(神经网络)模型是最为近年来研究的热点,其依靠仿制人脑神经元的运行方式,在复杂的非线性问题上展现了很高的实用性。这4个模型可以通过不同思想的分类方式更准确的描述数据二分类的关系。融合这4种模型各自的优势可以进一步提升分类精度。
其中,xgboost模型、lightgbm模型、svm模型使用的是常规模型,由各模型开发包直接提供。
nn模型的具体结构共12层,第一层是有120个节点的输入层;第二层是prelu激活层;第三层是dropout层,随机舍去60%的节点;第四层是有48个节点的输入层;第五层是prelu激活层;第六层是标准化层;第七层是dropout层,随机舍去50%的节点;第八层是有24个节点的输入层;第九层是prelu激活层;第十层是标准化层;第十一层是dropout层,随机舍去50%的节点;第十二层是输出节点为2的完全连接层。
为了融合4个模型的优势,本实施例采用加权投票法对4个模型计算的类概率进行加权投票。因此,在4个模型的模型结构确定后,还需要初始化每个模型对应的权重值。
接下来,利用阶段2构建的训练样本对构建的心血管不良事件预测模型进行训练,以确定模型参数和每个模型对应的权重值。
具体地,训练时,每个训练样本分别输入到xgboost模型、lightgbm模型、svm模型以及nn模型,获得发生心血管不良事件的4个预测值,4个预测值的加权求和即为心血管不良事件的最终预测值,根据该最终预测值与训练样本的交叉熵的大小更新xgboost模型、lightgbm模型、svm模型以及nn模型的参数和每个模型对应的权重值。
由于医疗技术的提升,实际上的阈值2年内mace发生率远远小于2年以上mace事件发生率,即整个训练样本存在着分布不均衡状态。故训练时,本实施例采用重抽取采样法,即通过多次抽取同一样本,来训练心血管不良事件预测模型,以此来增加整个模型训练的均衡性。
此外,为了提升整个模型的可靠性,本实施例在模型训练时采用五折交叉验证,即将整个数据集随机划分为五份,其中每次取出一份数据作为验证集,其余四份作为训练,重复训练5次。
经过训练优化,xgboost模型、lightgbm模型、svm模型以及nn模型对应的权重值分别为0.323~0.358,0.389~0.492,0.184~0.263,0.152~0.353。这组权重值,能够大大提高心血管不良事件预测概率的准确性。
在大量的实验研究中发现,当xgboost模型、lightgbm模型、svm模型以及nn模型对应的权重值分别为0.32,0.38,0.18和0.12。训练后的心血管不良事件预测模型的评价指标acc,auc,recall,f1分别能达到0.823、0.741、0.891、0.896。说明该模型能够准确地预测发生血管不良事件的概率。
模型训练过程中,通过计算信息熵获得每个临床特征对发生心血管不良事件的影响重要程度,根据该影响重要程度对临床特征排序。排序靠前的表示对发生心血管不良事件影响较重,该临床特征排序可以帮助医生进行发生心血管不良事件的判断,还可以辅助医生讨论影响发生mace的因子,以挖掘更多影响mace事件的特征。
获得的心血管不良事件预测模型存储在预测装置的存储器中,如图1所示,应用时,接收患者的临床特征数据,并对临床特征数据进行缺失值填充处理后,分别输入到训练好的xgboost模型、lightgbm模型、svm模型以及nn模型对相关性检测处理后的临床特征数据进行计算,获得4个预测概率,然后,对4个预测概率进行加权求和,获得利用心血管不良事件预测模型预测的概率值。
当上述心血管不良事件预测模型在线训练时,每次应用时接收的待预测的临床特征数据经处理后作为训练样本,对心血管不良事件预测模型做优化更新。
心血管不良事件预测模型的融合了4中模型的优点,使得发生心血管不良事件的预测概率得到了很大的提高,此外,该心血管不良事件预测模型还能输出影响发生心血管不良事件的临床特征,给临床医生提供了更多参考来预测发生mace的可能性。
本实施例中的计算机处理器可以为任意型号的处理器,存储器可以为随机存取储器(ram)、只读存储器(rom)、闪存(flashmemory)、先进先出存储器(fifo)以及先进后出存储器(filo)等。
本实施例还进行了对比试验,即将同一个待测样本输入到传统的cox回归模型进行预测,和输入到本实施例提供的预测模型中进行预测,发现本实施例提供的预测模型的预测准确性远远大于cox回归模型。
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!