基于深度学习的上下级眼科远程诊断平台及其构建方法与流程
本发明属于计算机信息处理
技术领域:
,涉及一种基于深度学习的上下级医院眼科远程联合诊断平台及其构建方法。
背景技术:
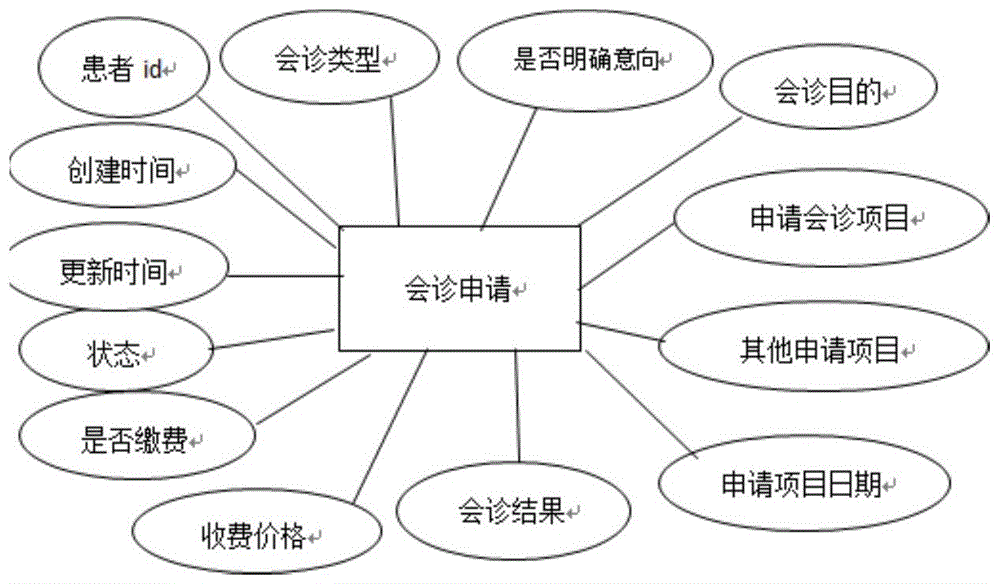
:目前市面上存在许多网络诊治云平台,致力于联通患者与专科医生,以期达到“不出门便可看病”的模式。从现有技术平台来看网络信息鱼龙混杂,缺乏医生的专业性、权威性,治疗疾病的有效性也无法预计。并且对于生活条件更为困难的患者或者重病患者,没有特别优先权,极易耽误病情,更是在用户量较大时容易引起系统平台崩溃。且现有的许多平台在数据收集方面缺乏眼科专业医师的建议,数据收集不完善,故降低了交流的效率,也使宝贵的眼科疑难病例大数据可能被浪费。同时,现有与眼科相关的远程诊断系统,并没有充分利用医学大数据,医生的诊断方式依然传统,平台不能够推荐治疗方案,减轻医生的负担。因此以互联网为背景,针对“上下级医院眼科远程联合诊断”这一对象,设计开发基于深度学习的上下级医院眼科远程联合诊断平台对眼科患者有着非常重要的意义。技术实现要素:本发明的目的在于提供一种基于深度学习的上下级医院眼科远程诊断平台,以解决现有诊断平台对于重症患者没有特权易耽误病情的问题、用户量较大时易引起系统平台崩溃的问题、安全性保障低的问题、和不能充分利用医学大数据智能的给出推荐诊断及治疗方案的问题。本发明的另一目的在于提供一种基于深度学习的上下级眼科远程诊断平台的构建方法。本发明所采用的技术方案是,基于深度学习的上下级眼科远程诊断平台,包括:前端用户界面,用于用户登录,并通过验证码及用户身份关键字验证用户身份,依据用户身份赋予用户相应权限,用户身份包括上级医院、下级医院和管理员;下级医院处理模块,用于下级医院提交会诊申请、发送患者信息,并接收上级医院的会诊回复;上级医院处理模块,用于上级医院接收患者信息、对患者进行排队诊断、并发送诊断回复。进一步的,所述下级医院处理模块由会诊申请模块、下级在线互动模块、下级信息加密模块和下级信息解密模块组成;所述会诊申请模块,用于添加患者个人信息,提交下级会诊申请,并选择是否需要在线互动;所述下级在线互动模块,用于编辑下级医院与上级医院间的互动信息;所述下级信息加密模块,基于加密算法对患者信息及互动信息进行加密处理,并发送加密处理后的患者信息及互动信息;所述下级信息解密模块,用于接收上级医院的诊断回复及互动信息,并对其进行解密。进一步的,还包括有用于监测平台异常的后台管理模块;所述上级医院处理模块由上级信息解密模块、上级医院在线互动模块、会诊申请处理模块、分类推荐模块、上级信息加密模块组成;所述上级信息解密模块,用于接收加密处理后的患者信息及互动信息,并对其进行解密;所述会诊申请处理模块,用于依据患者信息,采用基于大数据的聚类分析算法对患者病症进行自动分类,并依据患者病情采用优先排队算法赋予患者权值,然后依据患者的病症和患者权值进行诊断排序,最后依据患者的诊断顺序进行诊断,并选择是否需要在线互动;所述上级医院在线互动模块,用于编辑上级医院与下级医院间的互动信息;所述分类推荐模块,基于患者的病症,利用apriori算法找出其诊断及推荐诊疗方案,辅助上级医院诊断及治疗;所述上级信息加密模块,基于加密算法对上级医院的诊断信息及互动信息进行加密处理,并发送加密处理后的诊断信息及互动信息;所述下级信息加密模块和上级信息加密模块均采用md5加密算法对发送的信息进行加密;上级信息解密模块和下级解密信息模块均采用同一密钥对接收的信息进行解密;所述下级信息加密模块与上级信息解密模块之间,以及上级信息加密模块与下级解密信息模块之间均通过tcp/ip协议传输患者信息。本发明所采用的另一技术方案是,基于深度学习的上下级眼科远程诊断平台的构建方法,具体步骤如下:步骤s1、前端用户登录及身份验证界面设计;步骤s2、依据上下级眼科远程诊断平台的功能及需求,设计并构建数据库;步骤s3、逻辑功能实现:采用php,利用thinkphp框架开发出上下级医院眼科远程联合诊断平台,在构建完成的数据库基础上实现平台的各项功能。进一步的,所述数据库的设计过程如下:步骤s21、依据上下级医院远程联合诊断平台的功能和需求分析来确定数据库,数据库包括患者信息表、医生信息表、医院信息表、会诊申请表、在线交流表、通知公告表、网站日志表;步骤s22、依据确定的数据库,确定会诊申请的各个实体之间的用例图,会诊申请的各个实体即为患者的各项信息;步骤s23、数据库中各字和字段代表用例图中的各个实体,依据用例图获取各个实体之间的关系模式,即确定数据库的表和表中的各个字段的关系;所述数据库的构建,是根据用例图直接编写sql语句,用ddl定义数据库结构、组织数据入库、编制与调试数据库应用程序,利用phpmyadmin直接导入数据创建表格;所述步骤s3具体包括:步骤s31、实现下级医院输入患者信息,进行会诊申请的功能;步骤s32、实现下级医院与上级医院之间的在线互动功能;步骤s33、基于md5加密算法实现上级医院和下级医院的信息加密以及信息解密功能;步骤s34、依据患者信息,采用基于大数据的聚类分析算法对患者病症进行分类,确定患者的疾病病症簇,利用gb算法对聚类分析算法分类的结果进行分类优化,并依据患者病情采用优先排队算法赋予患者权值,之后依据患者的疾病病症簇和患者权值进行诊断排序,最后依据患者的诊断顺序对下级会诊申请进行诊断,实现会诊申请处理功能;步骤s35、利用apriori算法找出每种疾病病症簇对应的疾病的诊断及推荐诊疗方案,实现依据患者的病症进行分类推荐的功能;步骤s36、定期访问平台的网站日志表,查看平台是否存在异常,实现监测平台异常的功能。