一种基于卷积神经网络的食管鳞癌患者生存风险预测方法
1.本发明涉及癌症风险评估技术领域,特别是指一种基于卷积神经网络的食管鳞癌患者生存风险预测方法。
背景技术:
2.食管癌是威胁全人类健康的主要恶性肿瘤之一,其发病率在全球恶性肿瘤中居第8位,死亡率居第6位,全世界每年死于食管癌的人数超过30万人,食管癌主要可分为食管腺癌和食管鳞癌。食管腺癌主要分布在以美国为主的欧美地区,食管鳞癌主要分布在以中国为主的亚洲地区。我国是全球食管癌高发地区之一,食管癌已成为了影响我国人民身体健康的重要疾病。
3.食管癌发病较为隐匿,早期症状不明显,临床发现的食管癌患者以中晚期患者居多,且患者的预后较差。根据相关统计,中晚期患者的5年整体生存率为15%
‑
34%。目前,外科手术切除联合新辅助放疗和化疗是根治食管癌的首选及最有效的治疗手段。随着食管癌发病率逐渐升高,对癌症患者进行精准的预后预测逐渐成为研究的热点。利用食管鳞癌患者各类临床数据建模并对其进行预后预测能够帮助医生对患者进行更精准的诊断和治疗,对于食管癌患者的治疗有着积极重大的意义。
4.随着现代医学的不断发展,医疗数据不断增多,从这些信息数据中获取对研究有益的数据就变得非常重要。计算机辅助下的数据分析及建模技术越来越多的应用于癌症诊疗。疾病的风险评估模型是当前广泛应用的疾病高危人群评估工具。基于数据挖掘的智能诊疗是利用大量医学数据,通过相关算法进行数据的分析,构建疾病的风险评估模型。目前国内外已建立的食管鳞癌风险评估模型多以食管鳞癌发病风险预测模型为主,食管鳞癌预后风险评估模型较少且模型预测效果较差。食管鳞癌研究需要一种能够准确判断预后风险的方法。
技术实现要素:
5.针对现有的背景技术中存在的不足,本发明提出了一种基于卷积神经网络的食管鳞癌患者生存风险预测方法,解决了现有评估模型的预测效果差,不能帮助患者判断预后效果的技术问题。
6.本发明的技术方案是这样实现的:
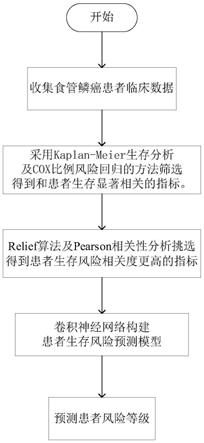
7.一种基于卷积神经网络的食管鳞癌患者生存风险预测方法,其步骤如下:
8.步骤一:获取食管鳞癌患者的m种临床表型指标、生存期信息和生存状态作为原始数据集;
9.步骤二:利用kaplan
‑
meier法和log
‑
rank法分别对m种临床表型指标与生存期信息和生存状态进行关系分析,根据分析结果将m种临床表型指标分为有用临床表型指标和无用临床表型指标;
10.步骤三:利用单因素cox回归分别对m种临床表型指标与生存期信息和生存状态进
行回归分析,得到了与步骤二相同的有用临床表型指标;
11.步骤四:根据各个有用临床表型指标和食管鳞癌患者的高低风险类别的相关性,采用relief特征选择算法计算各个有用临床表型指标的权重值,并将权重值小于权重法阈值的临床表型指标移除,得到与食管鳞癌患者生存风险相关度高的临床表型指标;
12.步骤五:利用pearson相关性分析法计算与食管鳞癌患者生存风险相关度高的临床表型指标之间的相关度,剔除相关性强的临床表型指标,最终得到与食管鳞癌患者生存风险相关度更高的独立临床表型指标;
13.步骤六:使用卷积神经网络构建食管鳞癌患者生存风险预测模型,设置卷积神经网络结构参数,将步骤五中得到的独立临床表型指标作为卷积神经网络的输入,食管鳞癌患者风险等级作为卷积神经网络的输出,将食管鳞癌患者数据集分成训练集与测试集两部分,训练集用于食管鳞癌患者生存风险预测模型的训练,测试集用于评估食管鳞癌患者生存风险预测模型的优劣。
14.所述m种临床表型指标包括年龄、白细胞计数、淋巴细胞计数、单核细胞计数、中性粒细胞计数、红细胞计数、血红蛋白浓度、血小板计数、总蛋白、白蛋白、球蛋白、凝血酶原时间、活化部分凝血活酶时间、凝血酶时间、纤维蛋白原、预后营养指数、身体质量指数和国际标准化比值;m=18;
15.所述生存期信息是指生存时间,生存时间的范围为[0.26月,137.00月];
[0016]
所述生存状态是指截止到随访结束时患者健在或者患者死亡。
[0017]
所述有用临床表型指标包括年龄、白细胞计数、单核细胞计数、中性粒细胞计数、红细胞计数、血红蛋白浓度、凝血酶原时间、国际标准化比值、凝血酶时间、纤维蛋白原、活化部分凝血活酶时间、预后营养指数;无用临床表型指标包括淋巴细胞计数、血小板计数、身体质量指数、白蛋白、总蛋白和球蛋白。
[0018]
采用relief特征选择算法计算各个临床表型指标的权重值的方法为:
[0019]
s4.1、从食管鳞癌患者的原始数据集中随机选择一个患者样本r,然后从与样本r风险类相同的样本中寻找最近邻样本h,称为near hit;
[0020]
s4.2、从与样本r风险类不同的样本中寻找最近邻样本m,称为near miss;
[0021]
