基于脑电图时域数据的精神分裂症辅助诊断分类方法与流程
本发明涉及精神分裂症辅助诊断分类领域,尤其涉及基于脑电图时域数据的精神分裂症辅助诊断分类方法。
背景技术:
精神分裂症是一种易复发、易致残的慢性迁延性疾病,其可能对个人生活和心理健康产生较为严重的影响,在某些特定的情况下甚至可能对其家庭、治安和社会经济造成负担。在这样的情形下,对于精神分裂症的研究与治疗显得尤为重要。
目前,有两种常用的脑电生理技术被广泛应用于精神疾病临床和科研,分别是自发脑电技术和诱发脑电技术。自发脑电技术是指在不施加外部刺激的情形下人类脑部活动时自发产生的生物电位变化,通常包含静息态脑电图(resting-stateeeg)、脑电地形图、多导睡眠图等;而诱发脑电技术是在视觉、听觉等外部任务刺激下产生的有规律的脑部生物电位变化,包括视觉诱发电位(vep)、听觉诱发电位(aep)、p300等,其在精神分裂症的诊断中的作用较多地体现在患者对任务的完成情况分析。两者相比,自发脑电技术在诊断中是一种更新颖的方式,在没有诱导的情况下获得的脑电数据更能代表受试者自主的脑部活动情况,有利于获得受外界干扰较小的脑波特征并进一步探寻疾病发作的病理。
公开号为cn104545939a的专利申请公开了“一种头戴式精神分裂症辅助诊断装置”,通过内置信号发生器触发50对80db声压级(spl)短音的click声刺激受试者,记录仪受试者收到刺激后所诱发的p50波幅以作为精神分裂症辅助诊断。
脑电图数据更加集中于时间序列的脑部变化情况,更加符合思维或行动相关的、基于脑部活动而非脑部静态结构的精神分裂症研究和诊断,因此有理由相信精神疾病各阶段的特征与临床表现的差异可以通过脑电图数据体现出来。综上所述,提出一种基于脑电图时域数据的精神分裂症辅助诊断分类算法是非常有必要的。
技术实现要素:
为实现上述目的,本发明提供了一种基于脑电图时域数据的精神分裂症辅助诊断分类方法,包括以下步骤:
步骤一、利用自发脑电波技术,使用电极帽,获得个体的脑电图时域数据。
步骤二、进行数据预处理工作,包括对原始脑电图时域数据的滤波以及去除伪迹等降噪操作,此外根据卷积神经网络需要的数据输入的特性,对脑电图时域数据做归一化处理以及分段处理。
步骤三、建立精神分裂症辅助诊断模型并对其进行训练,具体方法如下:根据卷积神经网络中应用到的前向传播与反向传播算法,以alexnet为模板搭建基础卷积神经网络,包括卷积层、池化层、激活函数、全连接层、softmax层以及dropout单元,在第一个卷积层之后构建通道权重层,并且用svm分类单元代替最后的全连接层和softmax层;权重层通过学习得到;根据eeg数据分段的特点,在svm分类单元之后加入分类结果投票器,将片段分类结果综合为受试者整体eeg数据分类结果;优化所述精神分裂症辅助诊断模型的网络超参数,利用已得到的脑电波数据样本,样本经过预处理后,将样本输入到所述精神分裂症辅助诊断模型中,网络超参数设置为随机,得到表示预测输入属于各个类别的概率输出结果;
构建损失函数,衡量样本预测分类与已知样本分类的距离,利用随机梯度下降算法,调整网络超参数,尽可能减小损失函数,迭代多次,得到训练好的网络超参数;
步骤四、将经过预处理的数据输入上一步骤中已经训练好网络超参数的精神分裂症辅助诊断模型,得到精神分裂症分类结果。
进一步地,步骤二所述的数据降噪的步骤如下:
(1)首先对于基线漂移干扰应采用高通滤波的方式将处于低频部分的、低于0.5hz的基线漂移信号滤除;
