一种电子听诊器的实时心肺音自动分离方法与流程
本发明属于听诊器技术领域,涉及到一种电子听诊器的实时心肺音自动分离方法。
背景技术:
对于听诊器信号的心肺音分离,目前已公开的专利申请或者已发表的论文主要从三个方向解决该问题:(1)利用多路听诊以及盲信号分离算法分离心肺音;(2)通过简单的滤波处理“分离”心音和肺音;(3)通过对短时傅里叶变换结果作非负矩阵分解并聚类来分离出心音通道和肺音通道。具体包括:
(1)多路听诊+盲信号分离方式
发明专利申请“一种基于fpga的心肺音分离多路听诊器”(公开号cn107174277a)采用多路采集的方式,将采集探头置于使用者的不同部位,对采集回来的多路混合声音信号进行分析比较,根据信号间的共同性和差异性,采用盲信号分离算法对信号进行处理,从而分离出心音信号以及肺音信号。该方法需要多个同步的听诊通道放置于使用者不同部位,与传统的听诊器形态大不相同,使用起来有诸多不便。
(2)简单的滤波处理方式
发明专利申请“便携可视化心、肺音可分离的蓝牙电子听诊器”(公开号cn101766493a)利用包括截止频率为30hz的高通滤波器电路、截止频率为100hz的高通滤波器电路、截止频率为500hz的低通滤波器电路和截止频率为1000hz的低通滤波器电路在内的有源滤波器电路,通过滤波的方法得到心音与肺音信号。但由于心音与肺音信号在60-320hz频率范围内的叠加,通过这种滤波器滤波的简单方法无法完全分离两部分信号,导致最终分离结果中的心音掺杂了大量肺音,肺音中掺杂了大量心音。
发明专利申请“数字听诊器与滤除心音提取肺音的方法”(公开号cn106022258a)对得到的肺音帧进行小波变换,利用阀值滤除小波系数,滤掉心音,得到纯净肺音帧。由于心音和肺音信号在小波域上并非是严格可分的,因此该小波域上的滤波方法同样不能很好地分离心音和肺音信号。
(3)非负矩阵分解并聚类的方式
目前已有很多论文或者专利申请通过对短时傅里叶变换结果作非负矩阵分解并聚类来分离出心音和肺音信号。
ghafoorshah等人发表的论文“ontheblindrecoveryofcardiacandrespiratorysounds”首次提出了基于该思想的心肺音分离方法;f.j.canadas-quesada等人发表的论文“anon-negativematrixfactorizationapproachbasedonspectro-temporalclusteringtoextractheartsounds”在此基础上增加了一个稀疏正则化项来提高分离性能。除此之外,专利申请“一种基于非负矩阵分解的心肺音分离的方法及装置”(公开号cn107463956a)、“一种单通道心肺音分离方法及系统”(公开号cn107837091a)、“一种基于自回归正则化nmf的心肺音分离方法及系统”(公开号cn108133200a)、“一种心肺音信号的分离方法、装置、设备及存储介质”(公开号cn108764184a)、“一种人体心肺音实时盲分离方法及系统”(公开号cn107392149a)同样利用该思想进行心肺音分离。
该方法要奏效需要较长的数据采集时长(典型的批处理长度为3.2秒),因此实时性较差,而对于一个实时输出心音或肺音信号的电子听诊器而言,信号处理后的输出时延应尽可能地小。
同时,由于多路听诊+盲分离方法使得听诊器使用过于复杂,因此现有技术的绝大部分方案都是通过单通道的方式采集心肺音并探索单通道听诊器的心肺音分离方法,其存在的缺点在于:
(1)简单滤波后直接输出会使最终输出心音、肺音仍有部分重叠,无法很好地将两者分离开;
(2)基于非负矩阵分解的心肺音分离方法所需的数据批处理长度较长,实时性很难满足要求;
(3)在心肺音这一特殊的时间序列信号中,相邻的心音周期中的心音信号往往具备类似的特征,该重要特点未被现有技术很好地利用;
(4)当呼吸道出现病变导致听诊信号出现附加呼吸音(如湿啰音、喘鸣音等)时,现有技术不能很好地在最终的肺音输出结果中保留这些特异性的附加呼吸音。
技术实现要素:
本发明的目的在于提供的一种电子听诊器的实时心肺音自动分离方法,解决了现有技术中存在的信号分离实时性差、心肺音分离难以及分离肺音中无法保留因病变导致的附加呼吸音的问题。
本发明的目的可以通过以下技术方案实现:
一种电子听诊器的实时心肺音自动分离方法,包括以下步骤:
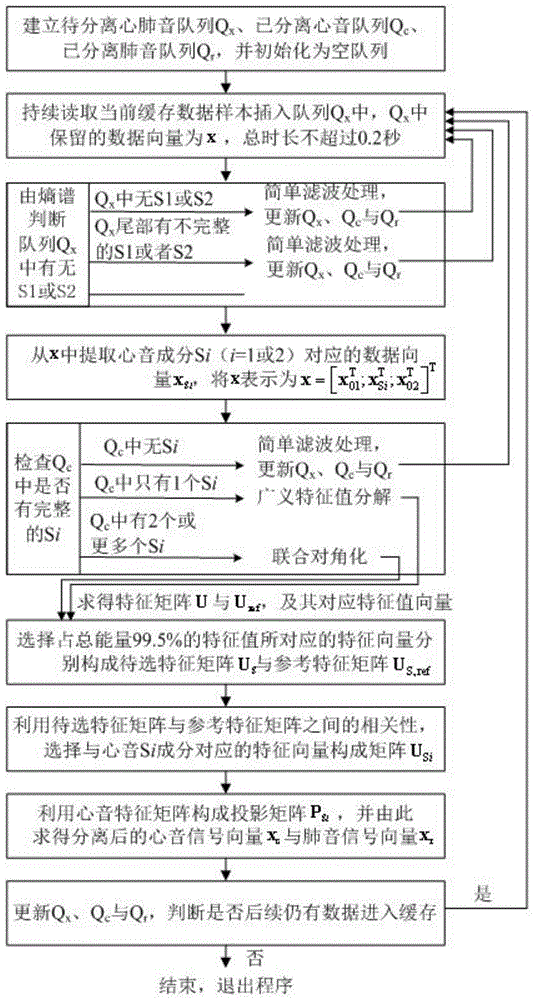
步骤1、建立3个数据队列分别为待分离心肺音队列qx、已分离心音队列qc以及已分离肺音队列qr,对待分离心肺音队列qx、已分离心音队列qc以及已分离肺音队列qr进行初始化,初始化成空队列;
步骤2、持续读取当前缓存数据样本插入队列qx中,且qx中保留的数据向量x总时长不超过0.2秒;
步骤3、采用熵谱判断队列qx中是否有第一心音成分s1或第二心音成分s2,若队列qx中无第一心音成分s1或者第二心音成分s2,将数据向量x经通带为[601000]hz的butterworth滤波器进行滤波,滤波后插入队列qr中,并将与数据向量x同等长度的全零数据向量插入队列qc中,删除队列qx中的数据,若队列qx的尾部有不完整的第一心音成分s1或者第二心音成分s2,则将该心音成分前的数据经带宽为[601000]hz的滤波器滤波,滤波后插入队列qr中,并将与该心音成分前的数据同等长度的全零数据向量插入队列qc中,删除队列qx中心音成分前的数据,若队列qx中有完整的第一心音成分s1或者第二心音成分s2,进入步骤4;
步骤4、若队列qx中有完整的si,将x中以si成分的中心点对称分布的一段连续数据向量表示为xsi,则x表示为
步骤5、若队列qx中有完整的si,检查队列qc中是否也有完整的si,若队列qc中无完整的si,将x经通带为[601000]hz的滤波器进行滤波,滤波后插入队列qr中,xsi经滤波器滤波得到
步骤6、判断队列qc中si成分的数量,若只有1个si成分,复制出以该成分的中心点对称分布的一段连续数据向量c1,利用xsi与c1计算其各自的协方差矩阵r0与r1以及参考协方差矩阵rref0与rref1,对r0与r1作广义特征值分解得到广义特征向量矩阵u和广义特征值向量d,对rref0与rref1作广义特征值分解得到广义特征向量矩阵uref和广义特征值向量dref;若有2个或者2个以上的si成分,选择最近的2个si成分,复制出以2个si成分的中心点对称分布的两段连续数据向量c1与c2,利用xsi、c1与c2计算其各自的协方差矩阵r0、r1与r2以及参考协方差矩阵rref0、rref1与rref2,对r0、r1与r2作联合对角化得到特征向量构成的矩阵u和三个对应特征值向量d0、d1与d2,对rref0、rref1与rref2作联合对角化得到特征向量构成的矩阵uref和三个对应特征值向量dref0、dref1与dref2;
步骤7、将特征向量矩阵u与uref各列按各自对应特征值从大到小顺序重新排列,选择占总能量99.5%的特征值所对应的特征向量分别构成待选特征向量矩阵us与参考特征向量矩阵us,ref;