s4.3、更新每个临床表型指标的权重值:如果样本r和near hit在某个特征上的距离小于样本r和near miss上的距离,降低该临床表型指标的权重;
[0022]
s4.4、重复执行m次步骤s4.1至s4.3,得到各临床表型指标的平均权重。
[0023]
所述与食管鳞癌患者生存风险相关度高的临床表型指标包括血红蛋白浓度、纤维蛋白原、活化部分凝血活酶时间、年龄、红细胞计数、预后营养指数和凝血酶原时间。
[0024]
所述利用pearson相关性分析法计算与食管鳞癌患者生存风险相关度高的临床表型指标之间的相关度的方法为:
[0025]
计算每两个临床表型指标之间的pearson相关系数:
[0026][0027]
其中,是协方差,σ
x
表示x的标准方差、σ
y
表示y的标准方差,e(x)表示临床表型指标的均值,ρ
xy
表示pearson相关系数值,j=1,2,
…
,n表示临床表
型指标的个数,x、y分别表示不同的临床表型指标数值。
[0028]
所述与食管鳞癌患者生存风险相关度更高的独立临床表型指标包括血红蛋白浓度、纤维蛋白原、活化部分凝血活酶时间、年龄、红细胞计数、预后营养指数和凝血酶原时间。
[0029]
食管鳞癌患者生存风险预测模型的准确率计算方法为:
[0030][0031]
其中,acc表示风险预测准确率,tp表示被正确地划分为高风险的个数,tn表示被错误地划分为高风险的个数,fn表示被错误地划分为低风险的个数,tn表示被正确地划分为低风险的个数。
[0032]
与现有技术相比,本发明产生的有益效果为:本发明通过传统医学分析与relief特征选择相结合,挑选出与患者生存状态有高相关的临床表型指标,然后使用卷积神经网络构建预后风险评估模型,合理、方便、有效的对食管鳞癌患者的预后风险等级进行预测,帮助患者更好的判断预后效果。
附图说明
[0033]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0034]
图1是本发明的总体流程图;
[0035]
图2本发明实施例提供的临床表型指标“白细胞计数”的kaplan
‑
meier生存曲线分析图;
[0036]
图3本发明实施例提供的临床表型指标relief算法特征选择图;
[0037]
图4本发明实施例提供的临床表型指标pearson相关性分析图;
[0038]
图5本发明实施例提供的卷积神经网络模型评价指标变化图;
[0039]
图6本发明实施例提供的卷积神经网络模型测试集预测结果混淆矩阵图。
具体实施方式
[0040]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0041]
如图1所示,本发明实施例提供了一种基于卷积神经网络的食管鳞癌患者生存风险预测方法,其步骤如下:
[0042]
步骤一:获取食管鳞癌患者的m种临床表型指标、生存期信息和生存状态作为原始数据集;收集食管鳞癌患者的临床数据;临床数据来自郑州大学第一附属医院2007年至2018年的食管鳞癌手术的患者。病例选择标准为:患者确诊为食管鳞癌,治疗过程有完整的记录且患者术后随访时间至少6个月。最终得到2007年1月至2018年12月在郑州大学附属医
院收治的食管鳞癌患者280例,其中男性患者173例(61.79%),女性患者107例(38.21%)。患者的年龄分布为38岁至81岁,平均年龄为61.19岁,年龄数据的选择符合正态分布。数据为食管癌患者术前7天常规检查记录的临床表型指标表达量。
[0043]
原始数据集包含280组样本数据,每组样本数据包括m种临床表型指标信息和生存期信息;所述m种临床表型指标的信息分别为年龄(age)、白细胞计数(white blood cell count,wbcc)、淋巴细胞计数(lymphocyte count,lyc)、单核细胞计数(monocyte count,moc)、中性粒细胞计数(neutrophil count,nec)、红细胞计数(erythrocyte count,ery)、血红蛋白浓度(hemoglobin,hgb)、血小板计数(thrombocyte count,thc)、总蛋白(total protein,tp)、白蛋白(albumin,alb)、球蛋白(globulin,glo)、凝血酶原时间(pt)、活化部分凝血活酶时间(aptt)、凝血酶时间(tt)、纤维蛋白原(fib)、预后营养指数(prognosis nutritional index,pni)、身体质量指数(bmi)、国际标准化比值(inr)。其中,m=18;所述生存期信息是指生存时间,生存期的范围为[0.26月,137.00月];生存状态是指截止到随访结束时患者的健在或者死亡的状态。
[0044]
步骤二:利用kaplan
‑
