一种新的基于元胞自动机的蛋白质进化仿真模型的制作方法
本发明涉及生物信息学、蛋白质结构域和蛋白质进化模拟技术领域,尤其涉及一种新的基于元胞自动机的蛋白质进化仿真模型。
背景技术:
了解蛋白质进化的机理是许多领域的核心,如分子进化、比较基因组学和结构生物学等。确定蛋白质的进化率对于量化选择、遗传漂移以及从基因组数据中计算选择压力(selectiveforces)都是至关重要的。蛋白质进化分析也提供了研究诸如生物形态进化、衰老等问题的独特工具,而且有利于确定重要的功能性位点(例如用于蛋白质的设计)、与人类遗传疾病有关的多肽、药物靶点或蛋白质相互作用网络。
目前,对蛋白质进化机理的研究还局限于简单的生物实验和统计分析,不仅费时费力,而且探究出的规律大多还只停留在假设阶段。随着实验数据的丰富和信息技术的发展,新的智能算法和系统建模方法正成为解决此类问题的有力工具。
近些年来,新提出的研究蛋白质进化的方法大多是基于概率模型。dayhoff等人提出了最具影响力的氨基酸替换模型,这个简单模型假定蛋白质序列中的所有位点在蛋白质进化过程中是相互独立的,每个位点的突变都取决于一个替换概率矩阵。但大多数情况下,“进化过程中蛋白质各位点相互独立”这一假设与事实并不相符,因为在蛋白质内部,任何一个氨基酸残基都与其相邻的氨基酸存在相互作用。yang设计了一个巧妙并易于计算处理的方法,允许氨基酸序列中的不同位点有不同的进化率,这种策略被证明能够更好地符合实际情况,其方法是先根据物化性质将氨基酸分类,使得具有相似性质的氨基酸之间更容易发生替换。lorrainemarsh通过对多个物种血红蛋白的结构信息研究发现,对蛋白质构象稳定性贡献小的氨基酸残基更倾向于发生突变,即蛋白质的结构稳定性对蛋白质的突变具有选择压力,从而可以根据氨基酸序列的结构特性构造蛋白质的进化模型。天津大学王奕蛟等人基于物理学原理,从分维数和动力学因子的角度分析蛋白质进化,得出了一种新的蛋白质进化模型,用于分析物种之间的相似性并预测生物的进化趋势。
元胞自动机(cellularautomata,ca)是一时间和空间都离散的动力系统。ca已应用于许多领域如对砂堆规则、蚂蚁规则、润湿现象等物理生物现象模拟。通过元胞自动机中简单的演化过程可以再现生物高度的复杂性,简单的遗传演化过程可以产生真正的生物形态,使用元胞自动机可以为生物信息学建立新的模型。
国外学者sirakoulis基于元胞自动机设计了一个dna序列演化的模型,在这个一维元胞自动机模型中,元胞有四个状态,分别代表四个碱基a、c、t和g,且用数字分别表示:a→0,c→1,t→2,g→3。元胞邻居定义为最近邻,也就是说一个碱基进化受其左右最靠近的碱基以及其本身决定,演化规则为最左边碱基和最右边碱基的数字加上其本身碱基所代表的数字求和并进行模4计算,最终得到的数字代表其进化后的碱基。这个模型能模拟dna序列的进化,但其缺陷也是非常明显的,其演化规则不具有生物学上的意义,所以其演化后的序列是否与现实中的序列相关也无从得知。
蛋白质结构域是蛋白质中具有特异空间结构和独立功能的区域,是蛋白质发挥生物学效用的关键功能单位。一般每个结构域由100-300氨基酸残基组成,各有独特的空间结构,并承担不同的生物学功能。蛋白质分子中的几个结构域有的相同,有的不同,而不同蛋白质分子中的各结构域也可以相似。现有物种都是从有限的远古物种进化而来,同样现有蛋白质也是从一些简单的蛋白质进化而来。进化过程中通过特定的结构域插入或删除、突变、复制或与其它结构域融合等,产生了具有新的功能或特异性的蛋白质。现有蛋白质进化模型都是基于蛋白质序列中氨基酸的数理统计,模型复杂度高,模拟蛋白质进化困难。由于结构域对蛋白质功能具有重要作用,所以设计出一种新的基于元胞自动机的蛋白质进化仿真模型,演化规则为结构域演化对模拟蛋白质进化研究非常必要。
技术实现要素:
本发明要解决的技术问题是提供一种新的基于元胞自动机的蛋白质进化仿真模型,旨在通过蛋白质结构域的演化,以解决现有蛋白质进化模拟模型模拟出的蛋白质与现实中蛋白质进化相差太远的问题。
为解决以上技术问题,本发明的技术方案是:一种新的基于元胞自动机的蛋白质进化仿真模型,其特征在于包括以下步骤:
