一种区分MODY与T1D和T2D的诊断模型的制作方法
本发明属于医学诊断领域,涉及一种区分mody与t1d和t2d的诊断模型。
背景技术:
青少年发病的成人型糖尿病(maturity-onsetdiabetesoftheyoung,mody)是一种最常见的单基因糖尿病,具有发病年龄早(<25岁)、常染色体显性遗传、非肥胖、非胰岛素依赖等特点。mody约占所有糖尿病的1%-5%,在青年发病(<45岁)的糖尿病患者中所占比例更高(约5%)。迄今为止,已发现14种基因突变可致mody,其中由葡萄糖激酶(gck)基因突变导致的gck-mody(又称mody2)和由肝核因子1-α(hnf1a)基因突变导致的hnf1a-mody(又称mody3)是最常见的mody亚型,约占所有mody的90%。由于临床表型的交叉使得80%的mody被误诊为1型糖尿病(type1diabetes,t1d)或2型糖尿病(type2diabetes,t2d)。因此,患者常常接受多年不适当的治疗(包括外源性胰岛素的使用)但血糖并未得到有效控制。
mody的准确诊断具有重要意义。首先,有助于指导治疗:如mody3患者对小剂量磺酰脲类药物敏感;mody2患者很少需要药物治疗且糖尿病并发症少见。其次,有助于预后判断。再者,作为常染色体显性遗传性疾病,正确诊断可为mody患者及其亲属提供遗传学咨询,明确家系成员的糖尿病患病风险。最后,mody是糖尿病研究的天然模型,对其致病机制的深入研究将极大的推动糖尿病整体研究的发展和治疗手段的创新。
mody确诊的金标准是基因检测,但由于基因检测费用昂贵,临床研究人员在制定mody致病基因检测的入组标准方面进行了积极尝试,例如建议同时具备以下3种特征的糖尿病患者进行mody致病基因检测:1)先证者的糖尿病发病年龄<25岁;2)存在连续3代糖尿病家族史,并伴有β细胞功能障碍;3)非肥胖、非胰岛素依赖。但该筛查标准在中国人群中的敏感性仅为10-20%。随后,临床上推出了一种新的mody诊断方法,通过在互联网(www.diabetesgenes.org/content/mody-probabilitycalculator)上填写8个简单的问题,医生会获得mody的阳性预测值。此外,近期研究还发现一系列生化指标,例如高密度脂蛋白胆固醇(hdl-c),甘油三酯(tg),载脂蛋白m,超敏c反应蛋白(hscrp),mirna,1,5-脱水葡萄糖醇和血浆聚糖谱等均可作为区分mody与t1d和t2d的新的生物标志物。但这些关于mody临床和分子遗传学特征的研究绝大多数来自国外,对于遗传特征及环境因素均存在显著差异的中国人群,仍需积极探索具有中国特色的mody临床筛查标准。
用于筛选mody的现有临床标准大多基于临床指标的绝对界值(例如,非肥胖且诊断年龄<25岁),而不是同时包含连续变量(例如bmi、诊断年龄)和分类变量(例如家族史)在内的几种临床指标的组合。因此,现有临床标准敏感性不足,仅能识别少部分mody患者。以加权方式联合几种临床指标制定mody的筛查标准将有助于更加准确的识别mody患者。因此,基于大样本中国mody患者,本申请旨在建立一种临床预测模型,以达到快速有效识别中国mody患者的目的。未来也可将该临床预测模型与互联网相结合,为临床医生和患者提供线上帮助。
技术实现要素:
为解决现有技术中存在的技术问题,本发明提供了一种区分mody与t1d和t2d的临床诊断模型。本发明的诊断模型具有高敏感性和高特异性,为临床mody的诊断提供了一种有效的方法。
根据本发明的一个方面,本发明提供了一种区分mody和t1d及t2d的诊断模型,所述诊断模型中的变量包括糖尿病家族史、空腹c-肽、bmi、诊断年龄、t1d自身抗体。
优选地,所述t1d自身抗体包括ica、gad、ia2中的一个或多个。
进一步,所述诊断模型如下:诊断分值=糖尿病家族史得分+空腹c-肽得分+bmi得分+诊断年龄得分+t1d自身抗体得分。
优选地,各变量计分标准如下:
糖尿病家族史1代,得分为0;连续2代,得分为1;连续≥3代,得分为2;
空腹c-肽浓度≤0.3ng/ml或>1.0ng/ml,得分为0;处于(0.3-0.5](不包括下端点0.3,包括上端点0.5)ng/ml之间或(0.8-1.0](不包括下端点0.8,包括上端点1.0)ng/ml之间,得分为1,处于(0.5-0.8](不包括下端点0.5,包括上端点0.8)ng/ml之间,得分为2;
bmi>25kg/m2,得分为0;处于(23-25](不包括下端点23,包括上端点25)kg/m2之间,得分为1,≤23kg/m2,得分为2;
诊断年龄>40岁,得分为0;处于(25-40](不包括下端点25,包括上端点40)岁之间,得分为1;≤25岁,得分为2;
t1d自身抗体阳性数目≥2,得分为0;等于1,得分为1;等于0,得分为2;
当诊断分值≥7分,则判断受试者患有mody的可能性大。
根据本发明的另一个方面,本发明提供了一种mody2的诊断模型,所述诊断模型中的变量包括糖尿病家族史、空腹c-肽、bmi、诊断年龄、t1d自身抗体、hba1c、餐后2h血糖、hscrp、tg。
进一步,所述诊断模型如下:诊断总分=诊断分值1+诊断分值2;诊断分值1=hba1c得分+餐后2h血糖得分+hscrp得分+tg得分,诊断分值2=糖尿病家族史得分+空腹c-肽得分+bmi得分+诊断年龄得分+t1d自身抗体得分;
优选地,各变量计分标准如下:
糖尿病家族史1代,得分为0;连续2代,得分为1;连续≥3代,得分为2;
空腹c-肽浓度≤0.3ng/ml或>1.0ng/ml,得分为0;处于(0.3-0.5](不包括下端点0.3,包括上端点0.5)ng/ml之间或(0.8-1.0](不包括下端点0.8,包括上端点1.0)ng/ml之间,得分为1,处于(0.5-0.8](不包括下端点0.5,包括上端点0.8)ng/ml之间,得分为2;
bmi>25kg/m2,得分为0;处于(23-25](不包括下端点23,包括上端点25)kg/m2之间,得分为1,≤23kg/m2,得分为2;
诊断年龄>40岁,得分为0;处于(25-40](不包括下端点25,包括上端点40)岁之间,得分为1;≤25岁,得分为2;
t1d自身抗体阳性数目≥2,得分为0;等于1,得分为1;等于0,得分为2。
hba1c(%)处于[6-7](包括下端点6,包括上端点7)之间,得分为0.5;
餐后2h血糖浓度处于(3-5]mmol/l(不包括下端点3,包括上端点5)之间,得分为0.5;≤3mmol/l,得分为1;
hscrp浓度≤0.8mg/l,得分为0.5;
tg浓度≤1.0mmol/l,得分为0.5;
当诊断总分≥8,且诊断分值2≥7,诊断分值1≥1时,则判断受试者患有mody2的可能性大。
根据本发明的又一个方面,本发明提供了一种mody3的诊断模型,所述诊断模型中的变量包括糖尿病家族史、空腹c-肽、bmi、诊断年龄、t1d自身抗体、hscrp、tg、肝脏腺瘤。
进一步,所述诊断模型如下:诊断总分=诊断分值1+诊断分值2;诊断分值1=hscrp得分+tg得分+肝脏腺瘤得分,诊断分值2=糖尿病家族史得分+空腹c-肽得分+bmi得分+诊断年龄得分+t1d自身抗体得分。
优选地,各变量计分标准如下:
糖尿病家族史1代,得分为0;连续2代,得分为1;连续≥3代,得分为2;
空腹c-肽浓度≤0.3ng/ml或>1.0ng/ml,得分为0;处于(0.3-0.5](不包括下端点0.3,包括上端点0.5)ng/ml之间或(0.8-1.0](不包括下端点0.8,包括上端点1.0)ng/ml之间,得分为1,处于(0.5-0.8](不包括下端点0.5,包括上端点0.8)ng/ml之间,得分为2;
bmi>25kg/m2,得分为0;处于(23-25](不包括下端点23,包括上端点25)kg/m2之间,得分为1,≤23kg/m2,得分为2;
诊断年龄>40岁,得分为0;处于(25-40](不包括下端点25,包括上端点40)岁之间,得分为1;≤25岁,得分为2;