meier法和log
‑
rank法分别对m种临床表型指标与生存期信息和生存状态进行关系分析,根据分析结果将m种临床表型指标分为有用临床表型指标和无用临床表型指标;所述有用临床表型指标包括年龄、白细胞计数、单核细胞计数、中性粒细胞计数、红细胞计数、血红蛋白浓度、凝血酶原时间、国际标准化比值、凝血酶时间、纤维蛋白原、活化部分凝血活酶时间、预后营养指数;无用临床表型指标包括淋巴细胞计数、血小板计数、身体质量指数、白蛋白、总蛋白和球蛋白。
[0045]
s2.1、根据x
‑
tile软件分别计算每种临床表型指标的最佳临界值,并根据每种临床表型指标对应的最佳临界值将临床表型指标划分为高指标组和低指标组;然后将连续数值型临床表型指标进行二分类,分析血液指标与患者生存预后的相关性。根据x
‑
tile软件计算出血液指标预测总生存期的最佳临界值如表1所示。并按照临界值,将每种连续数值型临床表型指标分为两组,即高指标组和低指标组,便于下一步的研究分析。高值指标组、低值指标组为定性划分,高指标组记为”1”,低指标组记为”0”。
[0046]
表1最佳截断点数值表
[0047][0048]
使用x
‑
tile软件计算出血液指标预测总生存期的最佳临界值的操作流程如下:
[0049]
s2.1.1、新建文本文档,将原始数据集中的生存状态、生存期及第m种临床表型指标复制到文本文档中,其中,m=1,2,
…
,m;
[0050]
s2.1.2、打开x
‑
tile软件点击analyze,在“file”目录中选择“open”,选择打开步骤s21中已导入数据的文本文档;
[0051]
s2.1.3、进行分析设置,选择“生存状态”数据,点击“censor”下侧的“load”,将“生存状态”数据导入“censor”中,并将“input type”改为“alivedead”;
[0052]
s2.1.4、选择“生存期”数据,点击“survival time”下侧的“load”,将“生存期”数据导入“survival time”中,并将“intertype”改为“months”;
[0053]
s2.1.5、选择“第m种临床表型指标”数据,点击“marker1”下侧的“load”,将“第m种临床表型指标”数据导入“marker1”中;
[0054]
s2.1.6、点击“do”操作,选择“kaplan
‑
meier”—“marker1”即可得到分解结果;
[0055]
s2.1.7、点击“2popx
‑
tileplot”所指的矩形图,x
‑
tile软件自动输出第m种临床表型指标的最佳临界值,根据最佳临界值将第m种临床表型指标的数据集分为高指标组和低指标组;
[0056]
s2.1.8、循环执行步骤s2.1.1至步骤s2.1.7,直至遍历所有临床表型指标。
[0057]
以白细胞计数为例,使用x
‑
tile软件计算出最佳临界值的操作流程如下:首先,新建文本文档,将所有患者样本中的生存状态、生存期及白细胞计数值复制到文本文档中。打开x
‑
tile软件点击analyze,在“file”目录中选择“open”,选择打开已导入数据的文本文档。然后进行分析设置,选择“生存状态”数据,点击“censor”下侧的“load”,将“生存状态”数据导入“censor”中,并将“input type”改为“alivedead”。选择“生存期”数据,点击“survival time”下侧的“load”,将“生存期”数据导入“survival time”中,并将“intertype”改为“months”。选择“白细胞计数值”数据,点击“marker1”下侧的“load”,将“白细胞计数值”数据导入“marker1”中。然后点左上角的“do”,选择“kaplan
‑
meier”—“marker1”即可。出现分析结果图后,点击“2popx
‑
tileplot”所指的矩形图,软件会自动找到最佳的二分类截断值,将白细胞计数值的数据集分为两部分。
[0058]
s2.2、对于某一临床表型,将该临床表型数据二分类后,进行kaplan
‑
meier法的步骤如下:将高指标组的食管鳞癌患者记为甲组,低指标组的食管鳞癌患者记为乙组,p为生存概率,指单位时段开始存活的个体到该时段结束时仍然存活的可能性;s(t)为生存率,指观察对象活过t个单位时间的概率。
[0059]
以月为单位时间,则月生存概率的计算公式为:
[0060][0061]
当数据中无删失值,生存率的计算公式为:
[0062][0063]
当数据中有删失值,需分时段计算不同单位时间的生存概率p
i
=(i=1,2,
…
,t),然后利用概率乘法原理将p
i
相乘得到t时刻生存率,即:
[0064]
s(t)=p1×
p2×…×
p
i
;
[0065]
绘制某一分组后临床表型数据的k
