一种基于尿液性状自学习的疾病征兆预测系统的制作方法
本发明涉及计算机技术领域,尤其涉及一种基于尿液性状自学习的疾病征兆预测系统。
背景技术:
尿液是血液经过肾脏代谢以后形成的终末产物,尿液的组成和性状可以反映出机体的代谢状况,并受机体各系统功能状态的影响。因此,尿液检测不仅能够反应出泌尿系统的问题,而且对其它系统疾病的诊断也有重要的参考价值。
传统的尿液检测,一般把这个尿液自动化分析仪的检查结果和人工显微镜的检查结合起来,我们称为尿常规检测。尿常规检测出来数据后,一般要根据临床医师的知识和经验进行分析和判断,然后给出结果。但是这种方式要依赖临床医师进行判断,不仅工作量大,而且可能会造成一定失误,所以亟需一种基于尿液性状自学习的疾病征兆预测系统,能够自动对尿液进行检测。
上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现要素:
有鉴于此,本发明提出了一种基于尿液性状自学习的疾病征兆预测系统,旨在解决现有技术无法实现通过建立语义相似度的计算模型来预测尿液性状异常变化与可能的疾病之间的关系的技术问题。
本发明的技术方案是这样实现的:
一方面,本发明提供了一种基于尿液性状自学习的疾病征兆预测系统,所述基于尿液性状自学习的疾病征兆预测系统包括:
映射关系库模块,用于获取尿液特征分词信息数据以及对应的疾病信息,根据该尿液信息数据以及对应的疾病信息建立映射关系库;
特征分词提取模块,用于获取待诊断尿液性状文本描述,通过最大正向匹配法将尿液性状文本描述与映射关系库中特征分词信息数据进行匹配,根据匹配结果获取待诊断尿液性状文本描述对应的待计算特征分词;
计算模块,用于建立语义相似度算法,根据语义相似度算法计算待计算特征分词与映射关系库中各信息数据的语义相似度;
辅助诊断模块,用于根据语义相似度,对待诊断尿液性状文本描述进行诊断。
在以上技术方案的基础上,优选的,映射关系库模块包括数据采集模块,用于采集尿液特征分词信息数据以及对应的疾病信息,所述尿液特征分词信息数据包括:正常特征分词信息数据以及异常特征分词信息数据,正常以及异常特征分词数据包括:气味、数量、颜色、透明度以及比重数据,对应的疾病信息包括:疾病特征分词数据以及疾病症状特征分词数据。
在以上技术方案的基础上,优选的,映射关系库模块包括映射关系建立模块,用于根据尿液特征分词信息数据以及对应的疾病信息建立对应的映射关系,每个尿液特征分词信息数据至少与一个对应的疾病信息建立映射关系,根据该映射关系建立映射关系库。
在以上技术方案的基础上,优选的,特征分词提取模块包括匹配模块,用于获取待诊断尿液性状文本描述,获取映射关系库中尿液特征分词信息数据的字符数,根据该字符数对待诊断尿液性状文本描述进行匹配查找,当匹配查找到对应文本描述时,提取该文本描述作为待计算特征分词。
在以上技术方案的基础上,优选的,计算模块包括语义相似度计算模块,用于建立语义相似度算法,通过语义相似度算法计算待计算特征分词与映射关系库中尿液特征分词信息数据以及疾病信息之间的语义相似度。
在以上技术方案的基础上,优选的,辅助诊断模块包括报告生成模块,用于设定语义相似度阈值,将语义相似度与语义相似度阈值进行比较,当语义相似度大于语义相似度阈值时,根据该语义相似度,生成对应诊断报告;当语义相似度小于语义相似度阈值时,重新选择语义相似度进行比较。
更进一步优选的,所述基于尿液性状自学习的疾病征兆预测设备包括:
映射关系库单元,用于获取尿液特征分词信息数据以及对应的疾病信息,根据该尿液信息数据以及对应的疾病信息建立映射关系库;
特征分词提取单元,用于获取待诊断尿液性状文本描述,通过最大正向匹配法将尿液性状文本描述与映射关系库中特征分词信息数据进行匹配,根据匹配结果获取待诊断尿液性状文本描述对应的待计算特征分词;
