一种基于脉冲神经网络的睡眠鼾声检测系统
1.本发明涉及神经网络和音频检测技术领域,尤其是涉及一种基于脉冲神经网络的睡眠鼾声检测系统。
背景技术:
2.阻塞性睡眠呼吸暂停低通气综合征(osahs)作为最常见的睡眠呼吸疾病之一,严重影响着人类的睡眠质量及健康状况,世界上约有5%的人患有osahs,如果得不到及时治疗,osahs将会诱发高血压、冠心病、糖尿病、心力衰竭,甚至猝死等症状。目前临床上诊断osahs的“金标准”是睡眠多导监测(psg),其是通过记录患者一夜睡眠期间的若干生理信号(如脑电信号、心电信号、肌电信号、眼电信号、血氧饱和度和鼾声等),然后通过睡眠技师人工分析得到关于osahs的报告。这一过程需要耗费大量的医护人力和医疗设备资源,导致很多osahs患者不能得到及时治疗。鼾声作为osahs早期特征,也是最典型的症状之一,有研究表明,鼾声中包含着osahs的信息,因此,近年来有大量的基于鼾声的osahs研究。在进行鼾声信号分析之前,完成对鼾声信号高效准确地识别检测能更好地推动鼾声分析领域的发展。
3.近年随着深度神经网络的快速发展,现在普遍用来进行鼾声信号分析的方法是循环神经网络(recurrent neural network,rnn)。对于声音这类有时序性的数据而言,传统rnn网络及变体结构,如长短期记忆(long short term memory,lstm)网络能得到很好的学习和训练效果,但是传统神经网络中大量线性神经细胞模型以及复杂的网络结构,导致计算量十分巨大,不能很好地应用到集成电路和移动设备上。
技术实现要素:
4.为解决现有技术的不足,通过端点检测技术提取整晚睡眠音频的有声段信号,对有声段进行特征提取,使用脉冲神经网络对有声段信号进行鼾声与非鼾声分类,实现对打鼾事件的自动检测和识别的目的,本发明采用如下的技术方案:
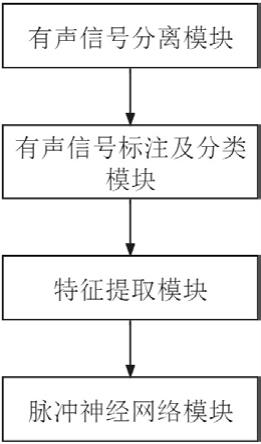
5.一种基于脉冲神经网络的睡眠鼾声检测系统,包括:有声信号分离模块、有声信号标注及分类模块、特征提取模块、神经网络模型;
6.所述有声信号分离模块,用麦克风阵列来拾取被测者整晚的睡眠声音信号,分离出有声段信号和静音段信号;
7.所述有声信号标注及分类模块,对有声段信号进行数据标注及分类,包括分出鼾声和非鼾声两类,其中非鼾声包括睡眠时的呼吸声、说话声、被子摩擦声等睡眠期间除打鼾外的其他声音,并对其标注;
8.所述特征提取模块,对标注及分类后的有声信号,提取mfcc(mel-scale frequency cepstral coefficients,mfcc)作为声音识别的特征参数;
9.所述神经网络模型为脉冲神经网络模型,包括脉冲编码单元和脉冲神经单元,脉冲编码单元对mfcc进行脉冲编码,得到脉冲序列;脉冲神经单元包括输入门、遗忘门、输入
信号调制单元和输出门,用于学习训练脉冲序列,其中输入门、遗忘门、输出门采用第一阈值激活函数,输入信号调制单元采用第二阈值激活函数,分别获取一组脉冲序列与上一时刻的隐藏状态,遗忘门的输出与上一时刻的单元状态计算哈达玛积,将输入门的输出和输入信号调整单元的输出计算哈达玛积,将两个哈达玛积结果相加作为当前时刻的单元状态,同时,将相加的结果与输出门的输出再次计算哈达玛积,作为当前时刻的隐藏状态;训练后的模型用于对待检测的睡眠有声段信号进行鼾声检测。
10.进一步地,神经网络模型为脉冲神经网络模型,包括脉冲编码单元、脉冲神经单元、归一化层;
11.所述脉冲编码单元,通过阈值θ对mfcc进行阈值脉冲编码,映射成脉冲序列,θ为动态阈值,满足高斯分布;
12.所述脉冲神经单元,用于计算脉冲序列,其门和状态的特征为:
13.f
t
=σ1(w
f,hht-1
+w
f,x
x
t
+b
f,h
+b
f,x
)
14.i
t
=σ1(w
i,hht-1
+w
i,x
x
t
+b
i,h
+b
i,x
)
15.g
t
=σ2(w
g,hht-1
+w
g,x
x
t
+b
g,h
+b
g,x
)
16.c
t
=f
t
⊙ct-1
+i
t
⊙gt
17.o
t
=σ1(w
o,hht-1
+w
o,x
x
t
+b
o,h
+b
o,x
)
18.h
t
=o
t
⊙ct
19.其中,f
t
表示遗忘门,σ1(
·
)、σ2(
·
)表示第一、第二阈值激活函数,当超过阈值θ1和θ2时,将累计输入映射成一个脉冲传递下去,h
t-1
表示t-1时刻的隐藏状态,x
t
表示一组输入序列,w
f,h
、b
f,h
表示遗忘门隐藏状态的权重系数,w
f,x
、b
