一种基于机器阅读理解的智能交互导诊咨询系统的制作方法
本发明涉及自然语言处理技术领域,特别是一种基于机器阅读理解的智能交互导诊咨询系统。
背景技术:
由于医院的科室类别繁杂,患者在医院就医时,无法准确选择自己应该挂号的科室,有时因为各种原因不方便咨询医院的导诊人员,导致挂号效率较低,还会出现挂错科室的结果,用户体验较差。近年来,机器学习领域发展迅速,使用机器学习相关技术构建医疗导诊系统,能够设计出智能化程度高、操作简便的导诊咨询系统。
传统的咨询系统基于大量规则库,主要通过人工录入一些规则,当用户提问时,会从规则库快速找到匹配答案返回给用户,但是这种方法需要编写大量的规则,规则之间的关系不透明。当规则很多时(多于100条规则),系统速度会很慢。基于规则的大型系统可能就不适用于实时应用。此外,基于规则的咨询系统没有学习能力,不具备从经验中学习的能力。人类专家知道何时打破规则,而咨询系统并不能自动修改知识库,例如调整规则、添加规则,修改和维护系统的任务仍然由知识工程师来做。
技术实现要素:
本发明的目的在于提供一种能够为患者提供导诊服务,方便了患者选择科室,提高医院效率,导诊准确率高,系统交互性强,方便用户使用的智能交互导诊咨询系统。
实现本发明目的的技术解决方案为:.一种基于机器阅读理解的智能交互导诊咨询系统,其特征在于,包括自然语言理解模块、阅读理解模块和对话管理模块;
所述自然语言理解模块,分析用户输入的自然语言语句,判断语句的意图,并且抽取语句中的关键信息;
所述阅读理解模块,根据自然语言理解模块抽取的关键信息,判断用户应该选择的科室;
所述对话管理模块,管理对话流程,生成系统回答语句,引导用户导诊。
进一步地,所述自然语言理解模块,具体包括:
语料获取和预处理;
数据集准备:根据医疗导诊数据集规模和内容设计长短期记忆神经网络,训练词表示模型,词表示模型将自然语言表示为计算机所能接受的形式;
模型训练:使用给定的医疗导诊数据集,包括医疗症状,对自然语言理解神经网络模型进行训练;
识别语句:使用训练后的模型识别用户输入语句的意图,并提取语句中的关键信息。
进一步地,所述阅读理解模块,具体包括:
数据集准备:根据医疗诊断数据集和内容,设计阅读理解神经网络;
模型训练:使用医疗诊断数据集,对阅读理解模型进行训练;
选择科室:使用训练后的模型,根据自然语言理解模块收集的信息,选择相应的科室。
进一步地,所述对话管理模块,具体包括:
定义意图和动作:基于当前对话状态和意图、实体选取下一步采取的行动;
定义解释器:包括执行自然语言理解模块和把消息转化为格式化信息;
数据准备:设计长短期记忆网络对话模型;
模型训练:得到对话模型;
根据对话模型进行对话管理。
进一步地,所述的语料获取和预处理,具体包括:
收集中文语料库,包括医疗相关语料和常用语料,训练词向量表示模型,得到词向量特征。
进一步地,所述数据集准备:根据数据集规模和内容设计长短期记忆神经网络,训练词表示模型,具体如下:
数据集由问诊相关语句与日常用语构成,标记语句的意图和语句中的实体,并标记语句中实体的起始位置;使用长短期神经网络作为模型,分类采用softmax归一化指数函数,训练词表示模型。
进一步地,所述数据集准备:根据数据集和内容,设计神经网络,具体如下:
预训练词向量和字向量,字向量用卷积神经网络训练。
进一步地,所述的选择科室:使用训练后的模型,根据收集的信息选择相应的科室,具体如下:
首先根据用户信息判断应该使用的医疗信息段落,然后使用训练的阅读理解模块的模型预测问题答案,并将答案传递给对话管理模块。
