一种k-means聚类糖尿病预警模型的改进方法与流程
本发明涉及医疗信息化技术领域,一种糖尿病预警模型建立方法,从糖尿病患病预警的需求出发,改进k-means聚类方法,建立糖尿病分段函数,具体涉及一种k-means聚类糖尿病预警模型的改进方法。
背景技术:
随着糖尿病患者数量逐年增加、糖尿病并发症越来越多样化,这给糖尿病患者的诊断和治疗带来了巨大挑战。
现有的医院信息系统虽有大量糖尿病诊断病例样本,却也只是单纯地做病例存储和简单的统计分析,并没有进一步挖掘其中的规律和知识,因此糖尿病诊断样本利用率较低;同时,已有糖尿病数据集仅有双标签,没有对未患病数据进行标记,难以实现健康人群的预警。
因此,迫切需要开展糖尿病预警模型研究,提高糖尿病的预防和治疗效果,提升人们的健康水平。
现有技术:
非专利文献[1]:刘荣凯,孙忠林.针对k-means初始聚类中心优化的pca-tdkm算法[j].软件导刊,2018,17(09):85-87.提出了pcatdkm算法在传统的kmeans算法中增加了pca、td与最大最小距离算法。pca算法能够对数据对象集合进行降维,加速聚类过程。td算法能够在选择初始聚类中心时根据数据对象的实际分布情况进行动态选择,使得通过聚类算法得到的初始k个聚类中心与实际聚类相对应。
非专利文献[2]:yuanql,shihb,zhouxf.anoptimizedinitializationcenterk-meansclusteringalgorithmbasedondensity[c]//ieeeinternationalconferenceoncybertechnologyinautomation,control,andintelligentsystems(cyber),shenyang,ieee,2015:790-794.提出了一种优化k均值初始中心点的方法.该算法利用密度敏感的相似性度量来计算物体的密度.通过计算该点与其他密度较高的点之间的最小距离,选出候选点。然后,结合平均密度,筛选出离群点。最后筛选出k-均值算法的初始中心.实验结果表明,该算法获得的初始中心点精度高,能够有效地滤除异常。
技术实现要素:
本发明的目的是在于提供一种k-means聚类糖尿病预警模型的改进方法,针对k-means聚类算法随机选择初始聚类中心导致聚类结果不稳定的问题,提出初始聚类中心优化的改进k-means算法,并结合糖尿病分段函数,提出k-means聚类糖尿病预警模型的改进方法。
为实现上述发明的目的,本发明采取的技术方案如下:
一种k-means聚类糖尿病预警模型的改进方法,包括如下步骤:
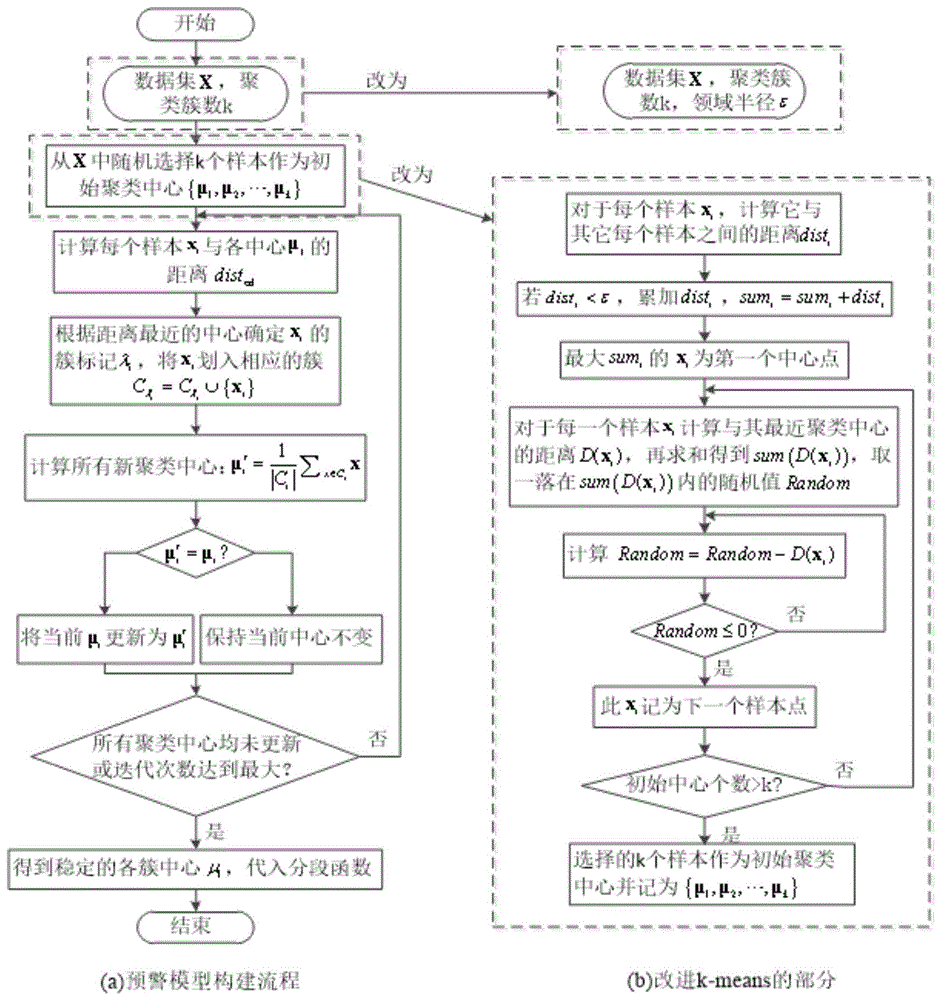
步骤1,第一个聚类中心点选择,选定数据集,定义聚类簇数k、领域半径ε,选择样本点xi与样本之间距离之和最大的点作为第一个聚类中心点;
步骤2,选择新的聚类中心,计算每个样本点与其最近聚类中心的距离之和sum(d(x)),在sum(d(x))内取一个随机值random,计算random-=d(x),直到random≤0,选择得到新的聚类中心;
