一种构建AI慢性肾病筛查模型的方法、慢性肾病筛查方法及系统与流程
本发明涉及一种慢性肾病筛查方法及系统,具体涉及到机器学习方法构建慢性肾病筛查模型,慢性肾病筛查评估方法及系统,采用该模型、评估方法及系统对体检人员的医学特征指标进行筛查,给出慢性肾病风险评估值,从而实现高效、低成本、高准确率的慢性肾病筛查。
背景技术:
慢性肾病具有患病率高、知晓率低、预后差和医疗费用高等特点,是继心脑血管疾病、糖尿病和恶性肿瘤之后,又一严重危害人类健康的疾病。近年来随着我国人口老龄化程度、糖尿病和高血压等疾病发病率逐年增高,慢性肾病患病率也逐年上升。我国18岁以上人群慢性肾病患病率为10.8%,而知晓率还不足5%。因此亟需一个有效慢性肾病筛查系统进行早期慢性肾病普查,提高知晓率,利于慢性肾病的早发现早治疗,防止肾功能的不断恶化,减轻其给个人、家庭和社会带来的经济负担。目前慢性肾病筛查需要检查者在医院进行检查,由肾内科医生结合临床指南与实践经验判断,这样不利于进行高效普查。
技术实现要素:
为了解决上述技术问题本发明提出一种ai慢性肾病筛查方法,包括如下步骤:
步骤s1,建立有效慢性肾病筛查模型;
步骤s2,整理待筛查用户数据;
步骤s3,将待筛查用户数据代入慢性肾病筛查模型进行模型计算,最终得到肾脏病风险预测结果。
建立有效慢性肾病筛查模型包括如下步骤:
步骤s11:准备病历数据;从医院电子病历平台采集患者电子病历,搜集诊断结果为慢性肾病患者与非慢性肾病患者的电子病例;
所述诊断结果为慢性肾病患者电子病历采集方法为:将电子病历中医师诊断结果与慢性肾病疾病名称数据库中的疾病名称进行比对,得到慢性肾病患者电子病历;
所述非慢性肾病患者的电子病例采集方法为,同期在内科接收的患者以及体检人员的数据,排除病史不清和检验检查数据不全,以及合并有急性病、严重的感染或者肿瘤患者电子病例;所述病例数据包括病程记录、检查检验结果、医嘱、手术记录、护理记录、真实的诊断结果,所述检查检验结果包括医学特征及阈值;
得到合格的电子病例数据;
所述慢性肾病疾病名称数据库包含可以判断为慢性肾病的各种医学疾病名称。
步骤s12:医学特征提取的步骤;对步骤s11中得到的合格的电子病例数据进行慢性肾病医学特征提取,提取医学特征及医学特征值;所述慢性肾病医学特征包括基本信息、既往史、家族史、主观症状、血液检查、尿液检查类。
基本信息表包括:性别、年龄、身高、体重、血压、孕否、职业7个具体特征字段;
既往史表包括:糖尿病、高血压、吸烟史、饮酒史4个具体特征字段;
家族史表包括:慢性肾病、糖尿病、高血压、肾囊肿、多囊肾5个具体特征字段;
主观症状表包括:抽搐、多尿、恶心、发热、乏力、关节痛、口干、尿急、尿痛、呕吐、皮疹、肉眼可见血尿、上呼吸道感染、少尿、食欲不振、水肿、头痛、头晕、无尿、小便泡沫多、胸闷、眼干、腰痛、子痫24个具体特征字段;
血液检查表包括:血c反应蛋白、血白细胞计数、血红蛋白、血红细胞计数、血糖、血小板、血乙肝e抗体、血乙肝e抗原、血乙肝表面抗体、血乙肝表面抗原、血乙肝核心抗体、血丙肝抗体、血沉、血乳酸脱氢酶、血白蛋白、血谷草转氨酶、血谷丙转氨酶、血总蛋白、血总胆红素、血总胆固醇、血甘油三酯、血肌酐、血尿酸、血尿素氮、血钾、血钠、血钙、血磷、血氯、血胱抑素c、抗中性粒细胞胞浆抗体、补体c4、补体c3、补体c2、补体c1q、免疫球蛋白a、免疫球蛋白e、免疫球蛋白g、免疫球蛋白m,39个具体特征字段;
尿液检查表包括:尿白细胞、尿比重、尿胆红素、尿蛋白、尿红细胞、尿肌酐、尿潜血、尿酮体、尿微量白蛋白、尿管型、尿白蛋白、尿ph值、尿胆原、尿亚硝酸盐、尿葡萄糖、镜下血尿、尿渗透压、尿钠、24小时尿量、24小时尿蛋白定量20个具体特征字段;
所述医学特征值为基本信息、既往史、家族史、主观症状、血液检查、尿液检查特征中各个医学特征的具体数值。
得到肾病临床表现的大数据资料。
步骤s13:特征数据标准化及数据清洗的步骤。对步骤s12得到的肾病临床表现的大数据资料进行特征数据标准化,去除有缺失值的数据,得到标准数据样本,标准数据样本包括标准医学特征数据集及标准诊断结果集,标准医学特征数据集与标准诊断结果集中的数据是一一对应关系。包括如下两个步骤:
s131特征数据标准化的步骤。
