一种适于多被试fMRI数据分析的快速移不变CPD方法与流程
本发明涉及医学信号处理领域,特别是涉及一种多被试功能磁共振成像fmri(functionalmagneticresonanceimaging)数据的分析方法。
背景技术:
采用磁共振扫描仪对多个被试的大脑进行扫描,获取的脑功能数据称为多被试fmri数据。fmri凭借其无损伤且空间分辨率高等优势,成为了目前脑科学研究的一大重要技术。多被试fmri数据一般看成为一个三维张量,包括空间维、时间维和被试维,可以采用张量分解算法来处理。cpd(canonicalpolyadicdecomposition)是一种典型的张量分解算法。cpd在多被试fmri数据分析中物理意义明确,将多被试fmri数据分解为各被试间共享脑空间激活成分(spatialmap,sm)和共享时间过程成分(timecourse,tc),以及各被试的强度差异信息。这些信息可以为脑功能研究和脑疾病诊断提供重要依据。
多被试fmri数据不可避免地存在着被试间空时差异性。其中时间差异性问题主要是由于各被试响应时间和血液动力学时延方面存在差异导致的。针对该问题,
近几年,大规模的多被试fmri数据(被试数目从几十到上万)的研究越来越受到人们的关注,而且fmri数据的空间维数通常很高,比如5万多个脑内体素,因此当移不变cpd算法应用于多被试fmri数据时,存在着运行速度慢且内存需求高的问题,特别是在被试时延的更新估计过程中,需要存储的数据量比较大。
技术实现要素:
本发明提供了一种适于多被试fmri数据的快速移不变cpd方法,通过矩阵相乘和变换,让被试时延估计速度变快、运行内存降低,且性能不会下降。
在移不变cpd算法的基础上,利用交替最小二乘法对被试共享sm成分、共享tc成分和各被试强度更新估计;在不影响时延估计性能的情况下,将维数高的共享sm成分和原始多被试fmri数据通过矩阵相乘和转换成维数低的数据,从而加快算法运算速度以及降低运算内存。
本发明的技术方案步骤如下:
第一步:输入多被试fmri数据
第二步:初始化。设成分个数为d(d为正整数且0<d≤j)。随机初始化共享sm成分
其中,bd(j-τk,d)表示对bj,d时移了τk,d(为整数)个点,τk,d为第k被试第d个成分的时延。若τk,d>0,第k被试第d个tc成分
第三步:更新共享tc成分b。采用文章“
第四步:对共享sm成分a和x进行降维。对a进行如下运算:
其中
其中
第五步:更新被试时延
第六步:更新共享sm成分a。采用文章“
第七步:更新被试强度c。采用文章“
第八步:计算误差。令iter=iter+1;根据式(1),计算本次迭代误差εiter,以及相对误差δεiter:
δεiter=|(εiter-1-εiter)/εiter-1|。(4)
第九步:若εiter小于预设误差阈值εiter_min,跳转到第十二步,否则执行第十步。
第十步:若δεiter小于预设相对误差阈值δεiter_min,跳转到第十二步,否则执行第十一步。
第十一步:若iter大于预设最大迭代次数itermax,跳转到第十二步,否则执行第三步。
第十二步:输出共享sm成分a、共享tc成分b、被试时延
本发明所达到的效果和益处是,能够快速且有效地对任务态多被试fmri数据的任务相关成分进行估计。在对10被试敲击手指任务的fmri数据分析中,设置相同初始值的情况下,本发明所需的收敛次数跟移不变cpd算法相同,但每次迭代所需运行速度快约9.33倍,而且被试时延估计所需内存约是移不变cpd算法的2/25。本发明和移不变cpd算法估计的共享任务相关成分与先验参考信号的相关系数均值之比约为1,分离性能相似。因此,本发明能快速且有效地提取出多被试共享的脑功能信息,未来可与独立成分分析和稀疏表示等方法相结合,提高分离性能,在今后大规模fmri数据研究和智慧医疗等方面也具有良好的发展前景。
附图说明
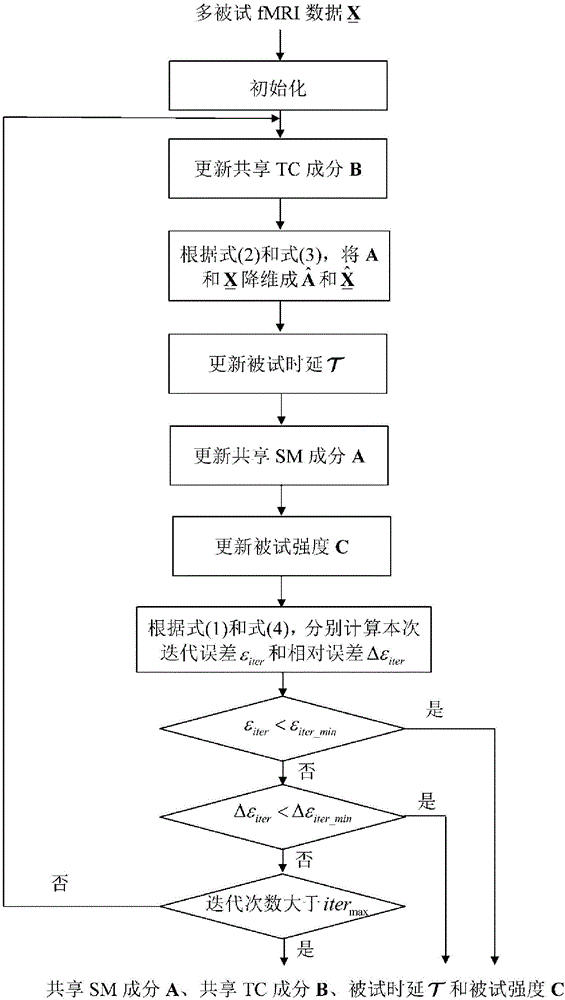
图1是本发明分析多被试fmri数据的工作流程图。
具体实施方式
下面结合技术方案和附图,详细叙述本发明的一个具体实施例。
现有10被试执行敲击手指任务下采集的fmri数据,即k=10。每个被试都进行了j=165次扫描,每次扫描采集了53×63×46的全脑数据,去掉脑外数据体素,保留脑内数据体素i=59610。假设共享sm和tc成分的成分个数d=30,采用本发明进行多被试fmri数据分析的步骤如附图所示。
第一步:输入多被试fmri数据
第二步:初始化。随机初始化共享tc成分
第三步:更新共享tc成分b。采用文章“
第四步:对共享sm成分a和x进行降维。根据式(2)和式(3),将a和x降维成
第五步:更新被试时延
第六步:更新共享sm成分a。采用文章“
第七步:更新被试强度c。采用文章“
第八步:计算误差。令iter=iter+1,根据式(1)和式(4),分别计算本次迭代误差εiter和相对误差δεiter。
第九步:预设误差阈值εiter_min=10-4。若εiter<εiter_min,跳转到第十二步,否则执行第十步。
第十步:预设相对误差阈值δεiter_min=10-6。若δεiter<δεiter_min,跳转到第十二步,否则执行第十一步。
第十一步:预设最大迭代次数itermax=500。若iter>itermax,跳转到第十二步,否则执行第三步。
第十二步:输出共享sm成分a、共享tc成分b、被试时延
- 还没有人留言评论。精彩留言会获得点赞!