一种LncRNA和疾病关联关系的高效预测方法
一种lncrna和疾病关联关系的高效预测方法
技术领域
1.本发明涉及生物信息学领域,具体涉及一种预测lncrna和疾病关联关系的方法。
背景技术:
2.分子生物学中心法则假设遗传信息储存在蛋白质编码基因中。人类约有20000个蛋白质编码基因,占人类基因组的不到2%,其中98%以上的基因组不编码蛋白质,但产生数以万计的非编码rna(ncrna)。在ncrnas的异质性亚型中,长非编码rna(long non
‑
codingrnas,lncrnas)是一类新的转录本,长度大于200nt1
‑
3,参与生命各个阶段的许多正常生理过程,从胚胎发育、细胞命运决定到整个生物体的生理稳态。越来越多的研究表明,大量的lncrnas在染色质修饰、转录和转录后调控、基因组剪接、分化、免疫反应、细胞周期调控等许多重要的生物学过程中起着至关重要的作用。
3.尤其是越来越多的文献报道,lncrnas的改变和失调与各种复杂疾病的发生发展密切相关。例如,基于定量pcr,lncrnahotair在乳腺癌转移中的表达水平是100到大约2000 倍。它通过与组蛋白修饰物prc2和lsd1复合物结合来控制组蛋白修饰的模式并调节基因表达。hotair被认为是各种癌症的潜在生物标志物。通过下调h19,一种20多年前证实的 lncrna,乳腺和肺癌细胞的克隆性和锚定非依赖性生长可以显著降低。事实上,h19与多种疾病有关,可作为膀胱癌早期复发的潜在预后标志物。
4.我们可以发现,尽可能多地收集lncrna与疾病的联系是必要的。然而,尽管实验证实 lncrna与疾病的关联性一直在增加,但与大量的lncrna和疾病相比,这个数字仍然相当小。此外,通过实验室实验来确定lncrna与疾病之间的联系是非常昂贵和耗时的。因此,通过计算模型准确地识别lncrna与疾病的相关性,不仅有利于进一步的生物学实验,节省成本和时间,而且可以辅助疾病生物标志物的检测,为疾病的诊断、治疗、预后和预防提供帮助。此外,这些正确识别的关联可以加快我们在rna水平上理解生命过程的步伐。
技术实现要素:
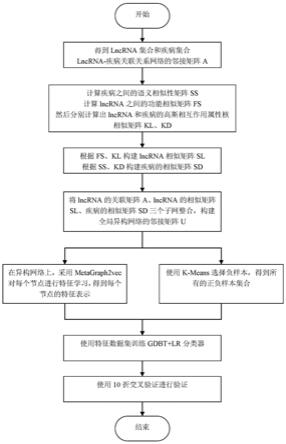
5.本发明的目的是针对现有技术的不足,提出了一种异构网络的高性能预测lncrna与疾病相关性的方法,该方法使用metagraph2vec在异构网络中对节点进行特征学习,然后利用 k
‑
means选择负样本来解决正负样本不平衡的问题,最后使用机器学习算法gbdt+lr去预测lncrna与疾病之间的关联。
6.本发明提出的lncrna和疾病关联关系的高效预测方法,步骤如下:
7.1.下载公开数据库lncrnadisease(网址:http://www.cuilab.cn/lncrnadisease)中已知的lncrna
‑ꢀ
疾病关联关系,包括三个版本的数据,分别是:2012年6月版本、2014年1月版本、2015 年6月版本,分别标记为ds1,ds2,ds3。我们首先对这三个数据集分别进行去重等处理,同时得到lncrna集合和疾病集合,并得到lncrna
‑
疾病关联关系网络的关联矩阵a,a的行数为lncrna的数量,a的列数为疾病的数量,其中a(l
i
,d
j
)=1,表示lncrnal
i
和疾病d
j
存在关联关系,值为0表示不存在关联关系,a的表示如式(1)所示:
[0008][0009]
2.计算疾病之间的语义相似性矩阵ss、计算lncrna之间的功能相似矩阵fs,然后分别计算出lncrna和疾病的高斯相互作用属性核相似矩阵kl、kd。具体子步骤如下:
[0010]
1)疾病语义相似矩阵
[0011]
基于疾病本体的层次结构,将疾病组织为有向无环图(dag)。根据相应dag,计算所有疾病之间的语义相似性。对于疾病i的有向无环图,首先计算疾病i的语义值;疾病i的语义值c(i)是是它的祖先疾病和i自己的贡献值之和,如公式(2)所示。
[0012]
c(i)=∑
t∈d(i)
c
i
(t)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0013]
其中d(i)表示疾病i的有向无环图中的节点集。疾病t对子疾病i的语义值c
i
(t)的贡献计算如公式(3)所示:
[0014][0015]
其中δ是连接疾病t和其子疾病之间的边的权重,即语义贡献因子。由上式可知,疾病对其自身的语义贡献为1。随着疾病i与其他疾病之间的距离的增加,语义贡献减小。因此,应该在0到1之间选择δ,在这里,我们取δ=0.5。
