病毒序列整合的优化检测方法与流程
本发明涉及病毒序列检测技术领域,特别是涉及一种病毒序列整合的优化检测方法。
背景技术:
人类的癌症中,很多癌症都是与病毒感染相关的。例如,几乎所有的宫颈癌患者都会感染人乳头瘤病毒(humanpapillomavirus,hpv),而在女性罹患的病毒感染相关的50%左右的癌症中均可以检测出hpv。又例如,在全世界范围内的肝癌患者中,74%的病例感染乙肝病毒(hepatitisbvirus,hbv)或(和)丙肝病毒(hepatitiscvirus,hcv)。
目前,主要存在三个问题阻碍了整合病毒整合算法与流程的开发。
1、由于病毒在复制过程中突变率很高,因此,在宿主体内会形成含有不同突变谱系的病毒准株。在这种情况下,病毒的参考序列很难定义。早期的研究往往在数据库中下载一条病毒序列,将其作为研究中所有样本的病毒参考序列。这种做法会在测序数据进行比对时得到欠佳的比对结果,从而造成信息的损失。再后来的一些研究会混合多条病毒序列,将其共同作为病毒参考序列。这种做法虽然可以避免之前研究的一些缺点,但是由于病毒序列之间高度的相似性,会导致序列比对软件误认为序列比对至多出,而在计算比对质量时直接输出0。这种情况的发生会导致后续的质量控制与数据处理更加复杂。针对这一现象,verse流程中针对每个样本的实际数据都会得到一条相应的最优序列。如此一来,较好的解决了上述问题。软件vifi则是结合了隐马尔科夫链算法与传统的比对方法对病毒进行了联合比对,从而提高比对的敏感度。虽然两种方法都较好的解决了这一问题,但是verse和vifi流程中对应的整合决策算法都没有很好的利用比对结果,从而造成流程的敏感度欠佳。
2、比对软件的选择问题。在既往研究中,通常是选用bwa软件对测序数据进行比对,但是bwa软件在处理一端比对至宿主(例如人)另一端比对至病毒的序列时,只会输出一端的比对结果,序列的剩余部分以软修剪(soft-clip)的方式输出。因此,早期的软件往往会将这类序列提取出来,然后使用另一种甚至更多的比对软件进行第二轮比对,从而提取相应的整合信息。但是,使用多种软件进行比对造成2个问题。首先,比对结果格式会不一致,从而给接下来的数据处理造成困难。另外,过多使用第三方软件也会导致软件在安装过程中难度增加。目前,随着bwa算法的更新换代,bwa-mem是使用较多的比对软件之一。相对于原始的bwa软件,bwa-mem可以直接输出整合序列两端的比对结果,方便后续的数据处理。virus-clip、vifi和vicaller三个软件都使用了bwa-mem,但是它们都没有充分的利用bwa-mem的输出信息。
3、很多病毒的基因组都是环状的(例如:hbv和hpv)。但是,目前很少有算法专门考虑了这一特征。通常,整合的测序序列会根据其坐标进行某种聚类,然后形成大小不同的类,代表各个整合事件。当一个类中,病毒的序列跨越了病毒的接合点(例如:跨过了hbv的最后一个碱基,然后从第1个碱基开始重新开始坐标计数),此时序列会主要分布于病毒的最末端与起始端。当然,也有一部分序列会直接跨过接合点。由测序数据合成的序列、整合事件的坐标范围以及支持整合事件的序列数量,这三者对于后面的实验验证是至关重要的。然而,在处理这类整合事件时,如果没有正确的处理会导致合成序列短、坐标范围变小以及序列数量减小,甚至影响后面的结论。
技术实现要素:
本发明针对现有技术存在的问题和不足,提供一种新型的病毒序列整合的优化检测方法。
本发明是通过下述技术方案来解决上述技术问题的:
本发明提供一种新型的病毒序列整合的优化检测方法,包括以下步骤:
s1、首先,从二代测序序列中筛选出病毒的参考序列,并将该序列作为一条染色体与宿主基因组序列合并,形成一个混合参考序列库,然后,采用bwa-mem算法将二代测序序列与混合参考序列库对比以获得sam/bam输入文件,sam/bam输入文件中的序列比对结果包括三个部分:(1)完全匹配到宿主基因组上的序列的比对结果;(2)完全匹配到病毒基因组上的序列的比对结果;(3)部分匹配到宿主基因组、部分匹配到病毒基因组的序列(即整合序列)的比对结果;
s2、从sam/bam输入文件中提取整合的序列,针对这些序列进行质量控制以过滤掉不符合预设条件中的任一条的序列;