(2)其次对于眼电信号等伪迹干扰,通过fast-ica算法获取64通道独立成分,通过adjust插件探测伪迹干扰并置零,再进一步逆变换回时域信号;
(3)最后对于高幅值的工频干扰同样采用滤波的方法,主要目的是滤去处于50hz的工频干扰,用低通滤波滤去高于49.5hz的频段。
一般将(1)(2)两个步骤结合,直接对时域数据采用线性相位fir数字滤波器滤去低频和高频信号,保留0.5hz-50hz部分数据。
进一步地,步骤二所述的数据分段的步骤如下:
(1)原始数据文件依据不同的类标划分在各文件夹中,首先依照类标顺序提取单个受试者eeg数据;
(2)对每个受试者样本的个体脑电波数据整体归一化,即将所有元素标准化至(0,1)区间之内;
(3)对于时域数据,由于有时间序列的连续性,如果直接按照等比例划分的方式,将有可能将存在物理意义的时间序列脑部生理活动事件信息切断。因此划分eeg时域数据时采用部分交叠的方式,尽量覆盖更多的脑部生理活动连续性事件,同时可以增加训练样本量。于是这一步骤计算对每个受试者需要分段的矩阵尺寸,并且根据交叠度p、数据总列数n、数据切分出的矩阵列数col计算要分出的段数n,如下式所示:
(4)根据求得的段数n划分每个矩阵第一列的索引index,并且根据该索引获取从index到index+col的数据矩阵m;
(5)将矩阵m和对应类标l换算为向量模式添加到类标集s以便于后期的onehot计算。换算的方式为:
根据数据划分步骤,归纳得到eeg时域数据分段算法如下所示:
输入:去噪后的时域eeg数据集d
输出:分段后的eeg数据集d*、对应的类标集s
1:for类标l∈(hc,fes)do
2:设置分段后的数据矩阵行数row、列数col
3:设置样本重叠度p,根据上式
4:for每个受试者样本i∈样本集ldo
5:读取i的数据
6:根据段数n设置要划分的每个矩阵第一列的索引index
7:获取从index到index+col的数据矩阵m
8:对数据矩阵m标准化
9:将m添加到数据集d*
10:将类标l换算成向量模式添加到类标集s
11:endfor
12:endfor
进一步地,步骤三所述算法模型的网络超参数调整步骤如下:
输入:m个样本矩阵x,图像边缘填充大小p,卷积核尺寸a×a,卷积核数目n,卷积核移动步长sc,池化矩形窗尺寸b×b,池化窗移动步长sp,梯度迭代步长η,最大迭代次数n与停止迭代阈值∈.
输出:对于前向传播的分类结果d*、对应的类标集s,以及反向传播各层w、b
1:填充输入样本矩阵的边缘,得到扩大的输入矩阵。随机数初始化各卷积核的w、b
2:for迭代次数i∈[1,n]do
3:for层数l∈[2,l-1]do
4:ifl层为卷积层then
5:滑动卷积核计算卷积值yl=xl-1*wl+bl并计算激活函数zl=f(yl)
6:elseifl层为权重层then
7:滑动卷积核为每个通道乘上权值yl=xl-1*wl+bl
8:elseifl层为池化层then
9:滑动池化矩形窗,通过xl=pool(xl-1)统计最佳值采样
10:elsel层为全连接层
11:采用神经网络全连接计算yl=xl-1*wl+bl
12:endif
13:endfor
14:对于输出层l计算ai,l=softmax(yl),通过损失函数j(w,b,x,y)计算输出层的δi,l
15:for层数l∈(l-1→2)do
16:ifl层为卷积层then
