助盲器的制作方法
1.本发明的实施例涉及盲人的行走辅助工具领域,具体涉及一种助盲器。
背景技术:
2.中国是世界上盲人最多的国家,据世界卫生组织给的数据,2016年,中国盲人的人数高达1730万,也就是说每一百个人里面至少有一个盲人。可是在我们的日常生活中却看不到几个盲人,这是因为盲道被随意占用,且几乎所有的盲道都没有从盲人的角度来规划、设计、建设以及管理,因此盲人的出行受到了很大的限制。
技术实现要素:
3.本发明的实施例提供一种助盲器,其包括:图像采集部,图像采集部用于采集场景的图像信息,其中,场景指助盲器的使用者所处的外部环境;图像处理部,图像处理部对采集的图像信息进行处理;图像符号转换系统,图像符号转换系统接收经过图像处理部处理后的图像信息,并将经过处理后的图像信息转换成预定的符号信息,预定的符号信息能够表征助盲器的使用者所处在的场景信息;舌部刺激部,舌部刺激部接收预定的符号信息,并根据预定符号的信息来输出电极脉冲,电极脉冲对使用者的舌部形成刺激,使用者能够根据所述刺激识别出其所处在的场景。
4.因此,本发明的实施例提供的助盲器,能够帮助有视力障碍的人或者盲人识别出其所处在的场景。具体地,助盲器能够将环境的场景信息转换为符号,这些符号能够通过电极脉冲刺激使用者的舌部,从而使用者能够根据刺激识别出其所处在的场景。
附图说明
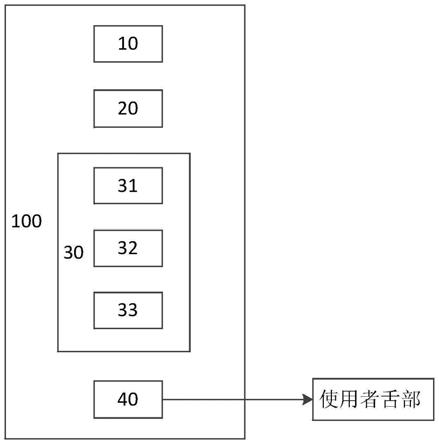
5.图1为本发明的实施例提供的助盲器的示意图;
6.图2为本发明的实施例提供的助盲器的图像符号转换系统的示意图;
7.图3为本发明的又一实施例提供的助盲器的示意图;
8.图4为本发明的实施例提供的助盲器中储存的预定的符号信息的示意图;
9.图5为本发明的实施例提供的助盲器中所要采集的场景信息的示意图;
10.图6为本发明的实施例提供的助盲器中图像处理部对图像信息进行处理的示意图。
11.标号说明:
12.100、助盲器;10、图像采集部;20、图像处理部;30、图像符号转换系统;31、识别模型;32、符号信息库;33、转换部;40、舌部刺激部。
具体实施方式
13.为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例的附图,对本发明的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明的一个实施
例,而不是全部的实施例。基于所描述的本发明的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
14.需要说明的是,除非另外定义,本发明使用的技术术语或者科学术语应当为本发明所属领域内具有一般技能的人士所理解的通常意义。若全文中涉及“第一”、“第二”等描述,则该“第一”、“第二”等描述仅用于区别类似的对象,而不能理解为指示或暗示其相对重要性、先后次序或者隐含指明所指示的技术特征的数量,应该理解为“第一”、“第二”等描述的数据在适当情况下可以互换。若全文中出现“和/或”,其含义为包括三个并列方案,以“a和/或b”为例,包括a方案,或b方案,或a和b同时满足的方案。此外,为了便于描述,在这里可以使用空间相对术语,如“上方”、“下方”、“顶部”、“底部”等,仅用来描述如图中所示的一个器件或特征与其他器件或特征的空间位置关系,应当理解为也包含除了图中所示的方位之外的在使用或操作中的不同方位。
15.请参照图1-图6,本发明的实施例提供的助盲器100,能够帮助有视力障碍的人或者盲人识别出其所处在的场景。具体地,助盲器100能够将环境的场景信息转换为符号信息,这些符号信息能够通过电极脉冲刺激使用者的舌部,从而使用者能够根据刺激识别出其所处在的场景。