s3、针对通过质量控制的序列,自动识别每个序列的类型;
s4、在完成整合序列类型的识别后,开始进行聚类,聚类针对宿主每条染色体、每个构象分别进行:根据宿主的整合序列坐标进行聚类,在聚类过程中坐标重复的序列会被过滤,这一步结束会得到若干个原始的类;针对每个类,根据其中病毒序列的坐标,对每个类进行精炼,若病毒序列距离太远,将二者分配至两个类中;根据每个类的宿主与病毒的坐标,将距离较近的类进一步合并;
s5、针对每一个类进行断点的决策,根据每个类中断点处的不同情况实施不同的操作,将断点归为4种类型:
a、准确的断点,类中的序列可给出准确的断点坐标;
b、同源区域,类中的宿主序列与病毒序列重合的序列中最远序列点作为断点坐标;
c、非模板序列,类中的宿主序列与病毒序列之间插入一段不明来源的序列,将不明来源序列的最前端的相邻点坐标和最远端的相邻点坐标作为断点坐标;
d、模糊的断点,类中的所有序列都无法给出准确的断点,将序列最远端的坐标作为断点坐标。
较佳地,预设条件为:1、比对结果中具有比对质量较低的序列,默认阈值为30,用户可以设置;2、序列中某部分无法比对;3、序列中某部分比对至多处;4、由双端测序序列比对结果合成的序列片段的构象异常。
较佳地,在步骤s5之后,针对同一个类,如果有证据表明多个断点可能存在,则输出多个断点,并且会对每个断点进行打分;
假设第i个类型a的序列与第j个类型b、c或者d的序列之间针对人类的距离为dhij,针对病毒的距离为dvij,同时支持断点j的序列数量为nj,则对断点j的打分公式为:
其中,若dhij+dvij=0,则ωij=1;若dhij+dvij>0,
本发明的积极进步效果在于:
1、可以充分利用比对结果,找到所有的整合序列;
2、流程合理,可以最大限度的检测出整合事件;
3、可以处理跨越环状病毒的结合点的片段;
4、可以正确的处理所有情况的断点,在无法判断断点位置真实情况的时候,可以给出预测的断点;
5、可以输出多个断点,并对每个断点排序、打分,更加符合真实情况。
附图说明
图1为本发明病毒序列整合的优化检测方法的流程图。
图2为本发明断点的4种情况示意图。
图3为本发明较佳实施例的一个跨越hbv基因组接合点的整合事件示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
本实施例提供一种病毒序列的检测与优化方法,其包括以下步骤:
s1、首先,从二代测序序列中筛选出病毒的参考序列,并将该序列作为一条染色体与宿主基因组序列合并,形成一个混合参考序列库,然后,采用bwa-mem算法将二代测序序列与混合参考序列库对比以获得sam/bam输入文件,sam/bam输入文件中的序列比对结果包括三个部分:(1)完全匹配到宿主基因组上的序列的比对结果;(2)完全匹配到病毒基因组上的序列的比对结果;(3)部分匹配到宿主基因组、部分匹配到病毒基因组的序列(即整合序列)的比对结果。
s2、从sam/bam输入文件中提取整合的序列,针对这些序列进行质量控制以过滤掉不符合预设条件中的任一条的序列。
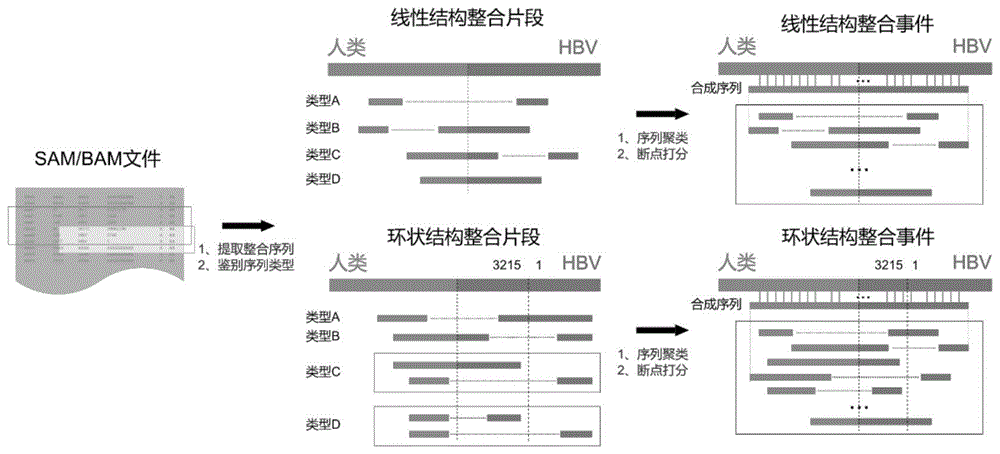
以人类宿主和hbv病毒为例,整体流程图如图1所示,输入sam/bam文件后,首先从中提取整合的序列,即比对结果一端是人、另一端是hbv的序列;然后针对这些序列进行质量控制。
凡是满足下列任何一个条件的序列都会被过滤:1、比对结果中具有比对质量较低的部分,默认阈值为30,用户可以设置;2、序列中某部分无法比对;3、序列中某部分比对至多处;4、由双端测序序列比对结果合成的序列片段的构象异常。
s3、针对通过质量控制的序列,自动识别每个序列的类型。