步骤3,遍历操作,重复上一步骤直至得到所需k个中心点,记为{μj,j=1,...,k};
步骤4,簇标记,计算每个样本与聚类中心的距离,根据其距离最近确定样本的簇标记,并将样本划入相应的簇;
步骤5,更新操作,更新所有聚类中心点;
步骤6,糖尿病预警模型,得到稳定的各簇中心,代入糖尿病分段函数,得到糖尿病的预警模型。
进一步的,所述步骤1中第一个聚类中心点的选择,因为现有k-means算法采用随机选取初始聚类中心,易导致聚类结果不稳定,因此需对初始聚类中心的选择进行改进,使其尽可能地落在各簇类的中心部位,这里定义聚类簇数k、领域半径ε,计算每一个点与第一个聚类中心点的距离dist(x),选取dist(x)较大的点作为新的聚类中心,即对每一个dist(x)求和得到:sumi=sumi+disti
式中,i是聚类中心个数。
最大的sum(dist(x))为的第一个聚类中心点,即:sum_max=max(sumi)。
进一步的,所述步骤2、步骤3中选择得到新的聚类中心,所述计算每一个点与第一个聚类中心点的距离为dist(x),选取dist(x)较大的点作为新的聚类中心,即对每一个dist(x)求和得到sum(dist(x)),取一个在sum(dist(x))内的随机值random,重复通过公式计算,所述公式为:random=random-dist(x)
直至random≤0,则该点为下一个聚类中心点,保证距离较大的dist(x)被较大概率选中,并将所需k个中心点,记为{μj,j=1,...,k}。
进一步的,所述步骤4中标记样本簇,是计算每个样本xi与聚类中心{μj,j=1,...,k}的距离distod,根据其距离最近确定样本xi的簇标记λi,并将样本xi划入相应的簇:
进一步的,所述步骤5更新所有聚类中心点,是计算所有新的聚类中心,其公式为:
进一步的,所述步骤5构建糖尿病预警模型,是根据步骤1到步骤5得到稳定的各簇中心,代入糖尿病分段函数,得到糖尿病的预警模型,糖尿病预警分段函数为:
其中,μi(i=1,2,3)为第i个聚类中心,这里0、1、2分别代表健康、i级预警和ii级预警,可以利用该预警模型来预测是否患糖尿病及糖尿病所处阶段。
本发明相对于现有技术的有益效果是:
采用改进k-means聚类算法有效克服了聚类结果不稳定的问题,结合改进k-means聚类算法和糖尿病分段函数相结合,建立了k-means聚类糖尿病预警模型的改进方法,提高了糖尿病预警能力,为糖尿病不同阶段的诊断和治疗提供了依据。
本发明附加技术特征所具有的有益效果将在本说明书具体实施方式部分进行说明。
附图说明
图1是本发明实施例中k-means聚类糖尿病预警模型的改进方法算法流程图;
图2是本发明实施例中不同算法在新糖尿病数据集上平均收敛速度对比的线型图;图3是本发明实施例中不同算法在新糖尿病数据集上多次聚类结果平均ari对比的线型图。
具体实施方式
结合图1,首先采用pima糖尿病数据集,因为现有k-means算法采用随机选取初始聚类中心,易导致聚类结果不稳定,因此需对初始聚类中心的选择进行改进,使其尽可能地落在各簇类的中心部位,这里定义聚类簇数k、领域半径ε,计算每一个点与第一个聚类中心点的距离dist(x),选取dist(x)较大的点作为新的聚类中心,即对每一个dist(x)求和得到:sumi=sumi+distii为聚类中心个数。
