一种基于深度学习的快速磁共振图像重建方法与流程
本发明属于医学图像领域,涉及一种图像重建方法,特别是一种基于深度学习的快速磁共振图像重建方法。
背景技术:
磁共振成像(magneticresonanceimaging,mri)是一种重要的临床医学影像检查手段,它通过信号采集和计算处理完成成像,具有无辐射危害及多参数成像等优点,尽管mri已经广泛应用到临床诊断中,但是核磁共振扫描的速度是核磁共振成像在很多应用中的一大瓶颈,缓慢的扫描速度导致运动伪影的产生,也给动态成像带来了困难。不断提高的高精度检测定位与高分辨率成像需求,同时也对核磁共振成像提出了更高的要求,因此如何在保证图像质量的情况下提高成像速度已经成为mri技术中一个亟待解决的问题。现有的基于k空间的快速磁共振成像技术,如并行成像(parallelimaging,pi)以及半傅里叶成像(partialfourier,pf)等等已经得到了广泛的应用,它们利用k空间数据的冗余性减少采样数量从而提升采样速度。然而无论是并行成像还是半傅里叶成像,它们的加速效果都具有一定的局限性,例如,并行成像加速因子受限于并行线圈数量,而半傅里叶成像仅支持大约两倍的速度提升。如何能够提升mri重建质量和成像速度,对于mri的发展有着重要的意义。这也正是本文研究mri快速成像技术的目的。近几年来,基于深度学习的磁共振图像重建方法得到了快速的发展,这使得加速磁共振图像的获取具有很大的前景。本文就现有的基于深度学习重建方法进行改进,直接将欠采样的k空间数据作为输入,通过神经网络预测出全k空间数据,旨在为快速磁共振重建找到另一种解决方案。
技术实现要素:
本发明提供了一种基于深度学习的快速磁共振图像重建方法,以找到另一种重建磁共振图像的思路。
为了实现上述目的,本发明包括以下步骤:
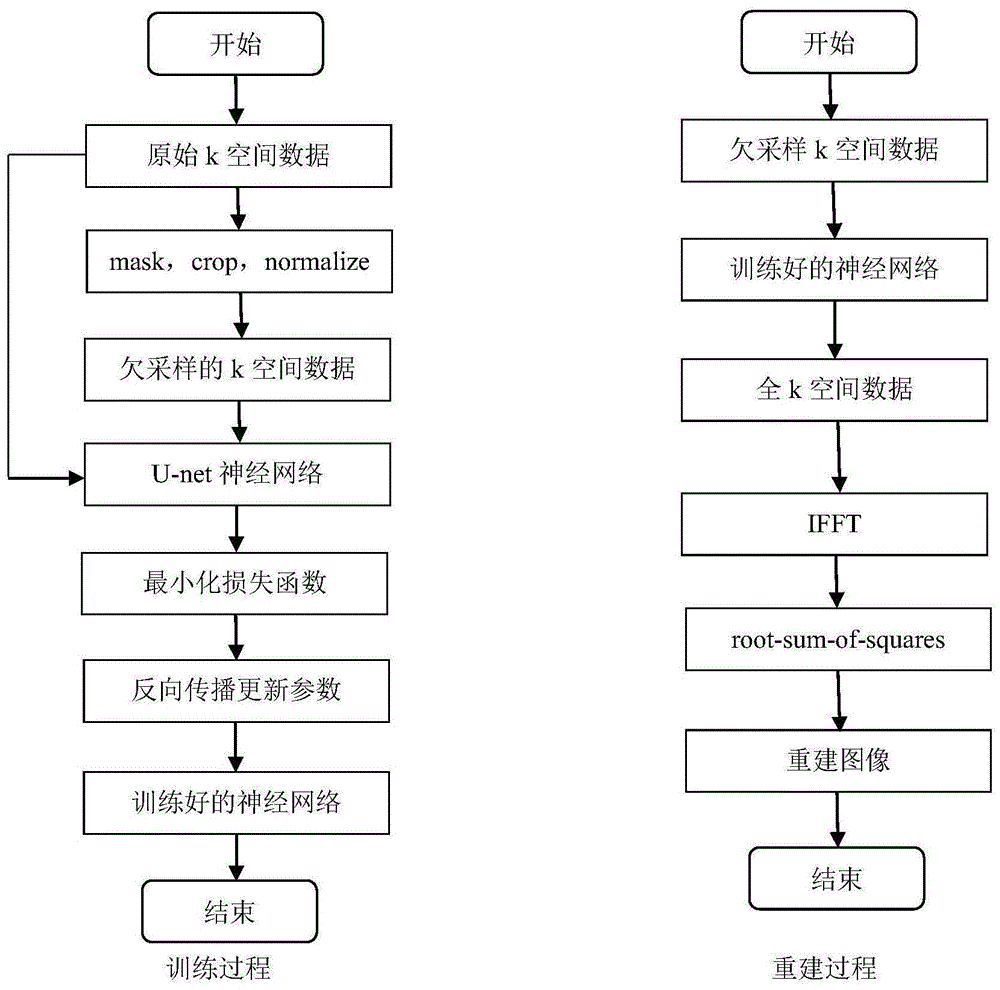
步骤(1)对k空间数据进行处理:先对训练集中的k空间数据进行掩膜处理,掩膜掉的地方采用零填充,接着进行剪裁和标准化;
步骤(2)训练神经网络:将处理好的k空间数据作为u-net网络的输入,将未处理的全采样k空间作为gt训练神经网络;
步骤(3)检测神经网络:将验证集的全采样k空间数据通过预处理输入u-net神经网络,检测神经网络的泛化能力的和过拟合情况;
步骤(4)测试结果:将测试集的欠采样k空间数据输入上述模型进行预测,得到全采样的k空间数据;
步骤(5)转化成图像:将k空间数据通过ifft转换成图像数据。
在步骤(1)中k空间数据是一个[numberofslices,h,w]包含若干切片的三维数据,我们需要对单个切片数据分别进行处理,随机生成一个与k空间数据有相同的h,w的欠采样掩码,在掩膜掉的k空间数据处用零填充,其余地方保持原始数据不变。
在步骤(1)中标准化指的是(数据-均值)/标准差,注意到k空间数据是复数,我们需要将实部和虚部分开标准化。
在步骤(2)中u-net网络是一种图形分割网络,先通过卷积核大小为3×3进行两次卷积,接着用relu函数进行修正,最后用max-pooling进行特征提取,这样循环四次之后,再通过上采样恢复到原始分辨率,为了得到更精确的输出,还将下采样的高分辨率特征与上采样相结合;将处理过后的k空间数据作为神经网络的输入,全采样的k空间数据作为gt,最小化损失函数训练神经网络。