进一步地,所述的数据准备,设计长短期记忆网络对话模型,具体如下:
编写对话规则,由不同的故事路径构成,设计长短期记忆网络,训练对话管理模型,使用对话管理模块的模型进行对话管理。
进一步地,所述的模型训练:得到对话模型,具体如下:
采用监督学习的训练方式,用长短期记忆网络模型训练对话模型,具体为:
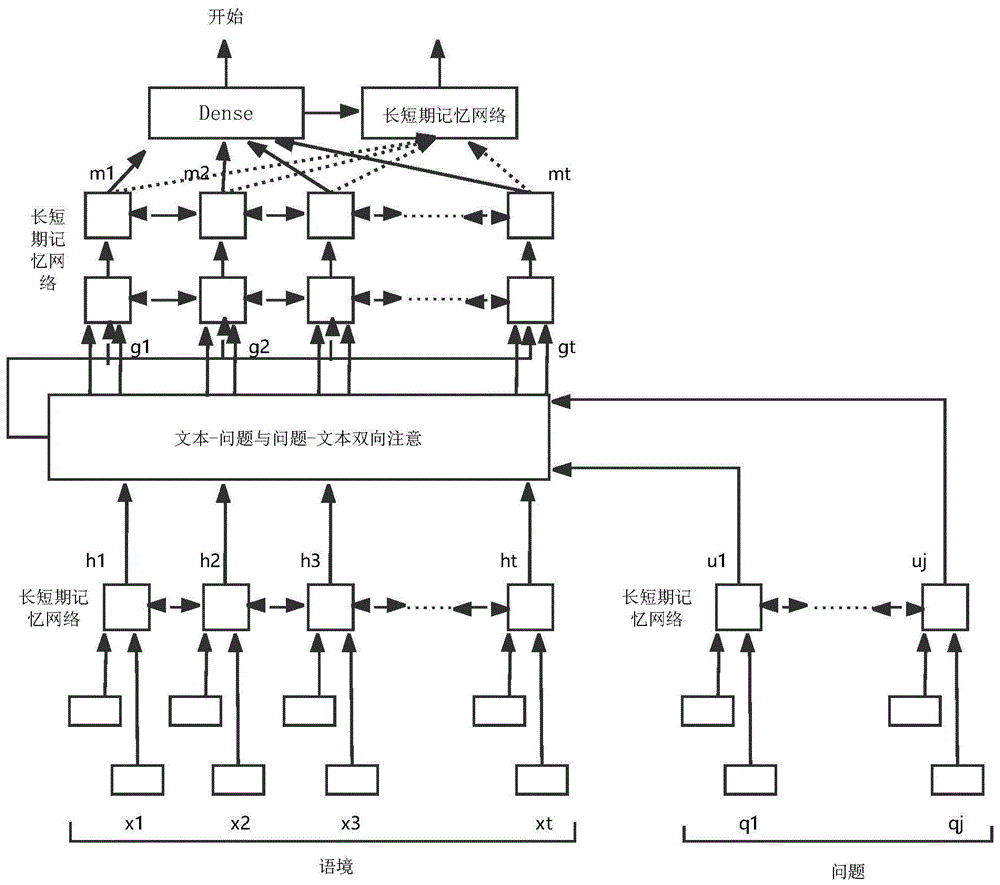
首先预训练词向量,单词w的表示由词向量和字向量拼接而成,然后经过两层高速公路网络得到d维度的向量,语境词集合x∈rd*t和问题词集合q∈rd*j,rd*t代表一个d*t的矩阵,rd*j表示一个d*j的矩阵,t为语境中的单词数,j为问题中的单词数;使用长短期记忆网络即lstm来模拟单词之间的时间交互,在两个方向上放置一个lstm,并连接两个lstm的输出,从上下文字向量x获得h∈r2d*t,并且从查询字向量q获得u∈r2d*t;
计算各自单词间的局部关系,相似度计算方式是:
其中
然后计算双向注意力
计算context-to-queryattention即c2q上下文注意力:对于语境中的第t个单词,计算查询中的每个单词与该词的相关度,根据前面得到的相关性矩阵,使用归一化指数函数softmax()对列归一化,然后计算查询向量加权和得到语境词的新表示
at=softmax(st:)
其中at为j维向量,表示第t个上下文词对查询词的注意权重,st:表示s的第t个行向量,atj代表at的第j个元素;
计算query-to-contextattention即q2c上下文注意力:计算对于查询中的词,语境中的每个词与它的相关度;首先取相关性矩阵每列最大值,对进行softmax归一化指数
b=softmax(maxcol(s))
其中sofrmax()为归一化函数,maxcol()函数为在列上执行最大函数,h:t为h的第t个列向量;b为语境词的注意力权重;
将上下文嵌入和注意力向量合并到了g之中,g的每一列就是对上下文的每一个词的问题-察觉表达,β是一个可训练的函数,⊙为点乘;
然后为建模层,输入是g,再经过一次长短期记忆网络lstm得到m,捕捉的是以查询为条件的上下文单词之间的关系,m的一列代表的是融入了查询后的语境中一个词的上下文表示;
预测开始位置p1和结束位置p2
其中
首先定义损失函数l(θ)
其中θ是模型中所有可训练权重的集合
本发明与现有技术相比,其显著优点在于:(1)为患者提供导诊服务,方便了患者选择科室,减少了医院成本,提高了医院效率,导诊准确率高,系统交互性强;(2)基于机器学习,使用用户模拟器做强化学习,进行端到端的训练,将知识库编码在一个复杂的深度网络,然后再和编码后的问题结合解码生成答案,提高了系统的智能化程度,提高了导诊的准确率;(3)数据集采用医疗相关信息,训练的模型非常适用于医疗导诊方面的应用。
附图说明
图1是本发明基于机器阅读理解的智能交互导诊咨询系统中阅读理解模块模型图。
图2是本发明中对话管理模块的流程图。
具体实施方式
本发明基于机器阅读理解的智能交互导诊咨询系统,其特征在于,包括自然语言理解模块、阅读理解模块和对话管理模块;
所述自然语言理解模块,分析用户输入的自然语言语句,判断语句的意图,并且抽取语句中的关键信息;
所述阅读理解模块,根据自然语言理解模块抽取的关键信息,判断用户应该选择的科室;
所述对话管理模块,管理对话流程,生成系统回答语句,引导用户导诊。
进一步地,所述自然语言理解模块,具体包括:
语料获取和预处理;
