基于ADR监测报告和离群点检测技术的药物风险评估方法与流程
本发明涉及一种评估方法,具体的说是一种药物风险评估方法,属于数据挖掘
技术领域:
。
背景技术:
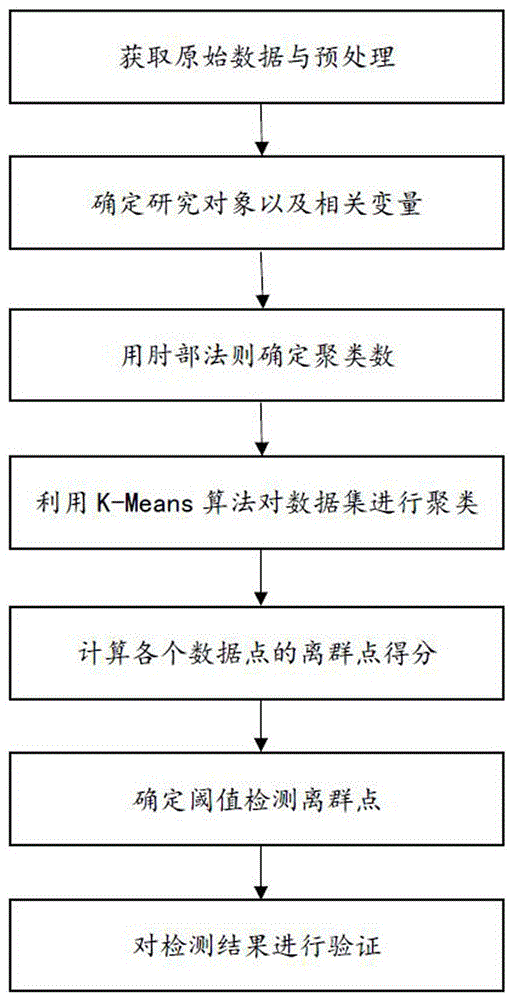
:药品在给病人治病的同时也可能带给病人与用药无关的副作用,称之为药品不良反应(adversedrugreaction,adr)。上市后药品的药物警戒是一项十分重要的工作。目前,世界各国都建立了自发报告监测系统,积累了大量的adr数据资源。但是这些数据的利用集中在传统的不良反应信号检测方法(prr、ic及mhra等)的应用研究上,主要是对常规信号的挖掘,而对罕见信号挖掘的方法却缺乏研究。这些罕见信号往往表现出一些与众不同的特点,蕴含着更加重要的信息,对药品的危害研究有着极其重要的参考价值。利用离群点检测技术进行异常信号的挖掘是具有创新性的和必要性的。在我国,药品不良反应监测报告以年百万份的量不断增加,不良反应情况也日趋复杂,给离群点检测带来困难,本发明基于我国adr监测报告,在对数据进行常规信号检测(prr、ic)的基础上,采用离群点检测技术挖掘异常信号并利用循环系统类药物进行验证方法的可靠性,以期为我国的药物警戒做出贡献。技术实现要素:本发明的目的是提供一种基于adr监测报告和离群点检测技术的药物风险评估方法,基于我国自发报告数据,利用数据挖掘技术,构建一种用于药品不良反应离群点自动识别模型,为我国的药物警戒提供一种异常信号检测方法。本发明的目的是这样实现的:一种基于adr监测报告和离群点检测技术的药物风险评估方法,包括以下步骤:步骤1)获取原始adr数据库,对数据进行预处理规整,并将原始数据库中的药品名称和不良反应名称规范化处理;步骤2)确定离群点检测研究对象以及参数:采用比例失衡方法计算每种药品-不良反应组合的prr值和ic值,以“药品-不良反应”组合作为研究对象,以prr值和ic值为特征构建空间向量模型;步骤3)利用肘部法则确定聚类数:通过计算各个簇成本函数的畸变程度之和,找到使成本函数最小化的参数k,该参数k则为最佳聚类数;步骤4)采用k-means聚类算法进行聚类:根据肘部法则确定的聚类数k随机选取k个数据点作为初始质心进行聚类迭代,直至迭代完成,聚类步骤结束;步骤5)计算所有数据点的离群点得分;步骤6)确定阈值并对各个簇进行离群点检测:根据离群点得分情况设定阈值,超出阈值的点则为离群点。作为本发明的进一步限定,步骤1具体包括:步骤1.1)获取原始adr数据库;步骤1.2)数据处理:步骤1.2.1)将原始数据库中重复的数据进行唯一化处理,缺项的数据进行删除,更新处理后的数据集为实验数据;步骤1.2.2)对实验数据中的不良反应名称按照世界卫生组织不良反应术语集进行规范。作为本发明的进一步限定,步骤2)具体包括:步骤2.1)根据每种药品发生的每种不良反应的报告数,计算四表格中a,b,c,d的数值;表2为不平衡方法中使用到的经典四格表:在表2中,a代表在报告数据库中,目标药物引起目标adr的报告数量,b代表目标药物所引起的除目标adr以外所有adr的总报告数,在数量上等于目标药物引起的所有adr减去引起目标adr的报告数量a,c代表除去目标药物外其它药物引起的目标adr的总报告数,d代表其他药物引起除目标adr外的其他adr的总报告数;步骤2.2)根据步骤2.1计算得出的a,b,c,d的值,以及每种药品-不良反应组合的prr值和ic值,各个指标的计算公式如下:其中,p(x,y)为联合概率,是指目标药物y和目标不良反应x同时出现在报告中的概率;p(x)为目标不良反应出现在报告中的概率;p(y)为目标药物出现在报告中的概率;步骤2.3)选取实验数据中循环系统用药数据作为研究对象,以“药品-不良反应”组合作为研究对象,以prr值和ic值为特征构建空间向量模型。