一种基于真实世界数据的消化性溃疡治疗方案的预测系统的制作方法
1.本发明涉及机器学习技术领域,更具体的说是涉及一种基于真实世界数据的消化性溃疡治疗方案的预测系统。
背景技术:
2.消化性溃疡主要指发生于胃和十二指肠的慢性溃疡,是一多发病、常见病。主要症状为上腹疼痛呈反复周期性发作,疼痛发作可持续几天、几周或更长,严重影响患者的身体和心理健康。导致消化性溃疡的危险因素较多,如应激,幽门螺杆菌感染等,不同因素引起的消化性溃疡在临床治疗方案上存在一定差异,但是由于医疗水平的不同,不同地区的患者因消化性溃疡到各医疗机构就诊时难以均得到相对正确的治疗。
3.随着互联网信息技术的发展,人工智能技术逐渐成熟,如果能将人工智能技术用于辅助医务人员进行消化性溃疡的诊疗,就能在一定程度上解决上述问题;真实世界研究是近年来不断得到重视的临床研究类型,正确的运用真实世界研究可降低临床研究成本,同时真实世界研究所产生的真实世界数据更接近真实的临床诊疗环境;正是由于真实世界数据的这一特点,如果使用真实世界数据训练机器学习分类算法,并使这些算法服务于医务人员对患者的诊疗,将在提高临床诊疗效率的同时为患者带来更大的福利。
4.因此,如何提供一种基于真实世界数据的消化性溃疡治疗方案的预测系统是本领域技术人员亟需解决的问题。
技术实现要素:
5.有鉴于此,本发明提供了一种基于真实世界数据的消化性溃疡治疗方案的预测系统。
6.为了实现上述目的,本发明采用如下技术方案:
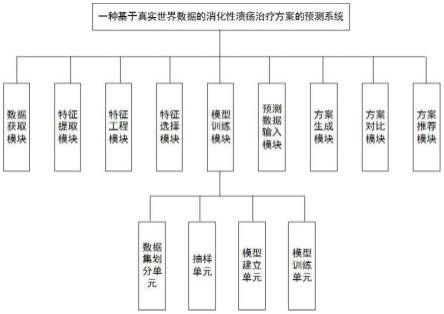
7.一种基于真实世界数据的消化性溃疡治疗方案的预测系统,包括:特征提取模块、特征选择模块、模型训练模块、预测数据输入模块、方案生成模块、方案对比模块和方案推荐模块;
8.所述特征提取模块,用于对获取到的真实世界数据进行特征提取;
9.所述特征选择模块,用于通过假设检验对所提取到的特征进行特征筛选;
10.所述模型训练模块,用于确定至少两个抽样规则,针对每个抽样规则建立一个候选机器学习分类模型,使用获取到的所有数据对所建立的候选机器学习分类模型进行训练;
11.所述预测数据输入模块,用于向待预测者提供输入端口,并接收待预测者输入的相关数据;
12.所述方案生成模块,用于将所获取到的待预测者输入的相关数据输入至训练好的所有机器学习模型中,获取预测方案;
13.所述方案对比模块,用于获取所述方案生成模块生成的所有预测方案,对不同内
容的预测方案进行计数,将数量最多的所述预测方案作为最终预测方案;并将用于预测的所有数据以及所获取到的最终预测方案均发送至所述模型训练模块;
14.所述方案推荐模块,用于将所述最终预测方案进行推荐。
15.优选的,还包括:数据获取模块;
16.所述数据获取模块,用于从真实世界数据源中获取真实世界数据,其中真实世界数据源包括:医院信息系统、电子病历系统、医保理赔数据库、公共卫生调查数据库和公共卫生监测数据库。
17.优选的,所述第一特征包括:患者人口学信息、患者既往史、患者实验室检查结果、患者影像学资料、患者饮食情况、患者家庭信息和患者医保信息。
18.优选的,还包括:特征工程模块;
19.所述特征工程模块,用于对所述特征选取模块提取的特征进行特征工程获取到第二特征;其中所述特征选取模块提取的特征为第一特征;
20.所述特征工程包括:数据中心化、数据离散化、主成分分析和核变换。
21.优选的,所述假设检验方法包括:
22.若所获取到的特征是连续且服从正态分布的,则使用t检验或方差分析方法进行假设检验;
23.若所获取到的特征是连续但不服从正态分布的,则使用秩和检验方法进行假设检验;
24.若所获取到的特征是等级资料或定性资料,则使用卡方检验方法进行假设检验;
25.当假设检验得到的p值低于预定的显著性水平时,则当前特征则用于机器学习训练过程。
26.优选的,所述模型训练模块包括:数据集划分单元、抽样单元、模型建立单元和模型训练单元;
27.所述数据集划分单元,用于将所获取到的真实世界数据随机划分为训练集和验证集,并实时接收所述方案对比模块所接收到的待预测数据以及所生成的所述最终预测方案,同样随机划分为训练集或验证集,所述训练集和所述验证集分别用于对候选机器学习分类模型的训练或验证;