16.请结合图1-图3,助盲器100可以包括:图像采集部10,图像采集部10用于采集场景的图像信息,其中,场景指助盲器的使用者所处的外部环境;图像处理部20,图像处理部20对采集的图像信息进行处理;图像符号转换系统30,图像符号转换系统30接收经过图像处理部20处理后的图像信息,并将经过处理后的图像信息转换成预定的符号信息,预定的符号信息能够表征助盲器的使用者所处在的场景信息;舌部刺激部40,舌部刺激部40接收预定的符号信息,并根据预定符号的信息来输出电极脉冲,电极脉冲对使用者的舌部形成刺激,使用者能够根据刺激识别出其所处在的场景。
17.在一些实施例中,助盲器100可以设计成头戴式,其中,图像采集部10可以设置有摄像头,摄像头位于使用者的额头部位。图像采集部10以每秒24帧的频率采集场景的图像信息,但不以此为限,可以按照需求进行调整。
18.在一些实施例中,图像采集部10可以存储有导航地图,导航地图可以包括百度地图以及高德地图,但不以此为限,可以按照需求进行调整。
19.在一些实施例中,图像处理部20对采集的图像信息进行的处理可以包括:裁剪图像信息以及改变图像信息的像素或通道,如图6所示,但不以此为限,可以按照需求进行调整。
20.例如,采集的原始图像有rgb三个通道信息,通过公式:
21.gray=0.03
×
red+0.59
×
green+0.11
×
blue
22.将图像灰度化,只保留0-255的灰度值。
23.通过上述处理,可以提高图像信息的处理速度和处理能力,从而,助盲器可以将场景信息更快速的提供给使用者。本领域技术人员还可以采用其他方式。
24.在一些实施例中,图像符号转换系统30可以包括识别模型31,其中,例如,识别模型31是根据神经网络建立的,神经网络模型设计使用多层感知网络,其为全连接的神经网络,属于监督学习算法,通过大量训练数据的标注。
25.在本发明的一些实施例中,基于神经网络的识别模型的训练包括多个隐含层,使
用线性纠正函数作为激活函数。
26.relu=max(0,x);
27.其中,relu表示激活函数。
28.由于x》0时导数为1,所以,这样的激活函数能够在x》0时保持梯度不衰减,从而缓解梯度消失问题。所以使用relu取代sigmoid函数去激活神经元。
29.因此,识别模型31能够在短时间内识别出经过图像处理部20处理后的图像信息,并且提取其中的图像要素。
30.在一些实施例中,图像符号转换系统30包括符号信息库32,符号信息库32储存有与助盲器的使用者在出行时感兴趣的或经常遇到的场景信息相对应的预定的符号信息,因此当图像要素传输到符号信息库32时,符号信息库32能够根据图像要素查找到与之对应的预定的符号信息。从而,可以快速的识别使用者的出行场景,降低助盲器的运算量,提高识别效率。
31.在一些实施例中,图像符号转换系统30还包括转换部33,转换部33能够将图像要素转换成预定的符号信息。
32.在一些实施例中,不同的预定的符号信息设置成具有内在的顺序。这里的不同的预定符号信息具有内在的顺序,是指这些符号信息设置成有一定的规律性和顺序性,从而有助于助盲器的使用者学习和记忆不同的符号信息代表的含义。
33.在一些实施例中,预定的符号信息设置成相同的符号信息处于静态下与处于动态下具有不同的意义,例如,在一个实施例中符号信息为汽车图形,当汽车图形为静态即静止时,可以说明使用者的前方有一辆静止的汽车,而当汽车图形为动态即运动时,可以说明使用者的前方有一辆处于运动状态的汽车。因此,通过相同的符号信息在静态与动态下表示不同的意义能够为使用者提供更多的信息。
34.在一些实施例中,预定的符号信息是场景信息经过科学的优化和抽象转换成的。
35.下面参见图4,在一些实施例中,预定的符号信息可以包括象形字和图形,象形字和图形能够很好地表达某些特定的场景信息的特征。
36.在一些实施例中,象形字可以包括静态的象形字以及规则动态变化的象形字。
37.在一些实施例中,图形可以包括静态的图形以及规则动态变化的图形。
38.其中,规则动态变化的象形字以及规则动态变化的图形可以让使用者更有效地获取到代表着不同含义的符号信息,并通过不同的符号信息的运动以及不同的组合方式来表达更复杂的出行信息,进而能够更好地指引使用者。