进一步的,所述md5加密算法的实现过程如下:步骤s331、分组及填充:从前到后依次对输入的用户信息按每组信息长度为512位进行一次分组,如果分组的信息长度小于512位,则对其进行填充,填充第一位为1,其余为0,使每组信息长度为512位;步骤s332、初始化变量:md5缓存区初始化,缓冲区用来存放中间结果,将每组信息长度为512位的信息数据进行二次分组,分成h0h1...hi...h1516个小组,每个小组hi的信息长度为32位;使用128位长的缓冲区来存放中间计算结果和最终hash值,将缓冲区分为4个32位长的寄存器r0、r1、r2、r3,每个寄存器都以小端存储方式保存数据,并对4个寄存器进行初始化;步骤s333、从第一分组开始,依次对每组信息长度为512位的数据进行处理,具体处理流程如下:步骤s3331、处理分组变量,将当前信息长度为512位的分组数据的最前面128位数据即h0~h3这4个小组中的数据复制到4个32位的中间变量m、n、o、p中;步骤s3332、将中间变量m、n、o、p的值赋值给另外4个中间变量m、n、o、p,即m=m,n=n,o=o,p=p,然后任意选取m、n、o和p中的三个变量作非线性函数运算,将非线性函数运算结果加上未参与非线性函数运算的变量后左移,然后将变量m、n、o或p与左移结果相加得到最终运算结果,最后用最终运算结果替换前述与左移结果相加的变量m、n、o或p;步骤s3333、将步骤s3332中完成计算后的变量m、n、o、p的值分别赋值给中间变量m、n、o、p,即m=m,n=n,o=o,p=p,对中间变量m、n、o、p进行更新;步骤s3334、将步骤s3332~s3333循环进行16次,对该分组进行计算;步骤s3335、将该分组数据的最终运算结果的m、n、o、p的值分别存放至缓冲区寄存器中;步骤s3336、将该分组数据下一个128位数据复制到4个中间变量m、n、o、p中,循环步骤s3332~s3335,当下一个128位数据的运算结果存入缓冲区寄存器中时,上一个128位数据的运算结果将会输出;步骤s3337、将步骤s3336循环进行三次,依次对h4~h7、h8~h11、h12~h15中的数据进行运算;步骤s334、循环步骤s333,利用更新的m、n、o、p进行下一分组的计算,直至所有分组完成计算;所述将步骤s3332~s3335循环进行四次中,非线性函数运算是依次采用下述非线性函数:y1(x,y,z)=(x&y)|((~x)&z);y2(x,y,z)=(x&z)|(x&(~z));y3(x,y,z)=x∧y∧z;y4(x,y,z)=x∧(y|(~z));其中,y1~y4表示四轮非线性函数运算的结果,每个非线性函数中x、y、z对应每次任选的m、n、o、p中的三个变量;所述解密过程与md5加密算法采用同一密钥,即解密过程为md5加密算法的逆过程。进一步的,所述采用基于大数据的聚类分析算法对患者病症进行分类,是采用k-means聚类分析算法和已有的医疗大数据推导患者的疾病病症簇,具体实现过程如下:步骤s341a、从样本数据即医联体内的医疗大数据中随机选择k个样本数据作为初始聚类中心,k由医疗大数据中存在的眼科疾病类型所确定;步骤s342a、确定每个待聚类对象即剩余样本数据与每个初始聚类中心之间的相似度,依据该相似度将每个待聚类对象和与其距离最小的初始聚类中心划分在一个簇中,得到k个初始病症簇;所述每个待聚类对象与每个初始聚类中心之间的相似度采用欧氏距离公式计算,欧式距离公式为:其中xi=(xi1,xi2,…,xim),cj=(cj1,cj2,…,cjm),xim表示第i个待聚类对象的第m个检查项目指标值,cjm表示第j个初始聚类中心的第m个检查项目指标值。样本中的检查项目指标很多,患者的检查项目指标较少,一般小于样本中的指标项目;步骤s343a、根据下式更新k个聚类中心:其中,cj是更新后的第j个聚类中心,sj是第j个初始簇中样本的集合,nj是sj中样本数据的个数,xi′表示sj中的第i′个样本数据;步骤s344a、采用交叉迭代的方法并利用目标优化函数对更新后的聚类中心的模糊位置进行微调,得到最终的聚类中心为:cj′=cj×(1+f);其中,f表示使用的目标优化函数;cj′表示最终的第j′个聚类中心;目标优化函数为:其中,e为调节因子;w为参数隶属度矩阵,wj为参数隶属度矩阵中的第j个元素即聚类后的第j个初始病症簇;r(xi″,wj)为采用深度学习对第j个初始病症簇中的第i″个数据进行特征学习得到的新特征;gi″(r(xi″,wj))为对r(xi″,wj)的平方误差重构;dj为聚类的第j个初始病症簇内单个样本数据的相关系数,为聚类的第j个初始病症簇内数据的平均值;n是隶属度矩阵w中的元素个数;步骤s345a、利用患者的各检查项目指标值计算患者与每个最终的聚类中心之间的欧式距离,确定与其距离最短的最终的聚类中心,即得到患者病症。进一步的,所述gb算法的步骤如下:步骤s341b、建立初始化损失函数:对在医院的疾病诊断中出现的m个病症ai,建立集合a=[a1,a2...am]t,同时对眼科疾病的正确病症簇yi建立集合y=[y1,y2,...ym]t,每一个病症ai都有唯一的病症簇yi与之对应,i=1,2,…m;每个病症ai经过聚类分析算法之后得到的病症簇设为wi,ai∈a,为其建立集合c0=[w1,w2...wm]t,建立初始化损失函数:其中,f0(ai)表示病症ai的初始化损失函数;l(yi,wi)为病症ai的可微损失函数,l(yi,wi)=(yi-wi)2;步骤s342b、迭代生成k'个基学习器:设置进行k次迭代,当循环次数k<=k'时,k'为设定的迭代次数,循环执行a)~d),循环完成后获得最终的病症分类标准集ck:a)、依据下述公式计算实际病症集与第k-1次迭代更新的损失函数fk-1(ai)之间的残差rki:其中,fk-1(ai)表示第k次迭代前的损失函数即第k-1次迭代更新的损失函数;b)、对rki拟合一棵回归树i;c)、对i=1,2,…,m,依次线性搜索出l(yi,fk-1(ai)+ck-1)的最小值,作为经过k次迭代得到的第k次迭代更新的病症分类标准集ck,使得采用聚类分析算法得出的分类结果与正确病症簇之间的误差最小:其中,ck-1表示第k次迭代更新前的病症分类标准集即经过k-1次迭代得到的第k-1次迭代更新的病症分类标准集;经过k次迭代得到的第k次迭代更新的病症分类标准集ck即为最终分类优化所得患者病症;d)、更新损失函数f(ai):fk(ai)=fk-1(ai)+cki;fk(ai)表示第k次迭代更新后的损失函数。