基于人工智能的婴幼儿铁微量元素风险预测方法和系统
1.本发明涉及婴幼儿铁微量元素风险预测方法,尤其涉及基于人工智能的婴幼儿铁微量元素风险预测方法和系统,属于人工智能医疗领域。
背景技术:
2.既往对早产儿的补铁研究大多为随机对照临床试验(randomizedcontrolledtrial,rct)、前瞻性或病例对照研究,研究对象往往临床表现典型且同质性高,并对干预措施和时间一致化要求。一定程度上揭示了预防性补铁对改善早产儿不良结局的影响,但研究维度和覆盖人群有限,缺乏长期有效的随访追踪,对结局指标的观察时效短,在真实世界中难以做到有效推广。
3.铁缺乏和铁超载均可通过细胞调控,造成全身器官不可逆的损伤,如何精细化管理铁稳态是早产儿保健的核心之一。基于上述研究可以推断,精准化、个体化的早产儿预防性补铁方案,既可以减少ida和id的发病率,避免补铁不足造成的神经发育迟缓及体格生长落后,也可避免铁超载所导致的过氧化损伤以及成年期神经退行性变的风险。
4.虽然国内外已有相关的补铁建议标准,但针对不同胎龄、出生体重、喂养方式、追赶生长模式下的适宜补铁推荐,尚缺乏相应的循证医学证据支持及更加精细化的补铁建议标准,从而对早产儿保健和追赶发育带来巨大挑战。
技术实现要素:
5.基于上述现有方案面临的问题,本发明着重考虑如下几个方面,第一,运用rws基于早产儿真实世界数据进行研究,为rws研究方法的在儿科临床领域提供尝试性的探索,通过挖掘数据的潜在价值,研究早产儿的铁营养的真实状态,寻找个性化治疗最优方案,为有效推广个体化预防性补铁方案提供依据;第二研究不同孕周、出生体重、出生方式及喂养方式的早产儿采用间歇性补铁和持续补铁、不同补铁时长、不同补铁剂量组别之间的id、ida、铁超载的发生率差异以及铁代谢生物学指标的差异,并建立人工智能预测模型;第三具备家庭-社区-医院的跨场景特性和精准可视化特性的早产儿铁营养精细化管理app。
6.基于上述考虑,本发明一方面提供基于人工智能的婴幼儿铁微量元素风险预测方法,其特征在于包括如下步骤:
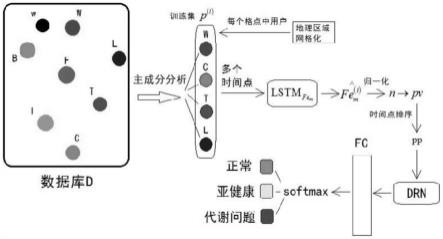
7.s1建立铁微量元素摄入与全程成长(5-6岁之前)健康的婴幼儿样本数据库d;
8.s2基于所述数据库d建立婴幼儿铁微量元素风险预测模型p;
9.s3建立区域性的婴幼儿铁微量元素风险预测互联网络n;
10.s4利用互联网络n实时对婴幼儿铁微量元素摄入量进行预测。
11.其中,s1具体包括:
12.将婴幼儿按照出生时不同孕周w、出生体重w、出生方式b、喂养方式f、采用间歇性补铁i和持续补铁c、不同补铁时长t、不同补铁剂量l进行数据记录,以及每一个婴幼儿id、ida、铁超载情况、以及铁代谢生物学指标,形成婴幼儿样本数据库d;
13.s2具体包括
14.s2-1将数据库d中的所述数据记录与id、ida、铁超载的发生率以及铁代谢生物学指标之间进行主成分分析,寻找出影响id、ida、铁超载的发生率以及铁代谢生物学指标的主要的影响因素pi,i=1,2,
…
,m,m为主成分个数且m<8;
15.s2-2按照主成分的方差贡献率从大至小排序,建立预测矢量其中元素为m个主成分指标,p1到pm方差贡献率逐步减小,以及p对应的检测指标矢量以p为输入层,以id、ida、铁超载的发生率fe
ol
以及铁代谢生物学指标fem中任一项或其组合,即pi中的元素作为输出端利用lstm模型建立婴幼儿铁微量元素风险预测模型p;
16.应当强调的是,采用按方差贡献率顺序排列的p的元素,即将p看作一种考虑导致id、ida、铁超载的发生率以及铁代谢生物学指标异常的因素的重要性顺序,相当于一种时序预测,目的是尽快保证先预测出重要的影响因素的预测结果指导补铁方案,以尽快逼近正确的补铁方案,大幅减少异常发生概率,而并非考虑以补铁时间节点为网络隐藏层的序列,从而加大了样本的时间节点划分带来和计算的复杂性。
17.当以id、ida、fe
ol
以及fem的组合作为输出端时即在模型中具有多个分支模型,形成模型集的子集lstm(
j)
,j∈[1,4]其中j表示子集中元素的个数,id、ida、fe
ol