f,x
表示遗忘门输入序列的权重系数,i
t
表示输入门,w
i,h
、b
i,h
表示输入门隐藏状态的权重系数,w
i,x
、b
i,x
表示输入门输入序列的权重系数,g
t
表示对输入信号的调制,w
g,h
、b
g,h
表示输入信号调制隐藏状态的权重系数,w
g,x
x
t
、b
g,x
表示输入信号调制输入序列的权重系数,c
t
表示t时刻的单元状态,
⊙
表示矩阵计算哈达玛积,c
t-1
表示t-1时刻的单元状态,o
t
表示输出门,w
o,h
、b
o,h
表示输出门隐藏状态的权重系数,w
o,x
、b
o,x
表示输出门输入序列的权重系数,h
t
表示t时刻的隐藏状态;
20.在对脉冲神经单元进行参数更新时,用高斯函数近似替代激活函数σ1(
·
)和σ2(
·
),以便可以采用反向传播算法进行参数更新;
21.所述归一化层,与最后一个脉冲神经单元连接,进行分类输出,并保存训练好的模型。
22.进一步地,脉冲神经单元是lstm脉冲神经单元。
23.进一步地,有声信号分离模块,设计多窗谱减算法,用于对分帧加窗后的信号进行降噪处理,具体为对睡眠声音信号同一数据序列,使用多个正交窗分别求直接谱,然后对多个直接谱取平均值获取噪声谱,这样获得的噪声谱值和检测结果会更加准确,用原始带噪信号的频谱减去噪声频谱获得降噪后的睡眠声音信号频谱,降噪后,使用短时过零率和短时能量相结合的双门限法,进行端点检测,完成有声段和静音段分离。
24.进一步地,有声信号分离模块,包括预加重单元,对睡眠声音信号进行预加重处理,从而提升高频分量的分辨率,传输函数z域表达式为:
25.h(z)=1-az-1
26.其中,a为预加重系数,值在0~1之间。
27.进一步地,预加重单元为一阶高通fir滤波器。
28.进一步地,有声信号分离模块,包括分帧加窗单元,对睡眠声音信号进行分帧处理,从而保证每帧信号足够短来达到平稳状态,再将每一帧信号乘以汉明窗函数,从而减少频域中的信号特征泄露,分帧加窗公式为:
[0029][0030]
其中,q表示分帧加窗后的声音信号,t[
·
]为分帧函数,x(m)为第m帧声音信号,h(
·
)为汉明窗函数,n表示汉明窗长度,w表示每一帧信号的移动长度;
[0031]
进一步地,分帧信号的长度为20ms,帧移10ms,50%的重叠率。
[0032]
进一步地,特征提取模块,将时域音频信号进行傅里叶变换转换为频域信号,并计算所有对应频率的功率谱;
[0033]
频域信号通过梅尔标度三角形滤波器组,平滑频谱上的特征,每个滤波器组输出的对数能量s(l)为:
[0034][0035]
其中l表示滤波器的数量,l表示滤波器总个数,k表示频域信号傅里叶变换采样点数量,n表示傅里叶变换总采样点数,xa(k)表示通过快速傅里叶变换得到的声音信号频谱功率,h(k)表示三角滤波器得到的能量谱的频率响应;
[0036]
再对每个滤波器组输出的对数能量s(l),作离散余弦变换得到mfcc系数。
[0037]
进一步地,有声信号标注及分类模块,将有声段信号分为鼾声和非鼾声,其中非鼾声包括睡眠时的呼吸声、说话声、被子摩擦声等睡眠期间除打鼾外的其他声音,并对其标注。
[0038]
本发明的优势和有益效果在于:
[0039]
本发明使用lstm脉冲神经网络对睡眠声音数据进行分类,可以保证脉冲神经网络对声音这类时间序列识别的准确性,提高预测结果的准确度。由于脉冲神经网络的计算是基于脉冲序列,时间上的稀疏性使得脉冲神经网络相比于传统神经网络计算量更少更节能,可以更好地应用到集成电路和移动设备中。
附图说明
[0040]
图1为本发明的系统结构图。
[0041]
图2为本发明中lstm脉冲神经单元内部结构图。
[0042]
图3为本发明的方法流程图。
具体实施方式
[0043]
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
[0044]
如图1、2所示,一种基于脉冲神经网络的睡眠鼾声检测系统,包括有声信号分离模块、有声信号标注及分类模块、特征提取模块、脉冲神经网络模型,脉冲神经单元包括输入门、遗忘门、输入信号调制单元和输出门。
[0045]
如图3所示,系统运行过程,包括如下步骤:
[0046]
s1,拾取被测者整晚的睡眠声音信号,对所述睡眠声音信号进行预加重、分帧加窗和端点检测处理,分离有声段和静音段;
[0047]
s2,对s1中获取的有声段信号进行数据标注及分类;
[0048]
s3,对s2中音频数据提取mfcc作为声音识别的特征参数;
[0049]