17:δi,l=δi,l+1*r(wl+1)⊙f′(zi,l)
18:elseifl层为池化层then
19:δi,l=u(δi,l+1)⊙f′(zi,l)
20:elsel层为全连接层
21:δi,l=(wl+1)t(δi,l+1)⊙f′(zi,l)
22:endif
23:endfor
24:for层数l∈(2→l-1)do
25:ifl层为卷积层then
26:
27:elsel层为全连接层
28:
29:endif
30:endfor
31:if达到最大迭代次数前w和b的变化小于阈值∈then
32:跳出循环
33:endif
34:endfor
35:输出各层系数矩阵w和偏倚向量b,通过softmax结果给出分类结果进行评估。
进一步地,步骤三所述深度神经网络参数选取参数调节为,实验中的参数包括网络的基础结构、优化算法、损失函数、学习率、批处理尺寸、对每一层卷积层的卷积核数目、卷积核移动步长以及卷积核大小、每一层池化层的池化函数、池化矩形窗大小和移动步长。
其中优化算法采用的是adadelta,激活函数均采用elu函数。
基础cnn网络结构中主要起到影响分类结果作用的是卷积组合数目,卷积层组合即包含一个卷积层、一个激活函数、一个池化层(在卷积层较多时将省略一部分池化层以保持特征图尺寸足够)一个dropout单元的结构组合。卷积组合数目为三层时获得了较好的学习效果。
在此基础上进行卷积核数目选择以及批处理尺寸选择实验,其中较多的卷积核数量指向的是较高的精确度,而批处理尺寸的大小不影响精确度的收敛值。批处理尺寸主要影响了损失值收敛的速度以及gpu发挥效能完成并行计算导致的总时长,对于相同数量的样本批处理迭代相同的次数(在60次迭代时达到提前停止要求),采用卷积核数目为32、批处理尺寸为64作为网络参数效果较好。
基于这样的卷积神经网络架构,将继续研究的是数据输入形式对于实验结果的影响。修改数据重叠度范围和数据段尺寸,如图3所示,对每个实验组取相同的矩阵数目。采用64×100的数据矩阵和20%~40%的交叠分段效果较好。
进一步地,步骤三所述svm为支持向量机,其中使用了高斯核函数,将样本映射到高维特征空间,可以在类标和属性之间关系为非线性的情况下寻找超平面。在训练中考虑到特征空间可能出现离群点,而通过核函数升维的方式完全杜绝离群点的存在往往会导致过拟合,于是在原有的优化目标中添加松弛变量。并以平方铰链损失作为反向传播的损失函数。
进一步地,步骤三所述分类结果投票器为:由于在预处理中执行了对eeg时域数据分段的工作,共分为n个片段,对每一个eeg数据的片段xi将生成一个分类结果向量si。向量si表达的是分类器对于xi处于某个类别的onehot值。每个片段是受试者总数据的一部分,对所有结果等权重投票,即做求和统计,计算得到向量中数字最大的元素,对应的类标作为最终的分类结果,式子如下:
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
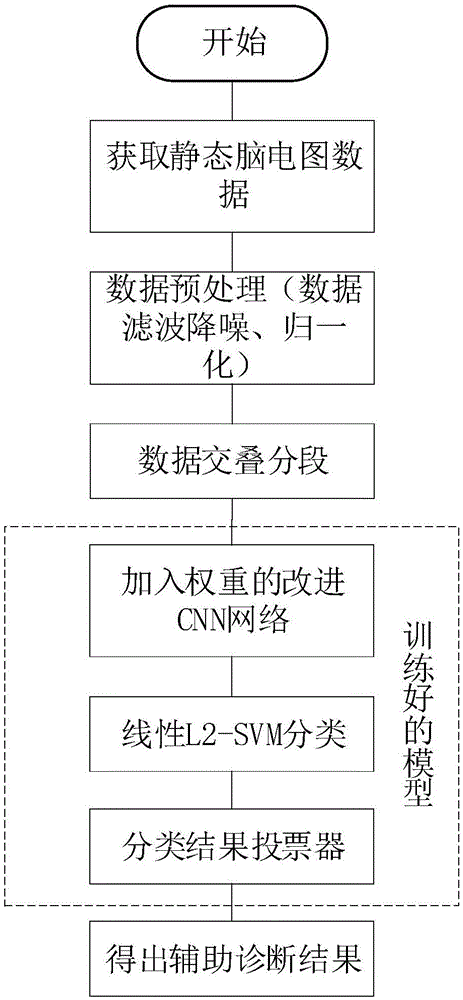
图1是本发明一个较佳实施例的辅助诊断流程图;
图2是本发明一个较佳实施例的脑电图采集导联空间与平面位置分布图;
图3是本发明一个较佳实施例的数据重叠分段示意图;
图4是本发明一个较佳实施例的算法模型前向传播结构示意图;
图5是本发明一个较佳实施例的算法模型可视化示意图;