t1d自身抗体阳性数目≥2,得分为0;等于1,得分为1;等于0,得分为2。
hscrp浓度处于(0.1-0.5]mg/l(不包括下端点0.1,包括上端点0.5)之间,得分为0.5;≤0.1mg/l,得分为1;
tg浓度≤1.7mmol/l,得分为0.5;
肝脏腺瘤存在,得分为1;
当诊断总分≥8,且诊断分值2≥7,诊断分值1≥1时,则判断受试者患有mody3的可能性大。
根据本发明的又一个方面,本发明提供了一种试剂盒,其包含:
检测受试者生化指标的试剂,所述生化指标包括空腹c-肽、t1d自身抗体;优选地,所述生化指标还包括hba1c、餐后2h血糖、hscrp、tg;
以及
表格,所述表格包含上述变量的计分标准;优选地,所述表格结构如表4所示;
进一步,所述试剂盒还包括供医生填写的信息单,所述信息单用于记录患者信息。患者信息包括患者基本信息,如性别、身高、体重、糖尿病诊断年龄、糖尿病家族史;还包括临床检测信息,如空腹c-肽、t1d自身抗体、hba1c、餐后2h血糖、hscrp、tg、肝脏腺瘤。
根据本发明的又一个方面,本发明提供了一种系统,其包含机器可读存储器,以及处理器,所述处理器计算前面所述的诊断分值;优选地,机器可读存储器包括计算机和/或计算器。
根据本发明的又一个方面,本发明提供了前面所述的区分mody与t1d和t2d的诊断模型在制备诊断mody的工具中的应用。
根据本发明的又一个方面,本发明提供了前面所述的mody2诊断模型在制备诊断mody2的工具中的应用。
根据本发明的又一个方面,本发明提供了前面所述的mody3诊断模型在制备诊断mody3的工具中的应用。
进一步,所述工具包括表格、试剂盒、系统。
更进一步,所述试剂盒如前面所述。
更进一步,所述系统如前面所述。
根据本发明的又一个方面,本发明提供了一种区分mody与t1d和t2d的方法,所述方法包括使用前面所述的区分mody与t1d和t2d的诊断模型。
在本发明的具体实施方案中,所述方法包括如下步骤:
(1)获取受试者以下变量信息:糖尿病家族史、空腹c-肽、bmi、诊断年龄、t1d自身抗体。
(2)按照前面所述的变量计分标准和诊断分值的计算公式计算以上变量的总分。
(3)若受试者以上变量总分≥7分,则判断该受试者存在患有mody的风险。
根据本发明的又一个方面,本发明提供了一种诊断mody2的方法,所述方法包括使用前面所述的mody2诊断模型。
在本发明的具体实施方案中,所述方法包括如下步骤:
(1)获取受试者以下变量信息:糖尿病家族史、空腹c-肽、bmi、诊断年龄、t1d自身抗体。
(2)按照前面所述的变量计分标准和诊断分值的计算公式计算以上变量的总分。
(3)对于以上变量总分≥7分的受试者,收集以下变量信息:hba1c、餐后2h血糖、hscrp、tg。
(4)按照前面所述的变量计分标准和诊断分值的计算公式计算hba1c、餐后2h血糖、hscrp、tg四个变量的总分。
(5)若以上四个变量总分≥1分,则判断该受试者患有mody2的风险大。
根据本发明的又一个方面,本发明提供了一种诊断mody3的方法,所述方法包括使用前面所述的mody3诊断模型。
在本发明的具体实施方案中,所述方法包括如下步骤:
(1)获取受试者以下变量信息:糖尿病家族史、空腹c-肽、bmi、诊断年龄、t1d自身抗体。
(2)按照前面所述的变量计分标准和诊断分值的计算公式计算以上变量的总分。
(3)对于以上变量总分≥7分的受试者,收集以下变量信息:hscrp、tg、肝脏腺瘤。
(4)按照前面所述的变量计分标准和诊断分值的计算公式计算hscrp、tg、肝脏腺瘤三个变量的总分。
(5)若以上三个变量总分≥1分,则判断该受试者患有mody3的风险大。
本发明的有益效果:
本发明构建的mody诊断模型的敏感性约80%、特异性高达85%,临床应用前景良好。
本发明的mody诊断模型可用于诊断mody所有亚型,具有普适性。
本发明的mody诊断方法简便高效可替代传统诊断方法有望成为新的诊断标准。
附图说明
