一种化学品遗传毒性预测模型的训练方法及预测方法
1.本公开涉及化学品环境健康风险评价技术领域,更具体地涉及一种化学品遗传毒性预测模型的训练方法及预测方法。
背景技术:
2.据报道,90-95%的癌症归因于环境暴露与生活方式,而污染物遗传毒性致使遗传物质在不同水平上的损伤是诱发癌症主要因素之一。因此,为了保护人类免受此类潜在风险,评估暴露于人类的化学品的遗传毒性潜力非常重要。
3.化学品的遗传毒性具有复杂的机制,不仅包括作用方式不同的基因位点上的致突变性,而且还包括不直接作用于基因而是染色体畸变的非致突变性。目前体内动物实验被广泛应用在化学品遗传毒性的检测中,但该方法费时费财,检测效率较低。
技术实现要素:
4.鉴于上述问题,本公开提供了一种化学品遗传毒性预测模型的训练方法及预测方法。
5.根据本公开的第一个方面,提供了一种化学品遗传毒性预测模型的训练方法,包括:
6.获取关于已知遗传毒性的化学品的原始数据,其中,上述原始数据包括上述化学品的化学编码、上述化学品的差异基因表达数据和上述化学品的体外高通量测试数据;
7.根据上述原始数据生成训练样本数据集,其中,上述训练样本数据集中包括原子特征矩阵、连接关系矩阵、差异基因表达矩阵、体外高通量测试矩阵以及上述化学品的标签信息;
8.利用上述训练样本数据集训练初始模型,得到化学品遗传毒性预测模型。
9.根据本公开的实施例,上述根据上述原始数据生成训练样本数据集包括:
10.将上述化学编码转换为表示上述化学品空间结构的二维图形结构,其中,上述二维图形结构中的原子用点表示,化学键用线表示;
11.根据上述二维图形结构,确定与上述化学编码对应的原子数量、原子特征向量以及原子之间的连接关系;
12.根据上述原子数量以及上述原子特征向量构成上述原子特征矩阵;
13.根据上述原子数量和上述原子之间的连接关系构成上述连接关系矩阵。
14.根据本公开的实施例,上述原子特征向量利用长度为n的数字向量表示,其中,n为原子特征数量,50≤n≤75。
15.根据本公开的实施例,上述原子之间的连接关系包括使用数值“1”表示两个原子之间存在化学键,数值“0”表示两个原子之间不存在化学键。
16.根据本公开的实施例,上述初始模型包括化学结构输入层、差异基因表达输入层、体外高通量测试数据输入层和二维卷积神经网络层;
17.上述利用上述训练样本数据集训练初始模型,得到化学品遗传毒性预测模型包括:
18.将上述训练样本数据集中的上述原子特征矩阵、上述连接关系矩阵输入上述化学结构输入层,输出第一向量;
19.将上述训练样本数据集中上述差异基因表达矩阵输入上述差异基因表达输入层,输出第二向量;
20.将上述训练样本数据集中的上述体外高通量测试矩阵输入上述体外高通量测试数据输入层,输出第三向量;
21.将上述第一向量、上述第二向量和上述第三向量拼接,形成第四向量;
22.将上述第四向量输入上述二维卷积神经网络层,输出与上述化学品对应的遗传毒性的预测值;
23.根据上述预测值和上述化学品的标签信息优化上述初始模型,得到上述化学品遗传毒性预测模型。
24.根据本公开的实施例,上述利用上述训练样本数据集训练初始模型,得到化学品遗传毒性预测模型包括:
25.利用上述训练样本数据集和预设的m组超参数集训练上述初始模型,得到m个待验证化学品遗传毒性预测模型,其中,上述m≥1;
26.利用接收者操作特征曲线下面积对上述m个待验证化学品遗传毒性预测模型进行评价,得出m个评价值;
27.确定上述m个评价值中最大的评价值;
28.将上述最大的评价值对应的超参数集确定为上述化学品遗传毒性预测模型的最终超参数。
29.根据本公开的实施例,上述训练方法还包括:
30.在上述利用上述训练样本数据集和预设的m组超参数集训练上述初始模型之前,针对上述初始模型中的多个超参数的每个超参数,确定与上述超参数对应的z个备选值,其中,z≥1;
31.将与上述超参数对应的z个备选值分别和与其他超参数对应的z个备选值进行组合,得到m组超参数集。
32.根据本公开的实施例,上述利用上述训练样本数据集和预设的m组超参数集训练上述初始模型,得到m个待验证化学品遗传毒性预测模型包括:
33.针对m组超参数中的每组超参数,利用k折交叉验证训练上述初始模型,得到k个待验证化学品遗传毒性预测模型,其中,k≥1;
34.上述利用接收者操作特征曲线下面积对上述m个待验证化学品遗传毒性预测模型进行评价,得出m个评价值包括:
35.利用上述接收者操作特征曲线下面积对上述k个待验证化学品遗传毒性预测模型进行评价,得出k个评价初值;
36.根据上述k个评价初值,确定上述k个评价初值的评价均值,其中,上述评价均值为上述超参数对应的待验证化学品遗传毒性预测模型的评价值。
37.本公开的另一方面提供了一种化学品遗传毒性的预测方法,包括:
38.获取待预测化学品的数据,其中,上述待预测化学品的数据包括化学编码、差异基因表达和体外高通量测试数据;
39.根据上述待预测化学品的数据生成待测样本数据集,其中,上述待测样本数据集中包括原子特征矩阵、连接关系矩阵、差异基因表达矩阵和体外高通量测试矩阵;
40.将上述待测样本数据集输入化学品遗传毒性预测模型,输出预测值,其中,上述化学品遗传毒性预测模型由上述的化学品遗传毒性预测模型的训练方法训练得到;
41.对上述预测值进行分析,得出分析结果。
42.根据本公开的实施例,上述预测方法还包括:
43.在上述分析结果表明上述预测值大于或等于预设阈值的情况下,确定上述待预测化学品具有遗传毒性;
44.在上述分析结果表明上述预测值小于上述预设阈值的情况下,确定上述待预测化学品不具有遗传毒性;
45.其中,上述预设阈值的确定方法包括:
46.将由多个已知遗传毒性的化学品的样本数据生成的样本数据集输入上述化学品遗传毒性预测模型,得到与每个上述已知遗传毒性的化学品对应的样本预测值;
47.根据上述样本预测值和与上述已知遗传毒性的化学品对应的活性标签,计算真阳性率和假阳性率;
48.以假阳性率为x轴,真阳性率为y轴,得到接受者操作特性曲线;
49.确定上述接受者操作特性曲线中真阳性率相对于假阳性率变化率最大点,将上述变化率最大点对应的预测值作为上述预设阈值。
50.本公开的另一方面提供了一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序,其中,当上述一个或多个程序被上述一个或多个处理器执行时,使得一个或多个处理器执行上述训练方法或预测方法。
51.本公开的另一方面还提供了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行上述训练方法或预测方法。
52.本公开的另一方面还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述训练方法或预测方法。
53.根据本公开的实施例,本方案通过获取已知遗传毒性的化学品的化学编码、差异基因表达和体外高通量测试数据,根据上述数据生成包括原子特征矩阵、连接关系矩阵、差异基因表达矩阵、体外高通量测试矩阵以及上述化学品的标签信息的训练样本数据集;然后利用训练样本数据集训练初始模型,从而得到化学品遗传毒性预测模型。因此,本方案构建的化学品遗传毒性预测模型可以直接读取由化学品化学结构计算得到的原子特征矩阵、连接关系矩阵,通过考虑分子内原子之间的相互作用自动捕获化学品结构,无需分子指纹或描述符等人为定义的特征,节省了分子描述符计算与挑选的时间,提高了模型的准确度。同时,本公开实施例提供的化学品遗传毒性预测模型可同时捕获化学品结构特征、差异基因表达特征以及体外高通量测试的交互关系,克服化学品遗传毒性预测中单纯依赖化学结构无法准确预测筛查的难题。
54.根据本公开的实施例,其提供的化学品遗传毒性预测模型适用于大规模化学品遗传毒性的筛查,方法快速简单效率高,在化学品风险评价等领域具有广阔的应用前景。
附图说明
55.通过以下参照附图对本公开实施例的描述,本公开的上述内容以及其他目的、特征和优点将更为清楚,在附图中:
56.图1示意性示出了根据本公开实施例的化学品遗传毒性预测模型的训练方法的流程图;
57.图2示意性示出了根据本公开实施例的化学品遗传毒性预测模型的最终超参数确定方法的流程图;
58.图3示意性示出了根据本公开实施例的化学品遗传毒性的预测方法的流程图;