计算单元,用于建立语义相似度算法,根据语义相似度算法计算待计算特征分词与映射关系库中各信息数据的语义相似度;
辅助诊断单元,用于根据语义相似度,对待诊断尿液性状文本描述进行诊断。
本发明的一种基于尿液性状自学习的疾病征兆预测系统相对于现有技术具有以下有益效果:
(1)通过建立尿液特征分词数据与疾病信息数据之间的映射关系库,在对待诊断尿液信息数据进行诊断时,能够通过映射关系库快速精确查找到对应的疾病信息以及疾病症状信息;
(2)通过建立语义相似度算法,通过语义相似度算法来计算待诊断尿液特征分词数据与映射关系库中其他特征分词数据之间的语义相似度,提高了系统诊断过程的精确度,提升了用户体验。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
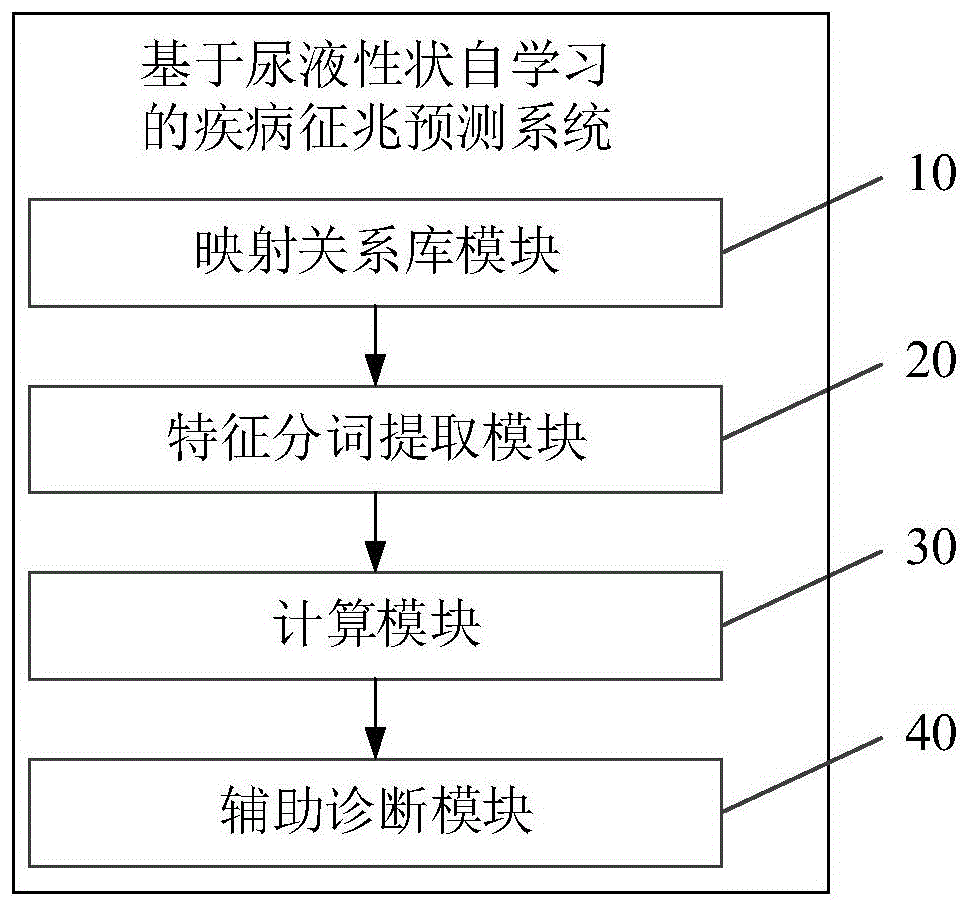
图1是本发明基于尿液性状自学习的疾病征兆预测系统第一实施例的结构框图;
图2为本发明基于尿液性状自学习的疾病征兆预测系统的第二实施例结构框图;
图3为本发明基于尿液性状自学习的疾病征兆预测系统的第三实施例结构框图;
图4为本发明基于尿液性状自学习的疾病征兆预测系统的第四实施例结构框图;
图5为本发明基于尿液性状自学习的疾病征兆预测系统的第五实施例结构框图;
图6为本发明基于尿液性状自学习的疾病征兆预测设备结构框图。
具体实施方式
下面将结合本发明实施方式,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式仅仅是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
如图1所示,图1为本发明基于尿液性状自学习的疾病征兆预测系统第一实施例的结构框图。其中,所述基于尿液性状自学习的疾病征兆预测系统包括:映射关系库模块10、特征分词提取模块20、计算模块30和辅助诊断模块40。
映射关系库模块10,用于获取尿液特征分词信息数据以及对应的疾病信息,根据该尿液信息数据以及对应的疾病信息建立映射关系库;
特征分词提取模块20,用于获取待诊断尿液性状文本描述,通过最大正向匹配法将尿液性状文本描述与映射关系库中特征分词信息数据进行匹配,根据匹配结果获取待诊断尿液性状文本描述对应的待计算特征分词;
计算模块30,用于建立语义相似度算法,根据语义相似度算法计算待计算特征分词与映射关系库中各信息数据的语义相似度;
辅助诊断模块40,用于根据语义相似度,对待诊断尿液性状文本描述进行诊断。
进一步地,如图2所示,基于上述各实施例提出本发明基于尿液性状自学习的疾病征兆预测系统的第二实施例结构框图,在本实施例中,映射关系库模块10还包括:
数据采集模块101,用于采集尿液特征分词信息数据以及对应的疾病信息,所述尿液特征分词信息数据包括:正常特征分词信息数据以及异常特征分词信息数据,正常以及异常特征分词数据包括:气味、数量、颜色、透明度以及比重数据,对应的疾病信息包括:疾病特征分词数据以及疾病症状特征分词数据;
映射关系建立模块102,用于根据尿液特征分词信息数据以及对应的疾病信息建立对应的映射关系,每个尿液特征分词信息数据至少与一个对应的疾病信息建立映射关系,根据该映射关系建立映射关系库;
应当理解的是,系统会采集尿液特征分词信息数据以及对应的疾病信息,其中尿液特征分词信息数据包括:正常特征分词信息数据以及异常特征分词信息数据,同时,正常以及异常特征分词数据包括:气味、数量、颜色、透明度以及比重数据,对应的疾病信息包括:疾病特征分词数据以及疾病症状特征分词数据。