以及fem中未选择作为输出端的,指标矢量pi中相应的元素为零。
[0018]
可以理解的是,当选择id、ida、fe
ol
以及fem全部时风险预测模型p=lstm。
[0019]
其中s2-2具体包括:
[0020]
s2-2-1将p和对应pi划分为训练集、验证集、预测集,三者比例为5-1:1:1-5;并且三者均划分为健康、亚健康、异常三类数据,
[0021]
s2-2-2在训练集中,选择健康一类以及随机选取两种方案,都以零向量为初始隐藏层输入端激活网络,以零元素作为初始隐藏单元输入数据,分别按照p的元素序列输入到输入层各单元,从而在输出层单元预测出各对应的下一个元素的概率,即中间预测值,而在最终隐藏层单元输出id、ida、铁超载的发生率以及铁代谢生物学指标中任一项预测概率进行训练;
[0022]
可以理解的是,由于中间预测值的存在,对于健康一类训练得到的模型可以帮助预测到当前输入p中任意一个元素的下一个元素走向健康方向的预测值,从而指导当下进行补铁的方案。
[0023]
s2-2-3从第二输出端单元开始到最终输出层单元得到的多个中间预测值建立损失函数l,利用验证集验证准确率,利用损失函数l进行反向传播优化网络,不断训练过程中当准确率大于第一预设值并且损失函数趋于稳定时停止训练,得到风险预测模型p。
[0024]
优选地,计算损失函数l时,对于选择pi中任一元素作为预测对象时,将其他元素
作为零元素,得到p
i0
,所述损失函数l为多个根据中间预测值得到的中间损失函数的加和,即其中
[0025][0026]
log为自然常数e为底的对数。
[0027]
而对于随机选取的方案,尤其不明确数据是否来自于健康一类,因此预测到的结果采纳的是检测指标矢量pi中元素的预测值,需要识别该预测值的分类(例如利用s2-2-3-1-s2-2-3-3的训练步骤获得深度残差网络分类模型),从而知道当下的补铁方案是否会导致id、ida、铁超载的发生或者表明铁代谢生物学指标异常,其中,当选择铁代谢生物学指标fem作为最终预测的输出端时,s2-2-3之后还包括:
[0028]
s2-2-3-1将所在预测地理区域划分为网格,数据库d中随机获取每个格点中的训练集每一个样本在定期不同时间点上的按4-1:1:1-4比例归入训练集、验证集和预测集中;利用训练集得到的风险预测模型p预测出i为时间点序号,t为选择一种标准建议的最长补铁时间对应的时间节点序号,或者当主成分中有补铁时长t时即为补铁时长t对应的时间节点序号,此时补铁时长t时长数值选择大于相邻时间点之间的时间;
[0029]
s2-2-3-2将进行归一化,并建立归一化的数值n与像素值pv之间的映射关系n
→
pv,按照时间点顺序排序形成预测图像pp;
[0030]
s2-2-3-3将预测图像pp作为输入端,以深度残差网络(drn)作为fem分类模型,输出端连接全连接层fc再输入softmax函数中得到fem分类结果进行训练,利用验证集验证准确率,以交叉熵函数作为损失函数l
loss
进行反向传播优化drn网络参数,直到准确率大于第二预设值且l
loss
趋于稳定之后停止训练得到lstm-drn联合模型。即此时婴幼儿铁微量元素风险预测模型p=lstm-drn。
[0031]
可以理解的是,无论是否按照健康一类训练得到的模型所预测的方案进行补铁(一般都会采用所述预测的方案进行补铁),如果铁代谢有问题,会有一定概率在指标上产生异常,或者由于代谢问题,即便按照所述预测的方案补铁也会有一定概率产生其他id、ida、铁超载问题,而贴代谢指标本身属于一个时间的函数,因此采样不同时间点上的预测样本就有了铁代谢的预测指导意义。我们选择深度残差网络也是为了提高网络的预测准确率。
[0032]
步骤s3具体包括:
[0033]
s3-1将风险预测所在的地理区域进行网格化划分(与s2-2-3-1将所在预测地理区域划分的网格可以相同或不同),对于每个网格中都设立子服务器s,并设立总服务器sv,
[0034]
所述总服务器sv用于收集子服务器s中记录的不同孕周w、出生体重w、出生方式b、喂养方式f、采用间歇性补铁i和持续补铁c、不同补铁时长t、不同补铁剂量l数据记录,并建立数据库d以及风险预测模型p,并将预测结果发送给子服务器s;