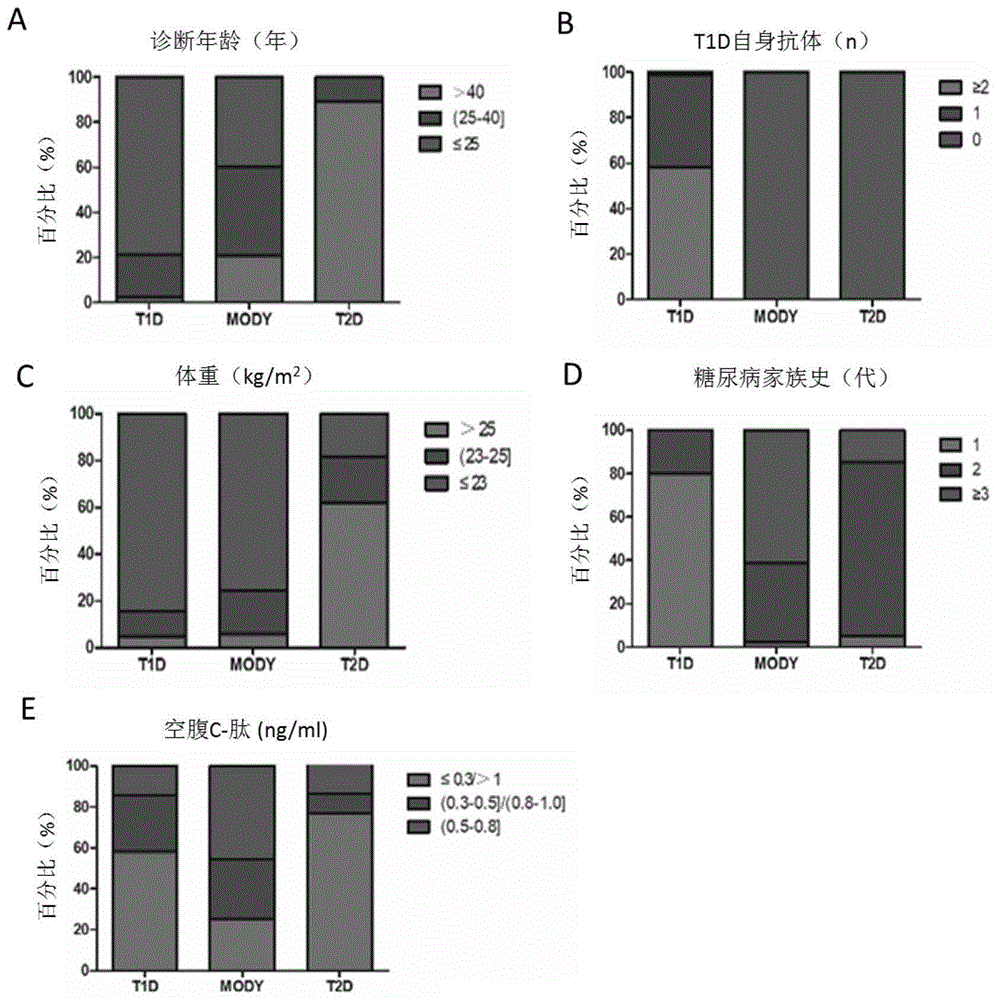
图1显示三组糖尿病患者临床特征柱形图,其中a:诊断年龄,b:t1d自身抗体,c:bmi,d:糖尿病家族史,e:空腹c-肽;
图2显示mody诊断模型主要标准的诊断效能roc曲线图。
具体实施方式
为使本发明实施方式的目的、技术方案和优点更加清楚,下面将结合本发明实施方式中的附图,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。因此,以下对在附图中提供的本发明的实施方式的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施方式。
实施例模型构建和效能检测
1、研究对象
本研究招募了84例t1d患者,82例t2d患者(55岁前发病)和140例经基因检测确诊为mody的患者(106例mody2和34例mody3患者),所有患者均来自中国。
诊断标准
t1d和t2d的诊断标准参考美国糖尿病协会的糖尿病诊断标准;
mody疑诊标准如下:1)存在至少连续两代糖尿病家族史;2)先证者糖尿病发病年龄≤45岁;3)无t1d自身抗体;4)非肥胖(bmi<28kg/m2)。最终通过基因检测明确诊断。
本研究包含的所有受试者均为2014年1月至2018年12月就诊于北京协和医院内分泌科门诊或病房的患者。本研究通过了北京协和医院伦理委员会审核。按伦理委员会要求,详细告知临床试验参与者可能的风险及获益,所有纳入本研究的受试者均签署了纸质版知情同意书(18岁以下者由父母或法定监护人签署),参与者可于任何时间退出该研究。
2、研究方法
使用premier5软件设计引物序列(见表1)。通过ncbiblast数据库与参考序列nm_000162(gck)和nm_000545.6(hnf1a)比对鉴别突变。采用polyphen-2、mutationtaster和sift等生物信息学软件对突变位点进行功能预测。结合预测结果及患者临床表型证实本研究中发现的所有突变均为致病突变。
表1gck/hnf1a基因引物列表
病史采集:收集所有受试者的临床资料,包括:性别、年龄、糖尿病诊断年龄、糖尿病家族史、身高、体重、血压等,bmi值的计算方法为体重(公斤)除以身高(米)的平方。
实验室检查:所有患者禁食10小时后采集静脉血样,采用化学发光法测定c-肽和餐后2hc-肽。采用高效液相色谱系统测定糖化血红蛋白a1c(hba1c)。采用酶联免疫吸附法测定gad和ia2;间接免疫荧光法测定ica。采用全自动生化分析仪(au5800;美国贝克曼库尔特公司)测定hscrp、总胆固醇、高密度脂蛋白胆固醇(hdl-c)、低密度脂蛋白胆固醇(ldl-c)、tg和糖化白蛋白。采用△2h血糖表示餐后2h血糖与空腹血糖的差值。采用腹部超声检查筛查肝脏腺瘤。
3、统计分析
采用spss21.0进行统计分析。连续变量采用方差分析,以平均值±标准差(sd)表示,不符合正态分布变量采用中位数(25th-75th)表示。p<0.05被认为具有统计学上的显著差异。采用受试者工作特征曲线(roc曲线)寻找各生化指标的最佳切点,以区分不同类型糖尿病。采用youden指数确定切点值,youden指数=敏感性+特异性-1。
4、结果
4.1临床资料和实验室特征
本研究共包含306例糖尿病患者,其中t1d患者84例,mody2患者106例,mody3患者34例、t2d患者82例。受试者的基本特征见下表2。
表2研究受试者的基本特征
注:方差分析结果:与t1d存在差异采用*p<0.05表示;与mody2存在差异采用+p<0.05表示;与mody3存在差异采用#p<0.05表示。分类变量采用n(%)表示,线性变量采用均值±标准差表示,非正态分布数据采用中位数(25th-75th)表示。p<0.05被认为有显著性差异,采用加粗表示;若p<0.001,则用科学计数法表示。
