基于KATZ模型的代谢物与疾病关联关系预测方法与流程
本发明属于生物信息领域,具体涉及一种基于katz模型的代谢物与疾病关联关系预测方法。
背景技术:
代谢是一系列有序化学反应的统称,在维持人类生命中起着至关重要的作用,如生物体的生长和繁殖以及机体对外部环境的反应。大量的研究和实验表明,患病时候的机体与正常时的机体相比,体内的某些代谢物的浓度是不同的。因此,相关的代谢物-疾病关联关系成为了医生诊断和治疗病人的重要依据。生活中最常见的例子有很多比如糖尿病。人们谈到血糖时可能会自然而然地想到糖尿病。造成这种现象的原因是因为糖尿病患者体内的血糖浓度通常高于正常人。在过去的十年里,经过大量的实验和临床病例,血糖等浓度变化显著的代谢物逐渐成为医生诊断糖尿病的标准之一。同时也进一步的说明了代谢产物在人类疾病研究中发挥着不可或缺的作用。随着高通量代谢组学技术的发展,研究人员可以获得大量的有关代谢与疾病的宝贵信息。同时,代谢组学数据库的逐渐完善也促进了代谢组学的发展,例如hmdb数据库。然而,被证明有关系的代谢物-疾病对还只是冰山一角,还有成千上万种代谢和疾病的关联关系需要被测试和证明。传统的生物实验如果需要验证一些假设,通常需要相当长的时间才能得到结果。如果结果和假设的偏差太大,或者实验结果证明假设没有多大意义,实验者就会承担一定的损失如时间,人力,资金等。因此,发展相关的能节省实时间和资金以及提高准确率的预测方法是必不可少的。相关的预测方法在生物信息学的这几个领域中飞速发展:基因组学,如预测基因-疾病的潜在关系;转录学,如环状rna-疾病的预测;蛋白质组学,如识别关键蛋白,但在代谢组学领域上,可用来的预测方法屈指可数。
技术实现要素:
为了克服上述现有技术的缺点,本发明的目的在于提供一种基于katz模型的代谢物与疾病关联关系预测方法,本发明能够以现有的已知关系为基础,通过预测方法去挖掘潜在的代谢物与疾病关联关系。
为了达到上述目的,本发明采用以下技术方案予以实现:
基于katz模型的代谢物与疾病关联关系预测方法,包括以下步骤:
(1)将已知的代谢物与疾病关系转化为已知的代谢物与疾病网:
首先从人类代谢物数据库将已知的代谢物与疾病关系转化成一个邻接矩阵m(nd*nm),其中nd代表疾病的总个数,nm代表代谢的总个数,将对应的有关系的疾病和代谢的值设为1,否则为0。
(2)计算疾病语义相似性:
根据mesh数据库里每个疾病对应的有向无环图,计算出我们提取出的病对应的语义贡献值,进而得到任意两个疾病的语义相似性。
(3)分别计算代谢和疾病的高斯内核相似性:
根据已知的代谢物与疾病网络的拓扑特性以及相似的代谢(疾病)可能对同一疾病(代谢)有相同的或相似的作用关系的假设,分别计算出代谢高斯内核相似性及疾病高斯内核相似性。
(4)分别构建疾病和代谢相似性网络:
根据疾病的语义相似性及高斯相似性,若疾病对的语义相似性为0,则用相应的高斯核进行代替,若疾病对的语义相似性不为0,则将疾病对的语义相似性和高斯相似性按照一定的权重进行融合,得到疾病相似性矩阵sd从而构建出疾病相似性网络,另外直接通过代谢物的高斯内核相似性得到代谢物相似性矩阵sm从而构建代谢物相似性网络。
(5)通过katz模型进行代谢物与疾病关系的预测:
结合疾病相似性矩阵sd、代谢物相似性矩阵sm、已知关系矩阵m并根据各个代谢物与疾病对之间的路径数量及每条路径的长度,计算出相应代谢物与疾病对的预测的得分。分数越靠前的关系对,则潜在的关联关系较大。
(6)通过几种交叉验证的方法验证预测关系的准确度:
依次将每个已知代谢疾病关系作为测试集,则每次不作为测试集的已知关系作为训练集,未知的代谢疾病关系作为候选集。因为有4537个已知关系,所以留一验证要循环4538次。而五折和十折交叉验证是将已知关系分别的分成五份和十份,每次不重复的抽出一部分作为测试集,剩下的部分作为训练集,直到每个部分都作为测试集进行了运算,则可得到相应的评分。
(7)通过案例分析进一步检验方法的可用性:
针对某一的疾病,将步骤(5)所得到的与该疾病有关的已知代谢的预测分数删除,并将剩下的预测分数进行排序。挑出几个常见疾病并查找其排名靠前的预测关系的文献,证明预测的准确度及可用性。
进一步地,各疾病的语义贡献值由式(1)(2)得到:
其中,dv(d)代表疾病的语义相似贡献值,dd(d)代表在有向无环图中各父节点给所求节点的贡献值,d′是父节点中的子节点,dd(d′)是父节点中的子节点给所求节点的贡献值,δ是语义贡献的衰减因子;
。按(1)(2)式可得疾病间的语义相似性:
其中,dss表示疾病语义相似矩阵。dss(d(i),d(j))代表疾病i和j之间的语义相似性;t(d(i))代表包含疾病i及他所有的父节点的集合;t代表疾病i和j的共同父节点;d(i)(t),d(j)(t)分别代表父节点t对疾病i、j的贡献值;dv(d(i))dv(d(j))分别代表疾病i,j的语义相似贡献值。进一步地,步骤(4)中,疾病和代谢高斯内核相似性分别由(4)(6)式可得:
gd(d(i),d(j))=exp(-ωd||ip(d(i))-ip(d(j))||2)(4)
gd(d(i),d(j))代表疾病i,j的高斯内核相似性;ip(d(i)),ip(d(j))都是一个二元向量即已知关系矩阵m的第i,j行;ωd是控制内核带宽的参数,ω′d为ωd的初始值,通常设为1,通过(5)式进行迭代更新:
sm(m(i),m(j))=exp(-ωm||ip(m(i))-ip(m(j))||2)(6)
sm(m(i),m(j))代表代谢间的高斯内核相似性,ip(m(i)),ip(m(j))是一个二元向量,即已知关系矩阵m的第i,j列,ωm是控制内核带宽的参数,通过(7)式进行迭代更新:
其中,ω′m为ωm的初始值,通常设为1。nm代谢物的总数量。进一步地,步骤(4)中疾病两种相似性网络融合得到由疾病相似性构成的疾病相似性矩阵sd:
其中,sd(d(i),d(j))代表疾病i,j的相似性值;gd是由(4)式得到疾病高斯内核相似性;dss是由(3)式得到的疾病语义相似性。进一步地,步骤(5)中,通过使用katz模型计算得到各个代谢-疾病对的预测打分::
zk=2(m*)=δ·m+δ2·(sm·m+m·sd)(9)
zk=3(m*)=zk=2(m*)+δ3·(m·mt·m+sm2·sd+sm·m·sd+m·sd2)(10)
zk=4(m*)=zk=3(m*)+δ4·(sm3·m+m·mt·sm·m+sm·m·mt·m+m
·sd·mt·m)+δ4·(m·mt·m·sd+sm2·m·sd+sm·m·sd2+m·sd3)(11)