最大的sum(dist(x))为的第一个聚类中心点,即:sum_max=max(sumi)
选择新的聚类中心,计算每一个点与第一个聚类中心点的距离为dist(x),选取dist(x)较大的点作为新的聚类中心,即对每一个dist(x)求和得到sum(dist(x)),取一个在sum(dist(x))内的随机值random,重复通过公式计算,所述公式为:random=random-dist(x)
直至random≤0,则该点为下一个聚类中心点,保证距离较大的dist(x)被较大概率选中,并将所需k个中心点,记为{μj,j=1,...,k}。
标记样本簇,是计算每个样本xi与聚类中心{μj,j=1,...,k}的距离distod,根据其距离最近确定样本xi的簇标记λi,并将样本xi划入相应的簇:
更新所有聚类中心点,是计算所有新的聚类中心,其公式为:
构建糖尿病预警模型,是根据上述步骤得到稳定的各簇中心,代入糖尿病分段函数,得到糖尿病的预警模型,糖尿病预警分段函数为:
其中,μi(i=1,2,3)为第i个聚类中心,0表示健康、1表示i级预警、2表示ii级预警,利用该预警模型来预测是否患糖尿病及糖尿病所处阶段。
具体地,将对本发明提出改进k-means聚类糖尿病预警模型的改进方法与标准k-means聚类、背景技术提及的非专利文献[1]、非专利文献[2]等方法进行对比,以同质性、完整性、fmi、ari均值、chi、平均收敛速度、平均收敛次数和算法时间等为评判指标,通过这些指标及曲线对比分析,进一步验证本发明提出模型的有效性。
结合图1,指出如何修改标准的k-means聚类算法,采用pima糖尿病数据集,选用240例数据作为实验样本,其中训练集200例,测试集40例;使用python对算法进行编程,设计了不同算法的对比分析。
表1为标准k-means、改进k-means、文献[1]、文献[2]、agglomerative等5种算法在糖尿病数据集上运行300次得到的ari均值,从表1可以看出,使用改进k-means算法、文献[1]算法和文献[2]算法得到模型的ari均值均明显高于使用标准k-means算法的,其中本文的改进k-means和文献[2]算法都结合了密度的思想,得到的模型ari值要好于文献[1]算法的。但无论是标准k-means算法还是改进k-means算法,得到模型的表现都不如基于密度的聚类算法agglomerative算法,这是由于基于密度的agglomerative算法初始聚类中心在密度可达距离参数确定后,聚类结果很稳定,但是其实在处理高维数据时,由于算法本身的特点,没有k-means算法的扩展性好。
表1不同算法在新糖尿病数据集上的ari均值
