菌群移植配型的排序方法、系统、计算机设备及存储介质与流程
1.本发明涉及临床医学治疗技术领域,特别是涉及菌群移植配型的排序方法、系统、计算机设备及存储介质。
背景技术:
2.菌群移植(human microbiota transplantation,hmt或fmt)是指将健康供体的肠道菌群通过智能肠菌处理系统制成混悬液或胶囊,移植到患者胃肠道内,通过重建患者正常功能的肠道菌群以实现其肠道及肠道外疾病的治疗。菌群移植作为重建肠道菌群的有效手段,已用于难辨梭状芽孢杆菌感染等多种菌群相关性疾病的治疗和探索性研究,并被认为是近年的突破性医学进展,并且菌群移植还在难治性肠道感染、难治性炎症性肠病、糖尿病合并的神经病变等肠道菌群相关性疾病中进行了探索应用。
3.目前,进行肠道菌群移植的常用方法是根据供体和受体的数据,进行逐一比对给出排序,但是这种方法不仅计算效率低下,而且受体和供体的数量是不断动态增长的,从而导致计算复杂性会大幅增加,并且存在大量重复计算问题。
技术实现要素:
4.为了解决上述技术问题,本发明的目的是提供一种针对肠道菌群移植时受体和供体的数据建立搜索引擎,通过近似为回归问题解决排序问题,降低计算复杂性和提高计算效率的菌群移植配型的排序方法、系统、计算机设备及存储介质。
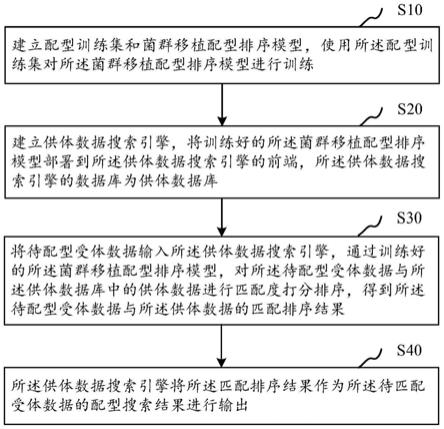
5.第一方面,本发明提供了菌群移植配型的排序方法,所述方法包括:
6.建立配型训练集和菌群移植配型排序模型,使用所述配型训练集对所述菌群移植配型排序模型进行训练;
7.建立供体数据搜索引擎,将训练好的所述菌群移植配型排序模型部署到所述供体数据搜索引擎的前端,所述供体数据搜索引擎的数据库为供体数据库;
8.将待配型受体数据输入所述供体数据搜索引擎,通过训练好的所述菌群移植配型排序模型,对所述待配型受体数据与所述供体数据库中的供体数据进行匹配度打分排序,得到所述待配型受体数据与所述供体数据的匹配排序结果;
9.所述供体数据搜索引擎将所述匹配排序结果作为所述待匹配受体数据的配型搜索结果进行输出。
10.进一步地,所述配型训练集的公式表示为:
11.ψ={(s,t),score}∈rn×r12.式中,s和t分别为由n/2个元素组成的肠道菌群数据特征向量,分别代表受体数据和供体数据,score为一个实数,表示受体数据和供体数据的匹配度,r为训练集特征向量。
13.进一步地,所述菌群移植配型排序模型使用的打分排序方法为pointwise方法。
14.进一步地,使用prank算法对所述菌群移植配型排序模型进行训练。
15.第二方面,本发明提供了菌群移植配型的排序系统,所述系统包括:
16.排序模型生成模型,用于建立配型训练集和菌群移植配型排序模型,使用所述配型训练集对所述菌群移植配型排序模型进行训练;
17.搜索引擎生成模型,用于建立供体数据搜索引擎,将训练好的所述菌群移植配型排序模型部署到所述供体数据搜索引擎的前端,所述供体数据搜索引擎的数据库为供体数据库;
18.匹配结果生成模型,用于将待配型受体数据输入所述供体数据搜索引擎,通过训练好的所述菌群移植配型排序模型,对所述待配型受体数据与所述供体数据库中的供体数据进行匹配度打分排序,得到所述待配型受体数据与所述供体数据的匹配排序结果;
19.搜索结果输出模型,用于所述供体数据搜索引擎将所述匹配排序结果作为所述待匹配受体数据的配型搜索结果进行输出。
20.进一步地,所述配型训练集的公式表示为:
21.ψ={(s,t),score}∈rn×r22.式中,s和t分别为由n/2个元素组成的肠道菌群数据特征向量,分别代表受体数据和供体数据,score为一个实数,表示受体数据和供体数据的匹配度,r为训练集特征向量。
23.进一步地,所述菌群移植配型排序模型使用的打分排序方法为pointwise方法。
24.进一步地,使用prank算法对所述菌群移植配型排序模型进行训练。