建立标准库和慢性肾脏病专业数据库,采用图像识别软件对慢性肾脏病专业书籍与文献进行识别,存储到慢性肾脏病专业数据库中,同时将慢性肾脏病专业电子书籍与电子文献也存储到慢性肾脏病专业数据库中,基于慢性肾脏病专业数据库人工构建血液检查项目、尿液检查项目、症状及其他医学实体名词标准库,标准库中包含每个医学名词的标准名称及出现过的相似名称,并进行编码便于唯一标识,形成特征标准库。
对步骤s13提取的医学特征和医学特征值,将其中同一种特征不同的表述对照特征标准库进行替换,统一特征描述,得到标准化的医学特征数据。
具体的,对医学特征值的替换,主要为符号、字母、文字、单位、医学代码的替换,统一符号、字母、文字、单位、医学代码。
s132数据清洗的步骤。
对标准化后的医学特征数据,去除有缺失值的数据。针对定量资料数据采用3倍标准差法剔除错误数据;针对定性资料与等级资料数据采用统一编码法量化,形成特标准医学特征数据集。
步骤s14:特征筛选的步骤;结合肾病专家提供的肾病相关特征,与运用统计学方法对标准数据样本进行计算,筛选出来的肾病相关特征,总结出用于肾病筛查任务的流行病学、检查检验与症状特征,得到选取的医学特征数据集。
肾病专家提供的肾病相关特征为肾病专家线下提供的一种医学经验肾病相关特征表。
对标准数据样本进行计算,筛选肾病相关特征的统计学方法为t检验、卡方检验。t检验、卡方检验是统计学中常用的一种方法,属于现有技术,运用t检验、卡方检验python的计算机程序是市场上的现有的一种计算机程序,也属于现有技术。
本发明只是用了上述统计学方法及相关软件进行了计算,得到概率值p,我们设定p值小于0.05的,可以认为选取的特征与慢性肾病危险度存在极其显著的相关关系,选取这些特征建立模型是合理的。
为了便于理解,本发明以t检验为例做进一步说明,针对步骤s12中提取到的肾病临床表现的大数据资料,运用t检验、卡方检验来筛选出与慢性肾病相关的影响因素有哪些。其中,t检验是通过比较各因素的均值,研究其因素在诊断结果有无慢性肾病之间是否存在显著差异。基本前提:样本数据服从正态或近似正态分布;用于检验定量数据(白细胞、红细胞、血红蛋白等数值数据)。操作如下:
将定量数据及研究数据输入到python的程序中,通过调用scipy包,首先,对定量数据进行正态性检验,正态性检验结果,通过查看q-q图进行确认,其数据如果基本分布在直线附近,可以认为服从正态分布。然后,通过t检验得到相应的p值,将p值与显著性水平做比较,若p<0.05,拒绝原假设(h0:该因素在诊断结果有无慢性肾病之间不存在显著差异),可认为该因素在有无慢性肾病之间的差异具有统计学意义。则说明该因素在有无慢性肾病之间存在显著性的差异,进一步说明,该因素是影响有无慢性肾病的因素之一。从而在所有因素中筛选出了与慢性肾病相关的影响因素。
卡方检验原理、步骤与上述类似,但针对的数据均为定类数据(性别、尿隐血等)。
步骤s15:特征数据集拆分的步骤;
采用python的sklearn包的stratifiedshufflesplit分层分割方法将步骤s13中得到的选取的医学特征数据集分成n份,n>2;选取其中的n-1份作为模型的训练数据,剩余的一份作为模型的测试数据。
stratifiedshufflesplit分层分割方法是一种现有技术,属于python计算机程序的功能模块。
s16:训练数据得到慢性肾病筛查模型的步骤
采用python开发语言的sklearn包,选用bp神经网络、xgboost与随机森林三种算法建立集成学习分类器系统;
所述bp神经网络包括神经元权重和偏差;
所述随机森林由多个决策树构成,决策树包括多个结点,结点为医学特征及阈值;
所述xgboost包括xgboost决策树,以及xgboost决策树之间的关系;所述xgboost决策树包括多个结点,结点为医学特征及阈值;所述xgboost决策树之间的关系为梯度下降优化算法,后一棵决策树由前一棵树决策树按照梯度下降优化算法得到;
将训练数据分别经过bp神经网络算法、xgboost算法与随机森林算法计算,分别得到bp神经网络预测结果集、xgboost预测结果集与随机森林预测结果集,
