一种基于测序和数据分析的肥胖风险预测装置及其预测方法与流程
本发明属于基因测序技术领域,特别涉及一种基于测序和数据分析的肥胖风险预测装置及其预测方法。
背景技术:
现有肥胖评估模型(体重指数、腰围臀围比)只将少数身体指标纳入评价体系,具有很大的缺陷。在小样本研究或个体应用中,由于bmi指数没有考虑到身体成分构成和肥胖的影响因素,其准确性必然存在问题。此外,bmi指数模型忽略了男女身体的差异,男女本身身体的差异在此模型中被忽视,就会导致因为性别问题而在肥胖预测中产生误判。这种类型的误判在女性尤其常见。根据有关研究显示,腰围腰臀比存在明显的性别差异,腰围和腰臀比皆按不同的性别采用不同的切点,两者用于评估人群肥胖发生率时差异较小。所以将腰围臀围比作为肥胖评估指标的准确度较低,会有一大批人群错过肥胖或代谢综合征的早期诊断和治疗。
技术实现要素:
发明目的:针对上述问题,本发明提供一种基于测序和数据分析的肥胖风险预测装置及其预测方法,通过将机器学习和基因分析相结合,利用庞大的基因型与对应个体的生理信息数据库,实现对个体肥胖风险的预测以及生理信息异常风险进行评估。
技术方案:本发明提出一种基于测序和数据分析的肥胖风险预测装置,包括数据处理单元、数据可视化单元、肥胖分类单元、基因位点预测单元和位点评分单元;
数据处理单元,用于对原始snp样本数据进行处理;
数据可视化单元,用于对所有数据进行可视化处理,得到样本的身高、体重、腰围及bmi指数之间的关系;
肥胖分类单元,通过k-means算法对肥胖进行分类,确定不同基因对不同肥胖类型的影响;
基因位点预测单元,通过浅层神经网络对基因位点信息、性别信息及身高体重进行回归性分析,预测基因位点对身高体重影响程度;
位点评分单元,基于集成学习模型,利用snps的信息和个体的生理信息对肥胖风险进行评估。
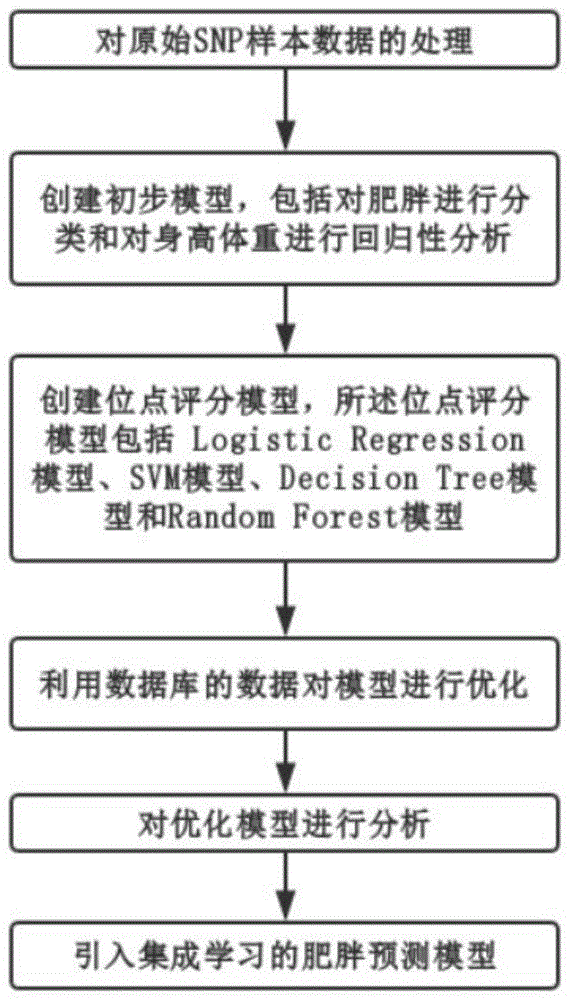
一种如上所述的基于测序和数据分析的肥胖风险预测装置的预测方法,其特征在于,包括如下步骤:
(1)对原始snp样本数据进行处理;
(2)创建初步模型,包括对肥胖进行分类和对身高体重进行回归性分析;
(3)创建位点评分模型,所述位点评分模型包括logisticregression模型、svm模型、decisiontree模型和randomforest模型;在机器学习任务中,将原始数据集分为三部分:训练集、验证集和测试集;
(4)利用数据库的数据对模型进行优化;
(5)对优化模型进行分析;
(6)引入集成学习的肥胖预测模型。
进一步的,所述步骤(1)中对原始snp样本数据进行处理的具体步骤如下:
(1.1)将所有snp信息文件转化为csv文件;
(1.2)进行数据清洗,去除不相关的位点信息数据和极端数据;
(1.3)将所有数据进行可视化处理。
进一步的,所述步骤(2)中创建初步模型的具体步骤如下:
(2.1)利用的是k-means算法对肥胖进行分类;
(2.2)利用浅层神经网络对八个基因位点信息和性别信息与身高体重进行回归性分析,
z=wx+b
式中:z是线性层输出;w为模型参数;x为输入数据(基因位点信息和生理数据);b为偏置项。
y=激活函数(z)
式中:z为线性层输出;y是逻辑斯蒂层输出,值域[0,1]。
在逻辑回归过程中,由于梯度下降算法中每一次迭代的时候w参数的值是根据
w=w-学习率*导数