作为本发明的进一步限定,步骤3)具体包括:步骤3.1)允许聚类数为1~10,分别计算聚类数为1~10时的簇内误差平方和sse,其公式如下:误差平方和sse的含义为各个簇中每个数据点到簇中心的距离的平方和,其中ci是第i个簇,p是ci中的数据点,mi是ci的质心(ci中所有样本点的均值);步骤3.2)随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,误差平方和sse会逐渐减小,当k值小于最佳聚类数时,由于k值的增大会大幅度增加每个簇的聚合程度,sse的下降幅度会很大,而当k值达到最佳聚类数时,再增加k值所得到的聚合程度回报会迅速减小,所以sse的下降幅度会骤减,然后随着k值的增加而趋于平缓。作为本发明的进一步限定,步骤4)具体包括:步骤4.1)根据步骤3确定的最佳聚类数k随机选取k个点作为初始质心;步骤4.2)对于数据集中的每个点,计算这些点到这k个初始质心的距离(采用欧式距离,公式如下)并将数据点根据距离划分在距离它较近的初始质心的簇中;步骤4.3)重新计算k个簇的聚类中心,采用欧式距离计算各个簇中每个数据点到该簇的原簇中心的距离,并计算均值,将该均值作为新的聚类中心;步骤4.4)重复步骤4.2和步骤4.3直至聚类中心不发生变化,聚类步骤结束。作为本发明的进一步限定,步骤5)具体包括:步骤5.1)离群点得分以距离作为评估标准,聚类后每个簇中距离较远的数据点为可疑离群点,本发明中采用欧式距离计算各个簇中每个数据点到聚类中心的距离di,并求出每个簇所有di的中位数dm;步骤5.2)将每个数据点到簇中心的距离di与簇中的距离中位数dm的比值d,即相对距离,作为每个数据点的得分。作为本发明的进一步限定,步骤6)具体包括:步骤6.1)本发明中将各个数据的离群点得分d,即相对距离作为阈值,超出阈值部分的药品-不良反应组合则为离群点,根据各个簇中的数据点的得分情况,调整阈值,检查离群点出现情况,将阈值设定为3时,检测出的离群点占总数的3%;步骤6.2)将检测出来的离群点与在中国知网及cfda(chinafoodanddrugadministration,国家食品药品监督管理总局)等网站检索到的药物警戒信息进行对比,具体情况见结果分析。本发明采用以上技术方案与现有技术相比,具有以下技术效果:本发明的步骤3至步骤6将聚类算法和离群点检测技术应用在药品不良反应研究这一新领域中,寻找药品不良反应中的异常信号,步骤6.2中将结果与权威网站发表的报告进行对比检验,绝大部分不良反应组合可被找到。附图说明图1为本发明的总体流程图。图2为本发明的肘部法则图。图3为本发明的实验结果图。