基于多相似度融合的药物新用途预测方法与流程
1.本发明属于药物用途预测领域,具体涉及一种基于多相似度融合的药物新用途预测方法。
背景技术:
2.药物重定位(drug repurposing),俗称“老药新用”,是指通过现有的技术手段将已经产生适应症的药物重新定位,寻找其新的适应症。药物重定位这一概念自被提出以来,国内外学者对该领域的研究投入了巨大的精力。chiang等人提出了一种从疾病的角度看待药物重定位的观点,当两种疾病可以被多种相同的药物治疗时,认为两种疾病是相似的。如果存在一种药物只对其中一种疾病有治疗效果,则认为该药对另一种疾病也存在潜在的治疗关系,可以作为治疗该疾病的候选药物。药物的化学结构被认为可以用来度量药物间相似性,dudley等人提出药物的化学性质与其治疗效果有密切的关系,药物的化学结构和生物活性之间存在定量关系,所以药物的化学结构是药物重定位的研究方向。药物靶蛋白是药物治疗疾病的关键因素,含有相似靶蛋白的药物也可能会有类似的作用效果,因此靶蛋白可以作为药物重定位中度量药物相似性的一个研究角度。同样,与药物对疾病的治疗效果类似,药物产生的副作用提供了人类的表型特征,因此从药物的副作用角度进行药物重定位的研究也是可行的。以上传统的基于协同过滤的药物重定位算法虽然有一定的效果,但仍有很大的进步空间,传统的方法都是从多个角度中的一类或两类进行药物重定位研究,可能会导致预测值的偏差。
技术实现要素:
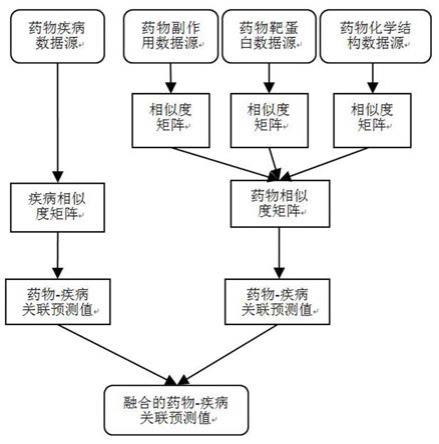
3.本发明的目的是针对上述问题,提供一种基于多相似度融合的药物新用途预测方法,分别利用药物化学结构、药物靶蛋白和药物副作用数据计算药物相似度,再加权求和得到融合的药物相似度,基于融合的药物相似度计算得到的药物
‑
疾病关联预测值,避免了依靠单一数据源计算药物对疾病预测值的偏差问题;利用谷本系数计算疾病相似度,基于疾病相似度计算得到的药物
‑
疾病关联预测值,与基于药物相似度计算得到的药物
‑
疾病关联预测值加权求和,得到融合后的药物对疾病的预测值,提高预测值的可靠性。
4.本发明的技术方案是基于多相似度融合的药物新用途预测方法,包括以下步骤,
5.步骤1:利用药物化学结构数据计算药物相似度;
6.步骤2:利用药物靶蛋白数据计算药物相似度;
7.步骤3:利用药物副作用数据计算药物相似度;
8.步骤4:对步骤1
‑
3计算得到的药物相似度进行融合,得到融合的药物相似度;
9.步骤5:利用融合的药物相似度,计算药物
‑
疾病关联预测值;
10.步骤6:利用药物
‑
疾病数据计算疾病相似度,基于疾病相似度计算药物
‑
疾病关联预测值;
11.步骤7:对步骤5、6的预测值进行融合,得到融合的药物
‑
疾病关联预测值。
12.步骤4中,融合的药物相似度的计算式如下:
13.sim
d
=αsim
s
+βsim
p
+γsim
f
14.式中sim
d
表示融合得到的药物a和药物b的药物相似度,sim
s
表示利用药物化学结构数据计算的药物a和药物b的药物相似度,sim
p
表示利用药物靶蛋白数据计算的药物a和药物b的药物相似度,sim
f
表示利用药物靶蛋白数据计算的药物a和药物b的药物相似度,α、β、γ分别表示利用药物化学结构、药物靶蛋白、药物靶蛋白数据计算的药物相似度的权重,α+β+γ=1。
15.步骤5中,药物
‑
疾病关联预测值的计算式如下:
[0016][0017]
式中表示利用药物相似度计算的药物a对疾病q的疗效的预测值;sim(d
a
,d
b