将bp神经网络预测结果集、xgboost预测结果集与随机森林预测结果集合并成一个总预测结果集,总预测结果集中由预测结果值组成,预测结果值为是和否两个值组成,是代表慢性肾脏病,否代表非慢性肾脏病;采用投票法对总预测结果集进行投票,按照预测结果中是与否的数量,是与否值数量最多的胜出,从而得到慢性肾病预测结果;
还包括迭代训练的步骤:
将慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果进行比较,如果慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果不符,则对该条数据放入bp神经网络继续进行训练,调节bp神经网络中的神经元权重和偏差,最终使得慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果相符,从而得到能够判别慢性肾病的相适应的神经元权重和偏差;
同时,将该条数据放入随机森林算法继续进行训练,调整决策树结点中的医学特征及阈值,最终使得慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果相符,从而得到能够判别慢性肾病的相适应的决策树结点中的医学特征及阈值;
同时,将该条数据放入xgboost算法继续进行训练,调整xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系,最终使得慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果相符,从而得到能够判别慢性肾病的相适应的xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系;
由此,得到能够判别慢性肾病的相适应的慢性肾病筛查参数集,所述能够判别慢性肾病的相适应的慢性肾病筛查参数集包括能够判别慢性肾病的相适应的bp神经网络神经元权重和偏差,随机森林决策树结点中的医学特征及阈值,以及xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系;
由此,能够判别慢性肾病的相适应的慢性肾病筛查参数集与bp神经网络算法、xgboost算法、随机森林算法共同构成了慢性肾病筛查模型;
步骤s17:慢性肾病筛查模型测试的步骤
慢性肾病筛查模型对步骤s15中得到的测试数据进行计算,对得到的结果计算准确率、召回率和精确率,如果这三个测试指标的平均值超过了0.95,则该慢性肾病人工智能筛查模型有效;如果其平均值没有达到0.95,则进行返回步骤s16再次使用训练数据,进行算法调参,重新得到慢性肾病的相适应的慢性肾病筛查参数集,再次得到慢性肾病筛查模型;
所述准确率为在测试数据中慢性肾病筛查模型正确预测慢性肾病的数量与非慢性肾病的数量的和占测试数据总数量的比值;
所述召回率为在测试数据中慢性肾病筛查模型正确预测慢性肾病的数量占测试数据中的诊断结果为慢性肾病总数量的比值;
所述精确率为在测试数据中慢性肾病筛查模型正确预测慢性肾病的数量占慢性肾病筛查模型预测为慢性肾病总数量的比值。
s18:建立慢性肾病有效筛查模型的步骤;经过步骤s16和s17得到的准确率、精确度与召回率都超过0.95的慢性肾病筛查模型,判定为慢性肾病有效筛查模型,最终得到慢性肾病有效模型。
进一步的,步骤s2整理待筛查用户数据;医院或体检中心提供待筛查用户数据,将提供的待筛查用户数据进行数据标准化,得到标准化的待筛查用户数据,使得符合慢性肾病筛查模型数据输入的标准。
所述待筛查用户数据为医院或体检中心检查所得到的待筛查用户的医学特征数据。
步骤s3,将标准化的待筛查用户数据输入慢性肾病筛查模型进行模型计算,最终得到肾脏病风险预测结果。进一步的,将标准化的待筛查用户数据输入慢性肾病筛查模型的方式为导入,或批量导入,或输入。
本发明还提出一种构建ai慢性肾病筛查模型的方法,包括如下步骤:
采用python开发语言的sklearn包,选用bp神经网络、xgboost与随机森林三种模型建立集成学习分类器系统;建立得到能够判别慢性肾病的相适应的慢性肾病筛查参数集,在bp神经网络、xgboost与随机森林三种模型中对数据进行训练以及迭代训练,对慢性肾病筛查参数集进行调优,最终得到能够判别慢性肾病的相适应的慢性肾病筛查参数集,该慢性肾病筛查参数集包括能够判别慢性肾病的相适应的bp神经网络神经元权重和偏差,随机森林决策树结点中的医学特征及阈值,以及xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系;