具体实施方式下面结合附图对本发明的技术方案做进一步的详细说明:如图1所示的一种基于adr监测报告和离群点检测技术的药物风险评估方法:步骤1)获取原始adr数据库,并对数据进行预处理规整:步骤1.1)获取原始adr数据库,原始adr数据从江苏省药品不良反应监测中心获得,数据时间范围为2011.1.1-2018.12.31;步骤1.2)数据处理:步骤1.2.1)将原始数据库中重复的数据进行唯一化处理,缺项的数据进行删除,更新处理后的数据集为实验数据;步骤1.2.2)对实验数据中的不良反应名称按照世界卫生组织不良反应术语集进行规范,规范后的名称如表1所示:表1:不良反应名称规范步骤2)确定离群点检测研究对象以及参数:步骤2.1)根据每种药品发生的每种不良反应的报告数,计算四表格中a,b,c,d的数值;表2为不平衡方法中使用到的经典四格表:表2:四表格原理目标adr其他adr目标药物ab其他药物cd在表2中,a代表在报告数据库中,目标药物引起目标adr的报告数量。b代表目标药物所引起的除目标adr以外所有adr的总报告数,在数量上等于目标药物引起的所有adr减去引起目标adr的报告数量a。c代表除去目标药物外其它药物引起的目标adr的总报告数。d代表其他药物引起除目标adr外的其他adr的总报告数。步骤2.2)根据步骤2.1计算得出的a,b,c,d的值,以及每种药品-不良反应组合的prr值和ic值,各个指标的计算公式如下:其中,p(x,y)为联合概率,是指目标药物y和目标不良反应x同时出现在报告中的概率;p(x)为目标不良反应出现在报告中的概率;p(y)为目标药物出现在报告中的概率;步骤2.3)选取实验数据中循环系统用药数据作为研究对象,共有2577种药品-不良反应组合;以“药品-不良反应”组合作为研究对象,以prr值和ic值为特征构建空间向量模型。步骤3)利用肘部法则确定聚类数:步骤3.1)允许聚类数为1~10,分别计算聚类数为1~10时的簇内误差平方和sse,其公式如下:误差平方和sse的含义为各个簇中每个数据点到簇中心的距离的平方和,其中ci是第i个簇,p是ci中的数据点,mi是ci的质心(ci中所有样本点的均值);步骤3.2)随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,误差平方和sse会逐渐减小。当k值小于最佳聚类数时,由于k值的增大会大幅度增加每个簇的聚合程度,sse的下降幅度会很大,而当k值达到最佳聚类数时,再增加k值所得到的聚合程度回报会迅速减小,所以sse的下降幅度会骤减,然后随着k值的增加而趋于平缓,如图2所示;图像中拐点出现的数值则为聚类效果达到最好时的聚类数,也就是最佳聚类数,在本发明中,拐点出现的的数值为3,说明聚类效果最好时的聚类数为3类。步骤4)采用k-means聚类算法进行聚类:步骤4.1)根据步骤3确定的最佳聚类数k随机选取k个点作为初始质心;步骤4.2)对于数据集中的每个点,计算这些点到这k个初始质心的距离(采用欧式距离,公式如下)并将数据点根据距离划分在距离它较近的初始质心的簇中;步骤4.3)重新计算k个簇的聚类中心:采用欧式距离计算各个簇中每个数据点到该簇的原簇中心的距离,并计算均值,将该均值作为新的聚类中心;步骤4.4)重复步骤4.2和步骤4.3直至聚类中心不发生变化,聚类步骤结束。步骤5)计算所有数据点的离群点得分;步骤5.1)离群点得分以距离作为评估标准,聚类后每个簇中距离较远的数据点为可疑离群点,本发明中采用欧式距离计算各个簇中每个数据点到聚类中心的距离di,并求出每个簇所有di的中位数dm;步骤5.2)将每个数据点到簇中心的距离di与簇中的距离中位数dm的比值d,即相对距离,作为每个数据点的得分。