步骤8、利用待选特征向量矩阵us与参考特征向量矩阵us,ref之间的相关性,选择与心音si成分对应的特征向量构成心音特征矩阵usi;
步骤9、利用心音特征矩阵usi构成投影矩阵psi,并由psi求得分离后的心音信号向量xc与肺音信号向量xr;
步骤10、将心音信号向量xc插入队列qc中,将肺音信号向量xr插入队列qr中,删除队列qx中的数据;若仍有数据进入缓存,执行步骤2,若再无数据进入缓存,任务结束,退出。
进一步地,所述步骤6中,利用xsi与c1计算其各自的协方差矩阵r0与r1以及参考协方差矩阵rref0与rref1,包括以下步骤:
h1、分别对xsi与c1利用上截止频率为100hz的低通滤波器进行滤波,并分别得到参考数据向量xsi,ref与c1,ref;
h2、将xsi、c1、xsi,ref与c1,ref数据向量都构造成数据矩阵x=[x1,x2,...,xn]的形式,其中,xn=[xn,xn+1,...,xm+n-1]t,n=1,2,...,n,当si为s1时,m等于0.14秒时长数据的采样点数,当si为s2时,m等于0.11秒时长数据的采样点数,而m+n-1则等于原数据向量xsi、c1、xsi,ref与c1,ref的长度;
h3、基于数据向量xsi、c1、xsi,ref与c1,ref所各自对应的数据矩阵x,利用r=(x-μ1t)(x-μ1t)t/n分别计算得到协方差矩阵r0与r1以及参考协方差矩阵rref0与rref1,其中,
进一步地,所述步骤6中,将r0与r1作广义特征值进行分解,得到广义特征向量矩阵u和广义特征值向量d的过程,采用方法如下:
w1、矩阵r0与r1为实对称矩阵,利用广义特征值分解的lanczos算法,计算矩阵束(r0,r1)的广义特征对(λk,uk),k=1,2,...,m,使得r0uk=λkr1uk,k=1,2,...,m;
w2、分别提取uk和λk,分别构成广义特征向量矩阵u=[u1,u2,...,um]和广义特征值向量d=[λ1,λ2,...,λm]t。
进一步地,所述步骤7中,将特征向量矩阵u与uref各列按各自对应特征值从大到小顺序重新排列,包括以下步骤:
p1、若步骤6得到广义特征值向量d和dref:首先对广义特征值向量d从大到小排序得到
p2、若由步骤5得到广义特征值向量d0、d1与d2以及dref0、dref1与dref2,首先计算
进一步地,所述步骤7中,选择占总能量99.5%的特征值所对应的特征向量分别构成待选特征向量矩阵us与参考特征向量矩阵us,ref,包括以下步骤:
q1、从
q2、从
进一步地,所述步骤8中,利用选特征向量矩阵us与参考特征向量矩阵us,ref之间的相关性,获得心音特征矩阵usi的方法,包括以下步骤:
f1、假设待选特征向量矩阵us的列数为m1,参考特征向量矩阵us,ref的列数为m2,计算相关系数均值
f2、将ri与阈值thr进行比较,其中,i=1,2,...,m1,thr一般取0.6,若ri大于thr,则该特征向量ui属于心音成分;
f3、将所有通过阈值thr判定属于心音成分的特征向量作为列,构成与心音si成分对应的特征向量矩阵usi。
进一步地,所述步骤9中,求得分离后的心音信号向量xc与肺音信号向量xr的方法,包括以下步骤:
k1、利用心音特征矩阵usi,构造投影矩阵
k2、计算xsi,c=psixsi,其中xsi是步骤5中由xsi构造而成的数据矩阵;