59.图4示意性示出了根据本公开另一实施例的化学品遗传毒性的预测方法的流程图;
60.图5示意性示出了杂化卷积神经网络模型的示意图;
61.图6示意性示出了根据本公开另一实施例的化学品差异基因表达数据与体外高通量测试数据的示意图。
具体实施方式
62.以下,将参照附图来描述本公开的实施例。但是应该理解,这些描述只是示例性的,而并非要限制本公开的范围。在下面的详细描述中,为便于解释,阐述了许多具体的细节以提供对本公开实施例的全面理解。然而,明显地,一个或多个实施例在没有这些具体细节的情况下也可以被实施。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本公开的概念。
63.在此使用的术语仅仅是为了描述具体实施例,而并非意在限制本公开。在此使用的术语“包括”、“包含”等表明了所述特征、步骤、操作和/或部件的存在,但是并不排除存在或添加一个或多个其他特征、步骤、操作或部件。
64.在此使用的所有术语(包括技术和科学术语)具有本领域技术人员通常所理解的含义,除非另外定义。应注意,这里使用的术语应解释为具有与本说明书的上下文相一致的含义,而不应以理想化或过于刻板的方式来解释。
65.在使用类似于“a、b和c等中至少一个”这样的表述的情况下,一般来说应该按照本领域技术人员通常理解该表述的含义来予以解释(例如,“具有a、b和c中至少一个的系统”应包括但不限于单独具有a、单独具有b、单独具有c、具有a和b、具有a和c、具有b和c、和/或具有a、b、c的系统等)。
66.目前,已经有很多基于化合物的分子指纹或分子描述符的定量构效关系(quantitative structure activity relationships,qsar)模型,且在化学品毒性评估上显示出出色的预测能力。这一方法的使用在一定程度上提高了化学品遗传毒性筛查的效率,成为了化学品风险评价的重要工具。但是由于遗传毒物结构的复杂性,微小化学结构变化可能带来巨大毒性改变,仅基于结构特征的模型在实际应用中表现出泛化能力较弱等问题。分子描述符或分子指纹对于化学品表示而言具有稀疏性,若仅依赖人为定义的分子描述符或分子指纹,可能造成分子结构信息的缺失,且冗余的特征也可能影响模型的预测性能。
67.随着高通量筛选技术的发展,大规模生物学数据的快速积累可为化学品的风险评
估提供更多信息。高通量生物学数据的特征变化一直被用作反映疾病潜在机制的指标,与整个生物系统的化学扰动有关。因此,尽管许多研究已使用高通量生物学数据进行毒性预测与风险评价,但大多只关注单一类型高通量数据的分析,并没有探索生物学数据与结构特征之间的协同作用与相互作用。事实上,结构特征与生物学数据具有互补作用,在毒性预测与风险评价中耦合化学结构特征与生物学数据的综合分析方法更能提供有效信息。
68.在实现本公开的过程中发现,机器学习预测模型可以用于评估化学品暴露引起的遗传毒性,虽然机器学习预测模型可以提高预测效率,但由于其仅基于化学结构或单一高通量生物学数据的预测模型,预测准确性不佳。
69.有鉴于此,本公开针对以上技术问题,提供了一种基于化学结构特征、差异基因表达特征以及体外高通量测试的化学品遗传毒性预测模型,该模型可以同时捕获化学品结构特征、差异基因表达特征以及体外高通量测试的交互关系,与其他模型相比,本公开提供的预测模型具有较为优异的预测性能。
70.具体地,本公开的实施例提供了一种化学品遗传毒性预测模型的训练方法,包括:
71.获取关于已知遗传毒性的化学品的原始数据,其中,上述原始数据包括上述化学品的化学编码、上述化学品的差异基因表达数据和上述化学品的体外高通量测试数据;根据上述原始数据生成训练样本数据集,其中,上述训练样本数据集中包括原子特征矩阵、连接关系矩阵、差异基因表达矩阵、体外高通量测试矩阵以及上述化学品的标签信息;以及利用上述训练样本数据集训练初始模型,得到化学品遗传毒性预测模型。