[0016]
对于疾病i和疾病j之间的语义相似度定义为与疾病i和j的有向无环图共享的结点越多,他们之间的语义相似度则更高,因此,可以得到疾病语义相似矩阵ss如公式(4)所示:
[0017][0018]
其中元素ss(i,j)表示疾病i和疾病j之间的语义相似度值。
[0019]
2)lncrna功能相似矩阵
[0020]
通过计算与这两个lncrna相关的两种疾病集的语义相似度来计算这两个lncrna的功能相似度。假设lncrna l
i
和lncrna l
j
分别与m个和n个疾病有关,lncrna l
i
和lncrna l
j
之间的相似度可由公式(5)和公式(6)计算如下:
[0021][0022][0023]
其中fs为lncrna功能相似矩阵,s(d,d1(l
i
))是疾病d与是与lncrna l
i
相关的疾病集 d1(l
i
)中的所有的疾病语义相似性的最大值。需要注意的是,疾病相似矩阵ss和lncrna相似矩阵fs都是稀疏的。因此,我们进一步引入高斯相互作用属性核相似性来缓解这一弱点。
[0024]
3)lncrna与疾病的高斯相互作用属性核相似矩阵
[0025]
对于一个lncrnal
i
,定义ip(l
i
)值为邻接矩阵a的第i行,计算每一对lncrnal
i
与l
j
之间的高斯相互作用属性核相似性,如式(7)所示:
[0026]
kl(l
i
,l
j
)=exp(
‑
γ
l
||ip(l
i
)
‑
ip(l
j
)||2)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0027][0028]
其中,kl表示lncrna的高斯相互作用属性核相似矩阵,元素kl(l
i
,l
j
)表示lncrnal
i
与l
j
的高斯相互作用属性核相似性,γ
l
用于控制高斯相互作用属性核相似性的频宽,它表示基于新的频宽参数γ'
l
的正规化的高斯相互作用属性核相似性频宽;nl表示lncrna的数量。
[0029]
同样地,基于功能相似的lncrna与相似的疾病之间具有关联关系的假设,利用已知的 lncrna
‑
疾病关联关系网络,构建疾病的高斯相互作用属性核相似矩阵kd,对于一个疾病 d
j
,它的ip'(d
j
)值定义为邻接矩阵a的第j列,计算每一对疾病d
i
与d
j
之间的高斯相互作用属性核相似性,如式(9)所示:
[0030]
kd(d
i
,d
j
)=exp(
‑
γ
d
||ip'(d
i
)
‑
ip'(d
j
)||2)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0031][0032]
其中,kd表示疾病的高斯相互作用属性核相似矩阵,元素kd(d
i
,d
j
)表示疾病d
i
与d
j
的高斯相互作用属性核相似性,γ
d
表示基于频宽参数γ'
d
的正规化的高斯相互作用核相似性频宽,nd表示疾病的数量。
[0033]
3.根据lncrna的功能相似矩阵fs、lncrna的高斯相互作用属性核相似矩阵kl构建lncrna相似矩阵sl:对于lncrna l
i
和lncrna l
j
,如果fs(l
i
,l
j
)=0,则sl(l
i
,l
j
)=kl(l
i
,l
j
),否则sl(l
i
,l
j
)=fs(l
i
,l
j
),如式(11)所示组合如下:
[0034][0035]
其次,我们整合了疾病的语义相似度ss和高斯交互属性核相似度kd,最终的疾病相似矩阵sd可以按照以下方式如式(12)所示组合:
[0036][0037]
4.将lncrna
‑
疾病的关联矩阵a、步骤3得到lncrna的相似矩阵sl和疾病的相似矩阵sd 整合,构建一个全局异构网络;在异构网络上,采用metagraph2vec对每个节点进行特征学习,得到每个节点的特征表示。具体实现子步骤为:
[0038]
(1)构建异构网络
[0039]
我们融合了lncrna
‑
疾病关联关系网络的关联矩阵a、lncrna的相似矩阵sl和疾病的相似矩阵sd三个子网,构成全局异构网络g,并得到一个新的邻接矩阵u,u中共nl+nd 维,nl表示lncrna的数量,nd表示疾病的数量。u如式(13)所示:
[0040][0041]
其中a
t
表示a的转置。我们在全局异构网络g上采用metagraph引导随机游走来获
得节点序列。如前所述,g=(v,e)表示全局异构网络,在g上定义一个元图g=(n,m,n
s
,n
t
),其中n
s
代表源节点,n
t
代表目标节点;n是节点集合,m是边集合。