‑
m生存曲线,根据计算出得不同时间点生存率,可以将随访时间作横坐标,生存率作纵坐标将各个时间点生存率连接在一起绘制该分组后临床表型数据的生存曲线,从生存曲线图中可以直观看出中位生存期。
[0066]
s2.3、对于某一临床表型,将该临床表型数据二分类后,进行log
‑
rank检验的步骤如下:将高指标组的食管鳞癌患者记为甲组,低指标组的食管鳞癌患者记为乙组,定义零和假设和备择假设:
[0067]
h0:两组患者生存曲线分布相同,
[0068]
h1:两组患者生存曲线分布不同,
[0069]
α=0.05;
[0070]
当h0成立时,两组的生存分布相同,将两组数据混合,计算合并的死亡概率,以此计算相应的期望死亡人数;两组在不同时间点期初观察例数m
1i
、m
2i
,其合计为m
i
=m
1i
+m
2i
,不同时间点两组的死亡人数为o
1i
、o
2i
,其合计为o
i
=o
1i
+o
2i
。
[0071]
计算各组期望死亡人数s
1i
和s
2i
:
[0072][0073]
分别将两组各时间点期望死亡人数相加,得到s
k
(k=1,2),则两组实际总死亡数为如果两组各时间点生存率都相同,那么两组总的期望死亡数s
k
和总的实际死亡数c
k
相差不大;检验实际数与期望数差别大小的统计量χ2:
[0074][0075]
通过查χ2界值表得,若该χ2对应的显著性值p,将显著性值p小于0.05的临床表型指标作为有用临床表型指标,将显著性值p大于0.05的临床表型指标作为无用临床表型指标。
[0076]
使用spss软件对划分后的m种临床表型指标与生存期信息和生存状态进行kaplan
‑
meier生存分析及log
‑
rank检验,得到每种临床表型指标的显著性值;使用食管鳞癌患者的二分类后的分类型临床表型指标,通过kaplan
‑
meier生存分析及log
‑
rank法研究获得食管鳞癌患者血液指标与生存预后的关系。
[0077]
使用spss软件进行kaplan
‑
meier生存分析及log
‑
rank检验的操作步骤为:
[0078]
s2.2.1、将划分后的m种临床表型指标、生存期信息和生存状态录入ibm spss statistics数据编辑器中,选择“分析
”→“
生存分析
”→“
kaplan
‑
meier”,进入选项设置界面;
[0079]
s2.2.2、在选项设置界面中,选择主对话框设置:将“生存期”数据送入“时间”框中
→
将“生存状态”数据送入“状态”框中
→
点击“定义事件
”→
定义表示事件已经发生的数值为1
→
将“第m种临床表型指标”数据分组后送入“因子”框中;
[0080]
s2.2.3、“比较因子”选项设置,在“比较因子”界面的“检验统计”项目栏内选择“秩的对数”作为检验高指标组和低指标组组间生存分布是否相同的组间比较方法;
[0081]
s2.2.4、在“选项”设置界面的“统计”项目栏中选择“平均值和中位数生存分析函数”,在“图”项目栏选择“生存分析函数”,点击“确定”,输出“第m种临床表型指标”的“生存函数曲线图”、“分析事件的平均值和中位数表”及“总体比较表”;
[0082]
s2.2.5、从步骤s2.2.4中的“总体比较表”中得到第m种临床表型指标的显著性值;
[0083]
s2.2.6、循环执行步骤s2.2.1至步骤s2.2.5,直至遍历所有临床表型指标。
[0084]
以“白细胞计数”为例,使用spss软件进行kaplan
‑
meier生存分析及log
‑
rank检验的操作步骤:首先,将数据录入ibm spss statistics数据编辑器中。然后,选择“分析
”→“
生存分析
”→“
kaplan
‑
meier”,进入选项设置界面。在选项设置界面中,选择主对话框设置:将“生存期”数据送入“时间”框中
→
将“生存状态”数据送入“状态”框中
→
点击“定义事件
”→
定义表示事件已经发生的数值为1
→
将“白细胞计数”数据分组后送入“因子”框中。“比较因子”选项设置,在“比较因子”界面的“检验统计”项目栏内选择“秩的对数”(log
‑
rank检验)作为检验指标高值组和低值组组间生存分布是否相同的组间比较方法,其他按默认选项。在“选项”设置界面的“统计”项目栏中选择“平均值和中位数生存分析函数”,在“图”项目栏选择“生存分析函数”。其他按默认选项。点击“确定”,软件输出分析结果,可以得到有关临床表型“白细胞计数”的“生存函数曲线图”、“分析事件的平均值和中位数表”及
“
总体比较表”,如表2和表3所示。
[0085]
结果分析:以“白细胞计数”指标为例。
[0086]
表2分析时间的平均值和中位数表