72.根据本公开的实施例,其基本原理可以理解为,将化学品计算得到的表示原子特征的原子特征矩阵与表示原子之间连接关系的连接关系矩阵输入化学结构输入层(化学结构输入层可以为一维图卷积层),获得表示化学结构特征的第一向量;将差异基因矩阵输入差异基因输入层(差异基因输入层可以为全连接层),得到表示差异基因表达特征的第二向量;将体外高通量测试矩阵输入体外高通量测试数据输入层(体外高通量测试数据输入层可以为全连接层),获得表示体外高通量测试特征的第三向量;之后将第一向量、第二向量和第三向量拼接后输入到二维卷积神经网络,建立其与分子遗传毒性间的数学函数关系,实现化学品遗传毒性的预测。
73.本公开首次提出基于化学结构、差异基因与体外高通量测试数据的化学品遗传毒性预测方法。在本公开之前,尚未发现在遗传毒性预测方面有将化学结构与多种生物学数据作为输入并使用杂化卷积神经网络模型的报道。
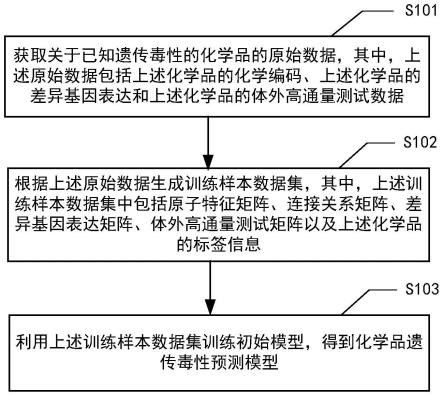
74.图1示意性示出了根据本公开实施例的化学品遗传毒性预测模型的训练方法的流程图。
75.如图1所示,该实施例的化学品遗传毒性预测模型的训练方法包括操作s101~操作s103。
76.在操作s101,获取关于已知遗传毒性的化学品的原始数据,其中,上述原始数据包括上述化学品的化学编码、上述化学品的差异基因表达数据和上述化学品的体外高通量测试数据。
77.根据本公开的实施例,化学品的原始数据例如可以包括多种化学品的原始数据。
78.根据本公开的实施例,已知遗传毒性的化学品的原始数据例如可以来自文献或公开数据库中。
79.根据本公开的实施例,化学品的化学编码可以包括化学品的smiles编码。
80.根据本公开的实施例,化学品的差异基因表达是指经化学品处理过的细胞系中上万个基因中的差异基因表达变化量。例如在本公开的另一实施例中,如图6所示,仅保留了化学品在人肝细胞癌(hepg2)细胞系中与遗传毒性相关的295个标志基因的表达变化量,并以z分数表示。
81.根据本公开的实施例,化学品的体外高通量测试数据是指化学品在toxcast项目与tox21项目中上千个生物测试终点中的活性值或响应数据。例如在本公开的另一实施例中,如图6所示,我们仅保留了化学品在与遗传毒性相关的434个生物测试终点的响应数据响应数据以二元变量表示,其中“1”表示化学品在该生物测试终点中响应,“0”表示化学品在该生物测试终点中不响应。
82.在操作s102,根据上述原始数据生成训练样本数据集,其中,上述训练样本数据集中包括原子特征矩阵、连接关系矩阵、差异基因表达矩阵、体外高通量测试矩阵以及上述化学品的标签信息。
83.根据本公开的实施例,原子特征矩阵例如可以包括对化学品的m个原子的n个特征向量构成的m
×
n的数字矩阵。
84.根据本公开的实施例,原子特征向量利用长度为n的数字向量表示,其中,50≤n≤75。原子特征表示的是原子类型、杂化程度等化学与拓扑性质。
85.根据本公开的实施例,连接关系矩阵例如可以包括化学品的m个原子之间的连接关系构成的m
×
m的数字矩阵。
86.根据本公开的实施例,连接关系矩阵中原子之间的连接关系包括使用数值“1”表示两个原子之间存在化学键,数值“0”表示两个原子之间不存在化学键。连接关系矩阵对角线上的值均为“1”,表示每个原子都与自己相连,形成闭环。
87.根据本公开的实施例,化学品的标签信息例如可以包括化学品的遗传毒性类别,其中,遗传毒性类别以二元类别表示,“1”表示具有遗传毒性,“0”表示不具有遗传毒性。
88.在操作s103,利用上述训练样本数据集训练初始模型,得到化学品遗传毒性预测模型。
89.根据本公开的实施例,本方案通过获取已知遗传毒性的化学品的化学编码、差异基因表达数据和体外高通量测试数据,根据上述数据生成训练样本数据集,训练样本数据集中包括原子特征矩阵、连接关系矩阵、差异基因表达矩阵、体外高通量测试矩阵以及上述化学品的标签信息;然后利用训练样本数据集训练初始模型,从而得到化学品遗传毒性预测模型。因此,本方案构建的化学品遗传毒性预测模型可以直接读取由化学品化学结构计算得到的原子特征矩阵、连接关系矩阵,通过考虑分子内原子之间的相互作用自动捕获化学品结构,无需分子指纹或描述符等人为定义的特征,节省了分子描述符计算与挑选的时间,提高了模型的准确度。同时,本公开实施例提供的化学品遗传毒性预测模型可同时捕获化学品结构特征、差异基因表达特征以及体外高通量测试的交互关系,克服化学品遗传毒性预测中单纯依赖化学结构无法准确预测筛查的难题。