[0035]
s3-2设置用户终端app用于将所述数据记录和/或p(i)进行上传给所在网格的子服务器,子服务器再发送给总服务器sv,由总服务器sv对数据库d和模型p分别进行扩展更新和不断优化调整,并将预测结果回传给用户所在网格的子服务器,app获得所在网格的子服务器发送的预测结果。
[0036]
步骤s4包括:
[0037]
s4-1用户将当前预测矢量p
(t')
的元素依次输入经训练集健康类数据训练得到的模型p的输入层中,以获取用户所在网格的子服务器发送经由总服务器sv返回的预测矢量个中间预测值以及检测指标矢量中至少一个元素的预测值;
[0038]
s4-2当需要预测fem时,用户获得在当前预测矢量p
(t')
之前每隔一段时间的时间点上的预测矢量p
(j)
,j∈[1,t'),将p
(t')
和p
(j)
输入lstm-drn中得到lstm预测的归一化后按照时间点顺序排序形成预测图像pp
(t')
发送给用户所在网格的子服务器;
[0039]
s4-3用户所在网格的子服务器将预测图像pp
(t')
发送给总服务器sv,由总服务器sv输入lstm-drn中的drn输入端,输出端经过全连接层fc再输入softmax函数中得到fem分类结果,回传后,由用户所在网格的子服务器将预测结果发送给app。
[0040]
本发明另一方面提供了基于人工智能的婴幼儿铁微量元素风险预测系统,其特征在于,包括子服务器s,总服务器sv,用户终端app;其中,所述总服务器sv用于收集子服务器s中记录的不同孕周w、出生体重w、出生方式b、喂养方式f、采用间歇性补铁i和持续补铁c、不同补铁时长t、不同补铁剂量l数据记录,并建立数据库d以及风险预测模型p,并将预测结果发送给子服务器s;
[0041]
用户终端app用于将所述数据记录和/或p(i)进行上传给所在网格的子服务器,子服务器再发送给总服务器sv,由总服务器sv对数据库d和模型p分别进行扩展更新和不断优化调整,并将预测结果回传给用户所在网格的子服务器,app获得所在网格的子服务器发送的预测结果。
[0042]
有益效果
[0043]
1.利用现实世界真实样本为人工智能建模样本,研究了多影响因素下的id、ida、铁超载、和铁代谢准确预测问题,
[0044]
2.将传统的时序lstm模型转化为按照多影响因素的主成分贡献率的排序规则依次预测,采用健康训练集训练模型,依次预测出建议的补贴方案中的各影响因素的值,快速有效地对应优化补铁提供了指导,
[0045]
3.采用随机训练集采样训练模型,实现了id、ida、铁超载、和铁代谢指标的预测,并且对于诸多指标铁代谢问题,采用时序采样将预测结果图像化,并利用drn提高铁代谢分类预测准确性。
附图说明
[0046]
图1本发明的联合模型建立流程图;
[0047]
图2为本发明图1中地理区域划分和drn建模流程图;
[0048]
图3为本发明图1和2中模型具体网络结构示意图;
[0049]
图4本发明城市a区域划分以及建立区域性的婴幼儿铁微量元素风险预测互联网络n的架构示意图;
[0050]
图5用户手机上app界面示意图,其中a为ida分布界面,b为铁代谢检测结果界面。
具体实施方式
[0051]
实施例1数据库建立与建模
[0052]
以铁代谢为例,选择城市a作为预测地理区域,如图1所示,收集城市a历年婴幼儿出生时不同孕周w、出生体重w、出生方式b、喂养方式f、采用间歇性补铁i和持续补铁c、不同补铁时长t、不同补铁剂量l数据,以及每一个婴幼儿对应的id、ida、铁超载情况、以及铁代谢生物学指标,建立样本数据库d。
[0053]
通过主成分分析,得到w、c、t、l方差贡献率依次减小的四个主成分。对数据集d中的数据按照w、c、t、l排序形成建立预测矢量以及p对应的检测指标矢量如图2将p和对应pi划分为训练集、验证集、预测集,三者比例为3:1:1;并且三者均划分为健康、亚健康、异常三类数据,
[0054]
在训练集中,选择健康一类以及随机选取两种方案,如图3所示都以零向量为初始隐藏层输入端激活网络,以零元素作为初始隐藏单元输入数据,分别按照p的元素序列输入到输入层各单元,从而在输出层单元预测出各对应的下一个元素的概率,即中间预测值,而在最终隐藏层单元输出铁代谢生物学指标预测概率进行训练;