所述bp神经网络包括神经元权重和偏差;
所述随机森林由多个决策树构成,决策树包括多个结点,结点为医学特征及阈值;
所述xgboost包括xgboost决策树,以及xgboost决策树之间的关系;所述xgboost决策树包括多个结点,结点为医学特征及阈值;所述xgboost决策树之间的关系为梯度下降优化算法,后一棵决策树由前一棵树决策树按照梯度下降优化算法得到;
将训练数据分别经过bp神经网络算法、xgboost算法与随机森林算法计算,分别得到bp神经网络预测结果集、xgboost预测结果集与随机森林预测结果集,
将bp神经网络预测结果集、xgboost预测结果集与随机森林预测结果集合并成一个总预测结果集,总预测结果集中由预测结果值组成,预测结果值为是和否两个值组成,是代表慢性肾脏病,否代表非慢性肾脏病;采用投票法对总预测结果集进行投票,按照预测结果中是与否的数量,是与否值数量最多的胜出,从而得到慢性肾病预测结果;
还包括迭代训练的步骤:
将慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果进行比较,如果慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果不符,则对该条数据放入bp神经网络继续进行训练,调节bp神经网络中的神经元权重和偏差,最终使得慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果相符,从而得到能够判别慢性肾病的相适应的神经元权重和偏差;
同时,将该条数据放入随机森林算法继续进行训练,调整决策树结点中的医学特征及阈值,最终使得慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果相符,从而得到能够判别慢性肾病的相适应的决策树结点中的医学特征及阈值;
同时,将该条数据放入xgboost算法继续进行训练,调整xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系,最终使得慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果相符,从而得到能够判别慢性肾病的相适应的xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系;
由此,得到能够判别慢性肾病的相适应的慢性肾病筛查参数集,所述能够判别慢性肾病的相适应的慢性肾病筛查参数集包括能够判别慢性肾病的相适应的bp神经网络神经元权重和偏差,随机森林决策树结点中的医学特征及阈值,以及xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系;
由此,能够判别慢性肾病的相适应的慢性肾病筛查参数集与bp神经网络算法、xgboost算法、随机森林算法共同构成了慢性肾病筛查模型;
步骤s17:慢性肾病筛查模型测试的步骤
慢性肾病筛查模型对步骤s15中得到的测试数据进行计算,对得到的结果计算准确率、召回率和精确率,如果这三个测试指标的平均值超过了0.95,则该慢性肾病人工智能筛查模型有效;如果其平均值没有达到0.95,则进行返回步骤s16再次使用训练数据,进行算法调参,重新得到慢性肾病的相适应的慢性肾病筛查参数集,再次得到慢性肾病筛查模型;
所述准确率为在测试数据中慢性肾病筛查模型正确预测慢性肾病的数量与非慢性肾病的数量的和占测试数据总数量的比值;
所述召回率为在测试数据中慢性肾病筛查模型正确预测慢性肾病的数量占测试数据中的诊断结果为慢性肾病总数量的比值;
所述精确率为在测试数据中慢性肾病筛查模型正确预测慢性肾病的数量占慢性肾病筛查模型预测为慢性肾病总数量的比值。
s18:建立慢性肾病有效筛查模型的步骤;经过步骤s16和s17得到的准确率、精确度与召回率都超过0.95的慢性肾病筛查模型,判定为慢性肾病有效筛查模型。