[0042]
在这里的元图只有两种节点类型,即l节点代表lncrna,d节点代表疾病;边类型也有两种,即l
‑
d和d
‑
l。
[0043]
(2)metagraph引导随机行走
[0044]
基于步骤(1)得到一个n
s
=n
t
的元图g=(n,m,n
s
,n
t
),递归元图g
∞
=(n
∞
,m
∞
,n
s∞
,n
t∞
) 是由任意数量g的首尾拼接而成的元图。在选择一个n
s
类型的节点后,开始元图引导的随机漫步。
[0045]
在第i步,metagraph引导的随机行走从节点v
i
‑1开始,将第i步的转移概率记为 pr(v
i
|v
i
‑1;g
∞
),v
i
‑1是当前节点,v
i
是下一跳节点。先得到节点v
i
‑1与相邻节点的边类型,如果节点v
i
‑1在异构网络g中与邻居节点没有满足递归元图g
∞
约束边的边类型,转移概率pr 为0;
[0046]
否则随机选择一种满足条件的边类型,再从所选的边类型中随机选择一条边进行游走到达下一节点,第i步的转移概率如式(14)所示:
[0047][0048]
是从v
i
‑1开始的满足递归元图g
∞
中约束边的边类型数。如果没有满足递归元图g
∞
中的约束边,则终止游走。
[0049][0050]
且|u|(v
i
‑1,u)∈e,φ(v
i
)=φ(u)|是v
i
‑1的邻居节点中与节点v
i
相同类型的节点个数。
[0051]
经过多次游走最后得到一个长度为长度为l的节点序列sg={v1,v2,
…
,v
l
}。
[0052]
(3)metagraph2vec嵌入学习,并得到每一个节点节点的低维表示。
[0053]
根据步骤2得到的节点序列sg,通过最大化以φ(v
i
)为条件,在w窗口大小内v
i
上下文节点出现的概率来学习节点嵌入函数φ(
·
):
[0054]
其中:
[0055][0056]
根据metapath2vec,概率pr(v
j
∣φ(v
i
))以两种不同的方式建模:
[0057]
·
同构网络中的skip
‑
gram假定概率pr(v
j
∣φ(v
i
))不依赖于v
j
的类型,因此通过softmax 直接对概率pr(v
j
∣φ(v
i
))建模如式(17)所示:
[0058][0059]
·
异构网络中的skip
‑
gram假定概率pr(v
j
∣φ(v
i
))与v
j
的类型有关:pr(v
j
∣φ(v
i
))=
[0060]
pr(v
j
∣φ(v
i
),φ(v
j
))pr(φ(v
j
)∣φ(v
i
))其中概率pr(v
j
∣φ(v
i
),φ(v
j
))通过softmax建模:
[0061][0062]
为了学习节点嵌入,metagraph2vec算法首先生成一组元图引导随机游走的节点序列,然后计算每个节点上下文对(v
i
,v
j
)在w窗口大小内的出现频率f(v
i
,v
j
)。然后用随机梯度下降法学习参数。在每次迭代中,根据f(v
i
,v
j
)的分布对节点上下文对(v
i
,v
j
)进行采样,并更新梯度以最小化以下目标:
[0063][0064]
为了加快训练速度,使用负采样来逼近目标函数:
[0065][0066]
其中σ是sigmoid函数,是为节点v
j
采样的第k个负节点,k是负样本的数量。对于同构网络中的skip
‑
gram,从v中所有节点采样;对于异构网络中的 skip
‑
gram,从φ(v
j
)类型的节点中采样。
[0067]
其中α是学习率。参数φ和ψ的更新如下:
[0068][0069]
嵌入函数φ将异构网络的节点嵌入到低维空间中,对每个节点进行嵌入并得到低维表示φ(v)。最后我们就得到d维的特征矩阵x。
[0070]
5.使用k
‑
means选择负样本,得到所有的正负样本集合。由于数据集中负样本的数量远远大于正样本的数量,因此需要对数据集进行平衡。针对这一问题,我们使用了一种新颖的先进的数据平衡方法。k
‑
means聚类是一个将数据集中在某些方面相似的数据成员进行分类组织的过程。k
‑
means算法是一种基于形心的划分技术,即使用簇的形心代表该簇。k
‑
means聚类首先随机选取k个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。一旦全部对象都被分配了,每个聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到没有(或最小数目)聚类中心再发生变化。
[0071]
具体实现步骤如下:
[0072]