进一步的,所述利用apriori算法找出每种疾病病症簇对应的疾病的诊断及推荐诊疗方案,是利用apriori算法找出每种疾病病症簇与疾病诊断结果的强关联规则,以及疾病病症簇与治疗方案之间的强关联规则;采用apriori算法找出疾病病症簇与其治疗方案的关联的具体步骤如下:步骤s341c、设置所有疾病病症簇与其治疗方案的关联规则的最低置信度阈值和最低支持度阈值;步骤s342c、设ds={ds1,ds2,...dsi...dsn}为通过聚类分析算法得到的疾病病症簇,同时针对于每一种疾病病症簇,收集针对于此疾病病症的所有治疗方案,并将其归纳为治疗方案数据集ts={ts1,ts2...tsj...tsn′},疾病病症簇dsi与其治疗方案ts之间相关联的集合表示为e(dsi,ts);定义目前分析的疾病病症簇与治疗方案之间的关联规则为rix表示疾病病症簇dsi与其治疗方案数据集中tsx的对应关系,riy表示疾病病症簇dsi与其治疗方案数据集中tsy的对应关系,tsx∈ts,tsy∈ts,且定义关联规则的支持度为的计算公式为:其中,|e(dsi,ts)|表示疾病病症簇dsi的总治疗次数,表示疾病病症簇dsi采用治疗方案tsx和tsy的治疗次数;定义关联规则的置信度为的计算公式为:其中,表示疾病病症簇dsi采用治疗方案tsx的治疗次数;步骤s343c、生成频繁项目集:判断关联规则的置信度是否大于最小置信度阈值、关联规则的支持度是否大于最小支持度阈值,如果满足,则将满足最小支持度阈值和最小置信度阈值的所有rix、riy归入频繁项目集fi(ds,ts)={rix,riy}中;最后由频繁项目集即可得出病症与治疗方案的强关联规则;将上述采用apriori算法找出疾病病症簇与其治疗方法的关联的具体步骤中的治疗方案替换为疾病诊断结果,即可得到所述疾病病症簇与疾病诊断结果之间的强关联规则。进一步的,所述患者病情由下级医院进行会诊申请时分为重症患者、中度患者和一般患者三类;所述优先权排队算法的具体实现过程如下:步骤s341d、输入设置:设重症病患、中度病患和一般病患的申请均满足泊松分布,且相互独立,以传统医疗大数据资源得到申请率分别为λ1、λ2、λ3,且相互独立;步骤s342d、系统容量设置:设置上级医院能容纳的三类患者总量为s1+s2+s3,s1代表重症患者数量,s2代表中度患者数量,s3代表一般病情患者,当系统中三类患者的总量达到上限,系统将不再接受申请;步骤s343d、服务规则设置:设置重症患者享有比中度患者和一般患者更高的优先权,中度患者享有比一般患者更高的优先权;步骤s344d、服务过程:因三种患者的服务时间近似服从指数分布,故设重症患者的服务时间服从参数为μ1的指数分布,中度患者的服务时间服从参数为μ2的指数分布,一般患者的服务时间服从参数为μ3的指数分布,则重症患者的服务强度满足中度患者的服务强度满足一般病人的服务强度满足该远程联合诊断平台实现优先排队平稳状态的条件是ρ1+ρ2+ρ3<1,ρ1为重症患者的服务强度,ρ2为中度患者的服务强度,ρ3为一般患者的服务强度;步骤s345d、输出过程:患者申请完毕,对于疾病病症簇一致的患者,对服务强度小的优先进行服务,服务强度即为患者权值,即对患者权值小的优先进行诊断。本发明的有益效果是:基于聚类分析算法对患者病症进行分类,并采用gb算法对分类结果进行优化,确定患者疾病病症簇,提高分类准确性;依据患者病情,依据患者病情将患者分为重症病患、中度病患和一般病患三类,基于患者病情和优先排队算法对患者进行诊断排序,然后依据患者诊断顺序和疾病病症簇将患者分至对应的医生处进行会诊处理,对重症患者进行优先诊断,以免耽误病情,解决了现有诊断平台对于重症患者没有特权易耽误病情的问题。在上下级医院信息传输过程中采用改进的md5加密算法对患者信息和上级医院的回复进行加密,使诊断信息具有较强的安全性,不易被攻击破解,保护用户的信息数据安全,解决了现有诊断平台安全性保障低的问题。设定远程诊断平台中重症病患、中度病患和一般病患的申请上限,当系统中三类患者的总量达到上限,平台将不再接受申请,且通过平台的网站日志监控平台运行状况,避免用户量较大引起系统平台崩溃,解决了现有诊断平台用户量较大时易引起系统平台崩溃的问题。在得到患者的疾病病症簇后,基于apriori算法和现有医疗大数据,找出疾病病症簇与其诊断结果、治疗方案的强关联性,给出每种疾病的诊断及推荐诊疗方法,辅助医生诊断,解决了现有诊断平台不能够充分利用医学大数据智能的给出推荐诊断及治疗方案的问题。本发明的眼科远程联合诊断平台利于农村及边远地区眼病患者享有更优良的医疗资源的同时,也能大大降低看病的成本。同时,上传到平台的资料将依据深度学习算法与人工智能,在聚类分析算法下自动进行专业的整理汇总,补充到眼科大数据库,对眼科疑难疾病的发病原因、发病特点、检查结果、治疗效果是一个非常大的补充与完善,最终运用到人工智能诊断中,利于眼科未来的发展。避免了农村及边远地区患者因长途跋涉、住院预约时间长、等待看病排长队而产生的高额成本,同时提高了各医院的工作效率。本发明在眼科的疾病诊治、数据收集分类、学科发展、信息保护、看病成本效果更佳。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1是本发明联合诊断平台数据库设计用例图。