一种与早发型重度子痫前期发生相关的靶标基因组合及其应用的制作方法
1.本发明属于生物技术领域,涉及与早发型重度子痫前期发生相关的靶标基因组合及其应用。
背景技术:
2.重度子痫前期(severe pre-eclampsia)是一种多因素的、累积多系统的产科并发症,会导致孕妇和胎儿病死率增高,其中以发生在24至34周之间的早发型重度子痫前期(early onset severe pre-eclampsia)尤为严重,目前唯一的治愈方法是终止妊娠。早发型重度子痫患者发病早、进展迅速、靶器官损害出现早且症状重,需进行必要的治疗、待胎儿成熟后再终止妊娠。对孕期状态进行预测,及早发现重度子痫前期高危人群并干预,如补钙和小剂量阿司匹林等,不仅可以减缓疾病进展,还可降低胎儿发生宫内生长受限的机率,显著降低母子不良妊娠结局。
3.当前,早发型重症子痫前期的风险评估多基于流行病史、平均动脉压(map)以及胎盘相关的分子标志物等。流行病学相关危险因素(主要包括早发型重症子痫前期病史、初产及年龄大于40岁和/或妊娠间隔大于10年等)及平均动脉压对早发型重症子痫前期的预测效能有限,而基于胎盘相关的分子标志物,如血管生成因子(sflt-1)和血管生成因子(plgf)的比值对于子痫前期具有较高的阴性预测价值,但中国人群的研究表明,阴性预测效果明显,但其阳性预测值都不高。由于疾病发病机制的复杂性,目前尚无一种指标或几种指标联合用于早发型重症子痫前期的早期临床预测。因此,寻找有效的早期分子标志物成为早发型重症子痫前期临床诊疗的关键问题。
4.研究发现外周血游离dna在基因转录起始位点区域的分布情况能够表征基因的转录情况,血清游离dna丰度在先兆子痫患者与健康孕妇中存在显著差异;如cn110305954a公开了一种早期准确检测先兆子痫的预测模型,发现外周血游离dna在基因转录起始位点区域的分布情况能够反应孕妇与胎儿的生理状态,基于基因转录起始位点区域的血清游离dna丰度在先兆子痫患者与健康孕妇中存在显著差异,对游离dna丰度进行均一化校正后,使用机器学习算法,通过不同差异基因的优选组合,能够有效预测先兆子痫的发病,但该方法并没有对先兆子痫的亚型进行具体区分,无法判断其在早发型重度先兆子痫前期患者的情况。
5.综上所述,如何提供一种对先兆子痫的亚型进行具体区分的方法,是先兆子痫检测领域亟需解决问题之一。
技术实现要素:
6.针对现有技术的不足和实际需求,本发明提供一种与早发型重度子痫前期发生相关的靶标基因组合及其应用,利用所述靶标基因组合结合特殊设计的分析策略构建预测模型,能够有效对先兆子痫的亚型进行具体区分,预测早发型重度先兆子痫前期患病风险,提
供是一种相对无创、经济方便且具备高准确性的早发型重度子痫前期预测的方法。
7.为达上述目的,本发明采用以下技术方案:
8.第一方面,本发明提供一种与早发型重度子痫前期发生相关的靶标基因组合,所述靶标基因组合包括snord14c、aspa、arl13a、trim69、linc01338、fibin、f8a2、mrpl20、brf1、znf407-as1、bves、tfdp1、col4a4、ankrd36bp2、dus3l、adcy1、kif26a、slc12a2、klf4、chka和kif26b。
9.本发明对外周血游离dna进行深入分析,发现外周血游离dna在某些基因转录起始位点区域(transcript start site,tss)的分布情况在早发型重度先兆子痫和健康对照组存在差异,并筛选一种与早发型重度子痫前期发生相关的靶标基因组合,可有效作为筛查早发型重度子痫前期的标志物。
10.第二方面,本发明提供第一方面所述的与早发型重度子痫前期发生相关的靶标基因组合在作为筛查早发型重度子痫前期的标志物方面的应用。
11.第三方面,本发明提供第一方面所述的与早发型重度子痫前期发生相关的靶标基因组合在制备早发型重度子痫前期筛查产品中的应用。
12.第四方面,本发明提供一种用于早发型重度子痫前期检测的系统,所述用于早发型重度子痫前期检测的系统包括:
13.样本分析模块:将样本测序数据比对到参考基因组上并获取每个基因的转录起始位点区域覆盖情况;
14.筛选特征模块:筛选预测早发型重度先兆子痫前期的特征基因;
15.构建模型模块:构建预测早发型重度先兆子痫前期的模型;
16.计算模块:利用预测早发型重度先兆子痫前期的模型计算样本患早发型重度先兆子痫前期的概率;
17.所述特征基因为第一方面所述的与早发型重度子痫前期发生相关的靶标基因组合。
18.本发明基于外周血游离dna高通量测序中基因转录起始位点及附近区域特征,对游离dna tss特征进行均一化校正后,利用与早发型重度子痫前期发生相关的靶标基因组合和孕周,使用机器学习方法构建预测模型,预测效果接收者操作特征曲线(receiver operating characteristic curve,roc)中的曲线下面积(areaunderthe curve,auc)达到0.9以上,预测准确性远优于当前早发型重度先兆子痫前期风险预测方法。
19.优选地,所述样本分析模块用于进行包括如下的操作:
20.(1-1)获取样本的高通量测序原始数据与参考基因组进行比对,并按照染色体进行排序;
21.(1-2)对比对的结果进行去重复;
22.(1-3)统计每个基因的转录起始位点区域的覆盖深度,对每个转录起始位点区域的覆盖深度加和得到每个基因的tss
depth
;
23.(1-4)将每个基因的转录起始位点区域按照公式(1)进行标准化得到每个基因的转录起始位点区域的特征;
24.tss
i normalized
=tss
i depth
/total tss
depth
×
106ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(1)
25.其中,tss
i normalized
为基因i的转录起始位点区域的特征,tss
i depth
为基因i的转录
起始位点区域的覆盖深度,total tss
depth
为所有基因的转录起始位点区域的覆盖深度加和。
26.优选地,所述样本包括血浆游离dna。
27.优选地,所述转录起始位点区域的大小为转录起始位点上下游1kb。
28.优选地,所述筛选特征模块包括:
29.(2-1)将早发型重度先兆子痫前期患者和正常孕妇按照孕周进行匹配,使用差异分析软件寻找两组样本转录起始位点区域有显著差异的基因;
30.(2-2)使用最小绝对值收敛和选择算子对(2-1)差异基因筛选,得到预测模型的特征基因。
31.优选地,所述构建模型模块用于进行包括如下的操作:
32.(3-1)获取最佳截断值:按照公式(2)计算特征基因区分对照组和疾病组的最佳截断值best cut-off;
33.best cut-off=max(sensitivity+specificity)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(2);
34.其中,max(sensitivity+specificity)表示灵敏性(sensitivity)和特异性(specificity)加和的最大值;
35.(3-2)特征基因离散化:按照最佳截断值根据公式(3)将训练集样本中特征基因的转录起始位点tss
i normalized
进行离散化转化为0或1;
36.公式(3):
37.tssi=0,tss
i normalized
》=best cut-off;
38.tssi=1,tss
i normalized
《best cut-off;
39.其中,tssi为基因i最终离散化后的特征值;
40.(3-3)构建模型:使用机器学习的方法构建预测早发型重度先兆子痫前期的模型。
41.优选地,所述机器学习的方法包括贝叶斯统计、随机森林、支持向量机或广义线性模型中的任意一种。
42.优选地,(3-3)还包括使用10次交叉验证的方法对模型参数进行优化。
43.本发明中,预测模型使用r语言caret包进行构建,具体代码如下所述,其中trainx为训练集样本21个特征基因离散化后的结果和样本的孕周信息,trainy为训练集样本的患病结局,最终得到的模型有rf.model,svmlinear.model,naive_bayes.model和svmradialweights.model,代码为:
44.subsetsizes=c(1:length(trainx))
45.seeds《-vector(mode="list",length=51)
46.for(i in 1:50)seeds[[i]]《-sample.int(1000,length(subsetsizes)+1)
[0047]
seeds[[51]]《-sample.int(1000,1)
[0048]
control=traincontrol(
[0049]
method="repeatedcv",
[0050]
number=10,
[0051]
repeats=5,
[0052]
p=0.75,
[0053]
search="grid",
[0054]
initialwindow=null,
[0055]
horizon=1,
[0056]
fixedwindow=true,
[0057]
skip=0,
[0058]
verboseiter=false,
[0059]
returndata=true,
[0060]
returnresamp="final",
[0061]
savepredictions=true,
[0062]
classprobs=true,
[0063]
summaryfunction=twoclasssummary,
[0064]
selectionfunction="best",
[0065]
preprocoptions=list(thresh=0.95,icacomp=3,k=5,freqcut=95/5,
[0066]
uniquecut=10,cutoff=0.9),
[0067]
sampling=null,
[0068]
index=null,
[0069]
indexout=null,
[0070]
indexfinal=null,
[0071]
timingsamps=0,
[0072]
predictionbounds=rep(false,2),