由上表可见mody患者的糖尿病家族史更加明显。与其他组相比,t1d患者的hba1c水平最高,c-肽水平最低,且t1d自身抗体呈阳性。t2d患者发病年龄最大,bmi水平最高(26.80±4.35kg/m2)。两组mody患者空腹和餐后2h-c肽水平相近;但相较于mody2患者,mody3患者空腹血糖、餐后2h血糖、糖化血红蛋白及△2h血糖更高,hdl-c水平更低。另外,有2例mody3患者存在肝脏腺瘤。
t1d患者中,诊断年龄>40岁的患者所占比例为2.4%,介于25-40岁之间的患者所占比例为19.0%,≤25岁的患者所占比例为78.6%;mody患者中,诊断年龄>40岁的患者所占比例为20.7%,介于25-40岁之间的患者所占比例为39.3%,≤25岁的患者所占比例为40.0%。t2d患者中,诊断年龄>40岁的患者所占比例为19.2%,介于25-40岁之间的患者所占比例为73.1%,≤25岁的患者所占比例为7.7%(图1)。
三组糖尿病患者中,只有t1d患者存在抗体阳性,其中58.3%的t1d患者存在≥2种抗体阳性,40.5%的患者存在1种抗体阳性,另有1.2%的患者为抗体阴性的t1d患者(图1)。此外,t1d患者中,bmi>25kg/m2的患者所占比例为4.8%,介于23-25kg/m2之间的患者所占比例为10.7%,≤23kg/m2的患者所占比例为84.5%;mody患者中,bmi>25kg/m2的患者所占比例为5.7%,介于23-25kg/m2之间的患者所占比例为18.6%,≤23kg/m2的患者所占比例为75.7%;t2d患者中,bmi>25kg/m2的患者所占比例为48.1%,介于23-25kg/m2之间的患者所占比例为19.2%,≤23kg/m2的患者所占比例为32.7%(图1)。
糖尿病家族史方面:t1d患者中79.8%无糖尿病家族史,20.2%存在连续2代糖尿病家族史,无t1d患者存在连续3代及以上糖尿病家族史。mody患者中2.1%无糖尿病家族史,36.4%存在连续2代糖尿病家族史,61.4%存在连续3代及以上糖尿病家族史;t2d患者中,4.9%无糖尿病家族史,80.5%存在连续2代糖尿病家族史,14.6%存在连续3代及以上糖尿病家族史(图1)。
t1d患者中,空腹c-肽≤0.3/>1.0ng/ml的患者所占比例为64.3%,介于0.3-0.5(不包括下端点0.3,包括上端点0.5)/0.8-1.0(不包括下端点0.8,包括上端点1.0)ng/ml之间的患者所占比例为25.0%,介于0.5-0.8(不包括下端点0.5,包括上端点0.8)ng/ml之间的患者所占比例为10.7%;mody患者中,空腹c-肽≤0.3/>1.0ng/ml的患者所占比例为23.6%,介于0.3-0.5(不包括下端点0.3,包括上端点0.5)/0.8-1.0(不包括下端点0.8,包括上端点1.0)ng/ml之间的患者所占比例为28.6%,介于0.5-0.8(不包括下端点0.5,包括上端点0.8)ng/ml之间的患者所占比例为47.9%;t2d患者中,空腹c-肽≤0.3/>1.0ng/ml的患者所占比例为71.2%,介于0.3-0.5(不包括下端点0.3,包括上端点0.5)/0.8-1.0(不包括下端点0.8,包括上端点1.0)ng/ml之间的患者所占比例为18.3%,介于0.5-0.8(不包括下端点0.5,包括上端点0.8)ng/ml之间的患者所占比例为10.6%(图1)。
4.2逻辑回归分析寻找mody的生物标志物
本研究采用多变量逻辑回归,分析临床指标对mody的预测作用。如表3所示,调整年龄和性别后,相对于t1d,降低的bmi(or0.886;95%ci0.787-0.996)、空腹血糖(or0.832;95%ci0.749-0.926)、餐后2h血糖(or0.860;95%ci0.795-0.930)、△2h-血糖(or0.903;95%ci0.824-0.991)、糖化血红蛋白(or0.551;95%ci0.434-0.700)、总胆固醇(or0.494;95%ci0.306-0.798)、低密度脂蛋白(or0.536;95%ci0.321-0.895)和超敏c反应蛋白(or0.538;95%ci0.333-0.867)及升高的诊断年龄(or1.037;95%ci1.012-1.062)、空腹c肽(or783;95%ci72-8496)和餐后2h-c肽(or10.9;95%ci4.5-26)是mody的独立预测因子。