图6是本发明一个较佳实施例的分类结果输出。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。
参照图1,本发明的精神分裂症辅助诊断分类方法实施具体流程如下:
步骤一:利用自发脑电波技术,脑电图记录设备为国际脑电10-20系统,采用64导脑电图帽,空间示意图与对应的导联名称与位置平面图参照图2,得到个体的脑电图数据,得到的原始数据为64个通道的时序信号数据,采集可用信号300秒,采集频率为1000hz,故可以得到n×t的二维矩阵(n=64,t=300000)。
步骤二:进行数据预处理工作,参照发明内容中的数据预处理过程,包括对原始时域eeg数据的滤波以及去除伪迹等降噪操作,根据卷积神经网络需要的数据输入的特性,对eeg数据做归一化处理,并且为了尽量覆盖更多的脑部生理活动连续性事件,对数据做交叠分段处理,参照图3;
步骤三:将预处理好的数据输入利用已得到的脑电波数据样本训练好的算法模型。
参照图4,本发明的算法模型如下:
根据卷积神经网络中应用到的的前向传播与反向传播算法,以alexnet为模板搭建基础cnn,包括卷积层、池化层、激活函数、全连接层、softmax层以及dropout单元,在第一个卷积层之后构建通道权重层,并且用svm分类单元代替最后的全连接层和softmax层,在svm分类单元之后加入分类结果投票器。可视化算法模型结构如图5所示。
利用已得到的脑电波数据样本,样本经过预处理后,将样本输入到所构建的模型中,参数设置为随机,得到表示预测输入属于各个类别的概率输出结果。构建损失函数,衡量样本预测分类与已知样本分类的距离,利用随机梯度下降算法,调整网络超参数,尽可能减小损失函数,迭代多次,保存此模型的网络超参数;
本发明实现的分类算法模型参数设置使用结合的深度学习框架进行各项参数设定:
在深度神经网络参数选取参数调节部分中,实验中的参数包括网络的基础结构、优化算法、损失函数、学习率、批处理尺寸、对每一层卷积层的卷积核数目、卷积核移动步长以及卷积核大小、每一层池化层的池化函数、池化矩形窗大小和移动步长。
算法模型选取基础cnn网络结构,其中主要起到影响分类结果作用的是卷积组合数目,卷积层组合即包含一个卷积层、一个激活函数、一个池化层(在卷积层较多时将省略一部分池化层以保持特征图尺寸足够)一个dropout单元的结构组合。卷积组合数目为三层时获得了较好的学习效果。
其中优化算法采用的是adadelta,激活函数均采用elu函数,以平方铰链损失作为反向传播的损失函数,由于adadelta可以达到自适应的学习率调整,因此省去学习率的调整。
基础cnn网络结构中的卷积核数目选择以及批处理尺寸选择,其中较多的卷积核数量指向的是较高的精确度,而批处理尺寸的大小不影响精确度的收敛值。批处理尺寸主要影响了损失值收敛的速度以及gpu发挥效能完成并行计算导致的总时长,对于相同数量的样本批处理迭代相同的次数(在60次迭代时达到提前停止要求),采用卷积核数目为32、批处理尺寸为64作为网络参数效果较好。
基于这样的卷积神经网络架构,将继续研究的是数据输入形式对于实验结果的影响。修改数据重叠度范围和数据段尺寸,对每个实验组取相同的矩阵数目。采用64×100的数据矩阵和20%~40%的交叠分段效果较好。
步骤四:参照图6,通过比较判断为首次发作阶段和判断为健康状态的概率百分比,得到精神分裂症分类结果辅助诊断。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!