k3、从待分离心肺音队列qx的数据向量x中分离出的心音信号向量表示为
本发明的有益效果:
本发明提供的一种电子听诊器的实时心肺音自动分离方法,利用联合对角化对相邻心音周期段数据进行处理,可充分发掘相邻心音周期段心音成分的相似性以提取心音信号,从而实现心肺音的自动分离,具有较高的实用性;并可有效地分离出心音信号和肺音信号,具有准确性高的特点;能够考虑不同心音周期可能存在的信号时变,以对心音进行准确的分析,同时对于呼吸道出现病变导致听诊信号出现附加呼吸音,可在肺音分离结果中较好地保留这些附加呼吸音,为后续基于心肺音分离结果的诊断提供保障,该分离方法具有实时性以及准确性高的特点。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明中一种电子听诊器的实时心肺音自动分离方法的流程图;
图2中(a)、(b)、(c)分别表示为本发明中原始心肺音信号图、分离出的心音信号图和分离出的肺音信号图;
图3中(a)、(b)、(c)和(d)分别表示为混合前的含湿啰音的肺音信号波形图、肺音信号频谱图、心肺分离得到的肺音信号波形图和肺音信号频谱图;
图4中(a)、(b)、(c)和(d)分别表示为混合前的含喘鸣音的肺音信号波形图、肺音信号频谱图、心肺分离得到的肺音信号波形图和肺音信号频谱图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
实时例1:
通过电子听诊器采集一段健康人的心肺音信号,采样频率为8000hz,总时长为5.5秒,被试以深呼吸方式呼吸,外界无噪声干扰,且电子听诊器采用本发明中提出的实时心肺音自动分离方法。
请参阅图1和2所示,一种电子听诊器的实时心肺音自动分离方法,包括以下步骤:
步骤1、建立3个数据队列分别为待分离心肺音队列qx、已分离心音队列qc以及已分离肺音队列qr,对待分离心肺音队列qx、已分离心音队列qc以及已分离肺音队列qr进行初始化,初始化成空队列;
步骤2、持续读取当前缓存数据样本插入队列qx中,且qx中保留的数据向量x总时长不超过0.2秒;
步骤3、采用熵谱判断队列qx中是否有第一心音成分s1或第二心音成分s2,若队列qx中无第一心音成分s1或者第二心音成分s2,将数据向量x经通带为[601000]hz的butterworth滤波器进行滤波,滤波后插入队列qr中,并将与数据向量x同等长度的全零数据向量插入队列qc中,删除队列qx中的数据,若队列qx的尾部有不完整的第一心音成分s1或者第二心音成分s2,则将该心音成分前的数据经带宽为[601000]hz的滤波器滤波,滤波后插入队列qr中,并将与该心音成分前的数据同等长度的全零数据向量插入队列qc中,删除队列qx中心音成分前的数据,若队列qx中有完整的第一心音成分s1或者第二心音成分s2,进入步骤4;
步骤4、若队列qx中有完整的si(i=1或2),将x中以si成分的中心点对称分布的一段连续数据向量表示为xsi(i=1时其时长为0.18秒,i=2时其时长为0.15秒),则x表示为
步骤5、若队列qx中有完整的si(i=1或2),检查队列qc中是否也有完整的si,若队列qc中无完整的si,将x经通带为[601000]hz的butterworth滤波器进行滤波,滤波后插入队列qr中,xsi经butterworth滤波器(i=1时通带为[10300]hz,i=2时通带为[50320]hz)滤波得到