进一步的,本发明还提出一种ai慢性肾病筛查系统,包括慢性肾病有效筛查模型,所述慢性肾病有效筛查模型包括由bp神经网络、xgboost与随机森林三种模型建立的集成学习分类器系统,以及能够判别慢性肾病的相适应的慢性肾病筛查参数集。
有益效果
本发明采用机器学习bp神经网络、xgboost与随机森林集成算法训练慢性肾病筛查模型,能够根据身体基本测量信息、症状信息、医学检验检查信息、家族史、既往史、生活习惯等数据自动筛查出慢性肾病高危人群,其准确率高达0.96。本发明构建了机器学习的慢性肾病筛查的模型。可为广大人民群众提高肾病风险认知,为健康生活起指导作用。采用机器学习集成算法训练的模型准确率高达96%;基于云的部署方案可以实现大批量、高效率、高准确率的筛查,很大程度上节省了医疗资源。
附图说明
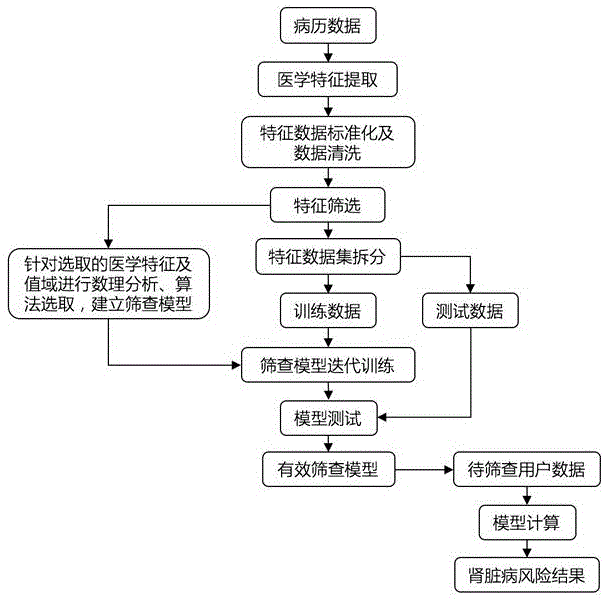
图1为本发明慢性肾病有效筛查模型构建流程及应用图。
具体实施方式
实施例1:
如图1所示,一种ai慢性肾病筛查方法,包括如下步骤:
步骤s1,建立有效慢性肾病筛查模型;
步骤s2,整理待筛查用户数据;
步骤s3,将待筛查用户数据代入慢性肾病筛查模型进行模型计算,最终得到肾脏病风险预测结果。
建立有效慢性肾病筛查模型包括如下步骤:
步骤s11:准备病历数据;从医院电子病历平台采集患者电子病历,搜集诊断结果为慢性肾病患者与非慢性肾病患者的电子病例;
所述诊断结果为慢性肾病患者电子病历采集方法为:将电子病历中医师诊断结果与慢性肾病疾病名称数据库中的疾病名称进行比对,得到慢性肾病患者电子病历;
所述非慢性肾病患者的电子病例采集方法为,同期在内科接收的患者以及体检人员的数据,排除病史不清和检验检查数据不全,以及合并有急性病、严重的感染或者肿瘤患者电子病例;所述病例数据包括病程记录、检查检验结果、医嘱、手术记录、护理记录、真实的诊断结果,所述检查检验结果包括医学特征及阈值;
得到合格的电子病例数据;
所述慢性肾病疾病名称数据库包含可以判断为慢性肾病的各种医学疾病名称。
步骤s12:医学特征提取的步骤;对步骤s11中得到的合格的电子病例数据进行慢性肾病医学特征提取,提取医学特征及医学特征值;所述慢性肾病医学特征包括基本信息、既往史、家族史、主观症状、血液检查、尿液检查类。
基本信息表包括:性别、年龄、身高、体重、血压、孕否、职业7个具体特征字段;
既往史表包括:糖尿病、高血压、吸烟史、饮酒史4个具体特征字段;
家族史表包括:慢性肾病、糖尿病、高血压、肾囊肿、多囊肾5个具体特征字段;
主观症状表包括:抽搐、多尿、恶心、发热、乏力、关节痛、口干、尿急、尿痛、呕吐、皮疹、肉眼可见血尿、上呼吸道感染、少尿、食欲不振、水肿、头痛、头晕、无尿、小便泡沫多、胸闷、眼干、腰痛、子痫24个具体特征字段;
血液检查表包括:血c反应蛋白、血白细胞计数、血红蛋白、血红细胞计数、血糖、血小板、血乙肝e抗体、血乙肝e抗原、血乙肝表面抗体、血乙肝表面抗原、血乙肝核心抗体、血丙肝抗体、血沉、血乳酸脱氢酶、血白蛋白、血谷草转氨酶、血谷丙转氨酶、血总蛋白、血总胆红素、血总胆固醇、血甘油三酯、血肌酐、血尿酸、血尿素氮、血钾、血钠、血钙、血磷、血氯、血胱抑素c、抗中性粒细胞胞浆抗体、补体c4、补体c3、补体c2、补体c1q、免疫球蛋白a、免疫球蛋白e、免疫球蛋白g、免疫球蛋白m,39个具体特征字段;
尿液检查表包括:尿白细胞、尿比重、尿胆红素、尿蛋白、尿红细胞、尿肌酐、尿潜血、尿酮体、尿微量白蛋白、尿管型、尿白蛋白、尿ph值、尿胆原、尿亚硝酸盐、尿葡萄糖、镜下血尿、尿渗透压、尿钠、24小时尿量、24小时尿蛋白定量20个具体特征字段;
所述医学特征值为基本信息、既往史、家族史、主观症状、血液检查、尿液检查特征中各个医学特征的具体数值。
得到肾病临床表现的大数据资料。
步骤s13:特征数据标准化及数据清洗的步骤。对步骤s12得到的肾病临床表现的大数据资料进行特征数据标准化,去除有缺失值的数据,得到标准数据样本,标准数据样本包括标准医学特征数据集及标准诊断结果集,标准医学特征数据集与标准诊断结果集中的数据是一一对应关系。包括如下两个步骤:
s131特征数据标准化的步骤。
