一种痛风预测模型系统、设备及存储介质的制作方法
1.本发明涉及健康管理领域,尤其涉及一种痛风预测模型系统、设备及存储介质。
背景技术:
2.痛风是一组由嘌呤代谢紊乱致血尿酸增高引起尿酸盐结晶沉积关节面所致的常见关节病,具有多并发症、病程长、发作剧烈等特点,且目前无法治愈。我国高尿酸血症与痛风发病率逐年上升,高尿酸血症发病率从1998年的10.10%上升到2008年的17.90%,而痛风的发病率从1998年的0.34%上升到2008年的2.0%;中国社科院调查发现,中国现有近9000万痛风人士,潜在人士1.2亿,而痛风出现情况还在以每年10%的速度逐年上升。2020年痛风现状,每6个人中就有1人高尿酸血症,每13人中有1人痛风,痛风已成为继糖尿病之后的人类第二大代谢慢病,它影响正常生活,晚期还会导致永久性关节畸变等一系列身体机能的病变。
3.痛风诊断的标准系统是关节腔穿刺抽取关节液检查,若关节液中看到尿酸盐结晶可确诊为痛风;但基层医院往往受到条件限制,只能依靠临床表现作出诊断,其准确性受到限制,这样容易错过痛风的最佳防范时机;因此,采取措施对痛风进行预防就显得尤为重要。但是,现有技术无法对个体未来是否患痛风进行预测,从而导致无法及时治疗和预防。
4.因此,当前还没有一个普遍适用的系统,能够解决现有技术无法对痛风进行预测,从而导致无法及时治疗和预防的的问题。
技术实现要素:
5.有鉴于此,本发明提出了一种痛风预测模型系统,用于解决现有技术无法对痛风进行预测,从而导致无法及时治疗和预防的问题。
6.本发明的技术方案是这样实现的:
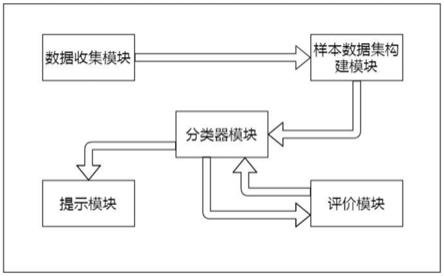
7.本发明第一方面,公开一种痛风预测模型系统,所述系统包括:
8.数据收集模块:用于收集样本数据,收集多份初始样本数据,所述样本数据包括体检数据及随访资料,并对所述初始样本数据进行剔除噪音数据处理,保留剔除噪音数据后依然完整的初始样本数据,并进行标准化处理;
9.样本数据集构建模块:用于构建样本数据集,采用lasso回归对所述进行标准化处理后的初始样本数据进行特征选择,筛选出与痛风强相关的变量作为特征变量,以特征变量为自变量,以是否发生痛风为因变量,构建样本数据集;
10.分类器模块:采用朴素贝叶斯算法训练分类器,用于预测被检者的痛风发病概率;
11.评价模块:用于评价痛风预测模型的预测效能,采用布里尔分数来评价所述痛风预测模型的预测结果价值;
12.提示模块:用于根据被检者的预测患痛风的概率及信息数据给出相应的提示和建议。
13.本发明通过上述系统,建立痛风预测模型,将被检者的信息输入该通风预测模型
即可对被检者患痛风的概率进行准确预测,同时根据被检者的信息为其给出相应的提示和建议。
14.在以上技术方案的基础上,优选的,所述数据收集模块中,对所述样本数据集进行标准化处理具体包括:
15.将所述初始样本数据映射到[-1,1]区间上,使得初始样本数据中每个变量的平均值为0,标准差为1。
[0016]
本发明通过上述系统,方便比较和计算相关系数,同时保持原始样本关系。
[0017]
在以上技术方案的基础上,优选的,所述样本数据集构建模块功能具体包括:
[0018]
设置
[0019][0020]
其中,yi是是否发生痛风即因变量,是回归变量,xi=(x
i1
,x
i2
,
…
,x
in
)为所述特征变量即自变量,βj为第j个自变量的回归系数;通过调整各自变量的回归系数来求因变量yi与回归变量的最小平方差和,即与实际值的最小偏差
[0021][0022]
通过
[0023][0024]
表示使平方差最小的一组回归系数值,其中表示到的向量;
[0025]
通过对回归系数添加约束条件公式
[0026][0027]
对所述使平方差最小的一组回归系数值进行筛选,将与因变量相关度低于预设相关度阈值的自变量的回归系数设置为0,从而在特征选择时将回归系数为0的自变量去除,只保留强相关的自变量,筛选出与痛风强相关的变量作为特征变量;