(1)使用关键词¢在ncbi数据库中找到属于蛋白质家族¢的所有蛋白质,通过这些蛋白质的id号到uniport数据库中找到蛋白质家族¢的结构域信息,构成进化仿真模型的训练数据集;
(2)通过训练数据集中的数据得到蛋白质家族¢的公共结构域,以及家族¢成员中所有包括的其它结构域,通过蛋白质家族¢的其它结构域在公共结构域后面出现的概率,计算出蛋白质家族¢由前向后进化先验概率表ф和由后向前进化先验概率表э;
(3)元胞自动机模型采用一维元胞自动机,假设蛋白质家族¢共有ξ种结构域,则元胞共有ξ+2个状态,包括ξ种结构域、一个进化终止符号x和一个空结构域;
(4)假设蛋白质家族¢的公共结构域为г+д,则蛋白质家族¢的祖先蛋白质的结构域为г+д,家族中其它蛋白质都是由此祖先进化而来,元胞自动机初始化时在元胞空间中间的两个元胞状态分别定义为г和д,其它元胞的状态为空结构域;在元胞自动机演化过程中,每一次演化改变两个元胞的状态,第一次演化时,根据由前向后进化先验概率表ф和由后向前进化先验概率表э,采用轮盘法分别得出元胞状态д后面的一个元胞状态,和元胞状态г前面一个的元胞状态,得到元胞状态г前面的元胞状态为я,元胞状态д后面的元胞状态为л,则蛋白质在第一次演化后进化为я+г+д+л;第二次演化时,根据由前向后进化先验概率表ф和由后向前进化先验概率表э,采用轮盘法分别得出元胞状态л后面的一个元胞状态,和元胞状态я前面的一个元胞状态,以此类推,当公共结构域为г+д左右两端都演化出进化终止符号x后,演化结束;
(5)元胞自动机模型运行一次,就仿真出一条新的蛋白质序列,蛋白质序列以结构域连接的形式给出。
所述(3)中假如蛋白质家族¢中蛋白质p拥有最多的结构域,其结构域个数为m,则模型中元胞数量必须大于2×m。
由于上述方法是基于现有蛋白质家族数据,将所述方法用于蛋白质进化仿真中,能从祖先蛋白质序列仿真出许多现有的蛋白质,证明了模型的有效性,且此模型也能预测现有蛋白质的进化。
本发明提出的方法与现有对碱基或氨基酸采用插入、删除、复制模拟蛋白质进化相比,具有模型简单、仿真度高的优点,具有广阔的运用前景。
附图说明
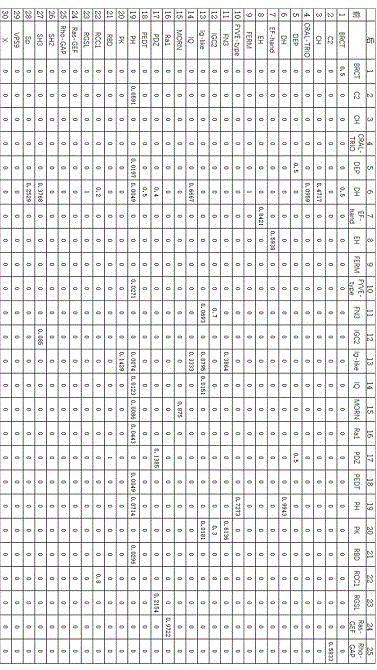
图1实施例中由前向后进化先验概率表ф;
图2实施例中由后向前进化先验概率表э。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,此处例子为仿真人类rhoguaninenucleotideexchangefactors(rhogef)蛋白质家族进化算法。
采用本发明新的基于元胞自动机的蛋白质进化仿真模型,具体步骤如下:
1)使用关键词rhoget在ncbi数据库中找到属于蛋白质家族rhoget的所有蛋白质,再通过关键词human找出所有属于人类rhogef的同源蛋白质,共有1507个蛋白质,通过这些蛋白质的id号到uniport数据库中找到它们的结构域信息,构成进化仿真模型的训练数据集。
2)通过训练数据集中的数据得到人类蛋白质家族rhoget的共有结构域dbihomology(dh)+pleckstrinhomology(ph),在家族成员中含有结构域dh+ph的蛋白质中出现了29种结构域,分别为:breastcancercarboxy-terminal(brct)、c2domain(c2)、calponin-homology(ch)、cral-trio、dishevelled,egl-10,andpleckstrin(dep)、dh、ef-hand(ef)、eps15homology(eh)、fermdomain(ferm)、fyve-typezincfingerdomain(fyve-type)、fibronectintype3domain(fibronectintype-iii)、ig-likec2-typedomain(ig-likec2-type)、immunoglobulin-likedomain(ig-like)、iqcalmodulin-bindingmotif(iq)、membraneoccupationandrecognitionnexus(morn)、n-terminalras-gef、pdzdomain(pdz)、phorbol-ester/dag-typedomains、pleckstrinhomology(ph)、proteinkinasedomain、theras-bindingdomain(rbd)、regulatorofchromosomecondensation(rcc1)、regulatorofgproteinsignalingdomain(rgsl)、rasgefdomain(ras-gef)、rho-gap、srchomology2domain(sh2)、srchomology3domain(sh3)、spectrinrepeat(spectrin)、vacuolarsortingprotein9domain(vps9)。计算出由前向后进化先验概率表ф和由后向前进化先验概率表э,如图1和图2所示,从图1中我们可以看出,在进化过程中,在结构域brct后面插入结构域brct和dh的概率分别是0.5,而其它结构域的概率都是0。在结构域ph后面插入结构域c2的概率是0.05911,插入结构域dep的概率是0.0197,插入结构域dh是0.00493,插入结构域fyve-type是0.0271,插入结构域ig-like是0.0074,插入结构域iq是0.0123,插入结构域morn是0.0086,插入结构域ra1是0.04433,插入结构域pedt是0.0049,插入结构域ph是0.0714,插入结构域rbd是0.0296,插入结构域sh3是0.1835,而插入进化终止符号x是0.5271,其它结构域的概率为0。从由后向前进化先验概率图2可以看出在dh前面插入结构域brct的概率是0.0142,插入结构域ch的概率是0.0355,插入结构域cral-trio的概率是0.099,插入结构域ferm的概率是0.0241,插入结构域iq的概率是0.0142,插入结构域pdz的概率是0.0369,插入结构域pedt的概率是0.0057,插入结构域ph的概率是0.0057,插入结构域rcc1的概率是0.0099,插入结构域rgsl的概率是0.0369,插入结构域sh3的概率是0.1889,插入结构域sp的概率是0.0938,插入x的是0.5241,其他结构域的概率是0。
3)元胞自动机模型采用一维元胞自动机,元胞表示结构域,人类蛋白质家族rhoget共有29种结构域,则元胞共有31个状态,包括29种结构域、一个进化终止符号x和空结构域。人类rhoget蛋白质家族中蛋白质q5vst9拥有最多的结构域,其结构域个数为65,在此元胞自动机模型中元胞数量定义为150。
4)人类蛋白质家族rhoget的公共结构域为dh+ph,则人类蛋白质家族rhoget的祖先蛋白质的结构域为dh+ph,家族中其它蛋白质都是由此祖先进化而来。元胞自动机初始化时(t=0)在元胞空间第75元胞状态定为dh,第76个元胞状态定为ph,其它元胞的状态定为空结构域。在元胞自动机演化过程中,每一次演化改变两个元胞的状态,t=1时,根据由前向后进化先验概率表ф和由后向前进化先验概率表э,采用轮盘法分别得出第76个元胞后面一个元胞的状态,和第75个元胞前面一个元胞的状态。在t=1时,dh状态的前面元胞选中为sp状态,则第74元胞的状态定为sp,ph状态后面的元胞选中为sh3状态,第77个元胞的状态为sh3,其它元胞的状态还是为空结构域状态,蛋白质在t=1时进化为sp+dh+ph+sh3。t=2时,元胞自动机第73个元胞状态进化成ct,而第78个元胞的状态为x,蛋白质进化成ct+sp+dh+ph+sh3+x。t=3时,由于第78个元胞的状态为x,则其后元胞的状态都为空状态,第72个元胞的状态也进化成x,这时蛋白质进化成x+ct+sp+dh+ph+sh3+x,左右都出现进化终止符号x,进化结束,元胞自动机模型完成一次仿真过程。而ct+sp+dh+ph+sh3为蛋白质o15068的结构域形式,此模型完成了从祖先蛋白进化到蛋白质o15068仿真过程。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!