在步骤(2)中处理过后的k空间数据维度是[batchsize,2,h,w],2是指k空间数据的实部和虚部,全采样的k空间数据作为gt,最小化损失函数训练神经网络。
在步骤(3)中验证集可以找到最优的模型并且检测神经网络的泛化能力。
在步骤(4)测试集本身就是欠采样的k空间数据,只需对其进行剪裁和标准化即可输入u-net神经网络,注意输入之前需要进行维度变换以匹配神经网络输入数据的维度,最后得到全采样的k空间数据。
在步骤(5)将k空间数据通过ifft转换为图像域,再通过根和平方函数将各个切片结合,最后可视化出来。
附图说明
图1为数据训练和重建过程
图2为待重建的欠采样磁共振图像
图3为基于深度学习的重建图像
具体实施方式
如图1所示对本发明做进一步说明,所描述的具体实施方式用来解释本发明但不仅限于本发明。
一种基于深度学习的快速磁共振图像重建方法,具体实施步骤:
步骤(1)对k空间数据进行处理:先对训练集中的k空间数据进行掩膜处理,掩膜掉的地方采用零填充,接着进行剪裁和标准化;
步骤(2)训练神经网络:将处理好的k空间数据作为u-net网络的输入,将未处理的全采样k空间作为gt训练神经网络;
步骤(3)检测神经网络:将验证集的全采样k空间数据通过预处理输入u-net神经网络,检测神经网络的泛化能力的和过拟合情况;
步骤(4)测试结果:将测试集的欠采样k空间数据输入上述模型进行预测,得到全采样的k空间数据;
步骤(5)转化成图像:将k空间数据通过ifft转换成图像数据。
在步骤(1)中k空间数据是一个[numberofslices,h,w]包含若干切片的三维数据,我们需要对单个切片数据分别进行处理,随机生成一个与k空间数据有相同的h,w的欠采样掩码,在掩膜掉的k空间数据处用零填充,其余地方保持原始数据不变。
在步骤(1)中标准化指的是(数据-均值)/标准差,注意到k空间数据是复数,我们需要将实部和虚部分开标准化。
在步骤(2)中u-net网络是一种图形分割网络,先通过卷积核大小为3×3进行两次卷积,接着用relu函数进行修正,最后用max-pooling进行特征提取,这样循环四次之后,再通过上采样恢复到原始分辨率,为了得到更精确的输出,还将下采样的高分辨率特征与上采样相结合;将处理过后的k空间数据作为神经网络的输入,全采样的k空间数据作为gt,最小化损失函数训练神经网络。
在步骤(2)中处理过后的k空间数据维度是[batchsize,2,h,w],2是指k空间数据的实部和虚部,全采样的k空间数据作为gt,最小化损失函数训练神经网络。
在步骤(3)中验证集可以找到最优的模型并且检测神经网络的泛化能力。
在步骤(4)测试集本身就是欠采样的k空间数据,只需对其进行剪裁和标准化即可输入u-net神经网络,注意输入之前需要进行维度变换以匹配神经网络输入数据的维度,最后得到全采样的k空间数据。
在步骤(5)将k空间数据通过ifft转换为图像域,再通过根和平方函数将各个切片结合,最后可视化出来。
以上具体实施方式只是用来帮助理解本发明的核心思想,对于本领域的技术人员可结合本说明书的思想对其进行延伸。
- 还没有人留言评论。精彩留言会获得点赞!