28.所述抽样单元,用于确定至少两个抽样规则,从获取到的特征中抽取部分特征子集,所述特征子集内容不完全一致;
29.所述模型建立单元,用于针对每个所述特征子集分别建立一个候选机器学习分类模型;
30.所述模型训练单元,用于使用所述训练集对所建立的候选机器学习分类模型进行训练;并通过验证集对候选机器学习分类模型进行性能评估。
31.经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于真实世界数据的消化性溃疡治疗方案的预测系统,该系统应用真实世界研究,从真实世界数据中获取相应的数据来对模型进行训练和验证,能为模型的训练和验证提供更为有效的数据基础,使训练后的模型更加准确,为处于不同医疗水平的患者提供了统一的消化性溃疡治疗方案预测方法,解决了现有技术中由于医疗水平不同为消化性溃疡治疗带来隐患的问题,进一步提高了自动化水平,为患者带来更大的福利。
附图说明
32.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
33.图1附图为本发明提供的一种基于真实世界数据的消化性溃疡治疗方案的预测系统结构示意图;
34.图2附图为本发明提供的一种基于真实世界数据的消化性溃疡治疗方案的预测系统的工作原理图。
具体实施方式
35.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
36.本发明实施例公开了一种基于真实世界数据的消化性溃疡治疗方案的预测系统,包括:特征提取模块、特征选择模块、模型训练模块、预测数据输入模块、方案生成模块、方案对比模块和方案推荐模块;
37.特征提取模块,用于对获取到的真实世界数据进行特征提取;
38.特征选择模块,用于通过假设检验对所提取到的特征进行特征筛选;
39.模型训练模块,用于确定至少两个抽样规则,针对每个抽样规则建立一个候选机器学习分类模型,使用获取到的所有数据对所建立的候选机器学习分类模型进行训练;
40.预测数据输入模块,用于向待预测者提供输入端口,并接收待预测者输入的相关数据;
41.方案生成模块,用于将所获取到的待预测者输入的相关数据输入至训练好的所有机器学习模型中,获取预测方案;
42.方案对比模块,用于获取方案生成模块生成的所有预测方案,对不同内容的预测方案进行计数,将数量最多的预测方案作为最终预测方案;并将用于预测的所有数据以及所获取到的最终预测方案均发送至模型训练模块;
43.方案推荐模块,用于将最终预测方案进行推荐。
44.需要说明的是:
45.在实际应用过程中预测数据输入模块可以为上位机、移动终端等电子设备。
46.为了进一步实施上述技术方案,还包括:数据获取模块;
47.数据获取模块,用于从真实世界数据源中获取真实世界数据,其中真实世界数据源包括:医院信息系统、电子病历系统、医保理赔数据库、公共卫生调查数据库和公共卫生监测数据库。
48.需要说明的是:
49.真实世界研究的数据来源广,可来自医院日常的诊疗记录,如医院信息系统(his),电子病历系统(emr),也可来源于医保理赔数据库,公共卫生调查和公共卫生监测
(如不良反应监测)等。选取来自上述一个系统或多个系统的诊断为消化性溃疡的病例数据,数据再经过标准化为统一医学编码,统一数值单位后存储至数据库,其中医学编码方式可为meddra,hl7等。
50.为了进一步实施上述技术方案,第一特征包括:患者人口学信息、患者既往史、患者实验室检查结果、患者影像学资料、患者饮食情况、患者家庭信息和患者医保信息。
51.需要说明的是:
52.患者人口学信息如性别、年龄、地域,婚姻状况等,患者既往史如患病史,手术史,放化疗史,既往药物使用情况,吸烟和饮酒情况等,患者实验室检查结果如血常规,粪常规,尿常规,幽门螺杆菌检查结果等,患者影像学资料包括胃镜等,患者饮食情况,患者家庭信息,患者医保信息,患者治疗方案等。
53.为了进一步实施上述技术方案,还包括:特征工程模块;
54.特征工程模块,用于对特征选取模块提取的特征进行特征工程获取到第二特征;其中特征选取模块提取的特征为第一特征;