图2是本发明联合诊断平台功能流程图。图3是本发明联合诊断平台信息处理流程图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。基于深度学习的上下级医院眼科远程联合诊断平台的构建方法,具体步骤如下:1、确定诊疗平台的功能;2、配置开发环境;3、平台模块实现:步骤s1、前端用户页面设计平台的前端部分主要在于前端用户界面(下级医院界面、上级医院界面与管理员界面)的设计,而下级医院界面、上级医院界面与管理员界面类似,只是有些权限功能的差别,具体实现步骤:1).创建项目目录:先创建一个总目录,然后在此目录中创建images、css、js三个目录,三个目录中分别放图片、css文件以及js文件。2).切图:通过photoshop对网页效果图进行切图,所使用图片需要是带图层的psd格式。3).界面设计:新建html文件,新建css文件,编写html和css代码,不断更改显示的界面效果步骤s2、数据库的设计和构建数据库的设计过程如下:步骤s21:围绕医院上下级联合诊断平台的功能和需求分析来确定数据库,从而用数据库来完成平台所需要的功能。下级医院向上级医院提交会诊申请,上级医院根据下级医院提交的会诊申请作出相应的回应,上下级医院之间在线互动,因此数据库要围绕医生、患者、医院、会诊申请等多个对象进行设计。步骤s22:由步骤s21中确定的所有数据库,确定联合诊断中各个实体之间的用例图,如图1所示,数据库包括患者信息表、医生信息表、医院信息表、会诊申请表、在线交流表、通知公告表、网站日志表,各表样式如下所示:表1患者信息表字段名类型是否主键说明实例idunsigner主键患者主键1namevarchar(100)患者姓名患者1id_numbervarchar(20)身份证号1122gendertinyint性别:1->男;2->女1agetinyint年龄21phonevarchar(20)联系方式10086emailvarchar(100)邮箱addressvarchar(200)住址湖南长沙ill_statetext病情描述重症narratorvarchar(100)叙述者李医生表2医生信息表字段名类型是否主键说明实例idunsigner主键主键1namevarchar(100)姓名小明gendertinyint性别男agetinyint年龄22phonevarchar(20)手机号10010emailvarchar(100)邮箱positionvarchar(100)职称博士infotext详细信息表3医院信息表字段名类型是否主键说明实例idunsigned主键主键1namevarchar(100)医院名称湘雅mastervarchar(100)院长小明phonevarchar(20)联系方式120urlvarchar(200)网址emailvarchar(100)邮箱addressvarchar(200)地址湖南长沙typevarchar(100)医院类型综合医院levelvarchar(100)医院等级三级甲等infotext详细信息roletinyint医院角色科会诊医院表4会诊申请表字段名类型是否主键说明idunsigned主键主键patient_idint患者id,外键source_user_idint送诊用户id,外键apply_typetinyint会诊类型apply_projecttinyint会诊项目apply_dateint(11)申请日期cousultation_resulttext会诊结果表5在线交流表表6通知公告表字段名类型是否主键说明idint主键主键typetinyint通知类型target_user_idint外键,接受用户titlevarchar(200)通知标题contenttext通知内容urlvarchar(200)跳转链接operationvarchar(50)操作prioritytinyint优先级statustinyint是否处理表7网页日志表字段名类型是否主键说明idint主键主键user_idvarchar(100)外键,用户idipvarchar(20)ip地址sectionvarchar(100)操作板块action_descrvarchar(100)操作详情那么可以由上述表中看到,如会诊申请表和患者信息表都会包含患者id,这就会在数据库中采取关联表形式建立。同理若有其它类似情况采取类似的操作关联。而所述的用数据库来完成平台所需要的功能,其实就是以数据库为背景,用php编写功能后,能对数据库中的信息进行相应的操作,如增加患者或删除患者之类的操作功能。步骤s23:根据步骤s22中的用例图,获得各个实体之间的关系模式,这就是要确定数据库中的表和表中的各个字段,会诊申请的各个实体即患者的各项信息,包括患者id、会诊类型、是否明确意向、会诊目的、申请会诊项目、其他申请项目、申请会诊日期、会诊结果、收费价格、是否缴费、状态、创建时间、更新时间。数据库的创建过程如下:该平台数据库的创建是直接编写的sql语句,根据逻辑设计和物理设计的结果建立数据库,编制与调试应用程序,组织数据入库,并进行试运行。数据库实施主要包括以下工作:用ddl(datadefinitionlanguage,用作开新数据表、设定字段、删除数据表、删除字段,管理所有有关数据库结构的东西)定义数据库结构、组织数据入库、编制与调试应用程序、数据库试运行。然后利用phpmyadmin创建数据库,phpmyadmin管理首页有创建数据库的入口,使用phpmyadmin直接导入创建成表格即可。步骤s3、逻辑功能实现:以php技术为基础,利用软件开发的相关应用知识,利用thinkphp框架开发出上下级医院远程联合诊断平台联合会诊功能,构建流程如图2所示。