90.根据本公开的实施例,上述根据上述原始数据生成训练样本数据集包括:将上述化学编码转换为表示上述化学品空间结构的二维图形结构,其中,上述二维图形结构中的原子用点表示,化学键用线表示;根据上述二维图形结构,确定与上述化学编码对应的原子
roc值相对应的超参数作为化学品遗传毒性预测模型的最终超参数。
100.根据本公开的实施例,每组超参数包括lr,dropout,λ,batchsize,其中,lr为学习率,dropout为dropout系数,λ为l2权重衰减正则化项参数,batchsize为批大小,其中,dropout是指在深度网络的训练中,以一定的概率随机地“临时丢弃”一部分神经元节点。
101.根据本公开的实施例,上述训练方法还包括:在上述利用上述训练样本数据集和预设的m组超参数集训练上述初始模型之前,针对上述初始模型中的多个超参数的每个超参数,确定与上述超参数对应的z个备选值,其中,z≥1;将与上述超参数对应的z个备选值分别和与其他超参数对应的z个备选值进行组合,得到m组超参数集。
102.根据本公开的实施例,对超参数lr,dropout,λ,batchsize中的每个超参数设置多个备选值,并使用各个超参数不同备选值进行组合,得到多组超参数集。
103.图2示意性示出了根据本公开实施例的化学品遗传毒性预测模型的最终超参数确定方法的流程图。
104.如图2所述,该方法包括操作s201~操作s206。
105.在操作s201,针对初始模型中的多个超参数集中的每个超参数,确定与上述超参数对应的z个备选值,其中,z≥1。
106.在操作s202,将与超参数对应的z个备选值分别和与其他超参数对应的z个备选值进行组合,得到m组超参数集。
107.在操作s203,利用训练样本数据集和m组超参数集训练初始模型,得到m个待验证化学品遗传毒性预测模型,其中,m≥1。
108.在操作s204,利用接收者操作特征曲线下面积对m个待验证化学品遗传毒性预测模型进行评价,得出m个评价值。
109.在操作s205,确定m个评价值中最大的评价值。
110.在操作s206,将最大的评价值对应的超参数集确定为化学品遗传毒性预测模型的最终超参数。
111.根据本公开的实施例,上述利用上述训练样本数据集和预设的m组超参数集训练上述初始模型,得到m个待验证化学品遗传毒性预测模型包括:针对m组超参数集中的每组超参数,利用k折交叉验证训练上述初始模型,得到k个待验证化学品遗传毒性预测模型,其中,k≥1;上述利用接收者操作特征曲线下面积对上述m个待验证化学品遗传毒性预测模型进行评价,得出m个评价值包括:利用上述接收者操作特征曲线下面积对上述k个待验证化学品遗传毒性预测模型进行评价,得出k个评价初值;根据上述k个评价初值,确定上述k个评价初值的评价均值,其中,上述评价均值为上述超参数对应的待验证化学品遗传毒性预测模型的评价值。
112.根据本公开的实施例,例如利用五折交叉验证训练上述初始模型,包括:针对m组超参数集中的每组超参数,将训练样本数据集随机均分为五份,依次取其中一份数据作为验证集,其余四份数据作为训练集,用于训练初始模型,最终对于每组超参数均得到5个待验证化学品遗传毒性预测模型;利用上述接收者操作特征曲线下面积对上述5个待验证化学品遗传毒性预测模型进行评价,得出5个评价初值;根据上述5个评价初值,确定上述5个评价初值的评价均值,其中,上述评价均值为超参数对应的待验证化学品遗传毒性预测模型的评价值,从而确定其中一组超参数对应的评价值;重复上述操作,直至确定与m组超参
数集对应的m个评价值;确定m个评价值中最大的评价值;将最大的评价值对应的超参数集确定为化学品遗传毒性预测模型的最终超参数。
113.根据本公开的实施例,利用上述接收者操作特征曲线下面积对上述5个待验证化学品遗传毒性预测模型进行评价,得出5个评价初值的方法包括:将验证集输入待验证化学品遗传毒性预测模型后输出预测值和该化学品的遗传毒性标签(1或0),计算真阳性(true positive,tp)、真阴性(true negative,tn)、假阳性(false positive,fp)、假阴性(false negative,fn)、真阳性率和假阳性率,制作受试者操作特性曲线并计算auc-roc值,将auc-roc值作为评价初值。