[0028]
以特征变量为自变量,以是否发生痛风为因变量,构建样本数据集。
[0029]
本发明通过上述系统,针对痛风的主要影响因素进行分析,运用lasso回归进行特征选择,去除大量与痛风无关的变量,降低数据维数,筛选出与痛风强相关的特征变量,从而减少系统的运行时间,同时提高系统的分类性能。
[0030]
在以上技术方案的基础上,优选的,所述分类器模块功能具体包括:
[0031]
设置a={a1,a2,
…
,am}为所述样本数据集中的一条数据样本,ai为a的一个特征属性;bi={b1,b2}为特征类别集合,所述特征类别包括患痛风和未患痛风;
[0032]
利用朴素贝叶斯算法对所述样本数据集进行训练分类,依据条件概率公式
[0033][0034]
计算每个特征类别下各个特征属性的条件概率p(a1|b1),p(a2|b1),
…
p(am|b1);p(a1|b2),p(a2|b2),
…
p(am|b2);
[0035]
样本数据集中每一条数据样本属于每个特征类别的概率p(b1|a),p(b2|a),选取概率最大的特征类别作为该数据样本属于的特征类别,即若p(bi|a)=max{p(b1|a),p(b2|a)},则a∈bi;
[0036]
输出训练好的分类器,所述分类器用以预测出体检者未来患痛风的风险指数。
[0037]
本发明通过上述系统,通过训练分类器,输出特征变量与是否患痛风的映射关系,从而预测出体检者未来患痛风的风险概率。
[0038]
在以上技术方案的基础上,优选的,所述评价模块功能具体包括:
[0039]
通过计算所述分类器的布里尔分数来判断所述痛风预测模型的预测准确度,若所述布里尔分数超过预设分数阈值,判定当前痛风预测模型的预测准确度不符合标准,则分类器模块继续对所述分类器进行训练;若所述布里尔分数未超过预设分数阈值,判定当前痛风预测模型的预测准确度符合标准,完成痛风预测模型的构建。
[0040]
在以上技术方案的基础上,优选的,所述计算所述分类器的布里尔分数具体包括:
[0041][0042]
其中,p(b
t
|a)为所述分类器计算的事件t的预测概率,o
t
为事件t的实际概率,n为预测事件数量;所述事件t为a∈bi,o
t
的值为0或1。
[0043]
本发明通过上述系统,对诉所述分类器进行评价,判断其准确率是否符合标准,确保了分类器的精准程度,进而确保痛风预测模型的预测结果价值。
[0044]
在以上技术方案的基础上,优选的,所述提示模块功能具体包括:
[0045]
根据分类器模块输出的被检者预测患痛风的概率,结合被检者提供的信息数据,针对单个信息数据的危险水平给出相应的提示和建议。
[0046]
本发明通过上述系统,根据体检者未来患痛风的风险概率以及信息数据中单项危险水平,给出更为细致的疾病护理提示建议和解决方案。
[0047]
本发明第二方面,公开一种电子设备,所述设备包括:至少一个处理器、至少一个存储器、通信接口和总线;其中,所述处理器、存储器、通信接口通过所述总线完成相互间的通信;所述存储器存储有可被所述处理器执行的一种痛风预测模型系统功能程序,一种痛风预测模型系统功能程序配置为实现如本发明第一方面所述的一种痛风预测模型系统功能程序。
[0048]
本发明第三方面,公开一种计算机可读存储介质,所述存储介质上存储有一种痛风预测模型系统功能程序,所述一种痛风预测模型系统功能程序被执行时实现如本发明第一方面所述的一种痛风预测模型系统功能程序。
[0049]
本发明的一种痛风预测模型系统相对于现有技术具有以下有益效果:
[0050]
(1)通过建立痛风预测模型,将被检者的信息输入该通风预测模型即可对被检者
患痛风的概率进行准确预测,同时根据被检者的信息为其给出相应的提示和建议;
[0051]
(2)针对痛风的主要影响因素进行分析,运用lasso回归进行特征选择,去除大量与痛风无关的变量,降低数据维数,筛选出与痛风强相关的特征变量,从而减少系统的运行时间,同时提高系统的分类性能。