25.第三方面,本发明实施例还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
26.第四方面,本发明实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述方法的步骤。
27.上述本发明提供了菌群移植配型的排序方法、系统、计算机设备及存储介质。通过所述方法,针对肠道菌群移植时受体和供体的数据建立搜索引擎,通过近似为回归问题解决排序问题,本发明不仅能够对受体和供体进行智能匹配,而且匹配计算的复杂性低,匹配结果的可读性更好,这对于临床医学领域来说,是非常有意义的。
附图说明
28.图1是本发明实施例菌群移植配型的排序方法的流程示意图;
29.图2是本发明实施例菌群移植配型的排序系统的结构示意图;
30.图3是本发明实施例中计算机设备的内部结构图。
具体实施方式
31.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
32.请参阅图1,本发明第一实施例提出的菌群移植配型的排序方法,包括步骤s10~s40:
33.步骤s10,建立配型训练集和菌群移植配型排序模型,使用所述配型训练集对所述
菌群移植配型排序模型进行训练。
34.由于目前的肠道菌群移植配型是根据供体和受体数据进行逐一计算评估比对,计算效率比较低下,因此本发明通过建立菌群移植配型排序模型来对供体受体进行智能匹配,本实施例中的菌群移植配型排序模型使用的打分排序方法选择了pointwise方法,通过近似为回归问题来解决排序问题,菌群移植配型排序模型输入的单条样本为{(受体,供体),得分},将每个受体-供体对的匹配度得分作为实数分数,使得单个受体-供体对作为样本点,为此,本实施例专门建立了配型训练集来对菌群移植配型排序模型进行训练。
35.本实施例中的配型训练集可以由经验丰富的肠道菌群移植科研人员根据实际经验进行构造,对一个受体数据对应匹配的供体数据的匹配度进行打分,因此训练集可以表示为:ψ={(s,t),score}∈rn×
r,式中s 和t分别为由n/2个元素组成的肠道菌群数据特征向量,分别代表受体数据和供体数据,其中,特征向量s中的元素为(si,1≤i≤n/2),特征向量t中的元素为(tj,(n/2)+1≤j≤n),score为一个实数,表示受体数据和供体数据的匹配度,r为训练集特征向量。
36.在建立好配型训练集和菌群移植配型排序模型之后,我们使用配型训练集对菌群移植配型排序模型进行训练,本实施例中采用了prank算法对菌群移植配型排序模型进行训练,即对于训练集中的(受体-供体)数据对x=(s,t),菌群移植配型排序模型的训练过程就是对x打分,让模型输出的分数和训练集中的score尽可能的接近,从而使训练好的模型在实际应用中,对输入的任一受体数据s,可以对所有供体数据t 计算(s,t)分值,并按照打分的大小进行排序,当然也可以使用其他算法对模型进行训练,在此以prank算法为例进行描述。
37.在实际训练过程中,我们使用的训练样本的score的值是一个实数,为了方便处理和解读,我们要将这个score转化成一个具有强弱分级的 label,如perfect(完美)》excellent(优秀)》good(良好)》fair(一般)》bad(糟糕)这样具有强弱关系的五级label。为了将score映射到分级label,需要设置5个阈值来区分score的label。如果score落在某两个相邻阈值之间,则划分为相应的label,从而使分析结果更具备可读性。
38.prank的目标是训练一个ranking rule h:rn→
y∈{1,2,
…
,k},即将样本特征投影到k个等级上,h的定义为:
[0039][0040]
其中,x=(s,t)∈rn,w和br是模型参数,w
·
x=w1·
x1+w2·
x2+
…
+wn·
