一种慢性病加重风险评估与告警系统的制作方法
本发明涉及一种评估与告警系统,尤其涉及一种慢性病加重风险评估与告警系统。
背景技术:
随着生活水平的提高,人类的主要死因已经从原来的意外伤害,传染病等逐渐转移到了慢性疾病上,根据世界卫生组织公布的人类死因数据显示,心血管,肿瘤,慢性呼吸道疾病等慢性病所占的比例在近二十多年内急剧增加。慢性病由于其发病周期长,复发性高的特点,给患者和医疗机构带来了巨大的就诊负担,有效的预防手段和早期确诊可以及时进行医疗干预,减轻因病情加重带来的人力和物力损失。因此,如何尽早的确诊慢性病,并对慢性病患者的病情进行预测有十分重要的现实意义。
与此同时,信息技术的飞速发展和向医学领域的扩展,为医学研究提供了新的契机。医学数据的存储方式从原来的纸质病例为主逐渐向电子病例转化,大量的医学数据得以以结构化的格式完整的存储到数据库中,借助计算机强大的数据分析和计算能力,医学研究进入了新的阶段。
慢性病加重风险评估系统的底层任务是通过分析(1)患者的基本统计信息,包括性别,年龄等;(2)对患者一段时间的调查数据,包括日常行为习惯信息,自我评估信息等,以慢性阻塞性肺疾病copd为例,常用的自评测试表包括cat,mrc等;(3)患者所处的环境信息,包括大气污染物,温度,湿度等信息,对患者当前病情做出风险评估,并给出相应的告警信息。目前已有的慢性病加重风险评估方案根据输入的数据类型可分为两类。横截面数据分析:对某一时间点的数据进行建模分析,主要通过回归模型建立各项数据和加重风险之间的关系,此类模型相对简单并且只利用了单时间片的数据,忽略上述三种数据在时间上的延展性和关联性;时序数据分析:对上述某一种数据随时间的变化进行建模,主要通过传统的自回归模型进行建模,包括移动平均模型(ma),自回归模型(ar),自回归移动平均模型(arima)等,此类模型考虑了该类型数据的时序依赖性,但是只能对单一的时序数据建模,风险评估结果的参考价值较低。
随着人工智能技术的发展,基于深度学习的时序数据分析模型逐渐成为了当前时序数据分析的主流技术。利用深度模型强大的特征抽取和分析特性,可以从多维时序数据中抽取有效的高维特征并加以分析和建模。目前较常用的时序深度模型以循环神经网络(rnn)为代表,并在其基础上演变出了各种变形,包括长短期记忆模型(lstm),gru(gatedrecurrentunit)等。深度学习模型的发展为医学数据分析提供了新的思路和解决方案,但是如何有效地结合医学先验知识将深度模型应用到医学领域仍面临巨大的挑战。
技术实现要素:
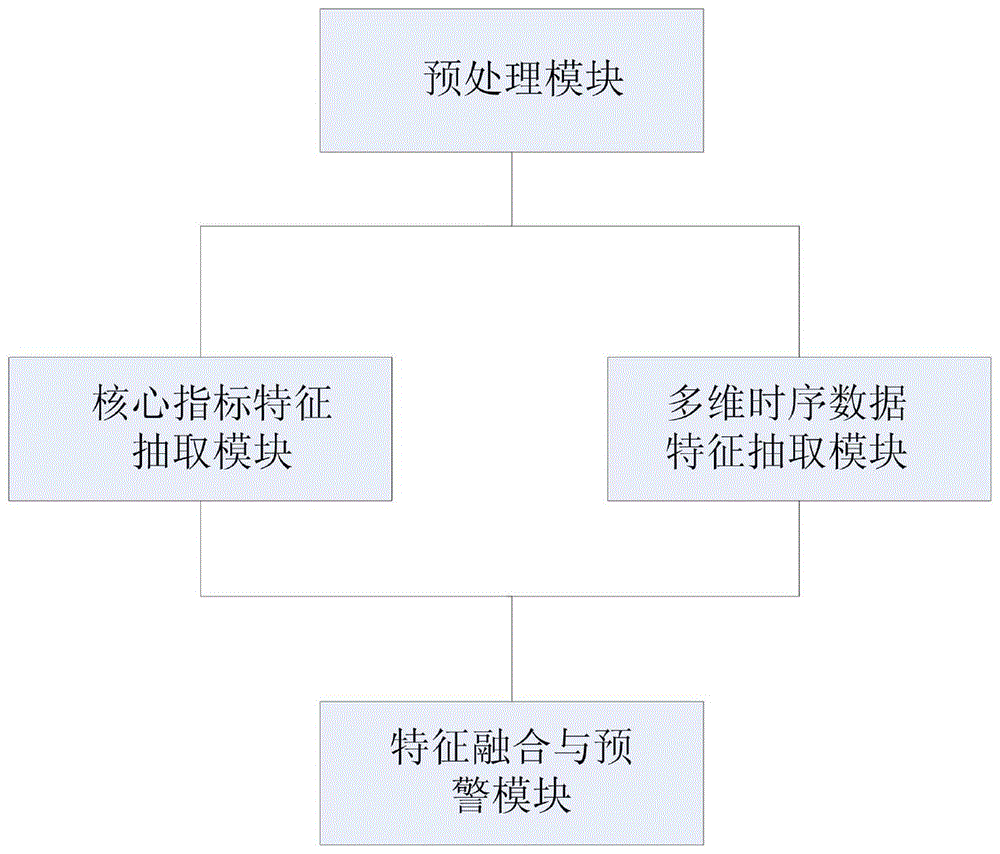
本发明包括预处理模块,核心指标特征抽取模块,多维时序数据特征抽取模块和特征融合与预警模块;所述预处理模块对医学数据进行全面的预处理得到核心指标数据的历史序列和多维特征的历史数据;所述核心指标特征抽取模块建立了所述核心指标数据的历史序列中相邻时间点的时间间隔与长期记忆传递之间的关联,得到第一组基准特征;所述多维时序数据特征抽取模块对所述多维时序数据进行抽取得到第二组基准特征;所述特征融合与预警模块将所述第一组基准特征和第二组基准特征进行融合,然后进行预警分析。
本发明有以下优势:一是结合医学先验知识将复杂的多维时序数据分为两部分:就诊数据核心指标时间序列和其它指标时间序列,将慢性病的核心指标序列抽取出来重点分析;二是将传统的时序数据分析的思路引入到神经网络模型中,并利用不同神经网络模型的特性和优势,对gru模型和cnn模型进行了改造和融合。其中gru模型用于分析核心指标数据,类似于传统时序数据分析中常用的自回归分析,cnn模型用于分析其它多维时序数据,从中抽取有效的特征;三是针对医学调研数据的时序不规律性特征,对gru模型的门结构做了调整和改进,使其可以捕获相邻时序数据之间的时间间隔,以此来调整模型中的相邻时间点之间记忆传递的程度,使之更加符合实际经验。