[0087][0088][0089]“生存分析时间的平均值和中位数”表格给出了生存时间估计的结果,显示该指标高值组与低值组两组患者的平均生存时间的估算值、标准错误和估算值的95%置信区间,以及中位生存时间的估算值、标准错误和估算值的95%置信区间。
[0090]
表3总体比较表
[0091][0092]“总体比较表”给出高值组与低值组的组间的整体比较,结果显示对两组生存曲线整体比较的log
‑
rank检验结果为显著性(p)=0.018。按照log
‑
rank检验的结果,可以认为两组患者的生存率有差异。
[0093]
图2为临床表型指标“白细胞计数”的生存函数曲线图,直观地显示“白细胞计数”低值组患者的生存曲线高于“白细胞计数”高值组患者的生存曲线。
[0094]
通过以上表2和表3信息可以得到最终结论为:“白细胞计数”指标的低值组患者的中位生存时间为67.251月,高值组患者的中位生存时间为56.146月。两组患者的生存曲线不同(log
‑
rankp=0.0018<0.05),整体来看,两组患者的生存率有差异,低值组患者的预后生存效果要优于高值组患者。
[0095]
kaplan
‑
meier生存曲线可以直观的表现出临床表型指标的高值组和低值组患者的生存率或死亡率。再经过非参数检验方法log
‑
rank检验,进行统计推断患者的临床表型指标与生存预后结果是否存在一定的关系。通过对各个临床表型指标的log
‑
rank检验得到的p值结果如表4所示。
[0096]
根据表4的结果显示,年龄、白细胞计数,单核细胞计数,中性粒细胞计数,红细胞计数,血红蛋白浓度,pt,inr,tt,fib,aptt,预后营养指数的值越大患者生存时间更长(p<0.05),而淋巴细胞计数,血小板计数,总蛋白,白蛋白,球蛋白,身体质量指数与食管癌患者的生存时间没有明显关系(p>0.05)。
[0097]
表4log
‑
rank检验表
[0098][0099][0100]
步骤三:利用单因素cox回归分别对m种临床表型指标与生存期信息和生存状态进行回归分析,得到了与步骤二相同的有用临床表型指标。具体方法为:
[0101]
cox比例风险回归模型的基本形式为:
[0102]
h(t,z)=h0(t)exp(β1*z1+β2*z2+
…
+β
p
*z
p
);
[0103][0104]
其中,h(t,z)表示具有临床表型z的食管鳞癌患者在t时刻的风险函数,表示生存时间达到t的食管鳞癌患者在t时刻的瞬时风险率,h0(t)称为基线风险函数,表示所有z都取值为0时的食管鳞癌患者在t时刻的瞬时风险率或死亡率;风险函数定义为具有临床表型z的食管鳞癌患者在生存了t时刻以后在t到t+δt这一段很短时间内死亡概率与δt之比的极限值,参数β
i'
为总体回归系数,i'=1,2,
…
,p。
[0105]
对于cox比例风险回归模型,临床表型z1使食管鳞癌患者的风险函数由h0(t)增至h0(t)exp(β1);则p个临床表型z1,z2,
…
,z
p
的共同影响下的风险函数为h(t,z)=h0(t)
·
exp(β1z1)
·
exp(β2z2)
…
exp(β
p
z
p
),使得食管鳞癌患者风险函数由h0(t)exp(β1)增至h(t,z)=h0(t)
·
exp(β1z1)
·
exp(β2z2)
…
exp(β
p
z
p
)。
[0106]
任意两个患者风险函数之比,即相对危险度rr或风险比:
[0107][0108]
rr=exp[β1(z
i'1
‑
z
j1
)+β2(z
i'2
‑
z
j2
)+
…
+β
p
(z
i'p
‑
z
jp
)];
[0109]
比值rr保持一个恒定比例,与时间t无关,称为比例风险假定(ph假定),基线风险函数h0(t)与时间变化无关,从样本数据中求出回归系数,给定非零的z值时,患者的相对危险度为定值,即各个协变量与时间变量无关的相对危险度,模型中的回归系数利用部分似然函数用最大似然估计方法得到。
[0110]
单因素cox回归分析的具体步骤如下:
[0111]
s3.1、将原始数据集录入ibm spss statistics数据编辑器中,选择“分析
”→“
生存分析
”→“
cox回归”,进入选项设置界面;
[0112]
s3.2、在选项设置界面中,选择主对话框设置:将“生存期”数据送入“时间”框中
→
将“生存状态”数据送入“状态”框中
→
点击“定义事件
”→
定义表示事件已经发生的数值为1
→
将“第m种临床表型指标”数据输入“协变量”框中
→
点击“方法”选择“输入”;
[0113]
s3.3、在“图”选项设置要绘制生存曲线,在“图类型”项目栏中选择“生存分析”作为输出的图形;
[0114]
s3.4、在“选项”设置中:选择“模型统计”项目栏中的“exp(b)的置信区间”选项,选择“显示模型信息”项目栏中的“在最后一个步骤”选项,点击“确定”,输出“第m种临床表型指标”的“方程中的变量表”;