39.在一些实施例中,助盲器100的使用者在出行时感兴趣的或经常遇到的场景信息可以分为室内信息和室外信息,其中,室内信息可以包括卫生间信息、房间信息等,室外信息可以包括交通站点信息以及公路警示信息等一系列关键的场景信息,如图5所示。
40.在一些实施例中,舌部刺激部40设置有多个电极点,其中,电极点可以与血氧检测仪连接。当预定的符号信息传输进舌部刺激部40,能够通过四百个电极点输出电极脉冲,电极脉冲能够对使用者的舌部形成刺激,进而,使用者能够根据上述刺激识别出其所处在的场景。
41.在一些实施例中,助盲器100能进一步辅助有视力障碍的人或者盲人学习盲文以及完成体育活动,例如,田径比赛,乒乓球比赛等。
42.下面对一个使用者使用助盲器100识别场景的整个过程的实施例进行详细的说明。
43.首先经过对识别模型31的优化、训练以及测试,识别模型31已经能够学会识别出有视力障碍的人或盲人的日常出行的场景信息,同时符号信息库32也储存有丰富的与场景信息相对应的预定的符号信息。但在某一个使用者使用助盲器100前,还需要采集这个使用者在日常出行时感兴趣的或经常遇到的场景信息,从而识别模型31能进一步学习识别该使用者感兴趣的或经常遇到的场景信息,例如,卫生间信息、房间信息、交通站点信息以及公路警示信息等等。同时,这些场景信息也以符号信息的方式储存入符号信息库32中,以丰富符号信息库32。
44.采集完该使用者在日常出行时感兴趣的或经常遇到的场景信息后,使用者便可以使用助盲器100,以头戴式的助盲器为例,使用者将助盲器100佩戴于头部,其中,将图像采集部10的摄像头固定于使用者的额头部位,从而有利于图像采集部10采集到使用者视角下的场景的图像信息。此外,使用者将舌部刺激部40放置于其舌头部位上,舌部刺激部40可以根据预定符号的信息输出电极脉冲,电极脉冲对使用者的舌部形成刺激,因此使用者能够根据刺激识别出其所处在的场景。以上完成了助盲器100的佩戴。
45.使用者佩戴好助盲器100后,便可以自由走动,使用者的额头部位的摄像头会随着使用者的移动以每秒24帧的频率采集使用者遇到的场景的图像信息,随后,采集的图像信息传输到图像处理部20,图像处理部20对图像信息依次进行裁剪以及改变图像信息的像素或通道;接着,图像符号转换系统30中的识别模型31能够在短时间内识别出经过图像处理部20处理后的图像信息,并且提取其中的图像要素;然后,图像要素传输到符号信息库32,符号信息库32能够根据图像要素查找到与之对应的预定的符号信息;接着,在转换部33将图像要素转换成预定的符号信息;最后,预定的符号信息传输入舌部刺激部40,舌部刺激部40根据预定符号的信息在四百个电极点输出电极脉冲,电极脉冲对使用者的舌部形成刺激,使用者能够根据刺激识别出其所处在的场景。
46.其中,以场景信息为楼梯作为例子,当使用者的面前有楼梯时,使用者的额头部位的摄像头会以每秒24帧的频率采集上述楼梯的图像信息,随后,采集到的楼梯的图像信息传输到图像处理部20,图像处理部20对楼梯的图像信息依次进行裁剪以及改变楼梯的图像信息的像素和通道;接着,图像符号转换系统30中的识别模型31能够在短时间内识别出经过图像处理部20处理后的楼梯的图像信息,并且提取其中关键的图像要素;然后,图像要素传输到符号信息库32,符号信息库32能够根据图像要素查找到与之对应的预定的符号信息,即楼梯图形;接着,在转换部33将图像要素转换成楼梯图形这一预定的符号信息;最后,楼梯图形这一预定的符号信息传输入舌部刺激部40,舌部刺激部40根据楼梯图形在四百个电极点输出电极脉冲,电极脉冲对使用者的舌部形成刺激,使用者能够根据刺激识别出其前面有一楼梯。
47.对于本发明的实施例,还需要说明的是,在不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合以得到新的实施例。
48.以上,仅为本发明的一些实施例,但本发明的保护范围并不局限于此,本发明的保护范围应以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1