基于预训练语言模型的疫情病例信息抽取框架构建方法
1.本发明属于文本信息提取技术领域。涉及一种疫情病例信息抽取框架构建方法,更具体地说,涉及一种基于预训练语言模型的集成了命名实体识别网络和蕴含式类别预测网络的疫情病例信息抽取框架构建方法。
背景技术:
2.新型冠状病毒(covid-19)的爆发已经成为全世界共同面临的突发公共卫生事件,以文本形式公开新型冠状病毒感染病例在全世界范围内逐渐普遍。从海量的公开数据中快速提取有效信息有助于控制疾病传播和协调应急响应。但是仅依靠领域专家进行病例文本的实时分析是十分低效和耗时的,无法保障疾病防控和干预措施的时效性。
3.随着深度神经网络的崛起,人工智能技术不断进步。预训练语言模型bert(bidirectional encoder representation from transformers)的提出进一步推动了自然语言处理技术的发展,bert通过在大量无标注文本上进行无监督训练来学习通用的、具有上下文特征的文本表示,并且在问答、机器翻译等十一项自然语言处理任务上取得了大幅度的性能提升。自然语言处理技术在信息抽取任务上的应用为提取病例文本中的关键事实提供了自动化识别模式。命名实体识别和文本分类是信息抽取的主要技术手段,深度学习模型能够从标注数据中学习适合病例信息抽取的参数,从而提取出新病例中的结构化事实。
4.深度神经网络是一种数据驱动的特征学习模式,其性能极大程度依赖于数据的规模和标注质量。数据的标注成本对于任何领域而言都是极为巨大的,尤其涉及新型冠状病毒传播这样的全新研究领域,数据标注的程式化和规范化尤为重要。此外,深度神经网络通常采用端到端的处理方式,对于某个具体任务而言通常具有很高的性能,但是模型不够灵活,可扩展性较差,从而不能完全适应于多方位的病例信息场景。
技术实现要素:
5.为了克服现有技术中存在的不足,本发明针对新型冠状病毒感染病例的特殊性设计了一种数据标注规则,定义了11种细粒度命名实体和6种蕴含式类别来刻画病例文本的关键信息,并提供一种基于预训练语言模型的疫情病例信息抽取框架以自动提取病例信息中的核心要素。该框架使用预训练语言模型编码病例文本,获得病例文本向量表示。随后使用两种不同的神经网络结构分别对病例中的命名实体和蕴含式类别进行识别和分类,实现病例文本的结构化表示。
6.为了实现上述发明目的,解决已有技术中所存在的问题,本发明采取的技术方案是:基于预训练语言模型的疫情病例信息抽取框架构建方法,包括步骤如下:
7.步骤1,对原始疫情病例数据进行标注:分为命名实体标注和蕴含式类别标注;其中,所述的命名实体标注指构建命名实体类型,包括感染者的基本信息相关、病征时间相关、行动轨迹相关和医疗机构相关,使用专有符号对所述的实体类型进行再标注,并制定标
注范式和标注最小粒度,使用“bio”标注方法对实体进行标注;所述的蕴含式类别标注指将涉及具体场景的编码方式进行整合和类别再标注,形成多种蕴含式类别;将命名实体标注数据和全部蕴含式类别数据按比例划分为训练集、验证集和测试集;
8.步骤2,使用预训练语言模型编码病历文本,输出病例文本对应的词向量和句向量;
9.步骤3,采用双向长短期记忆网络lstm和条件随机场crf构建命名实体识别网络,基于步骤2输出的病例文本的词向量,判断病例文本中每个字所属的正确标签,实体识别网络在相应训练集上训练网络参数,在验证集和测试集上对识别效果进行验证和测试;
10.步骤4,采样全连接神经网络构建蕴含式类别预测网络,基于步骤2输出的病例文本的句向量,预测出该文本对应的正确蕴含式类别,蕴含式类别预测网络在相应训练集上训练网络参数,在验证集和测试集上对识别效果进行验证和测试。
11.进一步地,所述步骤1中,构建命名实体类型包括11种细粒度命名实体分别为:年龄、性别、起始地、中转地、目的地、抵达目的地时间、隔离时间、发病时间、就诊时间、就诊及收治医院、确诊时间。
12.进一步地,所述步骤1中,构建包括命名实体类型的命名实体识别标注体系,如表1所示:
13.表1.命名实体识别标注体系
[0014][0015]
其中,【】表示病例文本中提及类别再标注一列中的标签;xx场所表示病例文本中提及的中转地的名称;xx医院表示病例文本中提及的就诊及收治医院的名称。
[0016]
进一步地,所述步骤1中,所述蕴含式类别为6种,包括感染场所、接触地点事件、接触人群、隔离地点、发现方式、病情程度。
[0017]
进一步地,所述步骤1中,构建包括蕴含式类别的蕴含式类别标注体系,如表2所示:
[0018]
表2.蕴含式类别标注体系
[0019][0020]
其中,na表示病例文本中未提及该类别信息;返回人员*表示除疫情发生地以外的返回人员。
[0021]
进一步地,步骤1中,所述命名实体标注的具体步骤为:
[0022]
(a)采用人工粗标的方式对病例中的实体进行标注,得到粗标注数据;
[0023]
(b)统计粗标注数据中不同命名实体类型的标签分布,为减少人工标注量,使用标
签同分布的采样方式选取部分病例文本进行后续的精标注,同分布采样的损失函数如公式(1)所示,随机进行多轮的采样,计算同分布采样损失,选取损失最小的一轮采样样本作为最终的精标注样本;
[0024][0025]
其中l为标签的总数量,和分别表示粗标数据中第i个标签的个数和采样数据中第i个标签的个数;
[0026]
(c)对采样的病例文本进行精标注,即在粗标注数据的基础上将病例文本中不属于选定实体范围的字段标注为其他实体类,包括其他时间、其他地点和其他机构三类;
[0027]
进一步地,步骤2中,所述的预训练语言模型为bert。
[0028]
进一步地,步骤2中,使用预训练语言模型bert编码病历文本;模型初始输入为病例文本集合c={c1,c,
…cm
…
,cm},cm表示第m个病例文本,其中m∈m;病例文本c表示成词的集合c={w1,w2,
…
wn…
,wn},wn表示病例文本中第n个字符,其中n∈n;预训练语言模型的输入向量en由字嵌入向量、分段嵌入向量和位置编码向量组合而成;其中,字嵌入向量是每个字符wn从嵌入矩阵取得的嵌入向量,其中[cls]、[sep]符号分别标识病例文本的开头和结尾;分段嵌入向量标识病例文本对的编号;位置编码向量标识每个单词的位置信息;
[0029]
预训练语言模型对文本的向量转化过程用公式(2)概括,
[0030]
xn=pre_trained(en,θ)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0031]
其中n∈n、θ为预训练语言模型的参数集合;当xn取文本中每个字符所对应的实数向量时,预训练语言模型的输出为病例文本中的词向量;当xn取[cls]句子起始符所对应的实数向量时,预训练语言模型的输出为病例文本中的句向量。
[0032]
进一步地,步骤3中,采用双向lstm和crf构建命名实体识别网络,具体包括以下步骤:
[0033]
(a)基于预训练语言模型输出的词向量采用双向lstm学习实体间的长距离依赖信息,通过公式(3)进行描述,
[0034][0035]
其中,hn为经过双向lstm编码后的向量输出;
[0036]
(b)在双向lstm之后增加一个crf层以更好地学习命名实体标签之间存在的依赖关系,crf层以双向lstm的输出hn为输入学习标签路径的概率分布;对于给定输入c={c1,c2,
…
,cn},其标签序列的概率y={l1,l2,
…
ln…
,ln}由公式(4)表示,
[0037][0038]
其中y
′
为任意可能标签序列,和是模型中可训练的参数;
[0039]
(c)对于给定的m个训练样本命名实体识别网络通过公式(5)所描述的损失函数计算网络的损失,通过最小化该损失函数优化命名实体识别网络;
[0040][0041]
进一步地,步骤4,基于全连接神经网络构建蕴含式类别预测网络,具体包括以下步骤:
[0042]
(a)给定经过预训练语言模型编码的句向量,通过一个全连接神经网络进行非线性变换以提取文本特征,再经过softmax分类器获得病例文本的蕴含式类别标签;