基于深度学习的上下级医院眼科远程联合诊断平台,包括:用户登录及身份验证界面,用于用户登录,并通过验证码及用户身份关键字验证判断用户身份,依据用户身份赋予用户相应权限(上级医院处理会诊申请的权限,下级医院进行会诊申请的权限,管理员查看日志等的权限),用户身份包括上级医院、下级医院和管理员。下级医院处理模块,用于下级医院提交会诊申请、发送患者信息,并接收上级医院的会诊回复,其由会诊申请模块、下级在线互动模块、下级信息加密模块和下级信息解密模块组成。会诊申请模块,用于添加患者信息,提交下级会诊申请,并选择是否需要在线互动。下级在线互动模块,用于编辑下级医院与上级医院间的互动信息。下级信息加密模块,基于md5加密算法对患者信息及互动信息进行加密处理,并发送加密处理后的患者信息及互动信息,使患者信息具有较强的安全性,不易被攻击破解,保护用户的信息数据安全。下级信息解密模块,用于接收上级医院的诊断回复及互动信息,并对其进行解密。上级医院处理模块,用于上级医院接收患者信息、对患者进行排队诊断、并发送诊断回复,其由上级信息解密模块、上级医院在线互动模块、会诊申请处理模块、分类推荐模块、上级信息加密模块组成。上级信息解密模块,用于接收加密处理后的患者信息及互动信息,并与下级医院加密模块采用同一密钥,对接收的患者信息及互动信息进行解密。会诊申请处理模块,用于依据患者信息,采用基于大数据的聚类分析算法对患者病症进行智能、高效的自动分类,下级医院在进行会诊申请时依据患者病情将患者分为重症患者、中度患者和一般患者三类,便于对该联合诊断平台的管理,从而能够很好地提高医院工作效率;并依据患者病情采用优先排队算法赋予患者权值,然后依据患者的病症和患者权值进行诊断排序,最后依据患者的诊断顺序进行诊断,并选择是否需要在线互动。上级医院在线互动模块,用于编辑上级医院与下级医院间的互动信息。分类推荐模块,基于患者的病症,利用apriori算法找出每种其诊断及推荐诊疗方案,辅助上级医院诊断及治疗。上级信息加密模块,基于md5加密算法对上级医院的诊断信息及互动信息进行加密处理,并发送加密处理后的诊断信息及互动信息,使诊断信息具有较强的安全性,不易被攻击破解,保护用户的信息数据安全。其中下级医院的会诊申请模块和上级医院的会诊申请处理模块不涉及算法,只是简单的信息填写。关键的是上级医院的信息加密解密和下级医院的信息加密解密采用的是md5加密算法,使用同一密钥,能够信息互通保护。并且为了能提高效率采用了聚类分析算法和优先排队算法。模块的具体实现如下:会诊功能:平台最关键的功能之一就是下级医院向上级医院提交会诊申请,上级医院接收到会诊申请后作出相应的回应。下级医院提交的会诊申请应该包含尽可能多的患者信息,供上级医院做出恰当的判断,如患者的视力、血压、心跳等所做的检查数据。首先通过下级医院的申请采集患者的信息,之后采用md5加密算法,将患者信息转换使其具有较强的安全性。而再通过tcp/ip协议从下级医院传输到上级医院,即信息的传输。当到达上级医院后进行采用同一密钥进行信息解密,在患者的信息解密后,平台系统将患者信息整合,进一步结合大数据的相关技术,利用聚类算法,具体通过编写map函数和reduce函数,利用mapreduce框架自动执行比较复杂的信息交换过程输出结果。这样能够对病人实现智能,高效率的分类,便于对平台的管理,从而能够很好地提高医院的效率。在平台对信息进行分类后,平台采用了优先权排队算法根据患者病情,为每位病人赋以不同的权值,然后根据权值对病人进行排队,这样就不会对病人的病情造成延误。采用gb算法提高分类准确性,在得到每种疾病的疾病病症簇后,便能够利用apriori算法找到每种疾病的对应诊断并给出推荐诊疗方案。具体实现:首先,通过扫描步骤s23医联体所建立的数据库,累计每个疾病症状的计数,并收集满足最小支持度的疾病病症簇。再对于疾病病症簇进行分析,得出频繁1项集的集合。该集合记为l1。然后,使用l1找出频繁2项集的集合l2,使用l2找出l3,如此下去,直到不能再找到频繁k项集。在获得频繁项目集l1,l2,l3之后,从这些频繁项目集中提取候选规则,利用这些规则提取疾病病症簇与疾病诊断结果与治疗方案之间的强关联规则。在医生填写患者病症时,我们通过聚类分析得到病人所属于的疾病病症簇,之后利用gb算法优化分类结果,最后通过我们的apriori算法进行机器学习,联系与疾病诊断与治疗方案推荐的强关联关系。利用疾病病症簇得出一个机器学习的诊断结果,与治疗方案,以此辅助医生治疗。上级医院在接收到智能推荐的辅助方案后,一方面在不同科室之间实行线下讨论诊断,另一方面在线上利用在线互动功能,进一步详细询问患者病情,双管齐下进行诊断。最后就是把医生确定后的诊断结果同样进行信息加密、信息传送、信息解密,最终到达下级医院。绿色通道功能考虑到某些特殊病人在进行会诊申请时,由于某些实际原因需要通过绿色通道进行会诊,因此平台在开发过程中应当充分考虑到这个问题,本平台特地在基本功能达到要求时增加了一个会诊申请的绿色通道功能,以满足某些特殊病人。上级医院在接收到绿色通道申请的会诊信息后,根据优先排队算法后所得结果,能够使特殊病人优先进行会诊,能及时为病人提供更快更好的服务,这也是医疗联合体应该逐渐完善的地方。在线互动功能本平台的另一个关键性的功能就是上下级医院之间的在线互动,并不存在患者和患者的互动功能。平台的在线互动功能是基于长连接来实现的。长连接是指在一个连接上,通信双方可以连续发送多个数据包,在连接保持期间,如果没有数据包的发送,则需要发送链路检测包对连接进行检测。上级医院针对下级医院提交的会诊申请与其进行在线沟通讨论,这样能更好的让上级医院充分了解患者的真实情况并做出相应的诊断;另外下级医院也能主动与上级医院进行直接沟通,比如进行在线咨询、联系手术等。由此可见在线互动功能的重要性。通知公告功能通知公告功能是网站上信息传播机制的一个重要组成部分,可以向所有用户显示大量的信息。