附图说明
[0052]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0053]
图1为本发明一种痛风预测模型的构建系统模块图。
具体实施方式
[0054]
下面将结合本发明实施方式,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式仅仅是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
[0055]
实施例
[0056]
本发明一种痛风预测模型系统模块见图1,各模块处理步骤说明如下:
[0057]
第一步,数据收集模块收集多份初始样本数据,所述样本数据包括体检数据及随访资料,并对所述初始样本数据进行剔除噪音数据处理,保留剔除噪音数据后依然完整的初始样本数据,并进行标准化处理;转第二步。
[0058]
应当理解的是,在上述方案的基础上,对所述样本数据集进行标准化处理具体包括:将所述初始样本数据映射到[-1,1]区间上,使得初始样本数据中每个变量的平均值为0,标准差为1,目的是方便比较和计算相关系数,同时保持原始样本关系。
[0059]
例如,收集北京国康体检中心2016年5月至2020年5月460例体检数据及随访资料,每位体检者信息包含55个变量,对缺失数据进行填补及剔除数据集中的噪音数据,保留具有完整资料的400名人员作为调查对象。
[0060]
第二步,样本数据集构建模块构建样本数据集,采用lasso回归对所述进行标准化处理后的初始样本数据进行特征选择,筛选出与痛风强相关的变量作为特征变量,以特征变量为自变量,以是否发生痛风为因变量,构建样本数据集。转第三步。
[0061]
应当理解的是,在上述方案的基础上,由于体检数据具有高维度、高冗余等特点而造成系统计算复杂度提高、性等下降等,因此需要利用特征降维对高维体检数据进行处理,特征选择是实现特征降维的有效手段,它通过去除大量与疾病无关的体检变量降低数据维数,寻找与疾病强相关的特征子集,从而减少算法的运行时间,提高算法精度,lasso克服了岭回归、主成分回归在特征选择时可解释性差和结果不稳定的缺陷,已成为热门的特征选择方法之一。因此本技术的痛风预测模型系统中样本数据集构建模块采用了lasso回归对样本数据集中的数据进行处理,具体包括:设置
[0062][0063]
其中,yi是是否发生痛风即因变量,是回归变量,xi=(x
i1
,x
i2
,
…
,x
in
)为所述特征变量即自变量,βj为第j个自变量的回归系数;通过调整各自变量的回归系数来求因变量yi与回归变量的最小平方差和,即与实际值的最小偏差
[0064][0065]
通过
[0066][0067]
表示使平方差最小的一组回归系数值,其中表示到的向量;
[0068]
通过对回归系数添加约束条件公式
[0069][0070]
对所述使平方差最小的一组回归系数值进行筛选,将与因变量相关度低于预设相关度阈值的自变量的回归系数设置为0,从而在特征选择时将回归系数为0的自变量去除,只保留强相关的自变量,筛选出与痛风强相关的变量作为特征变量;
[0071]
以特征变量为自变量,以是否发生痛风为因变量,构建样本数据集。
[0072]
例如,对上述的55个变量进行特征选择,通过lasso回归筛选出与痛风强相关的7个变量,分别是性别、是否有关节炎史、是否存在1天内发病、是否存在关节红肿、发病时最先累及的部位是否是大脚趾、是否有高血压或心血管疾病(其中心血管疾病包括心绞痛,心肌梗塞,短暂性脑缺血发作,脑血管意外,周边血管疾病即心绞痛、mi、chf、卒中/tia、pvd)、血清尿酸水平是否>5.88mg/dl。
[0073]
第三步,分类器模块采用朴素贝叶斯算法训练分类器,用于预测被检者的痛风发病概率。转第四步。
[0074]
应当理解的是,在上述方案的基础上,所述分类器模块功能具体包括:设置a={a1,a2,
…