s4,建立脉冲神经网络模型,将s3中的mfcc映射成脉冲序列,并采用反向传播算法进行参数更新,保存训练好的模型;
[0050]
s5,将待检测的睡眠有声段数据输入到保存好的网络模型中进行鼾声检测。
[0051]
步骤s1中可用麦克风阵列来拾取被测者整晚的睡眠声音信号,对采集的睡眠声音信号进行预加重、分帧加窗和端点检测处理包括如下步骤:
[0052]
s11,对拾取的整晚睡眠声音信号预加重用于提升高频分量的分辨率,实现方式为一阶高通fir滤波器,其传输函数为:
[0053]
h(z)=1-az-1
[0054]
其中a为预加重系数,值在0~1之间;
[0055]
s12,对预加重后的声音信号进行分帧用于保证每帧信号足够短来达到平稳状态,分帧信号的长度为20ms,帧移10ms,50%的重叠率,再将每一帧信号乘以汉明窗函数,用于减少频域中的信号特征泄露,分帧公式为:
[0056][0057]
汉明窗函数为:
[0058][0059]
其中,t[
·
]为分帧函数,x(m)为第m帧声音信号,h(
·
)为汉明窗函数,w为帧移长度;
[0060]
s13,设计多窗谱减算法用于对分帧加窗后的信号进行降噪处理,具体为对声音信号同一数据序列使用多个正交窗分别求直接谱,然后对多个直接谱取平均值获取噪声谱,这样获得的噪声谱值和检测结果会更加准确,用原始带噪信号的频谱减去噪声频谱获得降噪后的声音信号频谱。降噪后使用短时过零率和短时能量相结合的双门限法进行端点检测完成有声段和静音段分离。
[0061]
步骤s2中对获取的有声段信号进行数据标注及分类用于整理脉冲神经网络训练所需的训练集和测试集,数据集分为鼾声和非鼾声两类,其中非鼾声包括睡眠时的呼吸声、说话声、被子摩擦声等睡眠期间除打鼾外的其他声音。
[0062]
步骤s3中提取音频数据mfcc作为声音识别特征参数,包括如下步骤:
[0063]
s31,将平稳的时域音频信号进行傅里叶变换转换为频域信号,并计算所有对应频率的功率谱;
[0064]
s32,将s31中的频域信号通过梅尔标度三角形滤波器组来平滑频谱上的特征,每个滤波器组输出的对数能量s(m)为:
[0065][0066]
其中l表示滤波器的数量,l表示滤波器总个数,k表示频域信号傅里叶变换采样点数量,n表示傅里叶变换总采样点数,xa(k)表示通过快速傅里叶变换得到的语音信号频谱功率,h(k)表示三角滤波器得到的能量谱的频率响应;
[0067]
s33,对每个滤波器组输出的对数能量s(l)作离散余弦变换得到mfcc系数c(p):
[0068][0069]
其中,p和p表示mfcc系数的阶数。
[0070]
步骤s4建立脉冲神经网络模型包括输入脉冲编码、脉冲单元设计、网络参数更新和分类输出,具体包括如下步骤:
[0071]
s41,设计阈值θ对mfcc进行阈值脉冲编码映射成脉冲序列,θ为动态阈值,满足高斯分布;
[0072]
s42,设计lstm脉冲神经单元用于计算脉冲序列,内部结构如图2所示,其门和状态的特征为:
[0073]ft
=σ1(w
f,hht-1
+w
f,x
x
t
+b
f,h
+b
f,x
)
[0074]it
=σ1(w
i,hht-1
+w
i,x
x
t
+b
i,h
+b
i,x
)
[0075]gt
=σ2(w
g,hht-1
+w
g,x
x
t
+b
g,h
+b
g,x
)
[0076]ct
=f
t
⊙ct-1
+i
t
⊙gt
[0077]ot
=σ1(w
o,hht-1
+w
o,x
x
t
+b
o,j
+b
o,x
)
[0078]ht
=o
t
⊙ct
[0079]
其中x
t
表示一组输入序列,f
t
表示遗忘门,i
t
表示输入门,o
t
表示输出门,g
t
表示对输入信号的调制,c
t
为t时刻的单元状态,h
t
为t时刻的隐藏状态,w,b为权重系数。
⊙
表示矩阵计算哈达玛积,σ1(
·
)和σ2(
·
)为激活函数,当超过阈值θ1和θ2时,将累计输入映射成一个脉冲传递下去;
[0080]
s43,对lstm脉冲神经元进行参数更新时,用高斯函数近似替代激活函数σ1(
·
)和σ2(
·
),从而使用反向传播算法进行参数更新;
[0081]
s44,在最后一个lstm脉冲神经单元的输出后跟一个softmax层进行鼾声、非鼾声分类输出,并保存训练好的模型。
[0082]
步骤s5将未经训练的测试集数据输入到保存好的网络模型中进行鼾声和非鼾声两分类识别,完成鼾声检测。
[0083]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1