[0115]
s3.5、从步骤s3.4中的“方程中的变量表”中得到第m种临床表型指标的显著性值;
[0116]
s3.6、判断第m种临床表型指标的显著性值是否小于0.05,若是,将第m种临床表型指标作为有用临床表型指标,否则,将第m种临床表型指标作为无用临床表型指标;
[0117]
s3.7、循环执行步骤s3.1至步骤s3.6,直至遍历所有临床表型指标。
[0118]
以“白细胞计数”为例,使用spss软件进行单因素cox回归分析的操作步骤:首先,将数据录入ibm spss statistics数据编辑器中。然后,选择“分析
”→“
生存分析
”→“
cox回归”,进入选项设置界面。在选项设置界面中,选择主对话框设置:将“生存期”数据送入“时间”框中
→
将“生存状态”数据送入“状态”框中
→
点击“定义事件
”→
定义表示事件已经发生的数值为1
→
将“白细胞计数”数据输入“协变量”框中
→
点击“方法”选择“输入”。在“图”选项设置要绘制生存曲线,在“图类型”项目栏中选择“生存分析”作为输出的图形,其他按默认选项。在“选项”设置中:选择“模型统计”项目栏中的“exp(b)的置信区间”选项。选择“显示模型信息”项目栏中的“在最后一个步骤”选项,其他按默认选项。点击“确定”,软件输出分析结果,可以得到有关临床表型“白细胞计数”的“方程中的变量表”,如表5所示。
[0119]
在构建单因素cox比例风险回归模型时,只纳入一种临床表型到cox比例回归模型中进行拟合,若模型显示该指标对结局事件的效应值有统计学显著性,则可以认为该指标对于结局事件是一个影响因素。
[0120]
单因素cox比例风险回归模型结果分析:以“白细胞计数”指标为例。
[0121]
表5方程中的变量表
[0122][0123]
指标“白细胞计数”的显著性水平p=0.018<0.05,说明该因素能够显著影响患者术后的生存状况。hr及其95%置信区间:比如对于指标“白细胞计数”来说,exp(b)=1.304,说明高值组患者发生死亡风险的概率是低值组的1.304倍。
[0124]
分别对所有的临床表型建立单因素cox回归模型,单因素分析发现年龄、白细胞计数、单核细胞计数、中性粒细胞计数、红细胞计数、血红蛋白浓度、凝血酶原时间、国际标准化比值、凝血酶时间、纤维蛋白原、活化部分凝血活酶时间、预后营养指数这些临床表型是影响食管鳞癌患者的预后生存期的因素。
[0125]
步骤四:根据各个有用临床表型指标和食管鳞癌患者的高低风险类别的相关性,采用relief特征选择算法计算各个有用临床表型指标的权重值,并将权重值小于权重法阈值的临床表型指标移除,得到与食管鳞癌患者生存风险相关度高的临床表型指标;通过relief算法根据各个临床表型指标和食管鳞癌患者的高低风险类别的相关性赋予临床表型指标不同的权重,移除权重值小于阈值的临床表型指标,得到与食管鳞癌患者生存风险相关度更高的临床表型指标。所述与食管鳞癌患者生存风险相关度高的临床表型指标包括血红蛋白浓度、纤维蛋白原、活化部分凝血活酶时间、年龄、红细胞计数、预后营养指数和凝血酶原时间。
[0126]
采用relief算法来计算各个临床表型指标的权重值。relief算法中临床表型指标和患者的高低风险类别的相关性是基于临床表型指标对食管鳞癌患者样本的生存风险类别的区分能力。采用relief特征选择算法计算各个临床表型指标的权重值的方法为:
[0127]
s4.1、从食管鳞癌患者的原始数据集中随机选择一个患者样本r,然后从与样本r风险类相同的样本中寻找最近邻样本h,称为near hit;
[0128]
s4.2、从与样本r风险类不同的样本中寻找最近邻样本m,称为near miss;
[0129]
s4.3、更新每个临床表型指标的权重值:如果样本r和near hit在某个特征上的距离小于样本r和near miss上的距离,降低该临床表型指标的权重;
[0130]
s4.4、重复执行m次步骤s4.1至s4.3,得到各临床表型指标的平均权重。临床表型指标的权重越大,表示该临床表型指标的分类能力越强,反之,表示该临床表型指标分类能力越弱。
[0131]
将食管鳞癌患者预后生存期大于l年的患者认定为低风险患者,预后生存期小于l年的患者认定为高风险患者。其中,l的取值为3。以食管鳞癌患者的高风险、低风险状态作为结局变量,通过relief算法来计算各个临床表型指标与患者高风险、低风险的相关性大小。设定的relief算法计算次数为20次,然后将多次计算得到的权重值取平均作为临床表型指标重要性的参考。权重阈值设置为0.01,即小于0.01的特征将被过滤掉,大于0.01的变量则被保留下来。分析结果如图2所示,横坐标表示各个指标的编号(1
‑