(1)从样本数据中随机选取k个对象作为初始的聚类中心。
[0073]
(2)分别计算每个样本到各个聚类质心的距离,将样本分配到距离最近的那个聚类中心类别中。
[0074]
(3)所有样本分配完成后,重新计算k个聚类的中心。
[0075]
(4)与前一次计算得到的k个聚类中心比较,如果聚类中心发生变化,转(2),否则转(5)。
[0076]
(5)聚类中心不再发生变化,输出聚类结果。
[0077]
6.我们使用以上步骤得到的数据样本训练梯度提升树(gbdt,gradient boosting decison tree)+ 逻辑回归(lr,logisticregression)分类器。再将梯度提升树+逻辑回归(gbdt+lr)分类器用于预测lncrna与疾病之间的相关分数。用训练数据集对未经训练的gbdt+lr分类器进行训练,初始化模型参数,训练数据通过gbdt模型进行回归,将gbdt中生成的决策树的叶子节点进行特征组合,寻找训练集的特征及特征组合,再将其作为输入给lr分类器模型进行分类训练,从而完成对gbdt+lr分类器的训练过程。
[0078]
gbdt+lr是一个特征交叉的过程,gbdt的路径可以直接作为lr的输入特征来使用,避免了人工组合交叉特征的过程,gbdt+lr算法结构示意图如图2所示。
[0079][0080][0081]
可以看到图中示例的2个树均是gbdt训练出的回归树模型。在线过程中样本数据经过树种的路径最终到达子节点。将所有子节点作为lr的输入特征,进行分类。上图中共有两棵树,x为一条输入样本,遍历两棵树后,x样本分别落到两颗树的叶子节点上,每个叶子节点对应lr一维特征,那么通过遍历树,就得到了该样本对应的所有lr特征。举例来说:上图有两棵树,左树有三个叶子节点,右树有两个叶子节点,最终的特征即为五维的向量。对于输入x,假设他落在左树第一个节点,编码[1,0,0],落在右树第二个节点则编码[0,1],所以整体的编码为[1,0,0,0,1],这类编码作为特征,输入到lr中进行分类。
[0082]
gbdt+lr是一种特殊的分类算法,因为其寻找特征和组合特征能力的强大,非常适用于多个指标特征且特征之间存在关联,各特征非线性共同影响类别结果的情况,并且分类准确率高。分类效果显示,应用gbdt+lr算法训练得到的分类器评价结果准确度要远高于其他分类算法
[0083]
gbdt+lr用于算法的步骤如下:
[0084]
1)gbdt首先对原始训练数据做训练,得到一个二分类器,同时利用网格搜索寻找最佳参数组合。
[0085]
输入:训练样本d={(x1,y1),(x2,y2),
…
,(x
n
,y
n
)},最大迭代次数m,损失函数l,学习率为lr。
[0086]
输出:强学习器θ(x)
[0087]
(1)初始化学习器为(22)所示:
[0088][0089]
其中n为训练样本的数量,y
i
为真实标签。
[0090]
损失函数l(y,θ
m
(x))定义为(23)所示:
[0091]
l(y,θ
m
(x))=log(1+exp(
‑
yθ
m
(x)))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(23)
[0092]
其中y是真正的类标签,θ
m
(x)是第m轮的弱学习器。
[0093]
(2)依次进行第m次迭代,其中m=1,2,
…
m。
[0094]
①
计算第m次迭代的负梯度,即残差,让损失函数沿着梯度方向的下降,第m次迭代的第i个样本的损失函数的负梯度表示为(24)所示:
[0095][0096]
②
将上一步得到的残差作为样本新的真实值,以残差值作为目标值进行拟合,以最小化平方损失为标准寻找树的最佳划分节点,分别计算根据每个特征作为划分点进行分裂后两组数据的平方损失,找到使平方损失和最小的划分点,即最佳划分点。构造第m棵决策树,然后得到其对应的叶子结点区域为r
mj
,j=1,2,
…
,j。其中j为树的叶子节点个数。
[0097]
③
对叶子结点区域j=1,2,
…
,j,计算最佳拟合值。针对每一个叶子结点里的样本,我们求出使损失函数最小,也就是拟合叶子结点最好的输出值c
mj
如(25)所示:
[0098][0099]
④
第m个弱学习器
[0100][0101]
其中i(x∈r
mj
)表示如果x落在了r
mj
的对应某一叶子节点上,那么对应此项为1,lr为学习率。
[0102]
⑤
判断m是否大于m,如果m小于m,则m=m+1,跳转到
①
进行下一次迭代,否则说明m个弱学习器都已经构造好,跳转到(3)结束训练。