[0043]
(b)对于给定的m个病例文本和病例文本的类别蕴含式类别预测网络通过公式(6)所描述的损失函数计算网络的损失,通过最小化该损失函数优化蕴含式类别预测网络,
[0044][0045]
其中i表示第i个训练病例文本,表示模型预测的类别,y表示病例文本的真实类别。
[0046]
本发明有益效果是:本发明设计了一种疫情感染病例数据标注规则,提出一种基于预训练语言模型的信息抽取框架自动提取病例中的核心要素,其中,命名实体识别网络能准确地识别病例文本中的命名实体,定位病例传播路径的关键信息,蕴含式病例类别预测网络能够高效预测蕴含式类别,判断病例传播途径的主要形式,实现了病例文本的结构化表示,以进一步辅助疾病防控专家制定新型冠状病毒传播的干预措施。
附图说明
[0047]
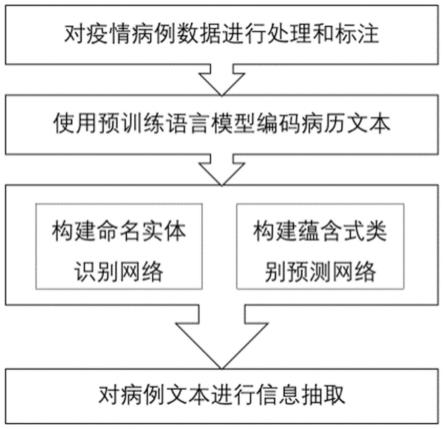
图1是本发明实施例新冠肺炎病例文本信息抽取步骤流程图。
[0048]
图2是本发明实施例模型框架图。
[0049]
图3是本发明实施例命名实体识别结果。柱状图展示了模型对9类命名实体的识别精确率、召回率和f值。精确率用黑线三角标示,召回率用灰线菱形标示,柱状长度表示f值。扇形面积图展示了病例文本中每类细粒度命名实体的标签数量。
[0050]
图4是本发明实施例蕴含式类别预测结果。
[0051]
图5是本发明实施例9种细粒度命名实体在粗标注(r.a)和精标注(f.a)条件下的f值对比图。图中柱状图表示精标注下的f值,折线图表示粗标注下的f值。折线图上的方形低于柱高说明粗标注的f值低于精标注f值。
具体实施方式
[0052]
下面结合附图对本发明作进一步说明。
[0053]
如图2所示,本发明实施例模型框架图中,标注数据包括命名实体标注和蕴含式类别标注两种形式。“b
‑”
表示一个命名实体的开始位置,“i
‑”
表示命名实体的中间位置。新冠疫情病例信息抽取框架covid-19-ccie由预训练语言模型、命名实体识别网络和蕴含式类别预测网络构成。
[0054]
1、预训练语言模型中输入是病例文本中的每个单词,[cls]标识句子的开始,[sep]标识不同句子之间的分隔符;“t”表示transformer,其内部结构如子图(a)所示。(a)中的
⊕
表示向量拼接操作。
[0055]
2、命名实体识别网络由双向lstm和crf构成,“l”表示lstm,其内部结构图如子图(b)表示。(b)中的表示向量拼接,表示向量的元素对位乘操作。σ为sigmoid函数,tanh表示激活函数,x
t
和h
t
分别为lstm的输入和输出。
[0056]
3、蕴含式类别预测网络由全连接神经网络构成,[cls]向量为句向量。
[0057]
4、模型评估包括命名实体识别评估和蕴含式类别预测评估。评估方式均为分析模型的输出结果与黄金标注之间的误差。
[0058]
如图1所示,一种基于预训练语言模型的集成了命名实体识别网络和蕴含式类别预测网络的疫情病例信息抽取框架构建方法,包括以下步骤:
[0059]
步骤1、以信息抽取技术的数据需求为导向,设计一套面向新型冠状病毒感染病例的标注规则,包括命名实体和蕴含式类别两种标注体系,具体包括以下子步骤:
[0060]
(a)以信息抽取技术的数据需求为导向,设计一套面向新型冠状病毒感染病例的标注规则,包括命名实体和蕴含式类别两种标注体系,命名实体标注体系涵盖11种细粒度的命名实体类型,相应专有符号、标注范式、标注最小粒度如表1所示。为了让信息抽取模型聚焦于关键特征,将地点类别qsl、mdl的标注最小粒度限定为“市”,将时间类别的标注最小粒度限定为“日”。采用“bio”标注方法对实体进行标注,具体地,对于实体起始位置的字符,标注为“b-l”,对于实体中间位置字符,标注为“i-l”,对于实体结束位置的字符,标注为“o-l”,其中l为实体所属类别的再标注标签;
[0061]