建立标准库和慢性肾脏病专业数据库,采用图像识别软件对慢性肾脏病专业书籍与文献进行识别,存储到慢性肾脏病专业数据库中,同时将慢性肾脏病专业电子书籍与电子文献也存储到慢性肾脏病专业数据库中,基于慢性肾脏病专业数据库人工构建血液检查项目、尿液检查项目、症状及其他医学实体名词标准库,标准库中包含每个医学名词的标准名称及出现过的相似名称,并进行编码便于唯一标识,形成特征标准库。
对步骤s13提取的医学特征和医学特征值,将其中同一种特征不同的表述对照特征标准库进行替换,统一特征描述,得到标准化的医学特征数据。
具体的,对医学特征值的替换,主要为符号、字母、文字、单位、医学代码的替换,统一符号、字母、文字、单位、医学代码。
s132数据清洗的步骤。
对标准化后的医学特征数据,去除有缺失值的数据。针对定量资料数据采用3倍标准差法剔除错误数据;针对定性资料与等级资料数据采用统一编码法量化,形成特标准医学特征数据集。
步骤s14:特征筛选的步骤;结合肾病专家提供的肾病相关特征,与运用统计学方法对标准数据样本进行计算,筛选出来的肾病相关特征,总结出用于肾病筛查任务的流行病学、检查检验与症状特征,得到选取的医学特征数据集。
肾病专家提供的肾病相关特征为肾病专家线下提供的一种医学经验肾病相关特征表。
对标准数据样本进行计算,筛选肾病相关特征的统计学方法为t检验、卡方检验。t检验、卡方检验是统计学中常用的一种方法,属于现有技术,运用t检验、卡方检验python的计算机程序是市场上的现有的一种计算机程序,也属于现有技术。
本发明只是用了上述统计学方法及相关软件进行了计算,得到概率值p,我们设定p值小于0.05的,可以认为选取的特征与慢性肾病危险度存在极其显著的相关关系,选取这些特征建立模型是合理的。
为了便于理解,本发明以t检验为例做进一步说明,针对步骤s12中提取到的肾病临床表现的大数据资料,运用t检验、卡方检验来筛选出与慢性肾病相关的影响因素有哪些。其中,t检验是通过比较各因素的均值,研究其因素在诊断结果有无慢性肾病之间是否存在显著差异。基本前提:样本数据服从正态或近似正态分布;用于检验定量数据(白细胞、红细胞、血红蛋白等数值数据)。操作如下:
将定量数据及研究数据输入到python的程序中,通过调用scipy包,首先,对定量数据进行正态性检验,正态性检验结果,通过查看q-q图进行确认,其数据如果基本分布在直线附近,可以认为服从正态分布。然后,通过t检验得到相应的p值,将p值与显著性水平做比较,若p<0.05,拒绝原假设(h0:该因素在诊断结果有无慢性肾病之间不存在显著差异),可认为该因素在有无慢性肾病之间的差异具有统计学意义。则说明该因素在有无慢性肾病之间存在显著性的差异,进一步说明,该因素是影响有无慢性肾病的因素之一。从而在所有因素中筛选出了与慢性肾病相关的影响因素。
卡方检验原理、步骤与上述类似,但针对的数据均为定类数据(性别、尿隐血等)。
步骤s15:特征数据集拆分的步骤;
采用python的sklearn包的stratifiedshufflesplit分层分割方法将步骤s13中得到的选取的医学特征数据集分成n份,n>2;选取其中的n-1份作为模型的训练数据,剩余的一份作为模型的测试数据。
stratifiedshufflesplit分层分割方法是一种现有技术,属于python计算机程序的功能模块。
s16:训练数据得到慢性肾病筛查模型的步骤
采用python开发语言的sklearn包,选用bp神经网络、xgboost与随机森林三种算法建立集成学习分类器系统;
所述bp神经网络包括神经元权重和偏差;
所述随机森林由多个决策树构成,决策树包括多个结点,结点为医学特征及阈值;
所述xgboost包括xgboost决策树,以及xgboost决策树之间的关系;所述xgboost决策树包括多个结点,结点为医学特征及阈值;所述xgboost决策树之间的关系为梯度下降优化算法,后一棵决策树由前一棵树决策树按照梯度下降优化算法得到;
将训练数据分别经过bp神经网络算法、xgboost算法与随机森林算法计算,分别得到bp神经网络预测结果集、xgboost预测结果集与随机森林预测结果集,
将bp神经网络预测结果集、xgboost预测结果集与随机森林预测结果集合并成一个总预测结果集,总预测结果集中由预测结果值组成,预测结果值为是和否两个值组成,是代表慢性肾脏病,否代表非慢性肾脏病;采用投票法对总预测结果集进行投票,按照预测结果中是与否的数量,是与否值数量最多的胜出,从而得到慢性肾病预测结果;