式中:w是模型参数;学习率为模型超参数。
进行设置得,其中学习率是手动设置的参数,这时候如果导数即斜率过小,会导致梯度下降的的步数也很小,影响效率;
relu激活函数定义为:
为了保证结果地准确性,引入损失函数对结果进行修正,损失函数采用的均方差函数(mse):
式中:y是真值;y’是预测值。
进一步的,所述步骤(4)中利用数据库的数据对模型进行优化的具体步骤如下:
(4.1)引入基因与生理信息数据库;
(4.2)基因位点即snps优化;
(4.3)优化模型参数。
进一步的,所述步骤(5)中对优化模型进行分析的具体步骤如下:
(5.1)以logisticregression建立的模型进行分析,logisticregression的表达式是:
式中:w为模型参数;x为输入数据(基因位点信息和生理数据);b为偏置项。
(5.2)在训练完成之后提取w的值,根据系数给出各个特征的重要程度,并定义一个人肥胖的风险值r:
r=-(wx+b)
式中:r为肥胖风险值;w为模型参数;x为输入数据(基因位点信息和生理数据);b为偏置项。
在logisticregression这个模型中,r的值越靠近负无无穷,表示这个人被判别为没有肥胖风险的可能性就越大,相反如果一个人的r值逐渐接近正无穷,表示这个人未来bmi偏大的可能性越大;
(5.3)在测试集上验证r值的准确性。
进一步的,所述步骤(6)中引入集成学习的肥胖预测模型的具体步骤如下:
(6.1)第一层分类器:利用snps的信息和测试者的生理信息分别构建多个弱分类器,采用的多种模型包括svm、logisticregression及randomforest,同时加入了新的模型adaboost和gradientboost,输出是对bmi分型的预测;
(6.2)第二层分类器:得到第一层的输出肥胖的分类即bmicategory之后,将其作为输入喂入第二层分类器xgboost,第二层的作用是根据第一层分类器已经提取出来的特征对肥胖类型进行预测。
由于肥胖是一个多因素相关的问题,必须对大数据进行分析,找到所有与肥胖相关的因素。而通过肥胖评估模型,可以对肥胖进行预测,在肥胖问题未发生或者肥胖程度较低时采取相应的措施来预防肥胖问题的发生或避免其严重化发展,所以对肥胖的评估是极其重要的工作。
本发明采用上述技术方案,具有以下有益效果:
本发明通过将机器学习和基因相结合,利用庞大的基因型与对应个体的生理信息数据库,实现对个体肥胖风险的预测以及生理信息异常风险评估。
附图说明
图1为本发明的流程图;
图2为具体实施例中引入集成学习的肥胖预测模型图;
图3为本发明的结构示意图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,但是本发明要求保护的范围并不局限于此。
在本实施例中,提出一种基于测序和数据分析的肥胖风险预测的方法,如图1所示,本方法包括以下步骤:s1、对原始snp样本数据的处理;s2、创建初步模型,包括对肥胖进行分类和对身高体重进行回归性分析;s3、创建位点评分模型,所述位点评分模型包括logisticregression模型、svm模型、decisiontree模型和randomforest模型;s4、利用数据库的数据对模型进行优化;s5、对优化模型进行分析;s6、引入集成学习的肥胖预测模型。其中,本发明利用基因与生理信息数据建立机器学习和集成学习模型来预测肥胖风险;其中,为了防止模型过于复杂而引起的过拟合,需要对各个模型进行交叉验证。