,am}为所述样本数据集中的一条数据样本,ai为a的一个特征属性;bi={b1,b2}为特征类别集合,所述特征类别包括患痛风和未患痛风;
[0075]
利用朴素贝叶斯算法对所述样本数据集进行训练分类,依据条件概率公式
[0076][0077]
计算每个特征类别下各个特征属性的条件概率p(a1|b1),p(a2|b1),
…
p(am|b1);p(a1|b2),p(a2|b2),
…
p(am|b2);
[0078]
样本数据集中每一条数据样本属于每个特征类别的概率p(b1|a),p(b2|a),选取概率最大的特征类别作为该数据样本属于的特征类别,即若p(bi|a)=max{p(b1|a),p(b2|a)},则a∈bi;
[0079]
输出训练好的分类器,所述分类器用以预测出体检者未来患痛风的风险指数。
[0080]
例如,结合上述举例数据,本发明中的a为所述样本数据集中的每一条数据样本,a1为性别,a2为是否有关节炎史,a3为是否存在1天内发病,a4为是否存在关节红肿,a5为发病时最先累及的部位是否是大脚趾,a6为是否有高血压或心血管疾病,a7为血清尿酸水平是否>5.88mg/dl;bi为特征类别集合,b1为患痛风标签,b2为未患痛风标签。
[0081]
第四步,评价模块采用布里尔分数来评价所述痛风预测模型的预测结果价值。转第五步
[0082]
应当理解的是,在上述方案的基础上,需要对所述分类器输出结果的准确率进行判断,分类性能常用的评价指标为布里尔分数,这个指标衡量了分类器输出概率距离真实结果的差异,布里尔分数的范围是从0到1,分数越高则预测结果越差,校准程度越差,因此布里尔分数越接近0其准确率越高,因此通过计算所述分类器的布里尔分数来判断所述痛风预测模型的预测准确度,若所述布里尔分数超过预设分数阈值,判定当前痛风预测模型的预测准确度不符合标准,则分类器模块继续对所述分类器进行训练;若所述布里尔分数未超过预设分数阈值,判定当前痛风预测模型的预测准确度符合标准,完成痛风预测模型的构建。
[0083]
应当理解的是,在上述方案的基础上,所述计算所述分类器的布里尔分数具体包括:
[0084][0085]
其中,p(b
t
|a)为所述分类器计算的事件t的预测概率,o
t
为事件t的实际概率,n为预测事件数量;所述事件t为a∈bi,o
t
的值为0或1。
[0086]
第五步,将被检者的体检数据输入训练好的痛风预测模型,所述分类器模块输出该被检者患有痛风的概率,提示模块根据分类器模块输出的被检者预测患痛风的概率,结合被检者提供的信息数据,针对单个信息数据的危险水平给出相应的提示和建议。
[0087]
应当理解的是,在上述方案的基础上,可以根据分类器模块输出该被检者患有痛风的概率,设置等级阈值,通过比较所述概率与所述等级阈值将被检者未来可能患有痛风的风险进行分级,分为低危、中危和高危,再根据被检者的风险等级和其体检数据中各项数据的危险水平,给出针对性的提示以及预防方案,便于被检者对痛风的及时治疗和预防。
[0088]
本发明通过性别、患病史、临床表现、血清尿酸水平等因素变量建立预测规则,评估待测人群的痛风发病风险,并针对不同风险分层和单个危险因素水平给出相应提示和建议,为临床痛风的早筛提供了指导性建议。
[0089]
本发明还公开一种电子设备,所述设备包括:至少一个处理器、至少一个存储器、通信接口和总线;其中,所述处理器、存储器、通信接口通过所述总线完成相互间的通信;所述存储器存储有可被所述处理器执行的一种痛风预测模型系统功能程序,一种痛风预测模型系统功能程序配置为实现如本发明实施例所述的一种痛风预测模型系统功能程序。
[0090]
本发明还公开一种计算机可读存储介质,所述存储介质上存储有一种痛风预测模型系统功能程序,所述一种痛风预测模型系统功能程序被执行时实现如本发明实施例所述的一种痛风预测模型系统功能程序。
[0091]
以上所述仅为本发明的较佳实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1