)表示药物a
[0018]
和药物b的药物相似度,t为药物a的邻居集合,表示基于药物疾病数据计算得到的药物
[0019]
a与所有疾病的药物
‑
疾病对应关系值的平均值,表示基于药物疾病数据计算得到的药物b与所有疾病的药物
‑
疾病对应关系值的平均值,s
b,q
表示药物b与疾病q的药物
‑
疾病对应关系值。
[0020]
步骤6中,利用谷本系数计算疾病相似度,计算式如下:
[0021][0022]
式中sim(i
q
,i
y
)表示疾病q和疾病y的疾病相似度,i
q
表示可治疗疾病q的药物数量,i
y
表示可治疗疾病y的药物数量,|i
qy
|表示可以同时治疗疾病q和疾病y的药物数量,sim(i
q
,i
y
)的值在区间[0,1]内。
[0023]
步骤6中,基于疾病相似度计算药物
‑
疾病关联预测值的计算式如下:
[0024][0025]
式中表示利用疾病相似度计算的药物a对疾病q的疗效的预测值;sim(i
q
,i
y
)表示疾病q和疾病y的疾病相似度,t为疾病q的邻居集合,s
a,y
表示药物a与疾病y的药物
‑
疾病对应关系值。
[0026]
步骤7中,融合的药物
‑
疾病关联预测值的计算式如下
[0027][0028]
式中p
aq
为融合后的药物a与疾病q的药物
‑
疾病关联预测值,表示利用疾病相似
度计算的药物a对疾病q的疗效的预测值;表示利用药物相似度计算的药物a对疾病q的疗效的预测值;ω1、ω2分别表示利用疾病相似度、药物相似度计算的药物
‑
疾病关联预测值的权重,ω1+ω2=1。
[0029]
相比现有技术,本发明的有益效果:
[0030]
1)本发明对基于药物相似度计算得到的药物
‑
疾病关联预测值,和基于疾病相似度计算得到的药物
‑
疾病关联预测值加权求和,得到融合后的药物对疾病的预测值,提高了预测值的可靠性和精确性;
[0031]
2)本发明分别利用药物化学结构、药物靶蛋白和药物副作用数据计算药物相似度,再加权求和得到融合的药物相似度,基于融合的药物相似度计算得到的药物
‑
疾病关联预测值,避免了单一数据源的数据稀疏、噪声数据对计算结果的影响。
[0032]
3)本发明利用谷本系数计算疾病相似度,相比余弦相似度的计算方法,在不影响相似度准确性的情况下,简化了计算的复杂程度。
附图说明
[0033]
下面结合附图和实施例对本发明作进一步说明。
[0034]
图1为本发明实施例计算融合的药物
‑
疾病关联预测值的示意图。
具体实施方式
[0035]
如图1所示,基于多相似度融合的药物新用途预测方法,包括以下步骤,
[0036]
步骤1:利用药物化学结构数据计算药物相似度,计算式如下:
[0037][0038]
式中sim
s
表示利用药物化学结构数据计算的药物a和药物b的相似度,d
1a
表示药物a包含的化学结构数量,d
1b
表示药物b包含的化学结构数量,|d
1ab
|表示药物a和药物b包含的相同化学结构数量;
[0039]
步骤2:利用药物靶蛋白数据计算药物相似度,计算式如下:
[0040][0041]
式中sim
p
表示利用药物靶蛋白数据计算的药物a和药物b的相似度,d
2a
表示药物a对应的靶蛋白数,d
2b
表示药物b对应的靶蛋白数,|d
2ab
|表示药物a和药物b对应的相同靶蛋白数;
[0042]
步骤3:利用药物副作用数据计算药物相似度,计算式如下:
[0043][0044]
式中sim
f
表示利用药物副作用数据计算的药物a和药物b的相似度,d
3a
表示药物a会产生的副作用数,d
3b