相比于t2d患者,mody患者的hdl-c(or9.090;95%ci1.438-57)水平更高,而诊断年龄(or0.841;95%ci0.798-0.886)、bmi(or0.651;95%ci0.546-0.776)、空腹血糖(or0.749;95%ci0.612-0.917)、餐后2h血糖(or0.849;95%ci0.757-0.952)、空腹c肽(or0.552;95%ci0.305-0.998)、糖化血红蛋白(or0.639;95%ci0.440-0.926)、甘油三酯(or0.193;95%ci0.073-0.506)和超敏c反应蛋白(or0.329;95%ci0.162-0.670)更低。
表3逻辑回归结果
采用逻辑回归分析方法,在矫正性别、年龄后分析临床指标对mody的预测作用。
结果采用or(95%ci)和p表示;p<0.05被认为具有显著性差异,采用加粗表示。
4.3mody诊断模型
本研究发现糖尿病家族史、空腹c-肽、bmi、诊断年龄和t1d自身抗体5种变量具有很好的预测mody风险的作用。因此本研究基于上述5种变量建立了针对中国人群的mody诊断模型。如表4所示,mody诊断模型分为主要标准和特异性标准。主要标准用于评估mody可能性,根据roc曲线寻找出的各代谢指标的最佳切点,并根据t1d自身抗体的个数及连续糖尿病家族史的代数分别指定分值为0、1、2。
表4诊断mody的主要标准和特异性标准
t1d的最强预测因子是自身抗体阳性和c-肽水平低;t2d的bmi值更高,诊断年龄更大;mody患者糖尿病家族史更加明显。本研究进一步采用roc曲线评估上述5种临床指标预测mody风险的效果。结果表明,主要标准的诊断阈值为7分时,区分mody、t1d和t2d的效果最佳,敏感性为80.0%,特异性为94.0%,auc为0.929;区分mody和t1d的敏感性为80.0%,特异性为92.9%,auc为0.916;区分mody和t2d的敏感性为80.0%,特异性为95.1%,auc为0.942(图2)。
相比较而言,若采用mody诊断的经典临床标准(参考文献:njolstadpr,molvena:totest,ornottotest:timeforamodycalculator?diabetologia2012;55:1231-12)(糖尿病发病年龄<25岁,至少存在连续两代糖尿病家族史,存在内源性胰岛素分泌,gada阴性),仅能筛检出30%的mody患者。而将mody概率计算器(参考文献:shieldsbm,mcdonaldtj,ellards,campbellmj,hydec,hattersleyat:thedevelopmentandvalidationofaclinicalpredictionmodeltodeterminetheprobabilityofmodyinpatientswithyoung-onsetdiabetes.diabetologia2012;55:1265-1272)应用于本研究队列则发现t1d的阳性预测值为64.2%,mody2的阳性预测值为75.5%,mody3的阳性预测值为70%,t2d的阳性预测值为60%。表明上述两种mody诊断标准均无法有效的鉴别出中国mody患者。
特异性标准针对常见mody类型(mody2和mody3):根据各个特异性指标(或者联合指标)的90th作为1分的切点,当特异性指标≥1分时,可针对性进入不同基因的sanger测序。主要标准评分越高,则筛查mody的必要性越强,而特异性标准评分越高,重点筛查相应基因的指向性就越强。