[0073]
seeds=seeds,
[0074]
adaptive=list(min=5,alpha=0.05,method="gls",complete=true),
[0075]
trim=false,
[0076]
allowparallel=true
[0077]
)
[0078]
rf.model《-train(trainx,trainy,method="rf",
[0079]
metric="roc",trcontrol=control)
[0080]
svmlinear.model《-train(trainx,trainy,method="svmlinear",
[0081]
metric="roc",trcontrol=control)
[0082]
naive_bayes.model《-train(trainx,trainy,method="naive_bayes",
[0083]
metric="roc",trcontrol=control)
[0084]
svmradialweights.model《-train(trainx,trainy,method="svmradialweights",
[0085]
metric="roc",trcontrol=control)。
[0086]
优选地,所述计算模块用于进行包括如下的操作:
[0087]
将特征基因离散化后的结果和孕周输入预测早发型重度先兆子痫前期的模型得到样本患早发型重度先兆子痫前期的概率。
[0088]
作为优选的技术方案,所述用于早发型重度子痫前期检测的系统包括:
[0089]
(1)样本分析模块,用于进行包括如下的操作:
[0090]
(1-1)获取样本的高通量测序原始数据与参考基因组进行比对,并按照染色体进
行排序;
[0091]
(1-2)对比对的结果进行去重复;
[0092]
(1-3)统计每个基因的转录起始位点区域的覆盖深度,对每个转录起始位点区域的覆盖深度加和得到每个基因的tss
depth
;
[0093]
(1-4)将每个基因的转录起始位点区域按照公式(1)进行标准化得到每个基因的转录起始位点区域的特征;
[0094]
tss
i normalized
=tss
i depth
/total tss
depth
×
106ꢀꢀꢀꢀꢀꢀꢀꢀ
公式(1)
[0095]
其中,tss
i normalized
为基因i的转录起始位点区域的特征,tss
i depth
为基因i的转录起始位点区域的覆盖深度,total tss
depth
为所有基因的转录起始位点区域的覆盖深度加和;
[0096]
(2)筛选特征模块,用于进行包括如下的操作:
[0097]
(2-1)将早发型重度先兆子痫前期患者和正常孕妇按照孕周进行匹配,使用差异分析软件寻找两组样本转录起始位点区域有显著差异的基因;
[0098]
(2-2)使用最小绝对值收敛和选择算子对(2-1)差异基因筛选,得到预测模型的特征基因;
[0099]
(3)构建模型模块,用于进行包括如下的操作:
[0100]
(3-1)获取最佳截断值:按照公式(2)计算特征基因区分对照组和疾病组的最佳截断值best cut-off;
[0101]
best cut-off=max(sensitivity+specificity)
ꢀꢀꢀꢀꢀꢀꢀꢀ
公式(2)
[0102]
(3-2)特征基因离散化:按照最佳截断值根据公式(3)将训练集样本特征基因的转录起始位点tss
i normalized
进行离散化转化为0或1;
[0103]
公式(3):
[0104]
tssi=0,tss
inormalized
》=best cut-off;
[0105]
tssi=1,tss
inormalized
《best cut-off;
[0106]
(3-3)构建模型:使用机器学习的方法构建预测早发型重度先兆子痫前期的模型;
[0107]
(4)计算模块,用于进行包括如下的操作:将(3-2)特征基因离散化后的结果和孕周输入预测早发型重度先兆子痫前期的模型得到样本患早发型重度先兆子痫前期的概率。
[0108]
优选地,样本患早发型重度先兆子痫前期的概率大于等于0.5,则判断样本为早发型重度子痫前期高危,样本患早发型重度先兆子痫前期的概率小于0.5,则判断样本为早发型重度子痫前期低危。
[0109]
与现有技术相比本发明具有以下有益效果:
[0110]
(1)本发明筛选一种与早发型重度子痫前期发生相关的靶标基因组合,基因组合的tss特征在患者与健康孕妇中存在显著差异,可有效作为筛查早发型重度子痫前期的标志物;
[0111]
(2)本发明对游离dna tss特征进行均一化校正后,利用与早发型重度子痫前期发生相关的靶标基因组合和孕妇的孕周信息,使用机器学习方法构建预测模型,预测效果接收者操作特征曲线(receiver operating characteristic curve,roc)中的曲线下面积(areaunderthe curve,auc)达到0.9以上,预测准确性远优于当前早发型重度先兆子痫前期风险预测方法。
附图说明
[0112]