还包括迭代训练的步骤:
将慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果进行比较,如果慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果不符,则对该条数据放入bp神经网络继续进行训练,调节bp神经网络中的神经元权重和偏差,最终使得慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果相符,从而得到能够判别慢性肾病的相适应的神经元权重和偏差;
同时,将该条数据放入随机森林算法继续进行训练,调整决策树结点中的医学特征及阈值,最终使得慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果相符,从而得到能够判别慢性肾病的相适应的决策树结点中的医学特征及阈值;
同时,将该条数据放入xgboost算法继续进行训练,调整xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系,最终使得慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果相符,从而得到能够判别慢性肾病的相适应的xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系;
由此,得到能够判别慢性肾病的相适应的慢性肾病筛查参数集,所述能够判别慢性肾病的相适应的慢性肾病筛查参数集包括能够判别慢性肾病的相适应的bp神经网络神经元权重和偏差,随机森林决策树结点中的医学特征及阈值,以及xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系;
由此,能够判别慢性肾病的相适应的慢性肾病筛查参数集与bp神经网络算法、xgboost算法、随机森林算法共同构成了慢性肾病筛查模型;
步骤s17:慢性肾病筛查模型测试的步骤
慢性肾病筛查模型对步骤s15中得到的测试数据进行计算,对得到的结果计算准确率、召回率和精确率,如果这三个测试指标的平均值超过了0.95,则该慢性肾病人工智能筛查模型有效;如果其平均值没有达到0.95,则进行返回步骤s16再次使用训练数据,进行算法调参,重新得到慢性肾病的相适应的慢性肾病筛查参数集,再次得到慢性肾病筛查模型;
所述准确率为在测试数据中慢性肾病筛查模型正确预测慢性肾病的数量与非慢性肾病的数量的和占测试数据总数量的比值;
所述召回率为在测试数据中慢性肾病筛查模型正确预测慢性肾病的数量占测试数据中的诊断结果为慢性肾病总数量的比值;
所述精确率为在测试数据中慢性肾病筛查模型正确预测慢性肾病的数量占慢性肾病筛查模型预测为慢性肾病总数量的比值。
s18:建立慢性肾病有效筛查模型的步骤;经过步骤s16和s17得到的准确率、精确度与召回率都超过0.95的慢性肾病筛查模型,判定为慢性肾病有效筛查模型,最终得到慢性肾病有效模型。
进一步的,步骤s2整理待筛查用户数据;医院或体检中心提供待筛查用户数据,将提供的待筛查用户数据进行数据标准化,得到标准化的待筛查用户数据,使得符合慢性肾病筛查模型数据输入的标准。
所述待筛查用户数据为医院或体检中心检查所得到的待筛查用户的医学特征数据。
步骤s3,将标准化的待筛查用户数据输入慢性肾病筛查模型进行模型计算,最终得到肾脏病风险预测结果。进一步的,将标准化的待筛查用户数据输入慢性肾病筛查模型的方式为导入,或批量导入,或输入。
实施例2:
本发明还提出一种构建ai慢性肾病筛查模型的方法,包括如下步骤:
采用python开发语言的sklearn包,选用bp神经网络、xgboost与随机森林三种模型建立集成学习分类器系统;建立得到能够判别慢性肾病的相适应的慢性肾病筛查参数集,在bp神经网络、xgboost与随机森林三种模型中对数据进行训练以及迭代训练,对慢性肾病筛查参数集进行调优,最终得到能够判别慢性肾病的相适应的慢性肾病筛查参数集,该慢性肾病筛查参数集包括能够判别慢性肾病的相适应的bp神经网络神经元权重和偏差,随机森林决策树结点中的医学特征及阈值,以及xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系;