zk=2(m*),zk=3(m*),zk=4(m*)分别代表代谢和疾病间不同路径长度的计算方法,m表示由已知关系构成的邻接矩阵,sm表示由代谢相似性构成的代谢相似性矩阵,sd表示由疾病相似性构成的疾病相似性矩阵。
与现有技术相比,本发明具有以下有益效果:
1、本发明选择在hmdb的最新版本中提取数据作为先验知识,构建已知的代谢物与疾病关系网咯,为提高预测的准确度打下结实基础。
2、本发明在构建疾病相似性网络时,综合考虑了疾病的生物特性(语义相似性)以及拓扑特性(高斯内核相似性),多种特性的融合使得疾病相似性网络有助于提高最后的预测性能。
3、本发明根据代谢与疾病之间的路径数及路径的长度,采用katz模型在已知的代谢物与疾病关系网、疾病相似性网、代谢相似性网里进行计算打分,挖掘出潜在的代谢疾病关联关系。
4、本发明方法能准确地预测出潜在关系;通过留一验证及k-折交叉验证表明,对应的auc指标性能优于其他预测方法。
5、采用本发明能够有效地从已知关系网络中预测出新的关联关系,这些预测的新关系比起其他的未知关系来说,能给生物实验一定的导向作用,对诊断治疗疾病也具有极其重要的理论价值。
附图说明
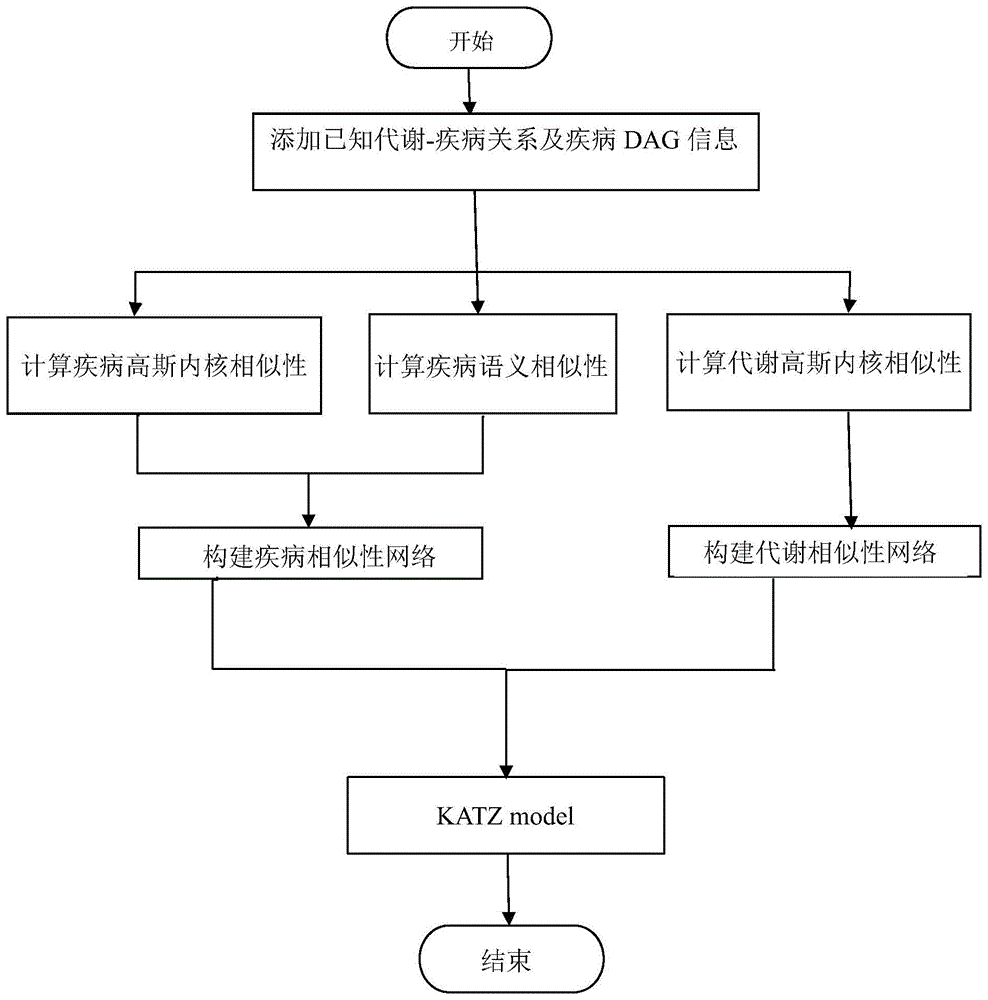
图1是本发明实施例的工艺流程图;
图2是本发明与其他预测方法的留一交叉验证的对比图;
图3是本发明与其他预测方法的5-折交叉验证的对比图;
图4是本发明与其他预测方法的10-折交叉验证的对比图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明基于katz模型进行代谢物与疾病关系的预测方法,包括以下步骤:
首先将从hmdb(人类代谢数据库)抽取的相关已知的代谢物与疾病关系转化成一个邻接矩阵m(nd*nm),其中nd代表疾病的总个数,nm代表代谢的总个数,将对应的有关系的疾病和代谢的值设为1,否则为0。
(2)计算疾病间的语义相似性:
根据mesh数据库里每个疾病对应的有向无环图(dag),计算出我们提取出的病对应的语义贡献值,进而得到任意两个疾病的语义相似性。
各疾病的语义贡献值由式(1)(2)得
dv(d)代表疾病的语义相似贡献值,dd(d)代表在有向无环图中各父节点给所求节点的贡献值,d′是父节点中的子节点,dd(d′)是父节点中的子节点给所求节点的贡献值,δ是语义贡献的衰减因子。
按(1)(2)式可得疾病间的语义相似性:
其中,dss表示疾病语义相似矩阵。dss(d(i),d(j))代表疾病i和j之间的语义相似性;t(d(i))代表包含疾病i及他所有的父节点的集合;t代表疾病i和j的共同父节点;d(i)(t),d(j)(t)分别代表父节点t对疾病i、j的贡献值;dv(d(i))dv(d(j))分别代表疾病i,j的语义相似贡献值。
(3)分别计算代谢和疾病的高斯内核相似性:
疾病和代谢高斯内核相似性分别由(4)(6)式可得:
gd(d(i),d(j))=exp(-ωd||ip(d(i))-ip(d(j))||2)(4)
gd(d(i),d(j))代表疾病间的高斯内核相似性;ip(d(i)),ip(d(j))都是一个二元向量即已知关系矩阵m的第i,j行,;ωd是控制内核带宽的参数,ω′d为ωd的初始值,通常设为1。通过(5)式进行迭代更新:
sm(m(i),m(j))=exp(-ωm||ip(m(i))-ip(m(j))||2)(6)
sm代表代谢间的高斯内核相似性矩阵;ip(m(i))是一个二元向量,ip(m(i)),ip(m(j)),是一个二元向量,即已知关系矩阵m的第i,j列。ωm是控制内核带宽的参数,ω′m为ωm的初始值,通常设为1。通过(7)式进行迭代更新:
(4)分别构建疾病和代谢相似性网络
根据疾病的语义相似性及高斯相似性,若疾病对的语义相似性为0,则用相应的高斯核进行代替,若疾病对的语义相似性不为0,则将疾病对的语义相似性和高斯相似性按照一定的权重进行融合,得到疾病相似性矩阵sd从而构建疾病相似性网络。而对于代谢相似性网络,可以直接通过代谢的高斯相似性构建。疾病相似性融合方法如式(8):
其中,sd(d(i),d(j))代表疾病i,j的相似性值;gd是由(4)式得到疾病高斯内核相似性;dss是由(3)式得到的疾病语义相似性
(5)通过katz模型进行代谢物与疾病关系的预测:
根据各个代谢物与疾病对之间的路径数量及每条路径的长度,计算出相应代谢物与疾病对的预测的得分。分数越靠前的关系对,则潜在的关联关系较大。
根据步骤(1)(4)构建的三种网及代谢与疾病间不同路径的不同长度进行预测如式(10-12):
zk=2(m*)=δ·m+δ2·(sm·m+m·sd)(9)
zk=3(m*)=zk=2(m*)+δ3·(m·mt·m+sm2·sd+sm·m·sd+m·sd2)(10)
zk=4(m*)=zk=3(m*)+δ4·(sm3·m+m·mt·sm·m+sm·m·mt·m+m
·sd·mt·m)+δ4·(m·mt·m·sd+sm2·m·sd+sm·m·sd2+m·sd3)(11)
zk=2(m*),zk=3(m*),zk=4(m*)分别代表代谢和疾病间不同路径长度的计算方法,m表示由已知关系构成的邻接矩阵,sm表示由代谢相似性构成的代谢相似性矩阵,sd表示由疾病相似性构成的疾病相似性矩阵。
(6)通过几种交叉验证的方法验证预测关系的准确度:
依次将每个已知代谢疾病关系作为测试集,则每次不作为测试集的已知关系作为训练集,未知的代谢疾病关系作为候选集。因为有4537个已知关系,所以留一验证要循环4538次。而五折和十折交叉验证是将已知关系分别的分成五份和十份,每次不重复的抽出一部分作为测试集,剩下的部分作为训练集,直到每个部分都作为测试集进行了运算,则可得到相应的评分。
(7)通过案例分析进一步检验方法的可用性:
针对某一的疾病,将步骤(5)所得到的与该疾病有关的已知代谢的预测分数删除,并将剩下的预测分数进行排序。挑出几个常见疾病并查找其排名靠前的预测关系的文献,证明预测的准确度及可用性。
以下通过具体实施例对本发明进一步详细说明:
实施例
以代谢物与疾病网络为例的一种基于katz模型进行代谢物与疾病关系的预测方法的步骤如下:
本实施例以采自hmdb最新版数据库的相关代谢数据,通过筛选去重后,得到了4537个已知关系,其中包含了216个疾病和2262个代谢物。实验平台为windows10操作系统,intel(r)core(tm)i5-8500cpu@3.00ghz处理器,8gb物理内存,用pycharm软件实现本发明的方法。
1、将从hmdb最新版数据库的相关代谢数据里抽取已知的代谢物与疾病关系转化为已知的代谢物与疾病网:
首先将已知的代谢物与疾病关系转化成一个邻接矩阵m(nd*nm),其中nd代表疾病的总个数,nm代表代谢的总个数,将对应的有关系的疾病和代谢的值设为1,否则为0。
2、计算疾病间的语义相似性:
根据mesh数据库里每个疾病对应的有向无环图(dag),计算出我们提取出的病对应的语义贡献值,进而得到任意两个疾病的语义相似性。
各疾病的语义贡献值由式(1)(2)得到:
其中,dv(d)代表疾病的语义相似贡献值,dd(d)代表在有向无环图中各父节点给所求节点的贡献值,d′是父节点中的子节点,dd(d′)是父节点中的子节点给所求节点的贡献值,δ是语义贡献的衰减因子。
按(1)(2)式可得疾病间的语义相似性:
其中,dss表示疾病语义相似矩阵。dss(d(i),d(j))代表疾病i和j之间的语义相似性;t(d(i))代表包含疾病i及他所有的父节点的集合;t代表疾病i和j的共同父节点;d(i)(t),d(j)(t)分别代表父节点t对疾病i、j的贡献值;dv(d(i))dv(d(j))分别代表疾病i,j的语义相似贡献值。
3、分别计算代谢和疾病的高斯内核相似性:
疾病和代谢高斯内核相似性分别由(4)(6)式可得:
gd(d(i),d(j))=exp(-ωd||ip(d(i))-ip(d(j))||2)(4)
gd(d(i),d(j))代表疾病间的高斯内核相似性;ip(d(i)),ip(d(j))都是一个二元向量即已知关系矩阵m的第i,j行;ωd是控制内核带宽的参数,ω′d为ωd的初始值,通常设为1。nd是疾病的总数量通过(5)式进行迭代更新:
gm(d(i),d(j))=exp(-ωm||ip(d(i))-ip(md(j))||2)(6)
sm(m(i),m(j))代表代谢间的高斯内核相似性ip(m(i)),ip(m(j)),是一个二元向量,即已知关系矩阵m的第i,j列。,ωm是控制内核带宽的参数,通过(7)
式进行迭代更新
其中,ω′m为ωm的初始值,通常设为1。nm代谢物的总数量
4、分别构建疾病和代谢相似性网络
根据疾病的语义相似性及高斯相似性,若疾病对的语义相似性为0,则用相应的高斯核进行代替,若疾病对的语义相似性不为0,则将疾病对的语义相似性和高斯相似性按照一定的权重进行融合,得到疾病相似性从而构建疾病相似性网络。而对于代谢相似性网络,可以直接通过代谢的高斯相似性构建。疾病相似性融合方法如式(8):
其中,sd(d(i),d(j))代表疾病i,j的相似性值;gd是由(4)式得到疾病高斯内核相似性;dss是由(3)式得到的疾病语义相似性进一步地,步骤(5)中,通过使用katz模型计算得到各个代谢-疾病对的预测打分。
5、通过katz模型进行代谢物与疾病关系的预测:
根据各个代谢物与疾病对之间的路径数量及每条路径的长度,计算出相应代谢物与疾病对的预测的得分。分数越靠前的关系对,则潜在的关联关系较大。
根据步骤(1)(4)构建的三种网及代谢与疾病间不同路径的不同长度进行预测如式(10-12):
zk=2(m*)=δ·m+δ2·(sm·m+m·sd)(9)
zk=3(m*)=zk=2(m*)+δ3·(m·mt·m+sm2·sd+sm·m·sd+m·sd2)(10)
zk=4(m*)=zk=3(m*)+δ4·(sm3·m+m·mt·sm·m+sm·m·mt·m+m