数据集准备:根据医疗导诊数据集规模和内容设计长短期记忆神经网络,训练词表示模型,词表示模型将自然语言表示为计算机所能接受的形式;
模型训练:使用给定的医疗导诊数据集,包括医疗症状,对自然语言理解神经网络模型进行训练;
识别语句:使用训练后的模型识别用户输入语句的意图,并提取语句中的关键信息。
进一步地,所述阅读理解模块,具体包括:
数据集准备:根据医疗诊断数据集和内容,设计阅读理解神经网络;
模型训练:使用医疗诊断数据集,对阅读理解模型进行训练;
选择科室:使用训练后的模型,根据自然语言理解模块收集的信息,选择相应的科室。
进一步地,所述对话管理模块,具体包括:
定义意图和动作:基于当前对话状态和意图、实体选取下一步采取的行动;
定义解释器:包括执行自然语言理解模块和把消息转化为格式化信息;
数据准备:设计长短期记忆网络对话模型;
模型训练:得到对话模型;
根据对话模型进行对话管理。
进一步地,所述的语料获取和预处理,具体包括:
收集中文语料库,包括医疗相关语料和常用语料,训练词向量表示模型,得到词向量特征。
进一步地,所述数据集准备:根据数据集规模和内容设计长短期记忆神经网络,训练词表示模型,具体如下:
数据集由问诊相关语句与日常用语构成,标记语句的意图和语句中的实体,并标记语句中实体的起始位置;使用长短期神经网络作为模型,分类采用softmax归一化指数函数,训练词表示模型。
进一步地,所述数据集准备:根据数据集和内容,设计神经网络,具体如下:
预训练词向量和字向量,字向量用卷积神经网络训练。
进一步地,所述的选择科室:使用训练后的模型,根据收集的信息选择相应的科室,具体如下:
首先根据用户信息判断应该使用的医疗信息段落,然后使用训练的阅读理解模块的模型预测问题答案,并将答案传递给对话管理模块。
进一步地,所述的数据准备,设计长短期记忆网络对话模型,具体如下:
编写对话规则,由不同的故事路径构成,设计长短期记忆网络,训练对话管理模型,使用对话管理模块的模型进行对话管理。
进一步地,所述的模型训练:得到对话模型,具体如下:
采用监督学习的训练方式,用长短期记忆网络模型训练对话模型,具体为:
首先预训练词向量,单词w的表示由词向量和字向量拼接而成,然后经过两层高速公路网络得到d维度的向量,语境词集合x∈rd*t和问题词集合q∈rd*j,rd*t代表一个d*t的矩阵,rd*j表示一个d*j的矩阵,t为语境中的单词数,j为问题中的单词数;使用长短期记忆网络即lstm来模拟单词之间的时间交互,在两个方向上放置一个lstm,并连接两个lstm的输出,从上下文字向量x获得h∈r2d*t,并且从查询字向量q获得u∈r2d*t;
计算各自单词间的局部关系,相似度计算方式是:
其中
然后计算双向注意力
计算context-to-queryattention即c2q上下文注意力:对于语境中的第t个单词,计算查询中的每个单词与该词的相关度,根据前面得到的相关性矩阵,使用归一化指数函数softmax()对列归一化,然后计算查询向量加权和得到语境词的新表示
at=softmax(st:)
其中at为j维向量,表示第t个上下文词对查询词的注意权重,st:表示s的第t个行向量,atj代表at的第j个元素;
计算query-to-contextattention即q2c上下文注意力:计算对于查询中的词,语境中的每个词与它的相关度;首先取相关性矩阵每列最大值,对进行softmax归一化指数
b=softmax(maxcol(s))
其中sofrmax()为归一化函数,maxcol()函数为在列上执行最大函数,h:t为h的第t个列向量;b为语境词的注意力权重;