[0103]
(3)得到最终的强学习器模型如如(27)所示
[0104][0105]
其中lr为学习率
[0106]
2)gbdt训练好后,我们需要的并不是最终的二分类概率值,而是要把模型中的每棵树计算得到的预测概率值所属的叶子结点位置记为1,构造出了新的训练数据。在这里使用独热编码(one
‑
hot encoding)对gdbt的结果进行处理并构造新的训练数据集。
[0107]
独热编码即one
‑
hot编码,又称为一位有效编码,其方法是使用n位状态寄存器来对n 个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
[0108]
例如:
[0109]
自然状态码为:000,001,010,011,100,101;
[0110]
独热编码为:000001,000010,000100,001000,010000,100000。
[0111]
3)新的训练数据构造完成后,与原始的训练数据的标签数据一并输入到lr分类器中进行最终分类器的训练。逻辑回归的假设函数如式如(28)所示。式如(29)表示的是在给定 x和θ时,x属于正样本的可能性。其中θ是需要通过训练使式如(30)中的损失函数最小得到的。
[0112]
[0113][0114][0115]
7.使用10折交叉验证进行验证。训练集随机分为10组大小大致相同的子集。每个子集依次用作验证测试数据,其余9个子集用作训练数据。交叉验证过程重复10次,并使用10次的平均性能度量进行性能评估。我们使用多种指标来评估性能,包括召回(rec)、f
‑
score(fsc)、准确度(acc)和roc曲线下与坐标轴围成的面积(auc)。
[0116]
8.性能评估:本发明的方法是基于梯度提升树(gdbt)结合逻辑回归(lr)算法,将本发明的方法与广泛使用的分类器进行比较,包括使用随机森林(rf)结合逻辑回归(lr)作为分类器、只使用梯度提升树(gdbt)作为分类器、只使用逻辑回归(lr)作为分类器。在构建标准训练集上使用10倍交叉验证;并将本发明使用的方法与已存在的其他方法进行比较,包括基于诱导矩阵完成的预测潜在lncrna疾病关联的方法(simclda),基于内部倾斜重启随机漫步的预测潜在lncrna疾病关联的方法(iirwr)和基于网络性一致性投影的预测潜在 lncrna疾病关联的方法(ncplda);为进一步验证本方法的性能,将本实验进行独立测试。为了体现本实验特征的性能,还将本实验使用不同特征组(不使用metagraph2vec进行表征学习、使用metagraph2vec进行表征学习),使用不同负样本(不使用k
‑
means进行聚类,使用 k
‑
means进行聚类)进行性能比较。
[0117]
经过验证本发明具有如下优点和有益效果:本发明使用metagraph2vec在异构网络中对节点进行特征学习,同时保留结构和语义相互关系的异构网络嵌入,然后利用k
‑
means选择负样本解决了正负样本不平衡的问题,最后使用机器学习算法gbdt+lr去预测lncrna与疾病之间的关联;这对生物学家的实验研究能够起到指导的作用,生物学家可以针对关联关系概率较大的lncrna和疾病对进行试验测试,避免了盲目的测试,有效减少生物学实验所消耗的时间和经济成本。
附图说明
[0118]
图1为本发明lncrna和疾病关联关系预测方法的流程图。
[0119]
图2为本发明gbdt+lr算法结构示意图。
[0120]
图3为本发明lncrna和疾病关联关系预测方法的示意图
[0121]
图4为步骤1计算邻居矩阵a流程图。
[0122]
图5为步骤2计算相似矩阵fs、ss、kl、kd的流程图。
[0123]
图6为步骤3计算相似矩阵sl和se的流程图。
[0124]
图7为步骤4融合a、sl、se构建一个全局异构网络并用metagraph2vec对每个节点进行特征学习,得到每个节点特征表示的流程图。
[0125]
图8为步骤5使用k
‑
means选择负样本,得到所有的正负样本集合的流程图。
具体实施方式
[0126]
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
[0127]
实施例:
[0128]
本实施例提供了一种预测lncrna和疾病关联关系的方法,所述方法的流程图如图1所示,本实施例需要的数据从lncrnadisease数据库下载lncrna
‑