针对通过质控的序列,会自动识别每个测序序列的类型。按照5’至3’的方向,假设人类的序列在正链(+)上,一个整合事件的构象或方向可以分为4种:1、5’-人类(+)-hbv(+)-3’;2、5’-人类(+)-hbv(-)-3’;3、5’-hbv(+)-人类(+)-3’;4、5’-hbv(-)-人类(+)-3’。如果人类序列位于负链,则相应的构象与方向可以根据碱基互补配对与序列方向变换转化为以上4种情况。假设人端序列和hbv序列都是正链,并且人端序列位于hbv序列上游,每个双端测序的整合序列可以归为下列四类之一(图1):a、双端测序的序列一部分比对至人类,另一部分比对至hbv,两部分中间不相连;b、双端测序的序列一部分比对至人类,另一部分的比对结果分为两段,一段比对至人类,另一段比对至hbv,序列的两部分之间不相连;c、双端测序的序列一部分比对至hbv,另一部分的比对结果分为两段,一段比对至人类,另一段比对至hbv,序列的两部分之间不相连;d、序列的两部分都分别比对至人类和hbv,而且两个部分之间有重合的部分。显然,在上述4个类型中,类型b、c和d都可以指示准确的断点位置(或区域),只有类型a无法指示准确的断点。如果整合事件的hbv端具有环状片段的结构,则在识别序列的类型时,也会将序列进行归类(图1):a、双端测序的序列一部分比对至人类,另一部分比对至hbv,两部分中间不相连,但是比对至hbv的序列部分会跨过hbv接合点;b、双端测序的序列一部分比对至hbv,另一部分的比对结果分为两段,一段比对至人类,另一段也比对至hbv,两段比对至hbv的部分中间不相连,但是跨过了hbv接合点。另外还有两种情况会发生在序列聚类的过程中的两条序列上,此时一条序列比对至hbv的部分位于hbv的最末端,另一条序列比对至hbv的部分位于hbv的起始区域。根据其中的一条序列中间是否能够相连,这两种情况归类为类型c和d。
s4、在完成整合序列类型的识别后,开始进行聚类,聚类针对宿主每条染色体、每个构象分别进行:根据宿主的整合序列坐标进行聚类,在聚类过程中坐标重复的序列会被过滤,这一步结束会得到若干个原始的类;针对每个类,根据其中病毒序列的坐标,对每个类进行精炼,若病毒序列距离太远,将二者分配至两个类中;根据每个类的宿主与病毒的坐标,将距离较近的类进一步合并。
整个聚类过程分为三个步骤:1、根据宿主端的整合序列坐标进行聚类,在聚类过程中坐标重复的序列会被过滤,这一步结束会得到若干个原始的cluster(类);2、针对每个cluster,根据其中病毒序列的坐标,对每个cluster进行精炼,即如果病毒序列距离太远,将二者分配至两个cluster中;3、最后,同时根据每个cluster的宿主与病毒的坐标,将距离较近的cluster进一步合并。下面以人类和hbv为例,进行详细描述。
1、在染色体和构象相同的条件下,首先将序列按照序列给出的人端断点坐标进行排序。由于聚类开始时,当前的cluster为空,因此,直接纳入第一条序列,并记录其坐标范围。然后,从第二个序列开始,递进式的计算每条序列与当前cluster之间的距离。距离的计算过程为:假设当前cluster的起始坐标为startcluster,终止坐标为stopcluster,第i条序列的起始坐标为startri,终止坐标为stopri,这二者之间的距离定义为二者的重心坐标之差,即当前cluster与序列i的重心坐标分别为:
centroidcluster=(startcluster+stopcluster)/2,
centroidri=(startri+stopri)/2,
则二者距离为:distance(cluster,ri)=|centroidcluster-centroidri|。这一距离如果小于阈值(默认200bp),则将序列i纳入当前cluster,并更新当前cluster的坐标范围,然后针对下一条序列重复这一过程;另一方面,如果这一距离大于阈值,则当前cluster序列数量已达到最大值,会将其记录下来,然后建立一个新的空cluster,并将序列i纳入其中,之后重复上述的聚类步骤,直至遍历数据中的所有序列。
2、由于第一步是针对人类端进行的,而没有考虑hbv端各个序列之间的距离,因此,接下来会针对每个cluster中的hbv序列,重复上述的聚类过程。经过这一过程可以将一个cluster中hbv序列坐标距离较远的序列分配至不同的cluster中,从而保证每个cluster中的序列针对两个物种的距离都很近。