应当理解的是,一般来说,尿液在正常情况下,颜色:淡黄色~深黄;尿量:成人1.0~1.5l/24h;儿童(1~12岁)0.3~1.l/24h;老年(>60岁)0.25~2.4l/24h;透明度:新鲜尿透明;气味:有酸味;比重:晨尿1.015~1.025。这里,考虑到下一步计算效率以及预测的准确性的问题,可以把尿液性状特征信息分为五个类别:即尿液的颜色(即尿色。发红、发黄、发绿等)、尿液的数量(即尿量。一般24小时尿量多于2.5l即为多尿;尿量<0.4l/24小时(或17ml/小时)者称为少尿;尿量少于100ml/24小时者,称为无尿或尿闭。)、尿液的气味(即尿味包括:酸臭味、鱼腥味等)、尿液的透明度(泡沫状、乳白状等)、尿液的酸碱度(正常尿液多呈弱酸性,ph约为6.5,有时呈中性或弱碱性)、尿液的比重(正常成人在普通饮食下尿比重多波动在1.015~1.025之间。大量饮水时尿比重可降至1.003以下;机体缺水时可达1.030以上)以及什么时段的尿液等等。
应当理解的是,之后系统会采集尿液特征分词信息数据与数据以及与之对应的疾病和疾病症状特征信息和数据,建立尿液特征分词信息数据与数据以及与之对应的疾病和疾病症状特征信息映射关系的数据库(包括各自对应的词典和对应的特征信息分词词库与数据库),其中词典是由管理员预先存储的关于本领域专业术语的词语集合,用于对特征分词进行判断。
应当理解的是,因为尿液不同的颜色、尿液的多少、尿液的不同气味、以及尿液不同的形态以及在不同时段(早上、夜里等)的尿液可能预示和对应泌尿系统不同的病患。比如,尿液的气味与泌尿系统疾病映射关系。正常的尿液,长时间放置,会分解出现氨臭味。但如果新排出的尿液就有氨味,常表示有慢性膀胱炎和慢性尿潴留。若排出的尿液带有粪臭味,很可能是大肠杆菌感染;若有苹果味,则多是糖尿病酮症酸中毒所致。再比如,尿液的颜色与泌尿系统疾病映射关系。尿液颜色除了疾病造成之外,还容易受到饮食、药物等影响。尿液颜色近无色透明一般见于过多饮水、糖尿病、尿崩症、多囊肾、慢性肾功能不全等;尿液颜色乳白色一般见于泌尿系统化脓性感染、前列腺炎、丝虫病(乳糜尿呈牛奶样)、肾病或挤压伤(脂肪尿)、尿中有大量磷酸盐或磷酸盐结晶;尿液颜色黄色一般见于服用药物,如峡哺妥因(味喃坦陡)、小檗碱(黄连素)、维生素b2等;尿液颜色深黄色一般见于发热性疾病、各种黄疽(将尿振荡后可产生黄色泡沫);如果尿液颜色为红色,血尿呈洗肉水样红色混浊,见于急性肾小球肾炎及其他泌尿系统的炎症、结石、肿瘤性疾病;尿液颜色酱油色一般见于血型不合时的输血、阵发性睡眠性血红蛋白尿症等,以及服用氨基比林、柔红霉素等药物。
进一步地,如图3所示,基于上述各实施例提出本发明基于尿液性状自学习的疾病征兆预测系统的第三实施例结构框图,在本实施例中,特征分词提取模块20还包括:
匹配模块201,用于获取待诊断尿液性状文本描述,获取映射关系库中尿液特征分词信息数据的字符数,根据该字符数对待诊断尿液性状文本描述进行匹配查找,当匹配查找到对应文本描述时,提取该文本描述作为待计算特征分词。
应当理解的是,系统在建立了映射关系之后,会获取待诊断尿液性状文本描述,首先将其输入已经建好的映射关系的信息库,然后通过基于字典、词库匹配的分词方法,提取得到该待诊断尿液性状文本描述的初始特征分词。通过这种方式,提起提取出待诊断尿液性状文本描述中的特征分词,方便后续系统进行计算,避免了系统在诊断时仍需要提取待诊断尿液性状文本描述中的特征分词的步骤,提高了系统诊断速度,这种方法按照一定策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。识别出一个词,根据扫描方向的不同分为正向匹配和逆向匹配。根据不同长度优先匹配的情况,分为最大(最长)匹配和最小(最短)匹配。根据与词性标注过程是否相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。本实施例使用的是最大正向匹配法。