本平台中,上级医院能够通过平台发布通知公告,将一些信息公开,通知的信息内容包括标题、类型、通知的用户、通知内容。通知信息的类型应该包括提醒类、公告类、警告类、错误类等。首先建立一个消息列表,表里面有是否阅读字段。而这条消息是谁发的,发给谁,表里面都需要记录,这样就可以根据每个用户的用户id去读取个人的消息。网站日志功能写一个写日志的函数,网站日志是以.log结尾的文件,记录web服务器接收和处理请求以及运行时错误等各种原始信息,具体来说是服务器日志。网站日志的最主要的作用是记录网站的相关操作,例如空间操作、访问请求的记录。通过网站网站日志,我们可以清楚地知道用户登录使用的ip地址、登录的时间、是否成功的访问了网站的哪个部分。网站网站日志的作用也是显而易见的,通过网站网站日志,可以记录访客和检测服务器端是不是能正常运行,或者是能查出平台网站存在哪些不足之处等等。模块的具体算法如下:当前存在的医联体平台中,普遍利用较为传统的加密算法,用户的密码较为容易的被破解,安全性能并没有得到很好地保障,本发明引入md5加密算法,在传统的加密算法上有了较大改进,主要在于对用户信息进行了填充,从而使消息长度增加,使分组增多,让加密的消息更不容易发生碰撞,这样被破解的概率就大大降低,尤其是当用户设置的登录密码长度超过八位时,其破解难度大大加大,很大程度的提高了平台的安全性能,保护了用户信息与数据的安全性,保证了平台中在线互动功能、通知公告功能以及网站日志功能的实现。md5加密算法是通过下述过程实现的:步骤s331、分组及填充:从前到后依次对输入的用户信息按每组信息长度为512位进行一次分组,如果分组的信息长度小于512位,则对其进行填充,填充第一位为1,其余为0,使每组信息长度为512位;步骤s332、初始化变量:md5缓存区初始化,缓冲区用来存放中间结果,将每组信息长度为512位的信息数据进行二次分组,分成h0h1...hi...h1516个小组,每个小组hi的信息长度为32位;使用128位长的缓冲区来存放中间计算结果和最终hash值,将缓冲区分为4个32位长的寄存器r0、r1、r2、r3,每个寄存器都以小端存储方式保存数据,并对4个寄存器进行初始化;步骤s333、从第一分组开始,依次对每组信息长度为512位的数据进行处理,具体处理流程如下:步骤s3331、处理分组变量,将当前信息长度为512位的分组数据的最前面128位数据即h0~h3这4个小组中的数据复制到4个32位的中间变量m、n、o、p中;步骤s3332、将中间变量m、n、o、p的值赋值给另外4个中间变量m、n、o、p,即m=m,n=n,o=o,p=p,然后任意选取m、n、o和p中的三个变量作非线性函数运算,将非线性函数运算结果加上未参与非线性函数运算的变量后左移,然后将变量m、n、o或p与左移结果相加得到最终运算结果,最后用最终运算结果替换前述与左移结果相加的变量m、n、o或p;步骤s3333、将步骤s3332中完成计算后的变量m、n、o、p的值分别赋值给中间变量m、n、o、p,即m=m,n=n,o=o,p=p,对中间变量m、n、o、p进行更新;步骤s3334、将步骤s3332~s3333循环进行16次,对该分组进行计算;步骤s3335、将该分组数据的最终运算结果的m、n、o、p的值分别存放至缓冲区寄存器中;步骤s3336、将该分组数据下一个128位数据复制到4个中间变量m、n、o、p中,循环步骤s3332~s3335,当下一个128位数据的运算结果存入缓冲区寄存器中时,上一个128位数据的运算结果将会输出;步骤s3337、将步骤s3336循环进行三次,依次对h4~h7、h8~h11、h12~h15中的数据进行运算;步骤s334、循环步骤s333,利用更新的m、n、o、p进行下一分组的计算,直至所有分组完成计算;所述将步骤s3332~s3335循环进行四次中,非线性函数运算是依次采用下述非线性函数:y1(x,y,z)=(x&y)|((~x)&z);y2(x,y,z)=(x&z)|(x&(~z));y3(x,y,z)=x∧y∧z;y4(x,y,z)=x∧(y|(~z));其中,y1~y4表示四轮非线性函数运算的结果,每个非线性函数中x、y、z对应每次任选的m、n、o、p中的三个变量;所述解密过程与md5加密算法采用同一密钥,即解密过程为md5加密算法的逆过程。4个寄存器在实际使用中的初始值设置为m=0x23456789,n=0x89fedcba,o=0xabcdef98,p=0x01234567,这些变量用于第一轮的运算。本发明md5加密算法一次进行128位数据的运算,位数的增加降低了被意外攻击破解的可能性,保证了信息传输的安全性。针对目前存在的用户量较大引起系统平台崩溃的问题,利用优先权排队算法解决这一难题,根据病人申请时的病症状况为不同的病人赋以不同的权值,然后根据权值进行排队,这样既不会耽误病重患者的病情,又能够保证平台的有秩序、高效率的进行,同时也保证了平台中会诊功能以及绿色通道功能的实现。优先权排队算法具体过程如下:由于患者申请会诊在时间上具有很大的随机性,因此该排队模块也具有一定的随机性。在将病人的病症状况分为重症、中度、一般三个等级的基础上进行:1).输入过程:设重症、中度、一般这三类病患的申请均满足泊松分布,且相互独立,以传统医疗大数据资源得到申请率分别为λ1、λ2、λ3,且相互独立。2).系统容量:医院的各项资源有限,所能容纳的三类患者总量为:s1+s2+s3(s1代表重症患者数量,s2代表中度患者数量,s3代表一般病情患者),当系统中三类患者的总量达到上限,系统将不再接受申请。3).服务规则:重症患者享有比中度患者和一般患者更高的优先权,中度患者也享有比一般患者更高的优先权。当有一个重症患者申请会诊时,他会直接跳过位于其前面的中度患者和一般患者,进入重症患者队列进行排队;同样若有一个中度患者申请会诊时,也会自动跳过位于其前面的一般患者,进入中度患者队列进行排队,但不能跳过前面的重症患者。