3、计算位于同一条染色体、构象相同的两两cluster之间的距离,合并距离较近的cluster。假设2个cluster人类部分的距离为dh,hbv部分的距离为dv,则这2个cluster会合并如果其满足以下条件:1、dh<dthreshold(human);2、dv<dthreshold(virus),其中dthreshold(human)和dthreshold(virus)是由用户设置的阈值(默认分别为1000bp和250bp)。这一步骤可以有效的避免多个cluster表示的是同一个整合事件这一情况的发生。
s5、针对每一个类进行断点的决策,根据每个类中断点处的不同情况实施不同的操作。
当完成了聚类,下一步就是针对每一个cluster进行断点的决策。根据每个cluster中断点处的不同情况实施不同的操作。将断点归为4种类型(图2):a、准确的断点。此时,cluster中的序列可以给出准确的断点,即人类的序列与hbv的序列虽然相连,但是没有重合的部分。b、同源区域。此时,cluster中的人类序列与hbv(病毒)序列有一段很短的重合序列,即同源序列。此时,虽然无法确定断点的准确位置,但是可以确定就在同源序列中,并将类中的人类序列与hbv序列重合的序列中最远序列点作为断点坐标。c、非模板序列。此时,人类序列与hbv序列之间会插入一段不明来源的序列,即非模板序列。从比对结果上来看,这段序列既不属于人类,也不属于hbv,将不明来源序列的最前端的相邻点坐标和最远端的相邻点坐标作为断点坐标。d、模糊的断点。如果cluster中的所有序列都无法给出准确的断点,此时,会根据坐标给出最有可能的断点坐标,将序列最远端的坐标作为断点坐标。
由于病毒整合现象固有的复杂性,有时会出现同一个区域出现不同整合事件的想象,而且整合事件之间的断点比较接近。为了使断点的决策与这一现象相符,针对同一个cluster,如果有证据表明多个断点可能存在,则会输出多个断点,并且会对每个断点进行打分。假设第i个类型a的序列与第j个类型b、c或者d的序列之间针对人类的距离为dhij,针对病毒的距离为dvij,同时支持断点j的序列数量为nj,则对断点j的打分公式为:
其中,若dhij+dvij=0,则ωij=1;若dhij+dvij>0,
本实施例以sam或bam文件为输入文件,自动识别序列的构象与方向,尤其是跨病毒基因组结合点的序列,并将其进行聚类,最后进行断点的决策与打分。
现通过使用hbv捕获测序数据,对cvfinder的使用加以说明,但是cvfinder适用于各类二代测序的数据,包括全基因组测序、转录组测序以及病毒捕获测序等。本次实施示例数据来源为sra数据库中样本id为srr3104810的数据。具体步骤如下:
1、使用bwa-mem进行比对
bwamemgrch38_virus.fasrr3104810_1.fastq.gzsrr3104810_2.fastq.gz>srr3104810_aln.sam
其中,grch38_virus.fa为人类基因组序列与hbv病毒优化后的参考序列混合后的文件,srr3104810_1.fastq.gz和srr3104810_2.fastq.gz为测序的原始数据,srr3104810_aln.sam为比对后的结果文件。
2、使用cvfinder检测数据中的整合事件
cvfinder.pl-fsrr3104810_aln.sam-osrr3104810_result.txt
其中,srr3104810_result.txt为cvfinder的输出文件。
结果如表1所示,展示了序列数量大于等于4的整合事件,共17个。其中8个整合事件的断点是准确的,而其余9个事件的断点是预测的。其它的输出内容详细列出了整合事件的构象与方向以及整合事件中序列的数量等信息。值得注意的是,最后一个整合事件跨越了hbv基因组的接合点(图3)。
表1、srr3104810数据中的整合事件
如图3所示,事件中hbv的坐标范围为:2868bp~3215bp,然后为1bp-52bp,其中3215bp和1bp为接合点。图中不同的碱基由不同颜色表示,其中灰色代表比对中的空位,或者代表一条序列中双端测序没有覆盖到的碱基。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这些仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!