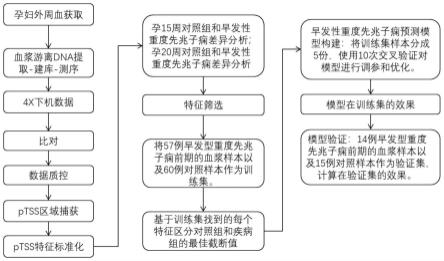
图1为本发明分析流程图;
[0113]
图2为孕15周疾病和对照的差异基因热图;
[0114]
图3为孕20周疾病和对照的差异基因热图;
[0115]
图4为使用lasso算法筛选得到的最终特征值及其系数图;
[0116]
图5为基于21个特征和孕周构建的模型在训练集中的效果图;
[0117]
图6为基于21个特征和孕周构建的模型在验证集中的效果图。
具体实施方式
[0118]
为进一步阐述本发明所采取的技术手段及其效果,以下结合实施例和附图对本发明作进一步地说明。可以理解的是,此处所描述的具体实施方式仅仅用于解释本发明,而非对本发明的限定。
[0119]
实施例中未注明具体技术或条件者,按照本领域内的文献所描述的技术或条件,或者按照产品说明书进行。所用试剂或仪器未注明生产厂商者,均为可通过正规渠道商购获得的常规产品。
[0120]
本发明实施例中提供一种在基于血浆游离dna的tss特征预测早发型重度先兆子痫前期的模型,完整分析流程图如图1所示。
[0121]
实施例1
[0122]
本实施例构建预测早发型重度先兆子痫前期的模型。
[0123]
1、血浆样本的获取
[0124]
在本实施例中,以71例已确诊为早发型重度先兆子痫前期孕妇的发病前外周血样本和75例健康孕妇外周血样本进行对照研究,提取外周血中血浆游离dna,对两种样本的血浆游离dna进行高通量双端测序,基因组的平均测序深度达到4
×
以上。
[0125]
2、血浆游离dna的分析
[0126]
在进行血浆游离dna高通量测序后,将序列与人类基因组标准序列hg19比对,确定每条序列在人类基因组染色体上的位置,对每个基因tss上下游1kb的覆盖深度加和得到每个基因tss
depth
,将每个基因的tss按照下述公式(1)进行标准化得到每个基因tss的特征。
[0127]
tss
i normalized
=tss
i depth
/total tss
depth
×
106ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(1)。
[0128]
3、预测早发型重度先兆子痫前期的特征筛选
[0129]
将早发型重度先兆子痫前期样本和对照组样本按照孕周进行匹配,分别在孕15周和孕20周使用差异分析软件(deseq2)找到两组样本tss特征显著差异的基因,孕15周疾病和对照的差异基因热图如图2所示,孕20周疾病和对照的差异基因热图如图2所示,使用lasso算法将上述找到的差异基因进一步筛选,得到最终21个基因纳入预测模型的特征,结果如图4所示。
[0130]
4、预测早发型重度先兆子痫前期的模型构建
[0131]
(1)挑选57例早发型重度先兆子痫前期的血浆样本以及60例对照样本(健康)作为训练集,在训练集的样本中,按照公式(2)计算上述找到的每个特征区分对照组和疾病组的最佳截断值。
[0132]
(2)按照最佳截断值将训练集样本特征基因的tss
inormalized
进行离散化。具体公式
见公式(3)。
[0133]
公式(3):
[0134]
tssi=0,tss
i normalized
》=best cut-off;
[0135]
tssi=1,tss
i normalized
《best cut-off。
[0136]
(3)使用机器学习的方法,包括贝叶斯统计(naive_bayes)、随机森林(rf)和支持向量机(svmlinear,svmradialweights)在训练集中基于上述的确认的特征和孕周构建预测模型,并使用10次交叉验证的方法对模型参数进行优化,确认最终预测模型,基于预测效果接收者操作特征曲线(receiver operating characteristic curve,roc),计算模型在训练集的auc,结果如图5所示,naive_bayes构建的模型auc达到0.93,rf构建的模型auc达到1.00,svmlinear构建的模型auc达到0.93,svmradialweights构建的模型auc达到0.95,四种模型在训练集的auc都高达0.9以上。
[0137]
其中模型构建使用r语言caret包进行构建,具体代码如下所述,其中trainx为训练集样本21个特征基因离散化后的结果和样本的孕周信息,trainy为训练集样本的患病结局,最终得到的模型有rf.model,svmlinear.model,naive_bayes.model和svmradialweights.model。代码为:
[0138]
subsetsizes=c(1:length(trainx))
[0139]
seeds《-vector(mode="list",length=51)
[0140]
for(i in 1:50)seeds[[i]]《-sample.int(1000,length(subsetsizes)+1)
[0141]
seeds[[51]]《-sample.int(1000,1)
[0142]
control=traincontrol(
[0143]
method="repeatedcv",