应当理解的是,一些常用的方法包括:
最大正向匹配法(maximummatchingmethod)通常简称为mm法。其基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。若字典中存在这样的一个i字词,则匹配成功,匹配字段被作为一个词切分出来。如果词典中找不到这样的一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字串重新进行匹配处理,如此进行下去,直到匹配成功,即切分出一个词或剩余字串的长度为零为止。这样就完成了一轮匹配,然后取下一个i字字串进行匹配处理,直到文档被扫描完为止。
逆向最大匹配法(reversemaximummatcingmethod)通常简称为rmm法。rmm法的基本原理与mm法相同,不同的是分词切分的方向与mm法相反,而且使用的分词辞典也不同。逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的2i个字符(i字字串)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。相应地,它使用的分词词典是逆序词典,其中的每个词条都将按逆序方式存放。在实际处理时,先将文档进行倒排处理,生成逆序文档。然后,根据逆序词典,对逆序文档用正向最大匹配法处理即可。由于汉语中偏正结构较多,若从后向前匹配,可以适当提高精确度。所以,逆向最大匹配法比正向最大匹配法的误差要小。统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。例如切分字段“尿液颜色棕红色”,正向最大匹配法的结果会是“尿液颜色棕红/色”,而逆向最大匹配法利用逆向扫描,可得到正确的分词结果“尿液/颜色/棕红色”。
进一步地,如图4所示,基于上述各实施例提出本发明基于尿液性状自学习的疾病征兆预测系统的第四实施例结构框图,在本实施例中,计算模块30包括:
语义相似度计算模块301,用于建立语义相似度算法,通过语义相似度算法计算待计算特征分词与映射关系库中尿液特征分词信息数据以及疾病信息之间的语义相似度。
应当理解的是,系统会根据获取到的尿液异常性状特征信息以及与之对应的疾病和疾病症状特征信息的匹配关系,建立尿液异常性状特征信息与相应疾病和疾病对之间特征信息的语义相似度的计算模型。关于相似度的计算,现有的几种基本方法都是基于向量(vector)的,其实也就是计算两个向量的距离,距离越近相似度越大。在这个场景中,在待诊断尿液性状用户与可能的疾病或者健康状况的二维矩阵中,我们可以将一个待诊断尿液性状用户对所有泌尿以及相应系统疾病作为一个向量来计算他们之间的相似度,或者将所有用户对某一个泌尿以及相应系统疾病的倾向作为一个向量来计算他们之间的相似度。为更精确的划分和提高模型预测的准确率,在本实施例中,所述尿液异常性状特征信息和/或对应疾病对的表示包括多个义原描述和关系符号描述。进一步的,具体计算模型和计算方法如下:
由于上述特征信息表示(分词或者短语)不是组织在一个树状的层次体系中,而是一种网状结构;因此可以借助义原和符号对概念进行描述。对于两个词条w1(尿液性状的目标特征信息)和w2(泌尿以及相应系统疾病的目标症状或者征兆特征信息),w1有个n特征信息义项(概念,分词或者短语):s11,s12,...,s1n,w2有个m特征信息义项(概念,分词或者短语):s11,s12,...,s1m,那么,w1和w2的相似度是各个特征信息义项(概念,分词或者短语)的相似度之最大值,也就是说:
在上述计算模型中,为了更加精确地计算出它们之间的语义相似度,我们把它们的描述可以表示为一个特征结构,该特征结构含有以下四个特征:
第一基本义原描述:其值为一个基本义原,将两个概念的这一部分的相似度记为sim1(s1,s2);
其它基本义原描述:对应于语义表达式中除第一基本义原描述式以外的所有基本义原描述式,其值为一个基本义原的集合,将两个概念的这一部分的相似度记为sim2(s1,s2);
关系义原描述:对应于语义表达式中所有的关系义原描述式,其值是一个特征结构,对于该特征结构的每一个特征,其属性是一个关系义原,其值是一个基本义原,或一个具体词。将两个概念的这一部分的相似度记为sim3(s1,s2);
关系符号描述:对应于语义表达式中所有的关系符号描述式,其值也是一个特征结构,对于该特征结构的每一个特征,其属性是一个关系义原,其值是一个集合,该集合的元素是一个基本义原,或一个具体词。将两个概念的这一部分的相似度记为sim4(s1,s2);
由此可见,由于各个义原所处的层次不一样,因而它们对词语相似度的影响程度也不一样,也就是说部分相似性在整体相似性中所占的权重是不一样的,权重(百分比)用β表示,于是,概念的整体相似度可以记为:
其中,β(1≤i≤4)是可调节的参数,且有:β1+β2+β3+β4=1,β1≥β2≥β3≥β4。后者反映了sim1(s1,s2)到sim4(s1,s2)对于总体相似度所起到的作用依次递减。由于第一独立义原描述式反映了一个概念最主要的特征,所以应该将其权值定义得比较大,一般应在0.5以上。在以上计算中,最后求加权平均时,各部分取相等的权值。这样,就把两个词语之间的相似度问题归结到了两个概念之间的相似度问题。然后利用机器学习和神经网络分类的方法,建立尿液性状的特征信息与泌尿以及相应系统疾病症状间特征信息语义相似度的计算模型。常见的计算语义相似度的机器学习模型包括:dssm(deepstructuredsemanticmodels)、cnn-dssm(convolutionallatentsemanticmodel)、lstm-dssm(long-short-termmemorydeepstructuredsemanticmodels)。当然,除了上述方法外,还可以利用夹角余弦(cosine)算法的方式来实现。
应当理解的是,为进一步提高预测的准确率,所述计算模型还包括将影响尿液性状的间接空间关系因子λ(包括直接关系:比如尿液的颜色、尿液的数量、尿液的气味、尿液的透明度以及什么时段的尿液等;间接关系:年龄、性别等),设定为可变或固定的权重,例如将直接关系设为固定权重λ,间接关系设为可变权重,作为相似度的权重系数(与调节参数相似度β相加或相乘)参与尿液性状认知模型里面进行匹配和加权计算。
进一步地,如图5所示,基于上述各实施例提出本发明基于尿液性状自学习的疾病征兆预测系统的第五实施例结构框图,在本实施例中,辅助诊断模块40包括:
报告生成模块401,用于设定语义相似度阈值,将语义相似度与语义相似度阈值进行比较,当语义相似度大于语义相似度阈值时,根据该语义相似度,生成对应诊断报告;当语义相似度小于语义相似度阈值时,重新选择语义相似度进行比较。
应当理解的是,系统最后会设定语义相似度阈值,语义相似度阈值由管理员进行设定,将语义相似度与语义相似度阈值进行比较,当语义相似度大于语义相似度阈值时,根据该语义相似度,生成对应诊断报告;当语义相似度小于语义相似度阈值时,重新选择语义相似度进行比较。比如:尿量,正常成人每昼夜尿量在du1500~2000ml之间。24小时之内尿量少于400ml或每小时不足17ml者称少尿;24小时尿量少于100ml者称为无尿。其原因有肾前性(如休克、失水、电解质紊乱等)、肾性(如急慢性肾炎、急性肾小管坏死等)、肾后性(结石、肿瘤等各种原因所致的尿路梗阻)。无尿可见于严重的急性肾功能衰竭。