除了最常见的mody亚型(mody2和mody3)之外,本研究小组在研究过程中还发现了一系列罕见的mody亚型,包括mody1(n=2),mody4(n=2),mody5(n=1),mody6(n=1),mody10(n=2)和mody13(n=2)并分别计算了这些患者的分值,发现除mody5(主要分值=6分)外,所有患者的主要分值均≥7分。该mody5患者肾脏超声表现为皮质回声增强,伴有多发囊肿,疑似肾钙质沉着或肾结石,这些表现有助于正确诊断。该验证结果表明,本发明的筛选模型可有效鉴别在中国遗传背景下各种mody亚型的作用。
以上所述仅为本发明的优选实施方式而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
序列表
<110>中国医学科学院北京协和医院
<120>一种区分mody与t1d和t2d的诊断模型
<150>2020103083730
<151>2020-04-18
<160>34
<170>siposequencelisting1.0
<210>1
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>1
ttgccaccagtcccagtt18
<210>2
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>2
actcccagaatgcccaat18
<210>3
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>3
gtgcagatgcctggtgac18
<210>4
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>4
aggagccaagggtgagaa18
<210>5
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>5
ctcccttagtcccttgtgc19
<210>6
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>6
tccccacccctggtagaca19
<210>7
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>7
aagcagcagcggaagagg18
<210>8
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>8
ggctacatttgaaggcagagt21
<210>9
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>9
ttcaaggagaatcgttccca20
<210>10
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>10
ctctgctctgacatcaccg19
<210>11
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>11
agagggactcctgtgggc18
<210>12
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>12
cggattgtcagtttgctttt20
<210>13
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>13
cgagggaaagacgtgaacc19
<210>14
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>14
cgtcgccctgagaccaag18
<210>15
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>15
ggctcagcgagggaaagag19
<210>16
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>16
ttgggaaccgcaaggaac18
<210>17
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>17
tttcgtagtcctcttctcgtcc22
<210>18
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>18
atggagcctgggtgctgt18
<210>19
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>19
gtgcaaggagtttggtttgt20
<210>20
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>20
ggctcaaacctccaagcaag20
<210>21
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>21
taactgctttcatgcacagtc21
<210>22
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>22
aataaatgcaggttgaatccc21
<210>23
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>23
ctgtaagctcctctggttca20
<210>24
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>24
agccaatatcaggagttctcg21
<210>25
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>25
cagcagacctggcattggaa20
<210>26
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>26
tggaaccaaactgaagtgcaa21
<210>27
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>27
tggcctaagcaaaccaatgga21
<210>28
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>28
tgagtcccagtggctcttcc20
<210>29
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>29
tgacttgccagagccactt19
<210>30
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>30
gacaccctcaatcacggaa19
<210>31
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>31
ctttccccagtcttgagg18
<210>32
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>32
gggcagggacagtaagggag20
<210>33
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>33
gctccctttgaagaaccga19
<210>34
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>34
gagccctccctttctgatg19
- 还没有人留言评论。精彩留言会获得点赞!