55.特征工程包括:数据中心化、数据离散化、主成分分析和核变换。
56.需要说明的是:
57.由于选取的第一特征存在数据变异程度大,维度高等问题,因此对选取的第一特征还需要进行特征工程得到第二特征,特征工程包括数据中心化,数据离散化,主成分分析,核变换等,目的是用尽可能使用分布均匀,维度低的数据训练机器学习,降低算法的复杂度以提高其性能。
58.为了进一步实施上述技术方案,假设检验方法包括:
59.若所获取到的特征是连续且服从正态分布的,则使用t检验或方差分析方法进行假设检验;
60.若所获取到的特征是连续但不服从正态分布的,则使用秩和检验方法进行假设检验;
61.若所获取到的特征是等级资料或定性资料,则使用卡方检验方法进行假设检验;
62.当假设检验得到的p值低于预定的显著性水平时,则当前特征则用于机器学习训练过程。
63.需要说明的是:
64.上述假设检验的区组因素均为治疗方案。
65.为了进一步实施上述技术方案,模型训练模块包括:数据集划分单元、抽样单元、模型建立单元和模型训练单元;
66.数据集划分单元,用于将所获取到的真实世界数据随机划分为训练集和验证集,并实时接收方案对比模块所接收到的待预测数据以及所生成的最终预测方案,同样随机划分为训练集或验证集,训练集和验证集分别用于对候选机器学习分类模型的训练或验证;
67.抽样单元,用于确定至少两个抽样规则,从获取到的特征中抽取部分特征子集,特征子集内容不完全一致;
68.模型建立单元,用于针对每个特征子集分别建立一个候选机器学习分类模型;
69.模型训练单元,用于使用训练集对所建立的候选机器学习分类模型进行训练;并通过验证集对候选机器学习分类模型进行性能评估。
70.需要说明的是:
71.根据一定的比例将数据随机划分为训练集和验证集,训练集和验证集划分的比例包括但不限于1:1,6:4,7:3,比如数据集中有1000例病例数据,如采取7:3的比例划分训练集和验证集,则训练集和验证集分别有700例和300例病例数据,且对数据集的任一病例数据,均有相同的机会被分配到训练集或验证集。
72.对于选取的两个或多个模型,使用训练集数据对模型对进行训练,使用预测集数据对模型的性能进行评估,性能评估的指标包括准确率,查准率,查全率,f1值等。
73.下面通过一个示例展示该系统的具体技术流程:首先从医院信息系统(his),电子病历系统(emr)等获取真实世界数据。
74.对于获取的真实世界数据,从当中选取第一特征,包括人口学信息、患者既往史、患者临床资料、实验室检查等。
75.示例性的,从真实世界数据源中获取了1000条病例数据,选取的特征包括消化性溃疡病例的性别、年龄、地域、病程、胃镜检查、rbc、幽门螺杆菌,分类目标为每个病例的消化性溃疡治疗方案。
76.表1为选取的第一特征和分类目标的一部分示例
77.表1
[0078][0079]
对于选取的第一特征,做一定的特征工程后得到第二特征,如对数据进行中心化、离散化、或使用主成分分析进行数据降维等。
[0080]
示例性的,年龄对消化性溃疡的患病和治疗方案选择有有影响,表现为不同年龄段的病例消化性溃疡患病率和治疗方案具有显著差异,获取的真实世界数据中年龄为连续性数据,所以有必要将其离散化为类别型资料,病例1的年龄为24岁,转换后为18~24岁,病例2的年龄为63岁,转换后为40~65岁。
[0081]
示例性的,病程对消化性溃疡的治疗方案选择有影响,表现为不同病程的病例消化性溃疡治疗方案具有显著差异,获取的真实世界数据中病程为变异程度大的连续性数据,所以有必要将其中心化为分布均匀的连续性资料,转换方式为:
[0082][0083]s′i为转化后的病程数值
[0084]
si为转化前的病程数值,
[0085]smin
为转化前病程数值的最小值,
[0086]smax
为转化前病程数值的最大值,
[0087]
假设病程数值的最小值为0.5,最大值为20,则病例1的病程转化前为1,转化后为0.0256,病例2的病程转化前为3,转化后为0.1282。
[0088]
表2为转化后的第二特征和分类目标的一部分示例
[0089]
表2
[0090][0091]