xn, wi为特征向量x中每个维度的权重,k个br就是上述的阈值, b1≤...b
k-1
≤bk=∞,如果一个样本满足b
r-1
《w
·
x≤br,则该样本的预测rank 值为r,即y=h(x)=r。
[0041]
prank更新参数的方法类似于随机梯度下降法,每当预测错误一个样本后,就更新参数,对于一个样本(x,y)和模型参数w和br,如果模型能够正确预测,则w
·
x》br,r≤y-1,w
·
x《br,r≥y。
[0042]
如上所述,y的取值是从集合{1,2,3
…
k}中选取,在此引入辅助变量s,s是一个向量,长度为k-1,s与y是一一对应的,对于样本(x,y) 来说,s的各维度值定义为:sr=+1,r≤y-1,sr=-1,r≥y,r《k,则参数的学习过程为:输入样本(x,y),对于所有的r∈{1,...,k-1},如果模型预测结果是正确的,则sr·
(w
·
x-br)》0,此时参数不需要更新;如果模型预测
结果是错误的,则存在sr·
(w
·
x-br)≤0,此时需要更新参数,对于特定的r,如果sr·
(w
·
x-br)≤0,说明score值w
·
x落在了阈值br的错误的一侧,为了改正这个错误的预测,只需要将w
·
x和br相对移动就能完成对于参数w和br的更新,更新公式为br=b
r-sr,w=w+sr·
x。
[0043]
步骤s20,建立供体数据搜索引擎,将训练好的所述菌群移植配型排序模型部署到所述供体数据搜索引擎的前端,所述供体数据搜索引擎的数据库为供体数据库。
[0044]
为了方便对受体进行配型查询,我们建立了供体数据搜索引擎,将训练好的菌群移植配型排序模型部署在搜索引擎的前端,而搜索引擎的数据库则是包含全部供体数据的供体数据库,由于供体数据是动态更新的,通过搜索引擎可以使用户只关注受体数据,而不用在意供体数据的变化,由菌群移植配置排序模型对所有供体数据自动进行匹配计算,从而降低计算的复杂性,提高了配型计算效率。
[0045]
步骤s30,将待配型受体数据输入所述供体数据搜索引擎,通过训练好的所述菌群移植配型排序模型,对所述待配型受体数据与所述供体数据库中的供体数据进行匹配度打分排序,得到所述待配型受体数据与所述供体数据的匹配排序结果。
[0046]
搭建好供体数据搜索引擎之后,将任一受体数据s输入搜索引擎后,菌群移植配型排序模型会分别计算受体数据s与供体数据库里的所有供体数据t的(s,t)的匹配度得分,并按照匹配度分数的大小进行排序,从而得到所有供体数据t匹配该受体数据s的排序结果。
[0047]
步骤s40,所述供体数据搜索引擎将所述匹配排序结果作为所述待匹配受体数据的配型搜索结果进行输出。
[0048]
在由菌群移植配型排序模型计算得到所有供体数据t匹配受体数据s的排序结果后,供体数据搜索引擎会将该排序结果作为受体数据s 的配型搜索结果进行输出,从而完成一次受体数据的配型搜索查询,医生可以结合临床经验,选择排名靠前的供体数据。
[0049]
本实施例提供的菌群移植配型的排序方法,相比传统方法受体供体配型计算复杂性高,计算效率低下,并且存在大量重复计算的问题,本发明通过针对肠道菌群移植时受体和供体的数据建立搜索引擎,将排序问题近似为回归问题,通过菌群移植配型排序模型对受体和供体进行智能匹配,具有良好的匹配结果可读性,降低了受体和供体的配型计算复杂性,提高了计算效率和匹配的准确度。
[0050]
请参阅图2,基于同一发明构思,本发明第二实施例提出的菌群移植配型排序的系统,包括:
[0051]
排序模型生成模型10,用于建立配型训练集和菌群移植配型排序模型,使用所述配型训练集对所述菌群移植配型排序模型进行训练。
[0052]
搜索引擎生成模型20,用于建立供体数据搜索引擎,将训练好的所述菌群移植配型排序模型部署到所述供体数据搜索引擎的前端,所述供体数据搜索引擎的数据库为供体数据库。
[0053]