疾病的关联数据,包括三个版本的数据,分别是:2012年6月版本、2014年1月版本、2015年6月版本,分别标记为 ds1,ds2,ds3。首先对这三个数据集分别进行去重等处理,最后得到的数据如表1所示,其中2012年6月版本的数据包括112个lncrna和150个疾病,它们之间关联数量是276,我们将该版本的数据标记为ds1;2014年1月版本的数据中包括131个lncrna和169个疾病,它们之间关联数量为319,我们将该版本的数据标记为ds2;2015年6月版本的数据中包括285个lncrna和226个疾病,它们之间关联数量为621,我们将该版本的数据标记为 ds3。
[0129]
表1 lncrna
‑
疾病关联关系数据集
[0130]
数据集lncrna数量疾病数量关联数量dataset1(ds1)112150276dataset2(ds2)131169319dataset3(ds3)285226621
[0131]
根据上面的数据,以ds1数据集为例,具体实施包括以下步骤:
[0132]
1、根据已知的lncrna
‑
疾病关联关系,进行去重等处理,得到lncrna
‑
疾病关联关系网络的关联矩阵a:
[0133][0134]
例:
[0135]
2、计算lncrna之间的功能相似矩阵fs、计算疾病之间的语义相似性矩阵ss,然后分别计算出lncrna和疾病的高斯相互作用属性核相似矩阵kl、kd。
[0136]
1)计算疾病之间的语义相似矩阵ss:
[0137][0138]
其中d(i)表示疾病i的有向无环图中的节点集,其中d(j)表示疾病j的有向无环图中的节点集。c(i)是疾病i的语义值,c(j)是疾病j的语义值;c
i
(t)是疾病t对疾病i的语义值的贡献, c
j
(t)是疾病t对疾病j的语义值的贡献。
[0139][0140]
2)计算lncrna之间的功能相似矩阵fs:
[0141]
[0142][0143]
其中,s(d,d1(l
i
))是疾病d与是与lncrna l
i
相关的疾病集d1(l
i
)中的所有的疾病语义相似性的最大值。
[0144][0145]
3)构建lncrna的高斯相互作用属性核相似矩阵kl:
[0146]
kl(l
i
,l
j
)=exp(
‑
γ
l
||ip(l
i
)
‑
ip(l
j
)||2)
[0147][0148]
其中,γ'
l
取值为1。
[0149]
例:
[0150]
ip(l0)
150
×1:[0
…
此处省略86个0
…
1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0151]
ip(l1)
150
×1:[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
ꢀ…
此处省略86个0
…
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0152]
kl(l0,l1)=exp(
‑
γ
l
||ip(l0)
‑
ip(l1)||2)=0.087616792106586
[0153][0154]
4)构建疾病的高斯相互作用属性核相似矩阵kd:
[0155]
ke(d
i
,d
j
)=exp(
‑
γ
d
||ip'(d
i
)
‑
ip'(d
j
)||2)
[0156][0157]
其中,γ
d
取值为1。
[0158]
例:
[0159]
ip(d0)
112
×1:[0
…
此处省略48个0
…
1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0160]
ip(d1)
112
×1:[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
ꢀ…
此处省略48个0
…
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0161]
kd(d0,d1)=exp(
‑
γ
d
||ip(d0)
‑
ip(d1)||2)=0.066046825955405
[0162][0163]
3、根据得到的lncrna的功能相似度fs和高斯交互属性核相似度kl,得到最终的lncrna 相似矩阵sl;整合疾病的语义相似度ss和高斯交互属性核相似度kd,最终的疾病相似矩阵sd。
[0164][0165][0166][0167][0168]
4、将lncrna
‑
疾病的关联矩阵a、lncrna的相似矩阵sl、疾病的相似矩阵sd三个子网整合,构建全局异构网络g。在异构网络上,采用metagraph2vec对每个节点进行特征学习,得到每个节点的特征表示。具体子步骤为:
[0169]
(1)构建异构网络
[0170]
我们融合了lncrna
‑
疾病关联关系网络的关联矩阵a、lncrna的相似矩阵sl和疾病的相似矩阵sd三个子网,构成全局异构网络g,并得到一个新的邻接矩阵u。u中共112+150=262 维,112表示lncrna的数量,150表示疾病的数量。
[0171][0172][0173]
其中a
t
表示a的转置。我们在全局异构网络g上采用metagraph引导随机游走来获得节点序列。如前所述,g=(v,e)表示全局异构网络,在g上定义一个元图g=(n,m,n
s
,n
t
),其中n
s
代表源节点,n
t
代表目标节点;n是节点集合,m是边集合。
[0174]
在这里的元图只有两种节点类型,即l节点代表lncrna,d节点代表疾病;边类型也有两种,即l
‑
d和d
‑
l。
[0175]
(2)metagraph引导随机行走
[0176]
基于步骤(1)得到一个n
s
=n
t
的元图g=(n,m,n
s
,n
t
),我们把l
‑
d
‑
l
‑
d设为本发明的元图, 递归元图g
∞
=(n
∞
,m
∞
,n
s∞
,n
t∞
)是由任意数量g的首尾拼接而成的元图。在选择一个n
s
类型的节点后,开始元图引导的随机漫步。
[0177]
在第i步,metagraph引导的随机行走从节点v
i
‑1开始,将第i步的转移概率记为 pr(v
i
|v
i
‑1;g
∞
),v
i
‑1是当前节点,v
i
是下一跳节点。先得到节点v
i
‑1与相邻节点的边类型,如果节点v
i
‑1在异构网络g中与邻居节点没有满足递归元图g
∞
约束边的边类型,转移概率pr 为0;
[0178]
否则随机选择一种满足条件的边类型,再从所选的边类型中随机选择一条边进行游走到达下一节点,第i步的转移概率为:
[0179][0180]
是从v
i
‑1开始的满足递归元图g
∞
中约束边的边类型数。如果没有满足递归元图g
∞
中的约束边,则终止游走。
[0181][0182]
且|u|(v
i
‑1,u)∈e,φ(v
i
)=φ(u)|是v
i
‑1的邻居节点中与节点v
i
相同类型的节点个数。
[0183]
我们把随机游走的步数设为100,从l节点开始,只把到达的d节点记录下来,可得到每一条长度为50的节点序列sg={v1,v2,
…
,v
50
}。
[0184]
(3)metagraph2vec嵌入学习,并得到每一个节点节点的低维表示。
[0185]
根据步骤2得到的节点序列sg={v1,v2,
…
,v
l
},通过最大化在以φ(v
i
)为条件,在w窗口大小内v
i
的上下文节点出现的概率来学习节点嵌入函数
[0186]
φ(
·
):
[0187]
其中:
[0188][0189]
根据metapath2vec,概率pr(v
j
∣φ(v
i
))以两种不同的方式建模:
[0190]
·
同构网络中的skip
‑
gram假定概率pr(v
j
∣φ(v
i
))不依赖于v
j
的类型,因此通过softmax 直接对概率pr(v
j
∣φ(v
i
))建模:
[0191][0192]
·
异构网络中的skip
‑
gram假定概率pr(v
j
∣φ(v
i
))与v
j
的类型有关:pr(v
j
∣φ(v
i
))= pr(v
j
∣φ(v
i
),φ(v
j
))pr(φ(v
j
)∣φ(v
i
))其中概率pr(v
j
∣φ(v
i
),φ(v
j
))通过softmax建模:
每个簇选择28个负样本;对于第二个数据集ds2来说,正样本个数有319,负样本个数有 21820个,所以对于ds2每个簇选择32个负样本;对于第三个数据集ds3来说,正样本个数有621,负样本个数有63789个,所以对于ds1每个簇选择62个负样本。
[0211]
6、对于每一个数据样本,结合其得到的128维特征数据。对于600个训练样本,得到556*128 的特征数据集如下所示:
[0212][0213]
1)将得到的特征数据集用于训练梯度提升树(gbdt),并将gbdt中生成的决策树的叶子节点进行特征组合。gdbt算法步骤如下所示:
[0214]
输入:训练样本d={(x1,y1),(x2,y2),
…
,(x
556
,y
556
)},x为特征,y为标签,样本个数为556,损失函数定义为l(y,θ
m
(x))=log(1+exp(
‑
yθ
m
(x))),其中y是真正的类标签,θ
m
(x)是第m 轮的弱学习器;学习率lr为0.1。