所述bp神经网络包括神经元权重和偏差;
所述随机森林由多个决策树构成,决策树包括多个结点,结点为医学特征及阈值;
所述xgboost包括xgboost决策树,以及xgboost决策树之间的关系;所述xgboost决策树包括多个结点,结点为医学特征及阈值;所述xgboost决策树之间的关系为梯度下降优化算法,后一棵决策树由前一棵树决策树按照梯度下降优化算法得到;
将训练数据分别经过bp神经网络算法、xgboost算法与随机森林算法计算,分别得到bp神经网络预测结果集、xgboost预测结果集与随机森林预测结果集,
将bp神经网络预测结果集、xgboost预测结果集与随机森林预测结果集合并成一个总预测结果集,总预测结果集中由预测结果值组成,预测结果值为是和否两个值组成,是代表慢性肾脏病,否代表非慢性肾脏病;采用投票法对总预测结果集进行投票,按照预测结果中是与否的数量,是与否值数量最多的胜出,从而得到慢性肾病预测结果;
还包括迭代训练的步骤:
将慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果进行比较,如果慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果不符,则对该条数据放入bp神经网络继续进行训练,调节bp神经网络中的神经元权重和偏差,最终使得慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果相符,从而得到能够判别慢性肾病的相适应的神经元权重和偏差;
同时,将该条数据放入随机森林算法继续进行训练,调整决策树结点中的医学特征及阈值,最终使得慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果相符,从而得到能够判别慢性肾病的相适应的决策树结点中的医学特征及阈值;
同时,将该条数据放入xgboost算法继续进行训练,调整xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系,最终使得慢性肾病预测结果与相应患者标准诊断结果集中的诊断结果相符,从而得到能够判别慢性肾病的相适应的xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系;
由此,得到能够判别慢性肾病的相适应的慢性肾病筛查参数集,所述能够判别慢性肾病的相适应的慢性肾病筛查参数集包括能够判别慢性肾病的相适应的bp神经网络神经元权重和偏差,随机森林决策树结点中的医学特征及阈值,以及xgboost决策树结点中的医学特征、阈值,以及xgboost决策树之间的关系;
由此,能够判别慢性肾病的相适应的慢性肾病筛查参数集与bp神经网络算法、xgboost算法、随机森林算法共同构成了慢性肾病筛查模型;
步骤s17:慢性肾病筛查模型测试的步骤
慢性肾病筛查模型对步骤s15中得到的测试数据进行计算,对得到的结果计算准确率、召回率和精确率,如果这三个测试指标的平均值超过了0.95,则该慢性肾病人工智能筛查模型有效;如果其平均值没有达到0.95,则进行返回步骤s16再次使用训练数据,进行算法调参,重新得到慢性肾病的相适应的慢性肾病筛查参数集,再次得到慢性肾病筛查模型;
所述准确率为在测试数据中慢性肾病筛查模型正确预测慢性肾病的数量与非慢性肾病的数量的和占测试数据总数量的比值;
所述召回率为在测试数据中慢性肾病筛查模型正确预测慢性肾病的数量占测试数据中的诊断结果为慢性肾病总数量的比值;
所述精确率为在测试数据中慢性肾病筛查模型正确预测慢性肾病的数量占慢性肾病筛查模型预测为慢性肾病总数量的比值。
s18:建立慢性肾病有效筛查模型的步骤;经过步骤s16和s17得到的准确率、精确度与召回率都超过0.95的慢性肾病筛查模型,判定为慢性肾病有效筛查模型。
实施例3:
进一步的,本发明还提出一种ai慢性肾病筛查系统,包括慢性肾病有效筛查模型,所述慢性肾病有效筛查模型包括由bp神经网络、xgboost与随机森林三种模型建立的集成学习分类器系统,以及能够判别慢性肾病的相适应的慢性肾病筛查参数集。
- 还没有人留言评论。精彩留言会获得点赞!