匹配结果生成模型30,用于将待配型受体数据输入所述供体数据搜索引擎,通过训练好的所述菌群移植配型排序模型,对所述待配型受体数据与所述供体数据库中的供体数据进行匹配度打分排序,得到所述待配型受体数据与所述供体数据的匹配排序结果。
[0054]
搜索结果输出模型40,用于所述供体数据搜索引擎将所述匹配排序结果作为所述待匹配受体数据的配型搜索结果进行输出。
[0055]
本发明实施例提出的菌群移植配型的排序系统的技术特征和技术效果与本发明实施例提出的方法相同,在此不予赘述。上述菌群移植配型的排序系统中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
[0056]
请参阅图3,一个实施例中计算机设备的内部结构图,该计算机设备具体可以是终端或服务器。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口、显示器和输入装置。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统和计算机程序。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现菌群移植配型的排序方法。该计算机设备的显示屏可以是液晶显示屏或者电子墨水显示屏,该计算机设备的输入装置可以是显示屏上覆盖的触摸层,也可以是计算机设备外壳上设置的按键、轨迹球或触控板,还可以是外接的键盘、触控板或鼠标等。
[0057]
本领域普通技术人员可以理解,图3中示出的结构,仅仅是与本技术方案相关的部分结构的框图,并不构成对本技术方案所应用于其上的计算机设备的限定,具体的计算设备可以包括比途中所示更多或更少的部件,或者组合某些部件,或者具有相同的部件布置。
[0058]
此外,本发明实施例还提出一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述方法的步骤。
[0059]
此外,本发明实施例还提出一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述方法的步骤。
[0060]
综上,本发明实施例提出的菌群移植配型的排序方法、系统、计算机设备及存储介质,所述方法通过建立配型训练集和菌群移植配型排序模型,使用所述配型训练集对所述菌群移植配型排序模型进行训练;建立供体数据搜索引擎,将训练好的所述菌群移植配型排序模型部署到所述供体数据搜索引擎的前端,所述供体数据搜索引擎的数据库为供体数据库;将待配型受体数据输入所述供体数据搜索引擎,通过训练好的所述菌群移植配型排序模型,对所述待配型受体数据与所述供体数据库中的供体数据进行匹配度打分排序,得到所述待配型受体数据与所述供体数据的匹配排序结果;所述供体数据搜索引擎将所述匹配排序结果作为所述待匹配受体数据的配型搜索结果进行输出。该方法通过针对肠道菌群移植时受体和供体的数据建立搜索引擎,将排序问题近似为回归问题,通过菌群移植配型排序模型对受体和供体进行智能匹配,具有良好的匹配结果可读性,降低了受体和供体的配型计算复杂性,提高了计算效率和匹配的准确度。
[0061]
本说明书中的各个实施例均采用递进的方式描述,各个实施例直接相同或相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。需要说明的是,上述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0062]
以上所述实施例仅表达了本技术的几种优选实施方式,其描述较为具体和详细,
但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和替换,这些改进和替换也应视为本技术的保护范围。因此,本技术专利的保护范围应以所述权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1