[0144]
number=10,
[0145]
repeats=5,
[0146]
p=0.75,
[0147]
search="grid",
[0148]
initialwindow=null,
[0149]
horizon=1,
[0150]
fixedwindow=true,
[0151]
skip=0,
[0152]
verboseiter=false,
[0153]
returndata=true,
[0154]
returnresamp="final",
[0155]
savepredictions=true,
[0156]
classprobs=true,
[0157]
summaryfunction=twoclasssummary,
[0158]
selectionfunction="best",
[0159]
preprocoptions=list(thresh=0.95,icacomp=3,k=5,freqcut=95/5,uniquecut=10,cutoff=0.9),
[0160]
sampling=null,
[0161]
index=null,
[0162]
indexout=null,
[0163]
indexfinal=null,
[0164]
timingsamps=0,
[0165]
predictionbounds=rep(false,2),
[0166]
seeds=seeds,
[0167]
adaptive=list(min=5,alpha=0.05,method="gls",complete=true),
[0168]
trim=false,
[0169]
allowparallel=true
[0170]
)
[0171]
rf.model《-train(trainx,trainy,method="rf",
[0172]
metric="roc",trcontrol=control)
[0173]
svmlinear.model《-train(trainx,trainy,method="svmlinear",
[0174]
metric="roc",trcontrol=control)
[0175]
naive_bayes.model《-train(trainx,trainy,method="naive_bayes",
[0176]
metric="roc",trcontrol=control)
[0177]
svmradialweights.model《-train(trainx,trainy,method="svmradialweights",
[0178]
metric="roc",trcontrol=control)。
[0179]
实施例2
[0180]
以14例早发型重度先兆子痫前期的血浆样本以及15例健康对照样本验证实施例1所构建模型的效果。
[0181]
1、血浆样本获取和血浆游离dna的分析的步骤同实施例1。
[0182]
2、提取每例样本实施例1中获得的21个基因的tss特征,按照实施例一在训练集中所确定的最佳截断值,按照公式(3)将测试集样本特征基因的tss
i normalized
进行离散化。离散化后的特征和孕周作为输入使用实施例1中构建的模型预测样本患早发型重度先兆子痫前期的概率。
[0183]
3、计算模型在验证集中预测早发型重度先兆子痫前期的效果,基于预测效果接收者操作特征曲线(receiver operating characteristic curve,roc),计算模型在验证集的曲线下面积(area under the curve,auc),结果如图6所示,naive_bayes构建的模型auc达到0.97,rf构建的模型auc达到0.90,svmlinear构建的模型auc达到0.94,svmradialweights构建的模型auc达到0.92,四种模型在验证集的auc都高达0.9以上。
[0184]
综上所述,本发明发现,虽然早发型重度先兆子痫前期患者在怀孕15~20周尚未出现临床症状,但此时患者与健康孕妇血浆游离dna部分基因的tss特征在患者与健康孕妇中存在显著差异,对tss特征进行标准化和离散化后结合孕妇孕周信息,使用机器学习算法,通过对疾病样本和健康样本的孕周进行匹配,筛选出15周和20周疾病样本和健康样本显著差异的基因组合,以此为基础构建的预测模型能够有效预测早发型重度先兆子痫前期的发病,所述模型基于孕15周和孕20周孕妇血浆游离dna高通量测序结果中tss特征差异,预测的早发型重度先兆子痫前期的发病风险,可应用于早发型重度先兆子痫前期筛查预测
相关产品开发。
[0185]
申请人声明,本发明通过上述实施例来说明本发明的详细方法,但本发明并不局限于上述详细方法,即不意味着本发明必须依赖上述详细方法才能实施。所属技术领域的技术人员应该明了,对本发明的任何改进,对本发明产品各原料的等效替换及辅助成分的添加、具体方式的选择等,均落在本发明的保护范围和公开范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1