步骤6)确定阈值并对各个簇进行离群点检测:步骤6.1)本发明中将各个数据的离群点得分d,即相对距离作为阈值,超出阈值部分的药品-不良反应组合则为离群点,根据各个簇中的数据点的得分情况,调整阈值,检查离群点出现情况,将阈值设定为3时,检测出的离群点占总数的3%;步骤6.2)将检测出来的离群点与在中国知网及cfda(chinafoodanddrugadministration,国家食品药品监督管理总局)等网站检索到的药物警戒信息进行对比,具体情况见结果分析。结果分析根据上述步骤进行实验,并且将离群点检测的输出结果进行可视化,如图3所示,其中,横坐标为2577个离群点的编号,纵坐标为每个数据点的相对距离即离群点得分d,绿色圆点表示当阈值设定为3时的常规信号,红色加号表示检测出的离群点,此时,离群点占数据总数的3%左右。离群点检测具体情况如表3所示,数据库中循环系统药物共2577种药品-不良反应组合,采用该方法检测出的离群点共83个,其中,0类中共1373个数据点,包含离群点25个;1类中共506个数据点,包含离群点34个;2类中共698个数据点,包含离群点24个;可以观察到,本次实验选定的聚类数为3,三类中检测出的离群点都有一定的规律:2类中prr值和ic值普遍都非常的小且ic值都为负;1类中的数据点prr值无明显特征而ic值相对较大;0类中的数据点prr值明显偏大且ic值都为负。其中,苯扎贝特-横纹肌溶解、瑞舒伐他汀-低密度脂蛋白升高、阿托伐他汀-中风、瑞舒伐他汀-代谢紊乱、非洛地平-过敏样反应、氨氯地平-动脉粥样硬化、卡托普利-咳嗽、银杏达莫-腹泻、前列地尔-静脉炎、依那普利-咳嗽、吲达帕胺-低钾血症、美托洛尔-心律失常、非诺贝特-横纹肌溶解、瑞舒伐他汀-血胆固醇降低、瑞舒伐他汀-胆固醇升高、瑞舒伐他汀-血胆固醇升高、美托洛尔-房室传导阻滞、美托洛尔-心肌缺血、硝苯地平-血管舒张、卡托普利-呼吸困难、瑞舒伐他汀-血脂异常、氯沙坦-蛋白、胺碘酮-甲状腺功能亢进、瑞舒伐他汀-横纹肌溶解、复方卡托普利-咳嗽、重组人脑利钠肽-低血压、胺碘酮-硬结、氟伐他汀-肝功能异常、辛伐他汀-横纹肌溶解、卡托普利-味觉异常、单硝酸异山梨酯-心肌梗死在中国知网上有相关不良反应报告记录;地高辛-血药浓度增高、吉非贝齐-肌痛、辛伐他汀-肌病、瑞舒伐他汀-肌酸磷酸激酶升高在cfda中有相关不良反应记录;复方硫酸双肼屈嗪-夜尿增多、拉西地平-皮肤充血、阿罗洛尔-外周水肿、比索洛尔-心动过缓、依那普利-呼吸系统反应、去甲肾上腺素-紫绀、复方利血平-鼻塞、贝那普利-咳嗽、复方利血平-大便次数增加、胺碘酮-甲状旁腺功能减退、复方利血平-胃酸过多、前列地尔-浅表血栓性静脉炎、培哚普利-恶心、前列地尔-腹部不适、非洛地平-寒战、复方利血平-瘙痒、卡前列素-皮疹可在药品说明书中找到不良反应说明;而对于未查到具体案例报告的不良反应,如厄贝沙坦-脑血管病、前列地尔-血管炎、瑞舒伐他汀-低密度脂蛋白降低等不良反应,在数据库中出现相应的案例,但是在相关网站及说明书中上并未找到相关病例报道或说明,这种药品-不良反应组合在以后的研究中应当引起药厂以及医生们的注意。表3:离群点检测结果以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1