将上下文嵌入和注意力向量合并到了g之中,g的每一列就是对上下文的每一个词的问题-察觉表达,β是一个可训练的函数,⊙为点乘;
然后为建模层,输入是g,再经过一次长短期记忆网络lstm得到m,捕捉的是以查询为条件的上下文单词之间的关系,m的一列代表的是融入了查询后的语境中一个词的上下文表示;
预测开始位置p1和结束位置p2
其中
首先定义损失函数l(θ)
其中θ是模型中所有可训练权重的集合
下面结合具体实施例,并参照附图对本发明进一步详细说明。
实施例
本发明基于机器阅读理解的智能交互导诊咨询系统,包括自然语言理解模块、阅读理解模块和对话管理模块;
所述自然语言理解模块,分析用户输入的自然语言语句,判断语句的意图,并且抽取语句中的关键信息;
所述阅读理解模块,根据自然语言理解模块抽取的关键信息,判断用户应该选择的科室;
所述对话管理模块,管理对话流程,生成系统回答语句,引导用户导诊。
进一步地,所述自然语言理解模块,具体如下:
语料获取和预处理:收集常用中文语料和大量医疗相关语料,对语料进行分词,将每个词映射到向量空间,其中向量之间的距离代表词之间的相似度,得到词特征向量;
数据集准备:根据医疗导诊数据集规模和内容设计长短期记忆神经网络,训练词表示模型,词表示模型将自然语言表示为计算机所能接受的形式;
模型训练:使用给定的医疗导诊数据集,包括医疗症状,对自然语言理解神经网络模型进行训练;
识别语句:使用训练后的模型识别用户输入语句的意图,并提取语句中的关键信息。
进一步地,所述阅读理解模块,具体如下:
所述数据集准备,根据数据集设计神经网络,具体如下:
预训练词向量和字向量可训练,字向量用卷积神经网络训练;
所述模型训练:使用大量数据集,对模型进行训练,具体如下:
单词w的表示由词向量和字向量的拼接,然后经过两层highwaynetwork得到x∈rd*t和q∈rd*j;
对上一步的x和q分别使用lstm编码,捕捉x和q各自单词间的局部关系,拼接双向长短期记忆网络的输出,得到h∈r2d*t和u∈r2d*j;
对上一步的h和u,做context-to-query(语境-问题)以及query-to-context(问题-语境)两个方向的注意力:先计算相关性矩阵,再归一化计算注意力分数,最后与原始矩阵相乘得到修正的向量矩阵;
context-to-query和query-to-context共享相似度矩阵,s∈rt*j;
相似度计算方式是:
stj=α(h:t,u:j)∈r
其中stj为第t个contextword和第j个queryword之间的相似度;α为scalarfunction,h:t为h的第t个列向量,u:j为u的第j个列向量,⊙为点乘,[;]表示向量在行上的拼接;
计算context-to-queryattention(c2q注意力):计算和每一个contextword(语境词)最相关的querywords(查词),根据前面得到的相关性矩阵,使用softmax(归一化指数函数)函数对列归一化,然后计算query向量加权和得到
at=softmax(st:)∈rjv
h=∑tbth:t∈r2d
计算query-to-contextattention(q2c注意力):计算和每一个queryword(查询词)最相关的contextwords(语境词),取相关性矩阵每列最大值,对其进行softmax归一化指数函数计算语境向量加权和,然后重复t次得到
b=softmax(maxcol(s))∈rt
其中
将三个矩阵拼接起来得到g:
其中β为多层感知机;
然后为建模层,输入是g,再经过一次lstm(长短期记忆网络)得到m∈r2d*t,捕捉的是以查询为条件的上下文单词之间的关系,m的每一个列向量都包含了对应单词关于整个语境词和查询词的上下文信息
预测开始位置p1和结束p2为:
p1和p2是答案开始位置和结束位置的概率分布,
最后的目标函数:
θ是模型中所有可训练权重的集合,n是数据集中的示例数,其中
进一步地,所述对话管理模块,具体如下:
定义意图和动作:模块基于当前对话状态和意图、实体选取下一步采取的行动;
定义解释器:包括执行自然语言理解模块和把消息转化为格式化信息;
数据准备:设计长短期记忆网络对话模型;
模型训练:得到对话模型;
根据对话模型进行对话管理。
所述数据准备:设计长短期记忆网络对话模型,具体如下:
编写两个文件domain.yml和story.md,domain.yml包括对话系统所适用的领域,其中包括意图集合、实体槽集合、机器人相应方式的集合;story.md包括训练数据集合,这里的训练数据是原始的对话在domain中的映射。
所述模型训练:得到对话模型,具体如下:
采用监督学习的训练方式,用长短期记忆网络模型训练对话模型。
所述对话管理模块,进行对话状态维护,控制导诊对话流程,引导用户完成导诊流程。作为接口与后端/任务模型进行交互,接收用户输入信息,根据对话模型判断系统的下一步操作,生成对话信息。如果用户输入的为症状等信息,系统利用自然语言理解模型判断用户的意图为问诊,并识别出相关实体,然后系统根据阅读理解模块从语料库中生成建议科室,对话管理系统根据相关信息生成回答返回给用户。
首先定义意图和动作,模块基于当前对话状态和意图、实体选取下一步采取的行动,定义解释器,包括执行自然语言理解模块和把消息转化为格式化信息,编写对话规则,设计长短期记忆网络,进行模型训练,得到对话模型,根据对话模型进行对话管理,对话模型采用监督学习的训练方式,使用f-score进行评估。
对于对话模型,首先准备两个数据文件,一个包括对话系统所适用的域,一个为数据的集合,此集合为原始对话在域中的映射。模型输入为历史对话记录,下一个决策动作作为标签,模型训练的三个参数为max_history_len(记录的最大历史长度),num_feature(每个记录的特征维度),num_actions(候选响应数)。x的维度为:(num_states,max_history,num_features),y的维度为:num_states,对y进行一个热编码,shuffle训练集,之后进行训练。
图1是阅读理解模块的模型图,首先是输入层,预训练词向量,字向量使用卷积神经网络训练,得到文本向量和问题向量,然后是嵌入编码层,使用长短期记忆网络对文本向量和问题向量进行编码,捕捉文本向量和问题向量单词间的局部关系,然后是文本-答案注意层,这一层采用双向计算注意分数的方式,并将三个矩阵拼接为一个矩阵,然后在经过建模层将矩阵编码为一个矩阵,最后为输出层,预测答案的起始位置和结束位置。
图2是对话管理模块的流程图,用户输入的语句首先经由解释器转成文本,意图和实体,然后传到跟踪器,跟踪器负责记录对话状态,接收解释器的结果,规则收到当前状态信息,规则自动选择下一步行动,所选择的行动被追踪器记录,系统向用户输出回复。
综上可知,本发明基于机器阅读理解的智能交互导诊咨询系统,包括自然语言理解模块、阅读理解模块、对话管理模块,所有模块基于机器学习相关技术完成,具有高度智能化、自动化等特点,适合用于医疗导诊服务。
- 还没有人留言评论。精彩留言会获得点赞!