·sd·mt·m)+δ4·(m·mt·m·sd+sm2·m·sd+sm·m·sd2+m·sd3)(11)
zk=2(m*),zk=3(m*),zk=4(m*)分别代表代谢和疾病间不同路径长度的计算方法,m表示由已知关系构成的邻接矩阵,sm表示由代谢相似性构成的代谢相似性矩阵,sd表示由疾病相似性构成的疾病相似性矩阵。
6、通过几种交叉验证的方法验证预测关系的准确度:
依次将每个已知代谢疾病关系作为测试集,则每次不作为测试集的已知关系作为训练集,未知的代谢疾病关系作为候选集。因为有4537个已知关系,所以留一验证要循环4538次。而五折和十折交叉验证是将已知关系分别的分成五份和十份,每次不重复的抽出一部分作为测试集,剩下的部分作为训练集,直到每个部分都作为测试集进行了运算,则可得到相应的评分。
7、通过案例分析检验方法的可用性:
针对某一的疾病,将步骤(5)所得到的与该疾病有关的已知代谢的预测分数删除,并将剩下的预测分数进行排序。挑出几个常见疾病并查找其排名靠前的预测关系的文献,证明预测的准确度及可用性。
为了验证本发明的有效性,发明人利用留一交叉验证,5-折交叉验证,10交叉验证对基于katz模型进行代谢物与疾病关系的预测方法行性评估并将其与其他预测方法(rwr,pagerank)作对比(结果见图2,图3),将已知关系以相应的方式轮流作为测试集或验证集,未知关系作为候选集,在本实验中,我们抽取4537个已知关系作为先验知识,其中,在留一交叉验证中,本预测方法auc达到0.9181,而其他两种对比方法分别达到0.7633(rwr)、0.8242(pagerank);在5-折交叉验证中,本预测方法auc达到0.8897,而其他两种对比方法分别达到0.6692(rwr)、0.7951(pagerank);在10-折交叉验证中,本预测方法auc达到0.9029,而其他两种对比方法分别达到0.7266(rwr)、0.8113(pagerank);从以上三种验证方法可看出本预测方法的准确性。同时,为了检验本预测方法的可用性,本发明选取了三种常见的疾病,去掉和他们已知的代谢物的预测分数后将剩下的进行将序排序,选取各疾病的前10个预测关系,分别进行研究,发现这些预测的关系大都有理论知识支撑(详情见表1-3)。
表1.与肝疾病有关的候选代谢物
表2.与脑梗死有关的候选代谢物
表3.与妊娠糖尿病有关的候选代谢物
本发明基于katz模型的代谢物与疾病关联关系预测方法,将已知的代谢物与疾病关系转化为关系网络、计算相应的疾病、代谢的相似性、分别构建疾病和代谢相似性网络、通过katz模型进行代谢物与疾病关系的预测、通过几种交叉验证方法验证预测关系的准确度、通过案例分析进一步检验方法的可用性。本发明方法能预测出新的代谢物与疾病关系并且部分关系已经有文献验证暂未被数据库收录;验证结果表明,auc指标性能较优;与其他关键蛋白质识别方法相比,将疾病的生物特性(语义相似性)和拓扑特性(高斯内核相似性)性融合,提高了预测方法挖掘潜在关系的准确度。
以上所述是本发明的优选实施方式,通过上述说明内容,本技术领域的相关工作人员可以在不偏离本发明技术原理的前提下,进行多样的改进和替换,这些改进和替换也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!