使用统计学假设检验的方法进行特征筛选,筛选后不同治疗方案的病例间的同一特征具有明显差异,这样可以提高分类模型的准确性。具体方式为,对于类别型特征,假设检验方法为卡方检验、确切概率法等,对于连续性资料,假设检验方法为方差分析、秩和检验等,预设假设检验显著性水平为0.05,如果假设检验的p值低于预设显著性水平则说明该特征在不同治疗方案具有显著差异,该特征被纳入用于分类模型预测的数据集,否则该特征被剔除。
[0092]
示例性的,对于性别的假设检验方法为卡方检验,结果如表3:
[0093]
表3
[0094][0095][0096]
性别和治疗方案的卡方检验p》0.05,说明不同性别的治疗方案不具有差异,性别从数据集剔除。
[0097]
示例性的,对于病程的假设检验为方差分析,结果如表4:
[0098]
表4
[0099][0100]
病程和治疗方案的方差分析p《0.05,说明不同治疗方案的病程具有差异,病程被纳入机器学习数据集。
[0101]
示例性的,对于幽门螺杆菌的假设检验方法为卡方检验,结果如表5:
[0102]
表5
[0103][0104]
幽门螺杆菌和治疗方案的卡方检验p《0.05,说明不同幽门螺杆菌检查结果的治疗方案具有差异,幽门螺杆菌被纳入机器学习数据集。
[0105]
将数据按训练集:验证集为7:3随机划分为训练集和验证集,训练集和验证集分别有700例和300例病例数据,随机分配保证了训练集和验证集的病例是同质的。
[0106]
确定两个或多个抽样规则,并根据每个抽样规则建立一个候选机器学习分类模型,抽样规则指的是对从总特征中抽取出一部分特征形成总特征的子集,子集中特征的数量大于1小于总特征数量,且保证不同抽样规则抽出的特征子集不完全一样。
[0107]
根据不同抽样规则为抽出的每个特征子集建立一个决策树分类模型。决策树模型可以是id3模型、c4.5模型和c5.0模型。决策树模型基于熵进行节点分类,熵的定义为:
[0108][0109]
每次分类应使熵的数值下降最大,直到节点中的数据全部属于同一个类别。
[0110]
示例性的,建立三个抽样规则确定三个候选机器学习分类模型,三个抽样规则抽出的特征子集及其模型分别为{a:年龄、病程、幽门螺杆菌}、{b:年龄、rbc、幽门螺杆菌}、{c:病程、胃镜检查、幽门螺杆菌}。
[0111]
使用训练集数据对模型进行训练,再使用验证集数据对模型进行性能评估,性能评估的指标为准确率,准确率定义为:
[0112][0113]
tp为模型正确阳性分类数,
[0114]
fp为模型错误阳性分类数,
[0115]
准确率超过预定阈值的模型将用于预测新增患者的治疗方案。
[0116]
示例性的,预设准确率预定阈值为98%,模型a的准确率为98.5%,模型b的准确率为99.0%,模型c的准确率为99.5%,三个模型的准确率均高于阈值,可用于消化性溃疡患者的治疗方案预测。
[0117]
当输入新的患者特征时,使用训练完成的两个或多个模型对患者用药方案进行预测,模型的输出结果为新患者的治疗方案,比较这些模型的预测结果是否一致,如果一致则该方案为患者的参考治疗方案,如果不一致,则根据模型预测结果的多数投票结果,投票数最多的为患者的推荐治疗方案。
[0118]
示例性的,新患者特征为{年龄:32,地域:农村,病程:5,胃镜检查:a2,rbc:偏低,幽门螺杆菌:阳性},当三个模型接收到新患者的特征时,模型a的输出治疗方案为奥美拉唑
+铋剂+1种抗生素,模型b的输出治疗方案为奥美拉唑+铋剂+2种抗生素,模型c的输出治疗方案为奥美拉唑+铋剂+2种抗生素,根据多数投票,治疗方案为奥美拉唑+铋剂+2种抗生素得票最多,故新患者的治疗方案为奥美拉唑+铋剂+2种抗生素。
[0119]
本发明可由软件的形式,或硬件的形式,再或者软件结合硬件的形式实施。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式实施。
[0120]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0121]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1