114.其中,
115.tpr=tp/(tp+fn);
116.fpr=fp/(fp+tn);
117.tp:表示验证集中预测为遗传毒物,实际也为遗传毒物的样本个数;
118.fp:表示验证集中预测为遗传毒物,实际为非遗传毒物的样本个数;
119.fn:表示验证集中预测为非遗传毒物,实际为遗传毒物的样本个数;
120.tn:表示验证集中预测为非遗传毒物,实际也为非遗传毒物的样本个数。
121.图3示意性示出了根据本公开实施例的化学品遗传毒性的预测方法的流程图。
122.如图3所示,该方法包括操作s301~s304。
123.在操作s301,获取待预测化学品的数据,其中,上述待预测化学品的数据包括化学编码、差异基因表达数据和体外高通量测试数据。
124.在操作s302,根据上述待预测化学品的数据生成待测样本数据集,其中,上述待测样本数据集中包括原子特征矩阵、连接关系矩阵、差异基因表达矩阵和体外高通量测试矩阵。
125.在操作s303,将上述待测样本数据集输入化学品遗传毒性预测模型,输出预测值,其中,上述化学品遗传毒性预测模型由上述的化学品遗传毒性预测模型的训练方法训练得到。
126.在操作s304,对上述预测值进行分析,得出分析结果。
127.根据本公开的实施例,上述预测方法还包括:在上述分析结果表明上述预测值大于或等于预设阈值的情况下,确定上述待预测化学品具有遗传毒性;在上述分析结果表明上述预测值小于上述预设阈值的情况下,确定上述待预测化学品不具有遗传毒性;其中,上述预设阈值的确定方法包括:将由多个已知遗传毒性的化学品的样本数据生成的样本数据集输入上述化学品遗传毒性预测模型,得到与每个上述已知遗传毒性的化学品对应的样本预测值;根据上述样本预测值和与上述已知遗传毒性的化学品对应的活性标签,计算真阳性率和假阳性率;以假阳性率为x轴,真阳性率为y轴,得到接受者操作特性曲线;确定上述接受者操作特性曲线中真阳性率相对于假阳性率变化率最大点,将上述变化率最大点对应的预测值作为上述预设阈值。
128.根据本公开的实施例,根据上述样本预测值和与上述已知遗传毒性的化学品对应的活性标签,计算真阳性率和假阳性率包括:将样本预测值从大到小排序,根据每个已知化学品预测值和该化学品对应的毒性标签(1表示具有遗传毒性,0表示不具有遗传毒性),计算真阳性率和假阳性率。
129.图4示意性示出了根据本公开另一实施例的化学品遗传毒性的预测方法的流程图。
130.如图4所示,该方法包括操作s401~s412。
131.在操作s401,获取已知遗传毒性的化学品的原始数据,其中,原始数据包括化学品的化学编码、化学品的差异基因表达和化学品的体外高通量测试数据。
132.在操作s402,根据原始数据生成训练样本数据集,其中,训练样本数据集中包括原子特征矩阵、连接关系矩阵、差异基因表达矩阵、体外高通量测试矩阵以及化学品的标签信息。
133.在操作s403,将训练样本数据集划分为训练集和测试集。
134.在操作s404,采用五折交叉法利用训练集对初始模型进行训练,得到待验证化学品遗传毒性预测模型。
135.在操作s405,利用测试集对待验证化学品遗传毒性预测模型进行验证,得到化学品遗传毒性预测模型。
136.在操作s406,获取待预测化学品的数据,其中,待预测化学品的数据包括化学编码、差异基因表达数据和体外高通量测试数据。
137.在操作s407,根据待预测化学品的数据生成待测样本数据集,其中,待测样本数据集中包括原子特征矩阵、连接关系矩阵、差异基因表达矩阵和体外高通量测试矩阵。
138.在操作s408,将待测样本数据集输入上述化学品遗传毒性预测模型中。
139.在操作s409,对待测样本数据进行计算,确定预测值。
140.在操作s410,判断预测值是否大于或等于预设阈值。在预测值大于或等于预设阈值的情况下,执行操作s411;在预测值小于预设阈值的情况下,执行操作s412。
141.在操作s411,输出待预测化学品具有遗传毒性的预测结果。
142.在操作s412,输出待预测化学品不具有遗传毒性的预测结果。