附图说明
图1为本发明系统的整体框架图;
图2为本发明系统进行慢性病加重预警的整体流程图;
图3为本发明系统中采用的等长可重叠数据切割方案示意图;
图4为本发明系统种改进gru的结构图
图5为本发明系统利用cnn进行多维时序数据特征抽取的结构图;
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图1所示为本发明的整体框架图,包括预处理模块,核心指标特征抽取模块,多维时序数据特征抽取模块和特征融合与预警模块;所述预处理模块对医学数据进行全面的预处理得到核心指标数据的历史序列和多维特征的历史数据;所述核心指标特征抽取模块建立了所述核心指标数据的历史序列中相邻时间点的时间间隔与长期记忆传递之间的关联,得到第一组基准特征;所述多维时序数据特征抽取模块对所述多维时序数据进行抽取得到第二组基准特征;所述特征融合与预警模块将所述第一组基准特征和第二组基准特征进行融合,然后进行预警分析。
本发明针对相关数据的两个特点:(1)多维度时序数据:与慢性病加重风险评估相关的数据包括调查数据和大气环境数据等,均为某一个时间段的连续值;(2)时序间隔不规律:由于患者调研的随机性和时序不规律性,进行医学调研时采集的时序数据往往是非等间隔分布的,而时间间隔的长短对于加重风险评估有重要意义。提出了改进gru模型和卷积神经网络模型相结合的新型慢性病加重风险评估与告警系统。
如图2所示,本发明首先通过预处理模块对医学数据做了全面的数据预处理,并将其分为两部分数据。借鉴传统时序数据预测常用的统计学自回归模型(arima,holt-winters等)的时序预测思想,使用改进的gru模型捕捉长短期依赖的特性来拟合核心指标的历史序列,用于抽取序列的趋势,季节性,周期性等特征;同时,借助cnn较强的局部拟合能力,从其他多维数据中抽取局部特征;最后将两种特征进行拼接,对患者当前的加重风险进行评估,并给出相应的告警信息。
所述预处理模块在数据清洗与标准化模块对医学数据进行全面的预处理,进行数据建模的前置操作。首先对离散数据和类别型数据进行one-hot编码等预处理,将各种调查数据数字化,便于后续输入模型。其次,结合各个统计数据的有效范围,使用95%的置信区间剔除异常值,通过多贝西小波等滤波对数据进行降噪处理;最后,采用临近插值法填补缺失数据,使用max_min归一化函数对数据做标准化处理。上述操作完成后,以等长可重叠切割的方式生成样本集。样本集输入的特征包括两部分,核心指标数据的历史序列和其他多维特征数据序列,并给出对应的样本标签,即要进行风险评估的t时刻的目标值。
如图3为等长可重叠切割方案示意图。等长可重叠切割方案的具体实施过程:假设现有时间长度为n的某时间序列,需要生成长度为k的样本,可重叠切割方案生成样本时从t1时刻开始,切割长度为k的子序列,k+1时刻的目标值为此样本对应的标签,按照步长为1的方式沿时间不断切割,具体如图3所示。图中第一个样本可表示为样本1(t1,t2,...,tk),对应标签为tk+1时刻的目标值,上图样例中一共可以生成n-k个序列长度为k的样本。
通过上述可重叠时序数据的切割方案,得到了样本集,我们将样本形式定义如下:
s={<x,y>,label},以标签为t时刻的目标值的样本为例,st={<xt,yt>,labelt}。其中xt为除核心指标外的其他特征的时间序列,可表示为xt=(x(t-k),x(t-k+1),...,x(t-1)),每个xi为i时刻的特征构成的向量(包括相邻时刻的时间间隔δ(t)),yt=(y(t-k),y(t-k+1),...,y(t-1)),每个y(i)为i时刻的核心指标的值;labelt=y(t),即y(t)为要预测的值。
经典的gru模型在处理时序数据时,默认相邻的时序数据之间的时间间隔是固定的,但是对于医学数据来说,相邻两次调查数据之间的时间间隔往往是不同的,并且间隔的长短对于分析患者的加重风险,捕获时序数据的时间依赖性具有显著的影响,因此,本发明通过改进传统的gru神经网络的内部结构,建立了时间间隔与长期记忆传递之间的关联。
改进后的gru结构如图4所示,图中当前时刻为t,可以看到,改进gru的输入包括三个部分,上一时刻的记忆h(t-1),当前的输入x(t)以及当前时刻t与上一时刻t-1的时间间隔δ(t)。改进gru增加了时间衰减模块,用于捕获时间间隔对于上一时刻记忆衰减的影响,该模块通过引入与δ(t)相关的函数,对上一时刻的记忆进行处理,衰减函数定义式(1)所示:
f(δ(t))=1-tanh(wd·δ(t)+bd)(1)
其中,tanh为激活函数,具体如公式(2),该函数的取值范围为(0,2)。
改进gru的计算过程如下:
首先通过上一时刻的记忆h(t-1)和当前时刻的输入x(t)计算得到重置门的值,如公式(3),然后结合当前输入和重置门以及上一时刻记忆给出下一时刻的预估值
r(t)=σ(wrx(t)+urh(t-1)+br)(3)
z(t)=σ(wzx(t)+uzh(t-1)+bz)(5)
上述公式中所有不同下标的w,u,b均为要训练的参数。
通过预处理步骤得到的另一组数据为多维时序数据。本装置中,多维时序特征的抽取选用了以卷积神经网络为基础的深度学习模型,具体如图5所示。图中,最左侧的方格代表多维的数据输入x,纵轴为数据的维数,横轴为数据的时长,通过不同的卷积核,在时间方向上做卷积操作并激活,得到图中间的特征表示z,z为d个向量,经过池化操作,得到图右侧的输出向量c。计算公式如下:hia=wc*ea+bc(7)
其中“*”表示卷积操作,hia为向量zi的一维,z为z的d个向量中的一个,ea的宽度与卷积核wc一致,卷积核的卷积步长为1。因此共有d个不同的卷积核,得到数据的d个特征向量,这些向量经过激活函数后得到对应的zi:
zi=relu(hi+bz)(8)
其中bz为参数,i∈{1,2,...,d},relu为激活函数。
最后经过均值池化,得到输出c,维数为d。
ci=average(zi),i∈{1,2,...,d}(9)
通过上述步骤得到了就诊数据的两组特征:改进gru得到的向量h(t)与cnn得到的向量c,将两组特征进行拼接,得到融合后的特征,经过全连接层和sigmoid激活函数得到患者目前的加重风险,具体见公式(10):
p=sigmoid(w[h(t);c]+b)(10)
sigmoid函数定义如下,取值范围为(0,1):
该“端到端”的模型的损失函数定义为交叉熵损失函数,如公式(12)所示:
其中li为样本i的标签(加重为1,正常为0),p(·)为公式(8)中定义的风险函数,xi和yi为上文提到的特征。该函数通过梯度下降进行优化。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!