表2为标准k-means、改进k-means、文献[1]、文献[2]、agglomerative等5种算法在新糖尿病数据集上在同质性、完整性、fmi、ari均值、chi等5个指标上的均值。从表2可以看出,本发明得到的模型在5种指标上的表现均好于使用标准的k-means算法,同时也好于使用文献[1]算法和agglomerative算法得到的模型,略好于使用文献[2]算法得到的模型。可以发现在ari和chi使用另外4种算法的模型都较明显的好于使用标准k-menas算法的模型,但在同质性、完整性和fmi上5种算法的模型表现相差不大,这是因为这三种指标主要用来衡量聚类结果的准确率,可以看出使用标准k-means算法的模型在训练集上准确率并不是很差,但是由于算法的不稳定导致得到的模型分布较差,意味着模型的泛化性能较差。
表2不同算法的模型在新糖尿病数据集上在5个指标上的均值
结合图2,这里以一次聚类的ari作为纵坐标,一次聚类中算法的迭代次数为纵坐标,运行300次求得一次聚类的迭代次数均值和ari均值。可看出,本发明算法、文献[1]算法、文献[2]算法在开始迭代时ari值更高,由于改进了初始中心选取方法,得到的初始聚类中心更准确,可知本发明算法、文献[1]和文献[2]算法一次聚类中迭代次数明显更少,其中本发明算法次数最少。
表3是标准k-means、改进k-means、文献[1]、文献[2]等4种算法得到模型的平均收敛次数和算法时间,可以看出使用标准k-means算法迭代次数基本上是其他改进算法的两倍。不过从平均一次的算法时间可以看出使用标准k-means算法求解模型时间并不是最长,文献[1]和[2]算法时间都超过它,这是由于文献[1]和[2]加了过多的数学计算,虽然减少了迭代次数,但是一次聚类算法时间却更长,本发明算法虽然也加了密度计算,但只是计算了一次,更多的是结合了概率的思想,不需重复计算整个数据集矩阵。
表3不同算法在新糖尿病数据集上平均收敛次数和算法时间
结合图3,纵坐标ari值是5种数据集的每次结果ari的均值,横坐标为聚类次数。从图3可以看出,agglomerative算法因为算法本身特点,每次聚类结果是一样的,所以是一条直线;标准k-means算法求得的模型结果上下波动剧烈,本发明算法和文献[2]算法求得的模型结果都表现较好;通过计算曲线的方差得知,本发明算法为3.19*10-5,文献[2]算法的为6.68*10-5,文献[1]算法的为2.94*10-4,而标准k-means算法的为2.78*10-3,可见本发明算法得到的模型最为稳定,文献[2]算法次之,而标准k-means算法得到的模型最不稳定。
综上,本发明算法、文献[1]算法、文献[2]算法和agglomerative算法得到的模型指标均优于标准k-means算法;本发明算法收敛情况和算法时间最好,文献[1]
和文献[2]虽然收敛情况优于标准k-means算法,但算法时间要更长;本发明算法、文献[1]算法、文献[2]算法得到的模型比标准k-means算法更稳定,其中本发明算法得到的模型最为稳定。
基于此,本发明将改进k-means聚类算法和糖尿病分段函数相结合,发明了一种k-means聚类糖尿病预警模型的改进方法,克服了k-means算法聚类结果不稳定的问题,提高了预警模型的准确性和稳定性。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!