143.根据本公开的实施例,该化学品遗传毒性预测模型可以直接读取由化学品化学结构计算得到的分子特征,通过考虑分子内原子之间的相互作用自动捕获化学品结构;并且同时捕获化学品结构特征、差异基因表达特征以及体外高通量测试的交互关系,克服化学品遗传毒性预测中单纯依赖化学结构无法准确预测筛查的难题。此外,本公开的预测模型适用于大规模化学品遗传毒性的筛查,方法快速简单效率高,在化学品风险评价等领域具有广阔的应用前景。
144.以下通过具体实施例对本公开的技术方案做进一步阐述说明。
145.实施例
146.(1)化学品数据的获取和预处理
147.下载crcgn数据集中具有遗传毒性二元标签的261个化学品的原始数据,原始数据包含化合物结构与其在人肝细胞癌细胞系中的差异基因表达数据,并获取与已获得的261个化学品匹配的体外高通量测试数据,最终得到了244个化学品及其smiles编码、差异基因表达数据与体外高通量测试数据,其中具有遗传毒性的化学品有92个,不具有遗传毒性的有152个。
148.(2)化学结构转换为原子特征矩阵与连接关系矩阵
149.将化学品结构计算得到的表示原子特征的原子特征矩阵与表示原子之间连接关
系的连接关系矩阵,其中,原子特征向量的长度n设置为75。
150.(3)杂化卷积神经网络模型的训练和超参数确定
151.将化学品的原始数据按照4:1的比例随机分为训练集和测试集,训练集用于杂化卷积神经网络模型的超参数确定和模型建立,测试集用于模型预测能力评估。
152.图5示意性示出了杂化卷积神经网络模型的示意图。
153.如图5所示,杂化卷积神经网络模型包括化学结构输入层、差异基因表达数据输入层、体外高通量测试数据输入层。
154.化学结构输入层之后连接三层一维的图卷积层,每层图卷积层后使用线性整流函数(relu)作为激活函数将神经网络中的线性特征转换为非线性特征,并进行批标准化使每一层神经网络的输入保持相同分布,随后使用使用dropout防止过拟合;第i层图卷积层包含uniti个节点,其中uniti为[256,256,256],卷积步长为stridej,其中stridej为[1,1,1];之后连接最大池化层,得到表示化学品结构特征的数字向量u。
[0155]
差异基因表达数据与体外高通量测试数据输入层之后连接一个节点数为256的全连接层,随后使用双切正曲函数(tanh)作为激活函数,并在使用dropout之后,以节点数为100、激活函数为线性整流函数(relu)的全连接层输出表示差异基因表达特征的数字向量q和表示体外高通量测试特征的数字向量p。
[0156]
将上述向量u、向量q和向量p经过拼接后,输入到二维的卷积神经网络,输出与化学品对应的遗传毒性的预测值。
[0157]
卷积神经网络分为8层,卷积神经网络的第一层为二维卷积层,包含30个卷积核,其尺寸为1
×
150,卷积步长为1,并使用relu函数作为激活函数;随后紧接二维最大池化层的第一层,池化核的尺寸为1
×
2。
[0158]
卷积神经网络的第二层、第三层与第一层相似,但略有不同,第二层、第三层卷积核的数目分别为10和5,尺寸均为1
×
5。二维最大池化层的第二层、第三层同样与第一层相似,位置在相应卷积层后,只是池化核的尺寸为1
×
3,最后的二维最大池化层后接dropout防止过拟合。
[0159]
全连接层中第l层全连接层包含unit
l
个节点,其中unit
l
为[300,100],激活函数分别为双切正曲函数(tanh)和sigmoid函数,分别作为二维卷积神经网络的输入与输出,其中,输出层输出化学品遗传毒性的预测值s,其范围在0~1之间。
[0160]
为防止模型过度拟合,在二维卷积层的每层中加入了l2权重衰减正则化项,参数设定为λ。
[0161]
训练时应用自适应矩估计优化器(adam)方法作为训练器,学习率设定为lr,每次训练进行100次迭代,并保存每一次迭代的模型参数。
[0162]
