止鼾系统及其控制方法与流程
本发明涉及智能控制技术领域,特别是一种止鼾系统及其控制方法。
背景技术:
打鼾是一种十分普遍的现象,大约有20%~40%的人群患有打鼾症状,打鼾不仅困扰打鼾者、影响同伴,还会对打鼾者造成威胁,有初步证据表明,长期处于鼾声环境中可能会使同伴老年性耳聋,此外,对患者本人而言,打鼾也有较大的危害,上气道结构的强烈颤动可能引起震动创伤,导致咽部组织和临近血管的早起炎症和永久损伤,为了克服上气道增加的阻力,打鼾者需要大大提高吸气肌的作用力,导致最低胸内压可能增加一倍或两倍,过度的胸内负压会增大新肌跨壁压,进而增大心脏负荷,还可能助长胃食管反流。
针对上述情况,目前市面上出现了一些止鼾产品,例如电子止鼾器、挂耳式止鼾器等,这些止鼾产品都是通过监测用户的鼾声,进而做出相应的止鼾操作,提醒用户,进而停止打鼾。但是这些产品都有一些共同的缺点,即有同伴的情况下,这些检测器无法检测到打鼾源,在监测到鼾声即会作出止鼾操作,从而可能导致将没有打鼾的人被吵醒,进而对其睡眠质量产生一定的影响。
技术实现要素:
有鉴于此,本发明的目的在于提供一种止鼾系统及其控制方法,可以提高用户体验。
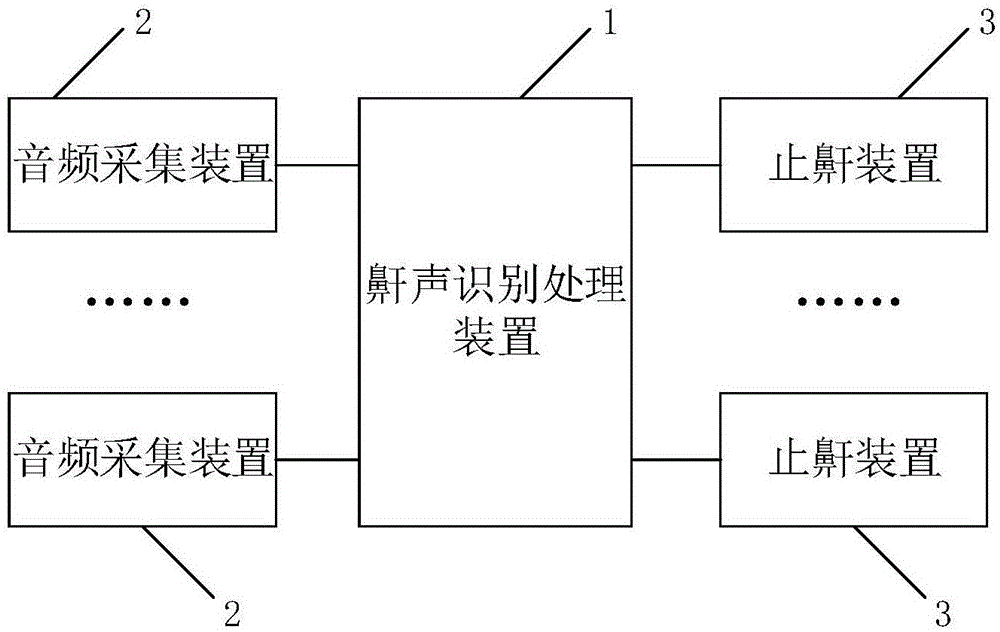
为达到上述目的,本发明的技术方案提供了一种止鼾系统,包括鼾声识别处理装置、多个止鼾装置以及不少于止鼾装置数量的多个音频采集装置,每个所述止鼾装置对应至少一个所述音频采集装置,每个所述止鼾装置与对应的所述音频采集装置的距离小于与任意一个非对应的所述音频采集装置的距离,所述鼾声识别处理装置与所述音频采集装置、所述止鼾装置相连;
所述鼾声识别处理装置用于从每一个所述音频采集装置采集的音频信号中分离得到各鼾声源的鼾声音频信号,以及对于所述分离得到的每一个鼾声源,确定最先采集到其鼾声音频信号的音频采集装置,并控制所述确定的音频采集装置对应的止鼾装置执行止鼾操作。
进一步地,所述鼾声识别处理装置包括:
鼾声增强模块,用于分别对每一个所述音频采集装置采集的音频信号进行音频预处理,以增强其中的鼾声音频信号,抑制其中的背景噪音信号;
鼾声分离模块,用于对经过所述音频预处理得到的音频信号进行音频分离,以将不同声源的音频信号相分离;
鼾声识别模块,用于对经过所述音频分离得到的每一个声源的音频信号进行鼾声识别,以判断是否为鼾声音频信号,并根据鼾声声纹特征识别鼾声源的数量;
控制模块,用于对于每一个鼾声源,确定最先采集到其鼾声音频信号的音频采集装置,并控制对应的止鼾装置执行止鼾操作。
进一步地,所述鼾声识别模块还用于根据每一个鼾声源的鼾声音频信号分析每一个鼾声源的鼾声强弱;
其中,所述控制模块还被配置为根据每一个鼾声源的鼾声强弱控制对应的止鼾装置的止鼾操作程度。
进一步地,所述鼾声增强模块被配置为采用鼾声增强模型对每一个所述音频采集装置采集的音频信号进行音频预处理,所述鼾声增强模型由神经网络模型训练得到。
进一步地,所述鼾声识别模块被配置为采用鼾声识别模型对经过所述音频分离得到的每一个声源的音频信号进行鼾声识别,所述鼾声识别模型由高斯混合模型训练得到。
进一步地,每一个所述止鼾装置包括止鼾枕头以及气泵,所述止鼾枕头的枕芯部位设置有与所述气泵相连的气囊;
其中,通过所述气泵对所述气囊进行充气与放气实现所述止鼾操作。
进一步地,每一个音频采集装置包括一麦克风。
为实现上述目的,本发明的技术方案还提供了一种上述止鼾系统的控制方法,包括:
步骤s1:所述鼾声识别处理装置从每一个音频采集装置采集的音频信号中分离得到来自各鼾声源的鼾声音频信号;
步骤s2:对于所述分离得到的每一个鼾声源,所述鼾声识别处理装置确定最先采集到其鼾声音频信号的音频采集装置,并控制所述确定的音频采集装置对应的止鼾装置执行止鼾操作。
进一步地,步骤s1包括:
所述鼾声识别处理装置对每一个音频采集装置采集的音频信号进行音频预处理,以增强其中的鼾声音频信号,抑制其中的背景噪音信号;
所述鼾声识别处理装置对经过所述音频预处理得到的音频信号进行音频分离,以将来自不同声源的音频信号相分离;
所述鼾声识别处理装置对经过所述音频分离得到的每一个声源的音频信号进行鼾声识别,以判断是否为鼾声音频信号,并根据鼾声声纹特征识别鼾声源的数量。
进一步地,在所述步骤s2之前还包括:所述鼾声识别处理装置根据每一个鼾声源的鼾声音频信号分析每一个鼾声源的鼾声强弱;
其中,所述步骤s2包括:所述鼾声识别处理装置根据每一个鼾声源的鼾声强弱控制对应的止鼾装置的止鼾操作程度。
本发明提供的止鼾系统,可以实现对不同鼾声源的准确识别,进而控制相应的止鼾装置进行止鼾操作,从而可以避免止鼾操作影响到未打鼾的人员,提高用户体验。
附图说明
通过以下参照附图对本发明实施例的描述,本发明的上述以及其它目的、特征和优点将更为清楚,在附图中:
图1是本发明实施例提供的一种止鼾系统的示意图;
图2是本发明实施例提供的一种止鼾系统的控制方法的流程图。
具体实施方式
以下基于实施例对本发明进行描述,但是本发明并不仅仅限于这些实施例。在下文对本发明的细节描述中,详尽描述了一些特定的细节部分,为了避免混淆本发明的实质,公知的方法、过程、流程、元件并没有详细叙述。
此外,本领域普通技术人员应当理解,在此提供的附图都是为了说明的目的,并且附图不一定是按比例绘制的。
除非上下文明确要求,否则整个说明书和权利要求书中的“包括”、“包含”等类似词语应当解释为包含的含义而不是排他或穷举的含义;也就是说,是“包括但不限于”的含义。
在本发明的描述中,需要理解的是,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。
参见图1,图1是本发明实施例提供的一种止鼾系统的示意图,该止鼾系统包括鼾声识别处理装置1、多个止鼾装置3以及不少于止鼾装置数量的多个音频采集装置2,每个所述止鼾装置3对应至少一个所述音频采集装置2(如止鼾装置与音频采集装置一一对应),每个所述止鼾装置3与对应的所述音频采集装置2的距离小于与任意一个非对应的所述音频采集装置2的距离,所述鼾声识别处理装置1与所述音频采集装置2、所述止鼾装置3相连。
所述鼾声识别处理装置1用于从每一个音频采集装置2采集的音频信号中分离得到各鼾声源的鼾声音频信号,以及对于所述分离得到的每一个鼾声源,确定最先采集到其鼾声音频信号的音频采集装置,并控制所述确定的音频采集装置对应的止鼾装置执行止鼾操作。
本发明实施例提供的止鼾系统,可以实现对不同鼾声源的准确识别,进而控制相应的止鼾装置进行止鼾操作,从而可以避免止鼾操作影响到未打鼾的人员,提高用户体验。
例如,在一实施例中,每一个音频采集装置包括一麦克风,每一个止鼾装置包括一止鼾枕头以及气泵,止鼾枕头的枕芯部位设置有与气泵相连的气囊,通过气泵对气囊进行充气与放气实现止鼾操作,另外,每一个麦克风可以设置在对应的止鼾装置的止鼾枕头上,当使用其中一止鼾枕头的用户打鼾时,其上的麦克风能够率先检测到其鼾声音频信号。