4).服务过程:我们在经过大量的数据分析后,通过函数拟合,发现三种患者的服务时间近似服从质数分布,所以我们可以设重症患者、中度患者、一般患者的服务时间服从参数为μ1、μ2、μ3的指数分布,则重症患者的服务强度满足公式(1),中度患者的服务强度满足公式(2),一般病人的服务强度满足公式(3),实现平稳状态的条件是公式(4):ρ1+ρ2+ρ3<1(4)其中,ρ1为重症患者的服务强度,ρ2为中度患者的服务强度,ρ3为一般患者的服务强度;5).输出过程:患者申请完毕,对服务强度大的优先进行服务,服务强度即为患者权值,即对患者权值大的优先进行诊断。智能推荐模块,用于基于聚类分析法和gb算法,分析并整理每种疾病在不同时间、不同治疗阶段、不同治疗方法下的症状,并分析大规模历史医学检查数据集,对已有的医疗大数据进行分类得出疾病病症簇,采用gb算法可提高分类准确性,然后利用apriori算法找到每种疾病的对应诊断并给出推荐诊疗方案。基于大数据的聚类分析法:虽然传统的分类方法在疾病分类中被广泛使用并取得了显著的效果,但是在不同的治疗阶段根据症状可能难以对疾病进一步分类。为了更准确有效地识别疾病症状,基于大数据的聚类分析算法被引入用于患者的疾病症状聚类。本发明利用聚类分析法并结合大数据,对已有的大量医疗资源进行分类,通过对每种疾病在不同时间、不同治疗阶段、不同治疗方法下的症状进行分析整理,分析大规模历史医学检查数据集以推导疾病病症簇。在得到每种疾病的疾病病症簇后,利用apriori算法找到每种疾病的对应诊断以及给出推荐诊疗方案。基于大数据的聚类分析算法对患者病症进行分类,是采用k-means聚类分析算法和已有的医疗大数据推导患者的疾病病症簇,通过编写map函数和reduce函数,利用mapreduce框架自动执行信息交换过程,输出分类结果。基于大数据的聚类分析算法k-means具体过程如下:步骤s341a、从样本数据即医联体内的医疗大数据中随机选择k个样本作为初始聚类中心,k由医疗大数据中存在的眼科疾病类型所确定;步骤s342a、确定每个待聚类对象即剩余样本数据与每个初始聚类中心之间的相似度,依据该相似度将每个待聚类对象和与其距离最小的初始聚类中心划分在一个簇中,得到k个初始病症簇;所述每个待聚类对象与每个初始聚类中心之间的相似度采用欧氏距离公式计算,欧式距离公式为:其中xi=(xi1,xi2,…,xim),cj=(cj1,cj2,…,cjm),xim表示第i个待聚类对象的第m个检查项目指标值,cjm表示第j个初始聚类中心的第m个检查项目指标值。此处的检查项目指标值即为所做检查的结果值。样本中的检查项目指标很多,患者的检查项目指标较少,一般小于样本中的指标项目。本发明目前针对的都是数值化指标,对于其他的图像类指标不参与分类运算,一般直接发给上级医院做参考。步骤s343a、根据下式更新k个聚类中心:其中,cj是更新后的第j个聚类中心,sj是第j个初始簇中样本的集合,nj是sj中样本数据的个数,xi′表示sj中的第i′个样本数据;步骤s344a、采用交叉迭代的方法并利用目标优化函数对更新后的聚类中心的模糊位置进行微调,得到最终的聚类中心为:cj′=cj×(1+f);其中,f表示使用的目标优化函数;cj′表示最终的第j′个聚类中心;目标优化函数为:其中,e为调节因子;w为参数隶属度矩阵,wj为参数隶属度矩阵中的第j个元素即聚类后的第j个初始病症簇;r(xi″,wj)为采用深度学习对第j个初始病症簇中的第i″个数据进行特征学习得到的新特征;gi″(r(xi″,wj))为对r(xi″,wj)的平方误差重构;dj为聚类的第j个初始病症簇内单个样本数据的相关系数,为聚类的第j个初始病症簇内数据的平均值;n是隶属度矩阵w中的元素个数;步骤s345a、利用患者的各检查项目指标值计算患者与每个最终的聚类中心之间的欧式距离,确定与其距离最短的最终的聚类中心,即得到患者病症。gb(gradientboosting)算法:在之前已经利用聚类分析的算法将医疗大数据中疾病病症、疾病诊断与治疗方案分别进行了相应的分类,预处理之后以便在后面为其建立相应的关联关系。为了后面深度学习的后续进行,最重要的就是实现分类的准确性。但是我们可以看到在传统的研究中往往忽略了对于算法的优化、提升问题。因此算法的准确性往往不够精准。或者在之前的研究中引入的都是经典的adaboost算法,其只能处理采用指数损失函数的二分类学习任务,与我们所需不同。基于以上想法,本发明引入了gradientboosting算法(在下面简称为gb算法)。将gb算法应用于疾病病症、疾病诊断与治疗方案的分类机器学习任务中。在已有的学习器的基础上,采用平方误差损失函数,使得每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树。因此在每一步会重新构建一个能够沿着梯度最陡的方向降低损失(steepest-descent)的学习器来弥补已有模型的不足,从而将弱学习器提升为强学习器。因此这大大的提高了我们分类的准确性与不足性。为接下来的关联算法打基础。