12),即包括了步骤
四得到的临床表型指标。纵坐标表示权重值,权重值越大表明两者相关性越强。
[0132]
根据matlab运行结果的分析,可以筛选得到7个重要临床表型指标:各个临床表型指标的权重值如表6所示,剔除权重值小于0.01的指标,最后得到的指标有血红蛋白浓度、纤维蛋白原、活化部分凝血活酶时间、年龄、红细胞计数、预后营养指数、凝血酶原时间七种。
[0133]
表6患者临床表型指标权重表
[0134]
编号123456指标agewbccmocneceryhgb权重值0.03960.007
‑
0.0009
‑
0.00650.01320.1436编号789101112指标ptinrapttttfibpni权重值0.01570.00160.05130.00820.11350.2827
[0135]
步骤五:利用pearson相关性分析法计算与食管鳞癌患者生存风险相关度高的临床表型指标之间的相关度,剔除相关性强的临床表型指标,最终得到与食管鳞癌患者生存风险相关度更高的独立临床表型指标;相关性分析,剔除变量中相关性较强的变量。
[0136]
计算每两个临床表型指标之间的pearson相关系数:
[0137][0138]
其中,是协方差,σ
x
表示x的标准方差、σ
y
表示y的标准方差,e(x)表示临床表型指标的均值,ρ
xy
表示pearson相关系数值,i=1,2,
…
,n表示临床表型指标的个数,x、y分别表示不同的临床表型指标数值。
[0139]
pearson相关系数是用协方差除以两个临床表型指标的标准差得到的,能反映两个临床表型指标的相关程度,pearson是一个介于
‑
1和1之间的值,当两个临床表型指标的线性关系增强时,相关系数趋于1或
‑
1;当一个临床表型指标增大,另一个临床表型指标也增大时,表明它们之间是正相关的,相关系数大于0;如果一个临床表型指标增大,另一个临床表型指标却减小,表明它们之间是负相关的,相关系数小于0;如果相关系数等于0,表明它们之间不存在线性相关关系。
[0140]
对通过relief特征选择算法筛选的变量进行pearson相关性检验,七个临床表型指标的相关性分析如图3所示。所有临床表型指标的相关性系数均小于0.5,不用剔除任何一个临床表型指标,则最终选择的指标为:血红蛋白浓度、纤维蛋白原、活化部分凝血活酶时间、年龄、红细胞计数、预后营养指数、凝血酶原时间。
[0141]
步骤六:使用卷积神经网络构建食管鳞癌患者生存风险预测模型,设置卷积神经网络结构参数,将步骤五中得到的独立临床表型指标作为卷积神经网络的输入,食管鳞癌患者风险等级作为卷积神经网络的输出,将食管鳞癌患者数据集分成训练集与测试集两部分,训练集用于食管鳞癌患者生存风险预测模型的训练,测试集用于评估食管鳞癌患者生存风险预测模型的优劣。
[0142]
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络。其具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类。具体的,卷积神经网络结构主
要包括:输入层、卷积层、池化层、全连接层以及输出层。输入层用来输入数据,卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算是提取输入的不同特征,更多层的网络能从低级特征中迭代提取更复杂的特征。池化层分别作用于每个输入的特征并减小其大小。全连接层的每一个结点都与上一层的所有结点相连,用来把前面提取到的特征综合起来,将前面得到的分布式特征映射到样本标记空间中,将输出值送给分类器。输出层输出模型分类结果。
[0143]
卷积神经网络训练过程中还需要引入激活函数,激活函数的引入是为了增加神经网络模型的非线性,加入激活函数之后,给神经元引入非线性因素,神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到非线性模型中去。
[0144]
食管鳞癌患者临床表型数据为非图像非线性连续型数据,故选择一维卷积神经网络进行处理。一维卷积神经网络是指卷积核为一维的卷积神经网络。
[0145]
使用一维卷积神经网络建立食管鳞癌患者生存风险预测模型的步骤为:
[0146]
s6.1、首先,载入数据:载入食管鳞癌患者病例信息280个样本数据,每个样本数据均包含步骤五得到的临床表型指标以及患者生存信息。将这些数据存为.csv文件,在python平台上导入数据文件。
[0147]
s6.2、通过利用python函数库中的“stratifiedshufflesplit”函数,实现对数据集的打乱划分,得到训练集与测试集,并保证得到的训练集与测试集中的高风险与低风险患者所占比例都相同。训练集与测试集分别占数据集总数的80%和20%,这里选择其中的224个样本作为训练集,来进行训练模型,56个样本作为测试集,对训练好的模型进行测试。