步骤6、判断队列qc中si成分的数量,若只有1个si成分,复制出以该成分的中心点对称分布的一段连续数据向量c1(当si为s1时c1的长度为0.18秒时长的采样点数,当si为s2时c1的长度为0.15秒时长的采样点数),利用xsi计算其协方差矩阵r0与参考协方差矩阵rref0,利用c1计算其协方差矩阵r1与参考协方差矩阵rref1,对r0与r1作广义特征值分解得到广义特征向量矩阵u和广义特征值向量d,对rref0与rref1作广义特征值分解得到广义特征向量矩阵uref和广义特征值向量dref;若有2个或者2个以上的si成分,选择最近的2个si成分,复制出以2个si成分的中心点对称分布的两段连续数据向量c1与c2(当si为s1时c1与c2的长度均为0.18秒时长的采样点数,当si为s2时c1与c2的长度均为0.15秒时长的采样点数),利用xsi、c1与c2计算其各自的协方差矩阵r0、r1与r2以及参考协方差矩阵rref0、rref1与rref2,对r0、r1与r2作联合对角化得到特征向量构成的矩阵u和三个对应特征值向量d0、d1与d2,对rref0、rref1与rref2作联合对角化得到特征向量构成的矩阵uref和三个对应特征值向量dref0、dref1与dref2;
其中,利用xsi与c1计算其各自的协方差矩阵r0与r1以及参考协方差矩阵rref0与rref1,包括以下步骤:
h1、分别对xsi与c1利用上截止频率为100hz的低通滤波器进行滤波,并分别得到参考数据向量xsi,ref与c1,ref;
将xsi、c1、xsi,ref与c1,ref数据向量都构造成数据矩阵x=[x1,x2,...,xn]的形式,其中,xn=[xn,xn+1,...,xm+n-1]t,n=1,2,...,n,当si为s1时,m等于0.14秒时长数据的采样点数,当si为s2时,m等于0.11秒时长数据的采样点数,m+n-1则等于原数据向量xsi、c1、xsi,ref与c1,ref的长度;
h3、基于数据向量xsi、c1、xsi,ref与c1,ref所各自对应的数据矩阵x,利用r=(x-μ1t)(x-μ1t)t/n分别计算得到协方差矩阵r0与r1以及参考协方差矩阵rref0与rref1,其中,
其中,将r0与r1作广义特征值进行分解,得到广义特征向量矩阵u和广义特征值向量d,采用的方法如下:
w1、矩阵r0与r1为实对称矩阵,利用广义特征值分解的lanczos算法,计算矩阵束(r0,r1)的广义特征对(λk,uk),k=1,2,...,m,使得r0uk=λkr1uk,k=1,2,...,m;
w2、分别提取uk和λk,分别构成广义特征向量矩阵u=[u1,u2,...,um]和广义特征值向量d=[λ1,λ2,...,λm]t。
其中,对r0、r1与r2作联合对角化,采用的是cardoso等人提出的近似联合对角化的jacobi算法,计算使得目标函数
步骤7、将特征向量矩阵u与uref各列按各自对应特征值从大到小顺序重新排列,选择占总能量99.5%的特征值所对应的特征向量分别构成待选特征向量矩阵us与参考特征向量矩阵us,ref;
其中,将特征向量矩阵u与uref各列按各自对应特征值从大到小顺序重新排列,包括以下步骤:
p1、若步骤6得到广义特征值向量d和dref:首先对广义特征值向量d从大到小排序得到
p2、若由步骤5得到广义特征值向量d0、d1与d2以及dref0、dref1与dref2,首先计算
其中,选择占总能量99.5%的特征值所对应的特征向量分别构成待选特征向量矩阵us与参考特征向量矩阵us,ref,包括以下步骤:
q1、从
q2、从
步骤8、利用待选特征向量矩阵us与参考特征向量矩阵us,ref之间的相关性,选择与心音si成分对应的特征向量构成心音特征矩阵usi;
其中,利用选特征向量矩阵us与参考特征向量矩阵us,ref之间的相关性,获得心音特征矩阵usi的方法,包括以下步骤:
f1、假设待选特征向量矩阵us的列数为m1,参考特征向量矩阵us,ref的列数为m2,计算相关系数均值
f2、将ri与阈值thr进行比较,其中,i=1,2,...,m1,thr一般取0.6,若ri大于thr,则该特征向量ui属于心音成分;
f3、将所有通过阈值thr判定属于心音成分的特征向量作为列,构成与心音si成分对应的特征向量矩阵usi。
步骤9、利用心音特征矩阵usi构成投影矩阵psi,并由psi求得分离后的心音信号向量xc与肺音信号向量xr;
其中,求得分离后的心音信号向量xc与肺音信号向量xr的方法,包括以下步骤:
k1、利用心音特征矩阵usi,构造投影矩阵
k2、计算xsi,c=psixsi,其中xsi是步骤5中由xsi构造而成的数据矩阵;
k3、从待分离心肺音队列qx的数据向量x中分离出的心音信号向量表示为
步骤10、将心音信号向量xc插入队列qc中,将肺音信号向量xr插入队列qr中,删除队列qx中的数据;若仍有数据进入缓存,执行步骤2,若再无数据进入缓存,任务结束,退出。
实施例2:
为验证本发明在呼吸音中出现湿啰音时的心肺音分离结果,采用在辽宁中医药大学附属医院儿科诊室采集的一段患有肺炎的5岁幼儿的听诊数据,采集位置在背部且该听诊信号中几乎不含心音信号,采样频率为8000hz,采样时长为4秒,经听诊专家判定该段数据中含有湿啰音。把该肺音信号与一段屏住呼吸时所录的心音信号进行叠加,生成一段混合心肺音信号。
为了模拟电子听诊器的实时处理过程,在计算机内存中分配1600×16bit的空间用于模拟待分离心肺音队列qx,并将该段混合心肺音信号数据以0.125ms每个样本(16bit)的速度读入该内存空间中,其余算法操作步骤与实施例1相同。
如图3所示,即使待分离的心肺音信号中含有湿啰音,本发明所得的心肺音分离结果中的肺音信号中仍然保留该湿啰音成分,因此不仅不会影响后续的肺音诊断结果,还因心音的抵消可增强肺音诊断效果,其中,虚线框所标记的是喘鸣音所在的区域。
实施例3:
为验证本发明在呼吸音中出现喘鸣音时的心肺音分离结果,采用在辽宁中医药大学附属医院儿科诊室采集的一段10岁哮喘患儿的听诊数据,采集位置在背部且该听诊信号中几乎不含心音信号,采样频率为8000hz,采样时长为4秒,经听诊专家判定该段数据中含有喘鸣音,把该肺音信号与一段屏住呼吸时所录的心音信号进行叠加,生成一段混合心肺音信号,该模拟电子听诊器的实时处理过程与实施例1相同。
图4所示的是混合前的含喘鸣音的肺音信号,通过该附图可知,即使待分离的心肺音信号中含有喘鸣音,本发明所得的心肺音分离结果中的肺音信号中仍然保留该喘鸣音成分,因此不仅不会影响后续的肺音诊断结果,还因心音的抵消可增强肺音诊断效果,其中,虚线框所标记的是喘鸣音所在的区域。
以上内容仅仅是对本发明的构思所作的举例和说明,所属本技术领域的技术人员对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,只要不偏离发明的构思或者超越本权利要求书所定义的范围,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!