[0215]
输出:根据gbdt中生成的决策树的叶子节点进行组合的特征数据xs。
[0216][0217]
(1)初始化学习器,如下所示:
[0218][0219]
其中556为训练样本的数量,就是正样本的个数,就是负样本的个数,以数据集ds1为实例,正样本个数为276,负样本个数都为280。
[0220]
(2)依次进行第m次迭代,其中m=1,2,
…
500。
[0221]
①
计算第1次迭代的负梯度,即残差,第1次迭代的第i个样本的损失函数的负梯度为:
[0222][0223]
②
将上一步得到的残差作为样本新的真实值,以残差值作为目标值进行拟合,以最小化平方损失为标准寻找树的最佳划分节点,分别计算根据每个特征作为划分点进行分裂后两组数据的平方损失,找到使平方损失和最小的划分点,即最佳划分点。构造第m棵决策树,然后得到其对应的叶子结点区域为r
mj
,j=1,2,
…
,j。其中j为树的叶子节点个数。
[0224]
③
对叶子结点区域j=1,2,
…
,j,计算最佳拟合值。针对每一个叶子结点里的样本,我们求出使损失函数最小,也就是拟合叶子结点最好的输出值c
1j
[0225][0226]
④
第1个弱学习器
[0227][0228]
⑤
判断m是否大于500,如果m小于500,则m=m+1,跳转到
①
进行下一次迭代,否则说明m个弱学习器都已经构造好,跳转到(3)结束训练。
[0229]
(3)得到最终的强学习器模型如下所示
[0230][0231]
训练好gbdt后,使用独热编码(onehotencoder)对gdbt的结果进行处理并构造新的训练数据集。最后得到特征xs
556
×
441
,样本数为556个,数据特征为441维。
[0232]
2)将新的数据特征xs
556
×
441
与原始的训练数据的标签数据一并输入到lr分类器中进行最终分类器的训练。逻辑回归的假设函数如式如下所示。
[0233][0234]
在给定x和θ时,x属于正样本的可能性如下所示
[0235][0236]
其中θ是需要通过训练是如下所示中的损失函数最小得到的。
[0237][0238]
7、使用10折交叉验证进行验证。我们采用网格搜索策略,在10倍交叉验证的基准数据集上选择gbdt+lr的最优参数。使用10倍交叉验证来评估方法的性能:训练集随机分为10组大小大致相同的子集。每个子集依次用作验证测试数据,其余9个子集用作训练数据。交叉验证过程重复10次,并使用超过10次的平均性能度量进行性能评估。实验使用多种方法来评估性能,包括召回率(rec)、f
‑
score(fsc)、准确度(acc)和roc曲线下与坐标轴围成的面积(auc)。本发明方法gbdtlrl2d在ds1,ds2,ds3这3个数据集上的auc分别为 0.98,0.98和0.96。
[0239]
8、性能评估:本发明方法是基于梯度提升树结合逻辑回归(gbdt+lr)算法,将本发明的方法与广泛使用的分类器进行比较,包括使用随机森林(rf)+逻辑回归(lr)作为分类器、只使用梯度提升树(gbdt)作为分类器、只使用逻辑回归(lr)作为分类器,在构建标准训练集上都使用了10倍交叉验证。表2展示了与其他机器学习方法的预测性能比较。我们可以看出使用组合分类器的效果明显要好的多,并且gbdtlrl2d使用的gbdt+lr组合分类器三个数据集上都比其他方法好得多。由此可见,本发明方法所采用的方法具有最佳的性能。
[0240]
表2与使用其他机器学习方法的预测性能比较
[0241]
数据集方法accrecallf1_scoremccaucds1gbdt+lr0.9280.9200.9270.8580.976ds2 0.9340.9280.9340.8700.983ds3 0.8870.8710.8850.7770.961
ds1rf+lr0.7870.76707800.5810.860ds2 0.8000.8020.8010.6030.898ds3 0.7960.7670.7900.6010.889ds1gbdt0.5700.6580.6080.1250.649ds2 0.6000.7240.6450.2100.705ds3 0.6360.6310.6360.2820.667ds1lr0.5700.6590.6090.1250.649ds2 0.6010.7240.6450.2110.705ds3 0.6360.6310.6360.2820.667
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1