例如,在一实施例中,止鼾系统包括鼾声识别处理装置、2个止鼾枕头(即2个止鼾装置),每一个止鼾枕头上设置其对应的麦克风,则该止鼾系统可由两个用户同时使用,当其中一用户打鼾时,由于位置关系,打鼾用户使用的止鼾枕头上的麦克风将率先采集到其鼾声音频信号,该用户的鼾声音频信号将会率先出现在该用户使用的麦克风采集的音频信号中,而另一用户使用的止鼾枕头上的麦克风后采集到该打鼾用户的鼾声音频信号,另外,上述两个麦克风也可以设置在其他位置,如分别设置在床的两侧且靠近枕头的位置,两个麦克风距床中线的距离大体相等。
具体地,在上述实施例中,鼾声识别处理装置分别对两个麦克风采集的音频信号进行处理,以从每一个麦克风采集的音频信号中分离出各鼾声源的鼾声音频信号,并对分离出的鼾声音频信号进行分析处理,根据鼾声声纹特征确定鼾声源的数量(即打鼾的人数),若判断只有一人打鼾,则确定最先采集该鼾声音频信号的麦克风,并控制对应的止鼾枕头执行止鼾操作,若判断两人打鼾,则同时控制两个止鼾枕头执行止鼾操作。
例如,在一实施例中,所述鼾声识别处理装置1可以包括鼾声增强模块、鼾声分离模块、鼾声识别模块以及控制模块。
其中,鼾声增强模块用于分别对每一个音频采集装置采集的音频信号进行音频预处理,以增强其中的鼾声音频信号,抑制其中的背景噪音信号,即通过鼾声增强模块监测音频数据,并对监测到的音频数据进行鼾声增强处理,例如,该鼾声增强模块被配置为采用鼾声增强模型对每一个音频采集装置采集的音频信号进行音频预处理,该鼾声增强模型可由神经网络模型训练得到,具体方式如下:
首先收集不同程度(分为轻、中、重)的鼾声音频数据以及不同的背景音频(如电视声、说话声、音乐声、空调声、风扇声等)数据,之后将鼾声音频与背景声音融合为混合音频作为神经网络模型(如wavnet模型)的输入,对应的纯净的鼾声音频数据作为神经网络模型的输出,利用神经网络模型对上述音频数据进行训练,从而得到鼾声增强模型;
鼾声分离模块用于对经过所述音频预处理得到的音频信号进行音频分离,以将不同声源的音频信号相分离,例如,可以利用鸡尾酒会问题的双麦语音分离方法对预处理后的音频信号进行鼾声语音分离,得到分离后的多段音频,每一段音频为一声源的音频信号;
鼾声识别模块,用于对经过所述音频分离得到的每一个声源的音频信号进行鼾声识别,以判断是否为鼾声音频信号,并根据鼾声声纹特征识别鼾声源的数量,由于不同人的声纹特征不同,因此可以利用鼾声声纹特征识别来自不同鼾声源的鼾声音频信号以及判断不同鼾声音频信号是否来自同一鼾声源,进而确定鼾声源的数量;
控制模块,用于对于每一个鼾声源,确定最先采集到其鼾声音频信号的音频采集装置,并控制对应的止鼾装置执行止鼾操作,具体地,对于每一个音频采集装置,在通过鼾声分离模块、鼾声识别模块将其采集的音频信号相分离得到各鼾声源的鼾声音频信号后,可确定各鼾声音频信号的开始采集时间,之后对于每一个鼾声源,控制模块比较不同音频采集装置采集其鼾声音频信号的开始采集时间,得到开始采集时间最早的音频采集装置,例如,该控制模块可以包括电路控制器,该电路控制器与电源电路、鼾声识别模块连接,电路控制器根据鼾声识别模块的输出控制每一个止鼾枕头的气泵,实现止鼾操作的控制。
优选地,在一实施例中,所述鼾声识别模块还用于根据每一个鼾声源的鼾声音频信号分析每一个鼾声源的鼾声强弱(即鼾声大小)。