在训练集中,使用网格筛选法获取最优超参数时,学习率lr的备选值为[0.01,0.001,0.0001],批大小batchsize的备选值为[16,32,64],dropout系数dropout的备选值为[0,0.1,0.2],l2权重衰减正则化项参数λ的备选值为[0,0.001,0.0001]。每种参数组合在训练时计算auc-roc,并基于五折交叉验证中的最大auc-roc均值确定最优参数,最终最优参数选定学习率lr为0.0001、批大小batchsize为16、dropout系数dropout为0.1、l2权重衰减正则化项参数λ为0.0001。
[0163]
(4)最优杂化卷积神经模型预设阈值的确定
[0164]
基于步骤(3)所述方法得到的最终超参数,在训练集中训练得到最优杂化卷积神经预测模型,并对测试集进行预测,获得测试集中化学品的预测活性值,根据预测活性值结合其真实的遗传毒性标签绘制接受者操作特性曲线(roc曲线)。roc曲线中tpr相对于fpr变化率最大点t对应的预测值作为判定遗传毒性的预设阈值s
t
,该实施例预设阈值s
t
为0.740。
[0165]
(5)与其他现有机器学习模型的预测性能比较
[0166]
为了更好体现本实施例所述的杂化卷积神经网络模型在遗传毒性预测方法的优异性能,将本实施例的预测模型与基于pubchem分子指纹的支持向量机、基于maccs分子指纹的随机森林的同类机器学习模型的性能进行比较。在测试集的预测结果中计算真阳性(true positive,tp)、真阴性(true negative,tn)、假阳性(false positive,fp)、假阴性(false negative,fn)、真阳性率(true positive rate,tpr)、精确度(precision)、f1分数(f1-score)、马修斯系数(matthews correlation coefficient,mcc)和auc-roc综合评估模型的预测能力。
[0167]
其中,
[0168]
tpr=tp/(tp+fn)
[0169]
precision=tp/(tp+fp)
[0170]
f1 score=2*(precision*tpr)/(precision+tpr)
[0171][0172]
在相同数据集中建立机器学习模型,各模型的预测性能评价指标如表1所示。
[0173]
表1
[0174][0175]
如表1所示,本实施例提供的预测模型的auc-roc、f1-score和mcc分别为0.889、0.811和0.697,这表明本公开实施例所提出的杂化卷积神经网络模型在遗传毒性中具有优异的预测性能。本公开实施例提供的方法在测试集上的auc-roc、f1-score和mcc均远高于其他两个同类方法,这表明本公开实施例提供方法相较于其他两个同类方法对于遗传毒物与非遗传毒物有更强的区分能力,且具有更好的泛化能力。同时,本公开实施例提供的方法相较于其他两个同类方法引入了化学品的差异基因表达数据与体外高通量测试数据,表明在遗传毒性的预测中化学品化学结构、差异基因与体外高通量测试数据之间存在互补关系,耦合化学结构与多种生物学数据的预测方法具有更好的性能。总之,本公开实施例提供的预测模型具有优越的化学品遗传毒性的预测能力。
[0176]
综上所述,本公开实施例建立的基于杂化卷积神经网络的化学品遗传毒性预测筛查模型,捕获了化学品结构特征、差异基因表达特征以及体外高通量测试的交互关系,能更为精确的预测化学品的遗传毒性。
[0177]
本领域技术人员可以理解,本公开的各个实施例和/或权利要求中记载的特征可以进行多种组合或/或结合,即使这样的组合或结合没有明确记载于本公开中。特别地,在不脱离本公开精神和教导的情况下,本公开的各个实施例和/或权利要求中记载的特征可以进行多种组合和/或结合。所有这些组合和/或结合均落入本公开的范围。
[0178]
以上对本公开的实施例进行了描述。但是,这些实施例仅仅是为了说明的目的,而并非为了限制本公开的范围。尽管在以上分别描述了各实施例,但是这并不意味着各个实施例中的措施不能有利地结合使用。本公开的范围由所附权利要求及其等同物限定。不脱离本公开的范围,本领域技术人员可以做出多种替代和修改,这些替代和修改都应落在本公开的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1