成人24小时尿量超过2500ml者为多尿,见于生理性多尿、内分泌疾病、肾脏疾病如肾小管功能不全等;尿色,正常尿液呈淡黄色,尿色的深浅与尿量、体内代谢有关。高热、尿量少则色深,尿量多则色浅。常见的尿色异常有:食物和药物因素;血尿;血红蛋白尿,呈浓茶色或酱油色,见于血管内或泌尿系统内溶血;胆色素尿,尿呈深黄色,见于黄疸;乳糜尿,为白色乳糜样尿液,见于丝虫病等引起的肾周围淋巴管阻塞;透明度,正常新鲜的尿液是透明的,放置后可出现轻微混浊。碱性尿时易析出灰白色结晶,酸性尿时呈淡红色结晶。新鲜尿液混浊可见于血尿、脓尿、菌尿、脂尿、乳糜尿或尿液含有多量的上皮细胞;尿的气味,尿液长时间放置,因尿素分解可出现氨臭味。如尿液新排出即有氨味,常提示有慢性膀胱炎和慢性尿潴留;大肠杆菌感染时尿液可带有粪臭味,糖尿病酮症酸中毒时尿有苹果味;酸碱度,正常尿液多呈弱酸性,ph约为6.5,有时呈中性或弱碱性。酸性尿可见于高蛋白饮食、酸中毒、发热、严重缺钾、痛风,服用某些药物如氯化铵、维生素c等、碱性尿见于进食多量蔬菜水果、碱中毒、ⅰ型肾小管酸中毒、服用某些药物如碳酸氢钠、噻嗪类利尿剂等;比重,正常成人在普通饮食下尿比重多波动在1.015~1.025之间。大量饮水时尿比重可降至1.003以下;机体缺水时可达1.030以上。病理性尿比重降低可见于慢性肾功能损害、肾小管浓缩能力减退、尿崩症等。糖尿病、大量出汗、呕吐、腹泻和高热等脱水状态,尿比重上升。尿比重可粗略代表尿的渗透压,以此测知肾浓缩功能的大致情况。
需要说明的是,以上仅为举例说明,并不对本申请的技术方案构成任何限定。
通过上述描述不难发现,本实施例提出了一种基于尿液性状自学习的疾病征兆预测系统,包括:映射关系库模块,用于获取尿液特征分词信息数据以及对应的疾病信息,根据该尿液信息数据以及对应的疾病信息建立映射关系库;特征分词提取模块,用于获取待诊断尿液性状文本描述,通过最大正向匹配法将尿液性状文本描述与映射关系库中特征分词信息数据进行匹配,根据匹配结果获取待诊断尿液性状文本描述对应的待计算特征分词;计算模块,用于建立语义相似度算法,根据语义相似度算法计算待计算特征分词与映射关系库中各信息数据的语义相似度;辅助诊断模块,用于根据语义相似度,对待诊断尿液性状文本描述进行诊断。本实施例通过建立映射关系库将尿液特征分词信息数据以及对应的疾病信息紧密联系起来,通过语义相似度算法能够精确对待诊断尿液数据进行诊断,提高了诊断速度与精确度。
此外,本发明实施例还提出一种基于尿液性状自学习的疾病征兆预测设备。如图6所示,该基于尿液性状自学习的疾病征兆预测设备包括:映射关系库单元10、特征分词提取单元20、计算单元30以及辅助诊断单元40。
映射关系库单元10,用于获取尿液特征分词信息数据以及对应的疾病信息,根据该尿液信息数据以及对应的疾病信息建立映射关系库;
特征分词提取单元20,用于获取待诊断尿液性状文本描述,通过最大正向匹配法将尿液性状文本描述与映射关系库中特征分词信息数据进行匹配,根据匹配结果获取待诊断尿液性状文本描述对应的待计算特征分词;
计算单元30,用于建立语义相似度算法,根据语义相似度算法计算待计算特征分词与映射关系库中各信息数据的语义相似度;
辅助诊断单元40,用于根据语义相似度,对待诊断尿液性状文本描述进行诊断。
此外,需要说明的是,以上所描述的装置实施例仅仅是示意性的,并不对本发明的保护范围构成限定,在实际应用中,本领域的技术人员可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的,此处不做限制。
另外,未在本实施例中详尽描述的技术细节,可参见本发明任意实施例所提供的基于尿液性状自学习的疾病征兆预测系统,此处不再赘述。
以上所述仅为本发明的较佳实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!