(b)对于蕴含式类别标注体系,将涉及的具体场景编码方式进行整合,将语义相似的具体场景归为一类,最后整合成6种蕴含式类别,如表3所示;
[0062]
表3.本实施例蕴含式类别标注体系
[0063][0064][0065]
其中,na表示病例文本中未提及该类别信息;返回人员*表示除疫情发生地以外的返回人员。
[0066]
步骤2、对原始疫情病例数据进行处理和标注。依据步骤1的标注规则,通过粗标注、精标注两步对病例文本进行命名实体标注;通过文本匹配的方式进行蕴含式类别标注,构建病历信息抽取数据集;将精标注的少量命名实体数据和全部蕴含式类别数据按一定比例划分为训练集、验证集和测试集,得到新冠疫情病例抽取框架covid-19-ccie所需的信息抽取数据集;
[0067]
命名实体标注具体包括以下子步骤:
[0068]
(a)根据表1规则,采用人工粗标的方式对病例中的实体进行标注,得到粗标注数据;
[0069]
(b)统计粗标注数据中9种命名实体的标签分布,为减少人工标注量,使用标签同分布的采样方式选取约12%的病例文本进行后续的精标注,同分布采样的损失函数如上述公式(1),随机进行100轮采样,计算同分布采样损失,选取损失最小的一轮采样样本作为最终的精标注样本;
[0070]
(c)对采样的病例文本进行精标注,即在粗标注数据的基础上将病例文本中不属于选定实体范围的字段标注为其他实体类,包括其他时间(ott)、其他地点(otl)和其他机构(oti)三类;
[0071]
上述蕴含式类别标注,依据表3构造一个词汇表来存储所有蕴含式类别标签和该标签下的所有场景,通过文本匹配的方式将每一个病例文本与词汇表中的所有场景进行匹配,以确定感染病例所属的类别标签。
[0072]
步骤3、使用预训练语言模型bert编码病历文本,获得能够表达长距离语义信息的词向量。模型初始输入为病例文本集合c={c1,c,
…cm
…
,cm},cm表示第m个病例文本,其中m∈m;病例文本c表示成词的集合c={w1,w2,
…
wn…
,wn},wn表示病例文本中第n个字符,其中n∈n;预训练语言模型的输入向量en由字嵌入向量、分段嵌入向量和位置编码向量组合而成;其中,字嵌入向量是每个字符wn从嵌入矩阵取得的嵌入向量,其中[cls]、[sep]符号分别标识病例文本的开头和结尾;分段嵌入向量标识病例文本对的编号;位置编码向量标识每个单词的位置信息。预训练语言模型对文本的向量转化过程可以用公式(2)。当xn取文本中每个字符所对应的实数向量时,预训练语言模型的输出为病例文本中的词向量。当xn取[cls]句子起始符所对应的实数向量时,预训练语言模型的输出为病例文本中的句向量。
[0073]
步骤4、采用双向lstm和crf构建命名实体识别网络,该网络目标是对于病例文本中任意给定的词,判断出这个词所属的正确标签,具体包括以下子步骤:
[0074]
(a)基于预训练语言模型输出的向量采用双向lstm学习实体间的长距离依赖信息,通过公式(3)进行描述;
[0075]
(b)在双向lstm之后增加一个crf层以更好地学习命名实体标签之间存在的依赖关系,crf层以双向lstm的输出hn为输入来学习标签路径的概率分布。对于给定输入c={c1,c2,...,cn},其标签序列的概率y={l1,l2,
…
,ln}由公式(4)表示。
[0076]
(c)对于给定的m个训练样本命名实体识别网络通过公式(5)所描述的损失函数计算网络的损失,通过最小化该损失函数优化命名实体识别网络。
[0077]
步骤5、基于全连接神经网络构建蕴含式类别预测网络,其目标是对于一个完整的病例文本s,预测出该文本对应的正确类别,具体包括以下子步骤:
[0078]
(a)给定经过预训练语言模型编码的句向量,通过一个全连接神经网络进行非线性变换以提取文本特征,再经过softmax分类器获得病例文本的蕴含式类别标签;
[0079]
(b)对于给定的m个病例文本和病例文本的类别蕴含式类别预测网络通过公式(6)所描述的损失函数计算网络的损失,通过最小化该损失函数优化蕴含式类别预测网络。