[0055]
从第二输出端单元开始到最终输出层单元得到的多个中间预测值建立损失函数l,利用验证集验证准确率,利用损失函数l进行反向传播优化网络,不断训练过程中当准确率大于第一预设值(大于85%)并且损失函数趋于稳定时停止训练,得到如图1和2中的风险预测模型
[0056]
如图3,计算损失函数l时,对于选择铁代谢情况的p
i0
,所述损失函数l为多个根据中间预测值得到的中间损失函数的加和,即其中其中
[0057]
将城市a按照图2的划分为多个网格组成网格,其中示出了12个格点,并且包括格点g3和其他所有格点中的多个用户在不同天数下测得的按照3:1:1归入训练集、验证集、预测集,如图1所示,将地理区域如图2网格化后每个格点中用户对应的训练集中每一个样本的多个时间点代入训练好的中得到预测值进行归一化,并建立归一化的数值n与像素值pv之间的映射关系n
→
pv,按照从右往左天数增加,从上往下周数增加的排序形成训练集中每个样本的预测图像pp(如图2所示)。
[0058]
将预测图像pp作为输入端,以深度残差网络(drn)作为fem正常、亚健康、代谢问题的分类模型,输出端连接全连接层fc再输入softmax函数中得到fem分类结果进行训练,利用验证集验证准确率,以交叉熵函数作为损失函数l
loss
进行反向传播优化drn参数,直到准确率大于第二预设值(90%)且l
loss
趋于稳定之后停止训练得到lstm-drn联合模型。
[0059]
实施例2风险预测互联网络n的建立
[0060]
如图4所示,将风险预测所在的地理区域城市a进行网格化划分,对于每个网格中都设立子服务器s,并设立总服务器sv,所述总服务器sv用于收集子服务器s中记录的不同孕周w、出生体重w、出生方式b、喂养方式f、采用间歇性补铁i和持续补铁c、不同补铁时长t、不同补铁剂量l数据记录,并建立数据库d以及风险预测模型p,并将预测结果发送给子服务器s;设置用户终端app用于将所述数据记录和/或p(i)进行上传给所在网格的子服务器,子服务器再发送给总服务器sv,由总服务器sv对数据库d和模型p分别进行扩展更新和不断优化调整,并将预测结果回传给用户所在网格的子服务器,app获得所在网格的子服务器发送的预测结果。
[0061]
实施例3预测与补铁建议
[0062]
本实施例按照实施例1的方法额外还建立了可以预测pi中ida预测的模型,具体预测包括如下步骤:
[0063]
s4-1如图5a所示,使用的app界面,位于格点g8用户a用手机点击数据按钮,将当前预测矢量p
(t')
的元素依次输入经训练集健康类数据训练得到的模型p的输入层中,以获取用户所在格点g8的子服务器发送经由总服务器sv而返回的ida预测值。在手机上点击查看按钮能够查看自己所在的g8的位置(即图中圆圈中圈出的点),以及g8中的ida分布和显示的所在位置对应的ida预测的状态为绿色的健康状态;
[0064]
s4-2预测fem时,用户a可以点击自己ida分布位置,并且点击数据,找到到其在建立的当前预测矢量p
(t')
之前每隔一段时间的时间点上的预测矢量p
(j)
,j∈[1,t'),并将p
(t')
和p
(j)
导入lstm-drn中app得到lstm预测的并归一化后按照时间点顺序排序形成预测图像pp
(t')
,用户可以点击查看按钮查看形成预测图像pp
(t')
并保存在手机中,发送给用户所在格点g8的子服务器;
[0065]
s4-3用户所在格点g8子服务器将预测图像pp
(t')
发送给总服务器sv,由总服务器
sv输入lstm-drn中的drn输入端,输出端经过全连接层fc再输入softmax函数中得到fem分类结果(如图5b所示),回传后,由用户所在格点g8子服务器将预测结果发送给app。其中显示了检测者的姓名、年龄、性别、检测结果以及按照健康训练集训练的模型得到的预测补铁模式、补铁时长32天以及补贴计量的建议。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1