在一些具体的实施例中,s1中对原始snp样本数据进行处理,所述处理包括:由于数据包括.csv和.json格式,对所有数据进行统一格式处理,将所有snp信息文件转化为csv文件;由于基因本身的特殊性,导致其数据量及其庞大,与研究内容无关的干扰数据非常多,需要进行数据清洗,去除不相关的位点信息数据和极端数据,同时需要填充部分缺失值;由于数据量庞大,为了构建初步的简单关系模型,将所有数据进行可视化处理,得到较为直观的数据关系。
在一些具体的实施例中,所述s2中创建初步模型包括:
s201、利用的是k-means算法对肥胖进行分类,利用腰围和bmi分布图进行聚类,得到的结果用不同的颜色和标记进行可视化处理;
s202、利用浅层神经网络对八个基因位点信息和性别信息与身高体重进行回归性分析,
z=wx+b
式中:z是线性层输出;w为模型参数;x为输入数据(基因位点信息和生理数据);b为偏置项。
y=激活函数(z)
式中:z为线性层输出;y是逻辑斯蒂层输出,值域[0,1]。
在逻辑回归过程中,由于梯度下降算法中每一次迭代的时候w参数的值是根据
w=w-学习率*导数
式中:w是模型参数;学习率为模型超参数。
进行设置得,其中学习率是手动设置的参数,这时候如果导数(斜率)过小,会导致梯度下降的的步数也很小,影响效率;
relu激活函数定义为:
为了保证结果地准确性,引入损失函数对结果进行修正,损失函数采用的均方差函数(mse):
式中:y是真值;y’是预测值。
在一些具体的实施例中,所述s3中在机器学习任务,首先会将原始数据集分为三部分:训练集、验证集和测试集;训练集用于训练模型,验证集用于模型的参数选择配置,测试集对于模型来说是未知数据,用于评估模型的泛化能力。
在一些具体的实施例中,所述s3中构建svm模型采用的是非线性的处理方式,为了能使高维情况下的svm能够更加简便地得到结果,选择rbf(径向基)核函数,将原空间映射到一个新的空间,使得所有样本点都线性可分。
在一些具体的实施例中,所述s3中构建decisiontree模型的一般步骤包括:确定模型目标;确定训练集数据、验证集数据、目标变量、自变量,对数据进行必要的预处理;使用训练集进行决策树构建;使用测试集进行模型的验证;确定模型。其中最常用的算法有cart,chaid,c5.0,c4.5等;另外,由于本发明使用的数据不是一个长期观察的动态数据,decisiontree易于通过静态测试来对模型进行评测,可以测定模型可信度。
在一些具体的实施例中,所述s4中利用数据库的数据对模型进行优化,包括一下步骤:
s401、引入基因与生理信息数据库,获得测试者生理信息,包括:性别,身高,体重,腰围,甘油三脂,舒张压,收缩压,空腹血糖值,总胆固醇值;获取snps位点数据;
s402、基因位点(snps)优化,数据集按照bmi的值被划分成两个区域,经过筛选后获得16个与肥胖相关的位点;
s403、优化模型参数,数据重新输入四种机器学习模型,将训练集数据输入模型中,训练集和测试集的比率是9:1,这里用交叉验证来避免过拟合问题。
在一些具体的实施例中,所述s5中对优化模型进行分析,包括以下步骤:
s501、考虑到logisticregression在流行病的研究中是非常常用的模型,而且svm在核函数非线性的情况下不能提取出特征的系数,这里以logisticregression建立的模型进行分析,logisticregression的表达式是:
式中:w为模型参数;x为输入数据(基因位点信息和生理数据);b为偏置项。
s502、在训练完成之后提取w出的值,根据系数给出各个特征的重要程度,并定义一个人肥胖的风险值r:
r=-(wx+b)
式中:r为肥胖风险值;w为模型参数;x为输入数据(基因位点信息和生理数据);b为偏置项。
在logisticregression这个模型中,r的值越靠近负无无穷,表示这个人被判别为没有肥胖风险的可能性就越大,相反如果一个人的r值逐渐接近正无穷,表示这个人未来bmi偏大的可能性越大;
s503、在测试集上验证r值的准确性。
由以上步骤可知,可以根据snps位点信息以预测一个人未来肥胖风险,并提取出了各个位点之间的相对重要性程度;其中表现最好的模型——logisticregression,其准确性也依然有很大的提高空间。实际上,肥胖是一个多因素导致的问题,并不是由单一的由基因决定,个体的生活环境、生活习惯等多方面因素都会影响其是否肥胖。在模型中加入测试者的生理征,包括年龄、性别、腰围、血糖、甘油三酯、收缩压、舒张压、胆固醇,来对风险预测的模型进行进一步优化。
在一些具体的实施例中,所述s6中引入集成学习的肥胖预测模型,如图2所示,包括以下步骤:
s601、第一层分类器:利用snps的信息和测试者的生理信息分别构建多个弱分类器,采用的多种模型包括svm、logisticregression及randomforest,同时加入了新的模型adaboost和gradientboost,输出是对bmi分型的预测;
s602、第二层分类器:得到第一层的输出肥胖的分类(bmicategory)之后,将其作为输入喂入第二层分类器xgboost,第二层的作用是根据第一层分类器已经提取出来的特征对肥胖类型进行预测。
经过上述所有的建模与优化过程,构建了一个基于集成学习构成的算法模型,在第一层分类器中使用交叉验证的方法,对数据集进行了十次划分,分别进行了十次训练和验证,最终的准确度取十次预测准确度的平均值;再将第一层的预测结果作为第二层分类器的输入特征,对肥胖进行分类。
另,本发明基于集成学习的肥胖预测模型,创建辅助模型分析测试者营养素含量异常,由于数据的局限性,只讨论血糖和血脂的相关问题。做预测的主要依据是判别患者是否存在对某种营养素的处理障碍。数据集标注了异常和非异常的样本,在对数据进行特征工程的处理之后,把snps的数据喂入模型中分析结果。
此外,本发明还提出一种基于测序和数据分析的肥胖风险预测的装置,其特征在于,包括:
数据处理单元,该单元能够对原始snp样本数据进行处理;
数据可视化单元,该单元将所有数据进行可视化处理,得到较为直观的样本的身高、体重、腰围及bmi指数之间的关系;
肥胖分类单元,该单元利用的是k-means算法对肥胖进行分类,便于确定不同基因对不同肥胖类型的影响;
基因位点预测单元,该单元利用浅层神经网络对基因位点信息、性别信息及身高体重进行回归性分析,预测基因位点对身高体重影响程度;
位点评分单元,该单元能够基于集成学习模型,利用snps的信息和个体的生理信息对肥胖进行评估。
- 还没有人留言评论。精彩留言会获得点赞!