[0080]
步骤6、对疫情病例信息抽取框架进行评估,分别针对命名实体识别和蕴含式类别预测两种不同的任务评估框架的信息抽取效果。
[0081]
为了检验本发明的有效性,本发明在10017份感染者病例上进行了实验,对于命名实体识别任务,在1200份精标注病例中选取1000份作为该任务的训练集,其余200份中选取100份作为验证集、100份作为测试集,在测试集上评估模型效果;对于蕴含式类别预测任务,选取全部的10017份感染者病例并以8:1:1的比例划分为训练集、验证集和测试集,在测试集上评估模型效果。针对命名实体识别和蕴含式类别预测两种不同的任务,使用两套不同的评价体系来评估模型效果,对于命名实体识别任务,评估指标为精确率(precision)、召回率(recall)和f值(f-value),如公式(7)所示,
[0082][0083][0084][0085]
其中tp表示将正样本预测正确的数量,fp表示将正样本预测错误的数量,fn表示将负样本预测错误的数量,f值是精确率和召回率的谐波均值;
[0086]
对于蕴含式类别预测任务,使用准确率(acc.),宏f值(macro-f)和加权f值(weighted-f)来评估,如公式(8)所示,
[0087][0088][0089][0090]
其中m表示测试集中的样本数量,k表示样本标签类型的数量。fi表示每一类标签的f值。wi表示每一类标签的权重,这里使用每一类标签的样本数量作为计算加权f值的权重。
[0091]
使用基于预训练语言模型的疫情病例信息抽取框架对11种细粒度的命名实体进行识别,其中年龄(age)和性别(ged)两种细粒度命名实体在病例文本中的描述非常规范且固定,因此使用正则式规则匹配方法进行提取,准确率可达100%。模型对其余9种细粒度的命名实体识别结果如图3所示,9类细粒度命名实体识别的平均f值为81.004%。抵达目的地时间(mdt),发病时间(fbt),确诊时间(qzt),目的地(mdl)和就诊及收治医院(zsi)这五类实体的识别结果高于平均f值。其中zsi类实体的f值达到最高的95.9%。同时,模型对于描述粒度更具体的中转地(zzl)和数量占比不足5%的隔离地点(glt)的识别率也能取得较高的f值。
[0092]
使用基于预训练语言模型的疫情病例信息抽取框架对病例文本的蕴含式类别进行预测,模型对6种蕴含式类别的分类结果如图4所示,可以看出,基于预训练语言模型的疫
情病例信息抽取框架对6种蕴含式类别的分类准确率(acc.)均达到80%以上,从而说明模型能够准确的根据病例文本内容判断其所属的标签,从而明确感染者在病发周期内的接触对象以及当前的生命体征表现。宏f值(macro-f)反映了模型在不同标签中的分类性能,可以看到基于预训练语言模型的疫情病例信息抽取框架在标签种类较多且分布极不平衡的接触地点事件(event)类中的性能依然是具有竞争力的。但是低于其他5种蕴含式类别的分类结果,这主要是因为在event类别中,标签数量过少的event_travel和event_hospital的分类结果较低,从而影响了整体的宏f值。为此,我们引入加权f值来平衡样本数量对宏f值的影响。加权f值(weighted-f)的评估结果与准确率基本一致。综合图4中的结果可以证明,在不同的蕴含式类别中,基于预训练语言模型的疫情病例信息抽取框架模型能够根据不同的标签学习病例文本的语义特征,较好地实现蕴含式类别预测。
[0093]
此外,本发明还使用基于预训练语言模型的疫情病例信息抽取框架分别在粗标注数据集和精标注数据集上进行实验,对比结果如图5所示,可以看出,在9种细粒度命名实体的对比中,精标注的结果优于粗标注结果,尤其是zsi实体的f值提升了118%。实验结果证明了本发明提出的面向新型冠状病毒感染病例的标注规则适合于人工智能技术在病例文本信息抽取中的应用。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1