表示药物b会产生的副作用数,|d
3ab
|表示药物a和药物b产生的相同副作用数;步骤4:对步骤1
‑
3计算得到的药物相似度进行融合,得到融合的药物相似度,计算式如下
[0045]
sim
d
=αsim
s
+βsim
p
+γsim
f
[0046]
式中sim
d
表示融合得到的药物a和药物b的药物相似度,sim
s
表示利用药物化学结构数据计算的药物a和药物b的药物相似度,sim
p
表示利用药物靶蛋白数据计算的药物a和药物b的药物相似度,sim
f
表示利用药物靶蛋白数据计算的药物a和药物b的药物相似度,α、β、γ分别表示利用药物化学结构、药物靶蛋白、药物靶蛋白数据计算的药物相似度的权重,α+β+γ=1,α、β、γ的取值采用试探法,以0.1为步长进行试探,通过多次实验确定一组能使效果最优的权值。通过试探法得出当α=0.2,β=0.4,γ=0.4时,效果达到最优;
[0047]
步骤5:利用融合的药物相似度,计算药物
‑
疾病关联预测值,计算式如下
[0048][0049]
式中表示利用药物相似度计算的药物a对疾病q的疗效的预测值;sim(d
a
,d
b
)表示药物a和药物b的相似度,t为药物a的邻居集合,表示基于药物疾病数据计算得到的药物a与所有疾病的药物
‑
疾病对应关系值的平均值,表示基于药物疾病数据计算得到的药物b与所有疾病的药物
‑
疾病对应关系值的平均值,s
b,q
表示药物b与疾病q的药物
‑
疾病对应关系值;
[0050]
步骤6:利用药物
‑
疾病数据计算疾病相似度,基于疾病相似度计算药物
‑
疾病关联预测值;疾病相似度的计算式如下:
[0051][0052]
式中sim(i
q
,i
y
)表示疾病q和疾病y的疾病相似度,i
q
表示可治疗疾病q的药物数量,i
y
表示可治疗疾病y的药物数量,|i
qy
|表示可以同时治疗疾病q和疾病y的药物数量,sim(i
q
,i
y
)的值在区间[0,1]内;
[0053]
基于疾病相似度计算药物
‑
疾病关联预测值,计算式如下
[0054][0055]
式中表示利用疾病相似度计算的药物a对疾病q的疗效的预测值;sim(i
q
,i
y
)表示疾病q和疾病y的疾病相似度,t为疾病q的邻居集合,s
a,y
表示药物a与疾病y的药物
‑
疾病对应关系值。
[0056]
步骤7:对步骤5、6的预测值进行融合,得到融合的药物
‑
疾病关联预测值,计算式如下
[0057][0058]
式中p
aq
为融合后的药物a与疾病q的药物
‑
疾病关联预测值,表示利用疾病相似
度计算的药物a对疾病q的疗效的预测值;表示利用药物相似度计算的药物a对疾病q的疗效的预测值;ω1、ω2分别表示利用疾病相似度、药物相似度计算的药物
‑
疾病关联预测值的权重,ω1+ω2=1,实施例中ω1=0.6,ω2=0.4;
[0059]
实施例中,药物化学结构数据从pubchem数据库进行采样,药物靶蛋白数据从uniport knowledgebase数据库中采样,药物副作用数据从sider数据库中采样。本发明的融合相似度的方法有效地缓解了单个数据源因为数据稀疏而导致计算出的有效相似度较少的问题。
[0060]
实施例中,对于疾病相似度的计算只考虑药物与疾病是否有对应的治疗关系,而不考虑治疗效果的优劣,所以疾病相似度通过谷本系数进行,与使用余弦相似度等方法相比,在不影响相似度准确性的情况下,简化了计算的复杂程度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1