gb算法的步骤如下:步骤s341b、建立初始化损失函数:对在医院的疾病诊断中出现的m个病症ai,建立集合a=[a1,a2...am]t,同时对眼科疾病的正确病症簇yi建立集合y=[y1,y2,...ym]t,每一个病症ai都有唯一的病症簇yi与之对应;每个病症ai经过聚类分析算法之后得到的病症簇设为wi,ai∈a,为其建立集合c0=[w1,w2...wm]t,建立初始化损失函数:其中,f0(ai)表示病症ai的初始化损失函数;l(yi,wi)为病症ai的可微损失函数,l(yi,wi)=(yi-wi)2;步骤s342b、迭代生成k'个基学习器:设置进行k次迭代,当循环次数k<=k'时,k'为设定的迭代次数,循环执行a)~d),循环完成后获得最终的病症分类标准集ck:a)、依据下述公式计算实际病症集与第k-1次迭代更新的损失函数fk-1(ai)之间的残差rki:其中,fk-1(ai)表示第k次迭代前的损失函数即第k-1次迭代更新的损失函数;b)、对rki拟合一棵回归树i;c)、对i=1,2,…,m,依次线性搜索出的l(yi,fk-1(ai)+ck-1)最小值,作为经过k次迭代得到的第k次迭代更新的病症分类标准集ck,使得采用聚类分析算法得出的分类结果与正确病症簇之间的误差最小:其中,ck-1表示第k次迭代更新前的病症分类标准集即经过k-1次迭代得到的第k-1次迭代更新的病症分类标准集;经过k次迭代得到的第k次迭代更新的病症分类标准集ck即为最终分类优化所得患者病症;d)、更新损失函数f(ai):fk(ai)=fk-1(ai)+cki;fk(ai)表示第k次迭代更新后的损失函数。在传统的研究中往往忽略了对于算法的优化、提升问题,因此算法的准确性往往不够精准。或者在之前的研究中引入的都是经典的adaboost算法,其只能处理采用指数损失函数的二分类学习任务,与我们所需不同。基于此,我们引入了gradientboosting算法(在下面简称为gb算法),将gb算法应用于疾病病症与疾病诊断以及治疗方法的分类的机器学习任务中。在我们已有的学习器的基础上,采用平方误差损失函数,使得每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树。因此在每一步会重新构建一个能够沿着梯度最陡的方向降低损失(steepest-descent)的学习器来弥补已有模型的不足,从而将弱学习器提升为强学习器。因此这大大的提高了我们分类的准确性。本发明通过机器学习分析已归类的大数据,进行疾病诊断与治疗方案推荐,以此辅助医生治疗。在此过程中用到了apriori算法,建立疾病病症簇、疾病诊断结果与治疗方案之间的关联分析。apriori算法是经典的挖掘频繁项集和关联规则的数据挖掘算法,其使用一种称为逐层搜索的迭代方法,其中k-1项集用于探索k项集。首先,通过扫描数据库,累计每个项的计数,并收集满足最小支持度的项,找出频繁1项集的集合。该集合记为l1。然后,使用l1找出频繁2项集的集合l2,使用l2找出l3,如此下去,直到不能再找到频繁k项集。其具体步骤如下:因疾病特征和其疾病诊断关联关系分析,与疾病诊断和其治疗方案的关联关系分析的方法一致,所以在此只针对疾病诊断与其治疗方案的关联关系进行具体算法分析。步骤s341c、设置所有疾病病症簇与其治疗方案的关联规则的最低置信度阈值和最低支持度阈值;步骤s342c、设ds={ds1,ds2,...dsi...dsn}为通过聚类分析算法得到的疾病病症簇,同时针对于每一种疾病病症簇,收集针对于此疾病病症的所有治疗方案,并将其归纳为治疗方案数据集ts={ts1,ts2...tsj...tsn′},疾病病症簇dsi与其治疗方案ts之间相关联的集合表示为e(dsi,ts);定义目前分析的疾病病症簇与治疗方案之间的关联规则为rix表示疾病病症簇dsi与其治疗方案数据集中tsx的对应关系,riy表示疾病病症簇dsi与其治疗方案数据集中tsy的对应关系,tsx∈ts,tsy∈ts,且支持度(ss:fractionoftransactionsthatcontainbothxxandyy),定义关联规则的支持度为的计算公式为:其中,|e(dsi,ts)|表示疾病病症簇dsi的总治疗次数,表示疾病病症簇dsi采用治疗方案tsx和tsy的治疗次数;置信度(cc:howoftenitemsinyyappearintransactionsthatcontainxx),定义关联规则的置信度为的计算公式为:其中,表示疾病病症簇dsi采用治疗方案tsx的治疗次数;步骤s343c、生成频繁项目集:判断关联规则的置信度是否大于最小置信度阈值、关联规则的支持度是否大于最小支持度阈值,如果满足,则将满足最小支持度阈值和最小置信度阈值的所有rix、riy归入频繁项目集fi(ds,ts)={rix,riy}中。根据关于疾病诊断与其治疗方案的有关研究,经过调研实践认为应设置最小支持度为最小置信度为将所有满足最小支持度阈值和最小置信度阈值的rix、riy归入频繁项目集fi(ds,ts)={rij}中。最后由频繁项目集即可得出病症与治疗方案的强关联规则;将上述采用apriori算法找出疾病病症簇与其治疗方案的关联的具体步骤中的治疗方案替换为诊断结果,即可得到所述疾病病症簇与诊断结果之间的强关联规则。下面举出一个患者信息传送的例子来具体说明信息处理的过程,如图3所示:在下级医院向上级医院申请过程中,采用md5加密算法,将患者信息转换使其具有较强的安全性,不易被攻击破解,保护用户的信息数据安全。进一步结合大数据的相关技术,利用聚类分析算法,具体通过编写map函数和reduce函数,利用mapreduce框架自动执行比较复杂的信息交换过程输出结果,对病人的病症实现智能,高效率的分类,便于对平台的管理,从而能够很好地提高医院的效率,采用gb算法提高分类准确性。之后采用了优先权排队算法根据患者的病情,为每位病人赋以不同的权值,然后根据权值对病人进行排队,这样就不会对病人的病情造成延误。然后利用聚类分析法并结合大数据技术,对已有的大量医疗资源进行分类,通过分析每种疾病在不同时间,不同治疗阶段,不同治疗方法下的症状进行分析整理,分析大规模历史医学检查数据集以推导疾病病症簇,在得到每种疾病的病症状簇后,利用apriori算法找到每种疾病的对应诊断以及给出推荐诊疗方案。最后就是把医生确定后的诊断结果进行信息加密、信息传送、信息解密,最终到达下级医院。以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1