[0148]
s6.3、数据预处理,首先对结局变量设定标签,结局变量是指食管鳞癌患者的生存风险,生存风险的定义为,生存期大于3年定为低风险,生存期小于3年定为高风险,将高风险与低风险状态赋值,分别赋值为1和2。利用python函数库中的“keras.utils.to_categorical”函数实现对食管鳞癌患者高低风险等级的热编码。热编码是将分类变量作为二进制向量表示。将食管鳞癌患者的风险等级高风险1,低风险2用热编码分别表示为[0,1]、[1,0],使用热编码能够使得在评估模型效果,计算模型损失函数或者准确率的时候变得更加方便。数据输入卷积神经网络之前首先进行归一化,通过调用python函数库中的“standardscaler”归一化函数将划定好的训练集以及测试集进行归一化,这里的归一化是指将数据映射到[0,1]区间,防止训练时结果收敛慢、训练时间过长。
[0149]
s6.4、设置卷积神经网络结构,使用python的开源人工神经网络库keras来搭建卷积神经网络,选择keras库中的sequential()模型搭建卷积神经网络结构,卷积神经网络的结构设置如下:添加一维卷积层:设置卷积核数目、卷积核的空域长度以及输入数据的维度,设置激活函数选择为“relu”。激活函数“relu”具有线性、非饱和的形式,能够克服训练网络过程中的梯度消失问题,并且可以加快训练速度。添加flatten层,实现将多维的输入一维化。添加dropout层,dropout是指暂时丢弃一部分神经元及其连接,随机丢弃神经元可以防止过拟合,同时指数级高效地连接不同网络架构。设置dropout比例为40%。添加三个全连接层,激活函数设置为“relu”。添加输出层,输出层的激活函数设置为“sigmoid”。激活函数“sigmoid”连续、光滑、严格单调,以(0,0.5)中心堆成,是一个良好的阈值函数,常用来做二分类预测。优化器选择为随机梯度下降(stochastic gradient descent,sgd),sgd是一种简单而有效的优化算法,用于查找使成本函数最小化的函数参数值。sgd对每个训练样
本进行参数更新,每次执行都进行一次更新,且执行速度更快。频繁的更新使得参数间具有高方差,损失函数会以不同的强度波动,有助于发现新的和可能更优的局部最小值。
[0150]
s6.5、模型评估参数选择为:准确率accuracy以及损失函数loss。
[0151]
accuracy是机器学习中最简单的一种评价模型好坏的指标,模型准确率的计算公式如下:
[0152][0153]
其中,acc表示风险预测准确率,tp表示被正确地划分为高风险的个数,tn表示被错误地划分为高风险的个数,fn表示被错误地划分为低风险的个数,tn表示被正确地划分为低风险的个数。
[0154]
损失函数loss选择为“binary_crossentropy”,“binary_crossentropy”称为交叉熵损失函数,常用于二分类问题,使用“binary_crossentropy”需要在卷积神经网络的最后一层添加激活函数“sigmoid”进行配合使用。模型进行迭代优化的次数设置为30次,即当训练次数达到30次,结束模型的训练。
[0155]
模型训练及预测:设置好卷积神经网络的结构及参数之后,使用训练集数据对卷积神经网络进行训练。从图4中可以看出,随着训练次数的增加,模型的预测准确率不断增大,损失函数loss值不断减小,模型的预测效果越来越好,最终训练结束之后,模型的训练集准确率为88.57%,loss值为0.1496。模型在测试集上的准确率为80.4%,loss值为0.5632。利用训练获得的模型对测试集进行生存风险预测,输入食管癌患者临床表型指标,得到患者生存风险预测结果,对测试集的预测结果如图5所示,混淆矩阵参阅图6所示。测试集包含56个患者样本,正确预测45例,整体预测准确率为80.4%。
[0156]
卷积神经网络在少量有限的样本下很好的将食管癌病例的风险等级分类出来,充分体现了卷积神经网络对食管鳞癌患者生存风险分类预测的有效性,以及在小样本、非线性、高位中的分类识别的独特优势。
[0157]
为了进一步求证卷积神经网络在对食管鳞癌患者生存风险预测的有效性,使用相同的数据,通过bp神经网络,建立食管鳞癌患者生存风险预测模型,对比两种模型的预测效果。
[0158]
表7风险预测模型对比
[0159][0160]
如表7所示,卷积神经网络建立的模型预测效果远好于bp神经网络建立的模型。
[0161]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1