其中,所述控制模块还被配置为根据每一个鼾声源的鼾声强弱控制对应的止鼾装置的止鼾操作程度,例如,每一个止鼾装置包括一止鼾枕头以及气泵,通过控制气泵的充气与放气的频率和/或幅度可以控制止鼾操作程度,若鼾声较大,则控制充气与放气的频率和/或幅度较大,若鼾声较小,则控制充气与放气的频率和/或幅度较小。
例如,本发明实施例中的鼾声识别模块被配置为采用鼾声识别模型对经过所述音频分离得到的每一个声源的音频信号进行鼾声识别,所述鼾声识别模型由高斯混合模型训练得到,具体步骤如下:
(1)、收集鼾声数据,建立鼾声数据库,具体地,可以利用音频采集系统采集鼾声音频,另外,由于在目前的音频采集系统采集的音频信号中,其中的高频部分会被抑制,故可以对信号进行预加重处理,得到鼾声数据,即可以采用高通滤波器对信号进行滤波;
(2)、对预加重处理后的音频信号进行分帧处理,即将原信号分割成多个时间较短的信号段,每一段作为一帧;
(3)、对每帧信号进行加窗处理,即将每帧信号乘以一个有限长的窗函数,如矩形窗、三角窗、汉明窗,优选地,可以采用汉明窗;
(4)、利用快速傅里叶变换将时域的鼾声信号转换为信号的功率谱;
(5)、利用离散余弦转换方式去除各维信号之间的相关性,将信号映射到低维空间,得到每帧的mfcc参数;
(6)、采用上述得到的mfcc参数训练鼾声高斯混合模型,得到鼾声识别模型。
本发明实施例提供的止鼾系统,通过鼾声增强模块监测音频,并对监测到的音频数据进行鼾声增强后利用鼾声处理模块进行鼾声分离,再通过鼾声识别模块对分离后的音频分别进行鼾声识别,判断否为鼾声、鼾声源的数量以及鼾声的强弱,进而对相应的止鼾装置发出控制指令,使其做出相应的止鼾操作,进而可以实现对不同鼾声源的准确识别,对打鼾者进行个性化的止鼾操作,避免止鼾操作影响到未打鼾的人员;同时,根据鼾声的强弱程度控制止鼾操作强度,避免止鼾操作强度太弱达不到止鼾效果,止鼾操作强度太强影响打鼾者睡眠质量,从而提高用户体验。
参见图2,图2是本发明实施例提供的一种上述止鼾系统的控制方法的流程图,该方法包括:
步骤s1:所述鼾声识别处理装置从每一个音频采集装置采集的音频信号中分离得到来自各鼾声源的鼾声音频信号;
步骤s2:对于所述分离得到的每一个鼾声源,所述鼾声识别处理装置确定最先采集到其鼾声音频信号的音频采集装置,并控制所述确定的音频采集装置对应的止鼾装置执行止鼾操作。
在一实施例中,步骤s1包括:
所述鼾声识别处理装置对每一个音频采集装置采集的音频信号进行音频预处理,以增强其中的鼾声音频信号,抑制其中的背景噪音信号;
所述鼾声识别处理装置对经过所述音频预处理得到的音频信号进行音频分离,以将来自不同声源的音频信号相分离;
所述鼾声识别处理装置对经过所述音频分离得到的每一个声源的音频信号进行鼾声识别,以判断是否为鼾声音频信号,并根据鼾声声纹特征识别鼾声源的数量。
在一实施例中,在所述步骤s2之前还包括:所述鼾声识别处理装置根据每一个鼾声源的鼾声音频信号分析每一个鼾声源的鼾声强弱;
其中,所述步骤s2包括:所述鼾声识别处理装置根据每一个鼾声源的鼾声强弱控制对应的止鼾装置的止鼾操作程度。
本领域的技术人员容易理解的是,在不冲突的前提下,上述各优选方案可以自由地组合、叠加。
应当理解,上述的实施方式仅是示例性的,而非限制性的,在不偏离本发明的基本原理的情况下,本领域的技术人员可以针对上述细节做出的各种明显的或等同的修改或替换,都将包含于本发明的权利要求范围内。
- 还没有人留言评论。精彩留言会获得点赞!